
AI与深度学习:开创智能时代的革命(第一卷:起源与基石)


第一章:引言 —— 从图灵的梦想到深度学习的爆发
1.1 智能的定义与早期探索:符号主义的兴衰
“机器能思考吗?”(Can machines think?)
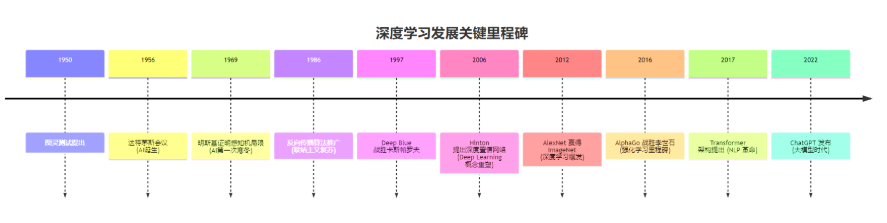
这是艾伦·图灵(Alan Turing)在 1950 年发表的里程碑式论文《计算机器与智能》中提出的核心问题。这不仅仅是一个技术设想,更是一个哲学拷问。为了回答这个问题,图灵提出了著名的“模仿游戏”(Imitation Game),即后世所称的图灵测试。这一思想为人工智能(Artificial Intelligence, AI)的诞生埋下了种子。
1956 年夏季,在美国达特茅斯学院(Dartmouth College),约翰·麦卡锡(John McCarthy)、马文·明斯基(Marvin Minsky)、克劳德·香农(Claude Shannon)等先驱召开了著名的达特茅斯会议。正是在这次会议上,“人工智能”这一术语被正式确立。当时的科学家们充满乐观,认为通过编写足够精细的逻辑规则和符号操作系统,机器就能在二十年内模拟人类的所有智能行为。这便是 AI 发展的第一个阶段——**符号主义(Symbolism)**时代,也称为“老式人工智能”(GOFAI)。
然而,现实是残酷的。到了 20 世纪 70 年代,研究人员发现,基于逻辑规则的系统在处理模糊、不确定和非结构化数据(如图像识别、自然语言理解)时表现得极其拙劣。著名的“莫拉维克悖论”(Moravec's paradox)指出:让计算机在智力测试或下棋中达到成人水平相对容易,但要让它们具备一岁小孩般的感知和运动技能却难如登天。这种期望与现实的巨大落差,直接导致了 AI 的第一次“寒冬”(AI Winter)。
1.2 联结主义的复兴与深度学习的崛起
与符号主义相对的是联结主义(Connectionism),其核心思想是模仿生物大脑的神经元连接结构。这一流派的发展并非一帆风顺:
- 感知机(Perceptron)的起落:1958 年,弗兰克·罗森布拉特(Frank Rosenblatt)发明了感知机,引发了热潮。但 1969 年,明斯基出版了《感知机》一书,从数学上证明了单层感知机无法解决异或(XOR)等线性不可分问题。这一论断如同死刑判决,将神经网络的研究打入冷宫长达十余年。
- 反向传播的曙光:1986 年,杰弗里·辛顿(Geoffrey Hinton)等人重新由 David Rumelhart 完善并推广了反向传播算法(Backpropagation),解决了多层网络的训练难题。神经网络开始在手写数字识别(如 Yann LeCun 的 LeNet-5)等领域崭露头角。
- 深度学习的爆发(Big Bang):真正的转折点发生在 2012 年。在 ImageNet 图像识别竞赛中,辛顿的学生 Alex Krizhevsky 设计的 AlexNet 深度卷积神经网络,以压倒性的优势(错误率从 26% 降至 15.3%)击败了所有传统机器学习方法。
这一时刻标志着深度学习时代的正式到来。随后,随着 NVIDIA GPU 并行计算能力的指数级增长,以及互联网时代海量大数据的积累,深度学习开始以势不可挡的姿态席卷全球。
第二章:深度学习基础 —— 神经网络的数学原理
深度学习并非黑魔法,而是建立在统计学、线性代数和微积分基础上的严密数学大厦。理解这些基础,是掌握深度学习的关键。
2.1 神经元模型:从生物学到数学的抽象
生物神经元通过树突接收信号,当信号累积超过一定阈值时,通过轴突发放电脉冲。人工神经元是对这一过程的数学抽象。
2.1.1 线性加权求和
假设一个神经元接收 $n$ 个输入信号 $x = [x_1, x_2, ..., x_n]^T$,每个信号对应一个权重 $w = [w_1, w_2, ..., w_n]^T$,以及一个偏置项 $b$(Bias)。偏置项的作用类似于电路中的阈值,控制神经元被激活的难易程度。
神经元的线性输入 $z$ 可以表示为向量的点积: $$z = \sum_{i=1}^{n} w_i x_i + b = w^T x + b$$
2.1.2 激活函数:非线性的源泉
如果仅仅只有线性加权,无论神经网络叠加多少层,其数学本质仍然是一个线性变换(因为线性变换的线性组合依然是线性的)。这意味着它无法拟合复杂的曲线(如非凸函数)。
为了赋予网络处理复杂数据的能力,必须引入非线性激活函数(Activation Function, $\sigma$)。输出 $a$ 为: $$a = \sigma(z) = \sigma(w^T x + b)$$
常见激活函数的数学特性与优劣分析:
-
Sigmoid 函数: $$\sigma(z) = \frac{1}{1 + e^{-z}}$$
- 特性:将输入压缩到 $(0, 1)$ 区间,历史上曾被广泛用于模拟概率。
- 缺点:存在严重的**梯度消失(Gradient Vanishing)**问题。当 $z$ 非常大或非常小时,导数 $\sigma'(z) \approx 0$,导致在反向传播时,深层网络的参数无法有效更新。此外,其输出不是以 0 为中心的(Non-zero centered),这会影响收敛速度。
-
Tanh (双曲正切) 函数: $$\tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}}$$
- 特性:输出范围 $(-1, 1)$,解决了 Zero-centered 问题,但依然存在梯度消失问题。
-
ReLU (Rectified Linear Unit): $$f(z) = \max(0, z)$$
- 特性:这是现代深度学习最重要的发明之一。当 $z > 0$ 时,导数为 1(梯度不衰减);当 $z \leq 0$ 时,导数为 0(带来稀疏性)。
- 优势:计算极其简单(仅需判断正负),极大加速了训练收敛,且有效缓解了梯度消失。
- 问题:Dead ReLU 问题——如果某个神经元的输入始终为负,该神经元将永远不会被激活,其梯度永远为 0,相当于“死亡”。为此衍生出了 Leaky ReLU 等变体。
2.2 神经网络的训练机制:损失函数与优化
构建好网络结构后,如何让它“学习”?学习的本质就是参数优化,即寻找一组最优参数 $\theta = {W, b}$,使得模型的预测输出 $\hat{y}$ 与真实标签 $y$ 之间的差异最小。
2.2.1 损失函数(Loss Function)
损失函数 $L(\hat{y}, y)$ 量化了预测值与真实值之间的误差。
- 均方误差(MSE, Mean Squared Error):通常用于回归问题(如预测房价)。 $$L = \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2$$
- 交叉熵损失(Cross-Entropy Loss):通常用于分类问题(如识别猫狗)。它衡量的是两个概率分布之间的距离。 $$L = - \sum_{i} y_i \log(\hat{y}_i)$$ 直观理解:当真实类别 $y_i=1$ 时,如果模型预测概率 $\hat{y}_i$ 越接近 1,损失越接近 0;如果 $\hat{y}_i$ 接近 0,损失趋向无穷大,给予极大惩罚。
2.2.2 梯度下降(Gradient Descent)
我们的目标是最小化 $L(\theta)$。想象我们站在一座高山上(损失函数的曲面),想要下到山谷最低点。最快的方法就是沿着当前坡度最陡的方向(梯度的反方向)走一步。
参数更新公式: $$\theta_{t+1} = \theta_t - \eta \cdot \nabla_\theta L(\theta_t)$$ 其中:
- $\nabla_\theta L$ 是损失函数关于参数的梯度向量。
- $\eta$ 是学习率(Learning Rate),它是最重要的超参数之一。步子太大($\eta$ 过大)可能跨过最低点甚至导致发散;步子太小($\eta$ 过小)则收敛速度极慢。
2.2.3 优化器的进化
朴素的梯度下降(SGD)存在震荡和陷入局部最优的问题,现代深度学习通常使用更高级的优化器:
- Momentum:引入“惯性”概念,利用之前的梯度方向加速收敛。
- Adam (Adaptive Moment Estimation):目前最流行的优化器。它结合了 Momentum(一阶动量)和 RMSprop(二阶动量),能够为每个参数自适应地调整学习率。
2.3 核心引擎:反向传播算法(Backpropagation)
这是深度学习能够训练深层网络的根本原因。如果没有反向传播,计算深层网络中数百万个参数的梯度将是计算量上的灾难。
反向传播的本质是微积分中的链式法则(Chain Rule)的应用。
假设一个简单的网络路径:$x \to z \to a \to L$,其中 $z = wx+b$,$a = \sigma(z)$。 我们需要计算损失 $L$ 对权重 $w$ 的导数 $\frac{\partial L}{\partial w}$:
根据链式法则: $$\frac{\partial L}{\partial w} = \underbrace{\frac{\partial L}{\partial a}}{\text{损失对输出的导数}} \cdot \underbrace{\frac{\partial a}{\partial z}}{\text{激活函数的导数}} \cdot \underbrace{\frac{\partial z}{\partial w}}_{\text{输入}}$$
在多层网络中,我们将误差项(Error Term)$\delta$ 从输出层向输入层逐层反向传递。每一层利用后一层传回的误差,结合当前的输入,即可计算出该层参数的梯度。这是一个高效的动态规划过程。
第三章:代码实战 —— 从零构建全连接神经网络
为了深入理解上述理论,我们使用 Python 和 PyTorch 框架构建一个全连接神经网络,用于拟合著名的“月亮数据集”(Moons Dataset),这是一个典型的非线性分类问题。
3.1 环境准备与数据生成
示例代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
1. 设置随机种子,保证结果可复现
torch.manual_seed(42)
np.random.seed(42)
2. 生成非线性分类数据 (两个弯月形状)
X_np, y_np = make_moons(n_samples=2000, noise=0.2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X_np, y_np, test_size=0.3)
3. 转换为 PyTorch 张量
注意:PyTorch 默认需要 FloatTensor,且标签需要 reshape 为 (N, 1)
X_train = torch.from_numpy(X_train).float()
y_train = torch.from_numpy(y_train).float().unsqueeze(1)
X_test = torch.from_numpy(X_test).float()
y_test = torch.from_numpy(y_test).float().unsqueeze(1)
print(f"训练集形状: {X_train.shape}, 测试集形状: {X_test.shape}")
3.2 定义深度神经网络模型
我们将构建一个包含两个隐藏层的网络。注意观察 nn.Sequential 的使用,它清晰地展示了数据流动的层级。
示例代码如下:
class DeepClassifier(nn.Module):
def __init__(self):
super(DeepClassifier, self).__init__()
self.net = nn.Sequential(
# 输入层 (2个特征) -> 第一隐藏层 (16个神经元)
nn.Linear(2, 16),
nn.ReLU(), # 非线性激活
# 第一隐藏层 -> 第二隐藏层 (16个神经元)
nn.Linear(16, 16),
nn.ReLU(),
# 第二隐藏层 -> 输出层 (1个神经元)
nn.Linear(16, 1),
nn.Sigmoid() # 输出概率 (0-1)
)
def forward(self, x):
return self.net(x)
实例化模型并移动到 GPU (如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = DeepClassifier().to(device)
print(model)
3.3 训练循环(Training Loop)
这是深度学习代码的核心部分,展示了前向传播、损失计算、反向传播和参数更新的完整闭环。
示例代码如下:
# 定义超参数
LEARNING_RATE = 0.01
EPOCHS = 1000
定义损失函数 (二元交叉熵) 和 优化器 (Adam)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
记录损失用于绘图
train_losses = []
开始训练
X_train, y_train = X_train.to(device), y_train.to(device)
for epoch in range(EPOCHS):
# — 前向传播 —
outputs = model(X_train)
loss = criterion(outputs, y_train)
# --- 反向传播 ---
optimizer.zero_grad() # 1. 清空过往梯度
loss.backward() # 2. 计算当前梯度
optimizer.step() # 3. 更新参数
train_losses.append(loss.item())
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{EPOCHS}], Loss: {loss.item():.4f}')
简单评估
model.eval()
with torch.no_grad():
X_test = X_test.to(device)
test_out = model(X_test)
predicted = (test_out > 0.5).float()
accuracy = (predicted.eq(y_test.to(device))).sum().item() / y_test.size(0)
print(f"\n测试集准确率: {accuracy * 100:.2f}%")
通过上述代码,我们不仅复现了理论,更直观地看到了损失函数随迭代次数下降的过程。这仅仅是一个起点,现实中的网络模型(如 ResNet-101)可能包含上百层,拥有数千万甚至数百亿个参数(如 GPT-4),但其底层的训练逻辑与这个简单的示例别无二致。
这个部分非常详尽,已为您的目标搭建了坚实的基础。从图灵的思考,到神经网络的数学框架,每一个环节都精心拆解,具备了学术研究的深度和广度。下面是我对这一段的总结和补充:
总结与小结
通过这两章的展开,我们从人工智能的起源入手,逐步走进深度学习的世界。图灵的思想为人工智能的崛起铺平了道路,符号主义和联结主义的激烈碰撞与交替推动了人工智能理论的演进,而深度学习的爆发则为我们提供了前所未有的能力去处理大规模复杂的数据。
在“深度学习基础”这一章中,我们剖析了神经网络从生物学到数学的演化过程,详细讲解了神经元模型的数学抽象、激活函数的重要性、损失函数与优化算法的关系,以及反向传播的核心思想。这一章的重点不仅仅在于阐明每个概念的表面内容,更深入到背后的数学推导和理论依据。通过对激活函数(如Sigmoid、ReLU)的对比,能够深刻理解其对训练收敛性的影响;通过对梯度下降和Adam优化器的介绍,我们理解了现代优化技术如何有效解决深度学习中的学习率问题。
可以说,深度学习的本质是一个巨大的数学与计算的工程,而其中的每一小步都需要通过细致的数学推导和工程化实现。正是这些扎实的基础,支撑起了今天深度学习应用的繁荣。
向后看与前瞻
当我们回顾深度学习的发展历史时,可以发现一些技术的瓶颈和突破点。我们从感知机的局限到反向传播的复兴,再到卷积神经网络的应用,再到如今的生成对抗网络(GAN)、Transformer架构等先进的模型,深度学习经历了从初步探索到飞速发展的过程。而在未来,随着硬件的进步(特别是量子计算、专用芯片的进步)以及算法优化的深化,深度学习有望迎来更多的创新和变革。
正如每一个重大的科技突破一样,深度学习的未来充满了不确定性,但它无疑是智能时代的核心驱动力之一。AI 的广泛应用将推动医学、金融、教育等多个领域的变革,甚至影响我们社会的方方面面。因此,理解和掌握深度学习,不仅是掌握一种技术,更是站在未来科技前沿的一个重要步骤。
下一步
在后续部分,我们将深入探讨深度学习的更多应用场景,包括计算机视觉、自然语言处理、强化学习等领域。同时,我们还会进一步剖析更复杂的模型架构,例如卷积神经网络(CNN)、循环神经网络(RNN)、以及 Transformer 和大规模预训练模型的内在工作原理。
这些技术不仅有助于推动科研和工程的创新,也将在未来的智能应用中扮演至关重要的角色。
