
自然语言处理与情感分析:理解和塑造人类语言!


摘要
自然语言处理(NLP)的核心目标是跨越人类认知的符号系统与计算机计算的数值系统之间的鸿沟。为了实现这一目标,技术架构经历了从基于规则的符号主义到基于统计的连接主义的深刻变革。本章将深入剖析支撑现代情感分析系统的三大基石:词向量表示、句法结构分析以及命名实体识别技术。
2.1 语言的数学表征:从离散符号到高维向量
计算机无法直接理解“喜欢”或“讨厌”这样的字符,它只能处理数字。因此,如何将词汇映射到数学空间(Vector Space)是 NLP 的首要问题。
2.1.1 传统表征的困境:独热编码(One-Hot Encoding)
在深度学习爆发之前,NLP 广泛采用独热编码。假设词汇表大小为 $V$,每个词被表示为一个 $R^{|V|}$ 维的向量,其中仅对应词的索引位置为 1,其余为 0。 例如:
$$ \text{apple} = [0, 0, 1, 0, ..., 0] $$
$$ \text{banana} = [0, 0, 0, 0, ..., 1] $$
这种表示法存在两个致命缺陷,导致其无法支撑复杂的语义分析:
- 维度灾难(Curse of Dimensionality):随着词汇量的增加(通常在 10 万到 100 万量级),向量维度极度膨胀且极度稀疏,导致计算效率低下。
- 语义鸿沟(Semantic Gap):任意两个不同词向量之间的余弦相似度恒为 0(正交)。这意味着计算机无法捕捉到“苹果”和“香蕉”都是水果这一隐含的语义相似性,这对于情感迁移分析是灾难性的。
2.1.2 分布式表示与 Word2Vec 革命
为了解决上述问题,Hinton 等人提出了分布式表示(Distributed Representation)的概念。其核心思想源于语言学中的分布假说(Distributional Hypothesis):“一个词的含义由它周围的词决定”。
2013年,Google 提出的 Word2Vec 模型将这一思想推向了工程实用的巅峰。Word2Vec 包含两种架构:CBOW(Continuous Bag-of-Words)和 Skip-gram。
(1) Skip-gram 模型数学推导
Skip-gram 的目标是给定中心词 $w_t$,预测上下文词 $w_{t+j}$。假设上下文窗口大小为 $c$,我们需要最大化以下对数似然函数:
$$ \mathcal{L} = \sum_{t=1}^{T} \sum_{-c \le j \le c, j \ne 0} \log P(w_{t+j} | w_t) $$
其中条件概率 $P(w_{t+j} | w_t)$ 通常使用 Softmax 函数定义:
$$ P(w_O | w_I) = \frac{\exp({v'{w_O}}^\top v{w_I})}{\sum_{w=1}^{W} \exp({v'w}^\top v{w_I})} $$
这里 $v_w$ 和 $v'_w$ 分别是词 $w$ 作为中心词和上下文词时的向量表示。
技术难点与优化: 由于分母需要遍历整个词汇表 $W$,计算成本极其高昂。在实际工程中,Word2Vec 采用了两种优化策略:
- 层次 Softmax (Hierarchical Softmax):利用霍夫曼树(Huffman Tree)将计算复杂度从 $O(W)$ 降低到 $O(\log_2 W)$。
- 负采样 (Negative Sampling):不再计算所有非目标词的概率,而是随机采样 $k$ 个负样本(非上下文词),仅更新这些样本的权重。
(2) 模型架构对比
下图展示了 CBOW 与 Skip-gram 在信息流向上的本质区别:
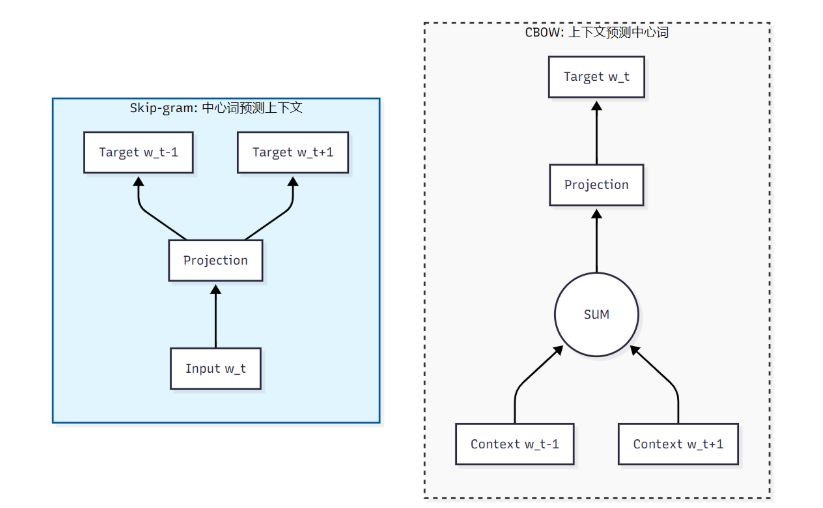
2.1.3 GloVe 与 FastText:词向量的进阶
Word2Vec 虽然高效,但通过滑动窗口训练,忽略了全局共现统计信息。
- GloVe (Global Vectors):斯坦福大学提出的模型,直接分解由语料库构建的“词-词共现矩阵”。其损失函数旨在使两个词向量的点积等于它们共现概率的对数,从而结合了统计矩阵分解和局部上下文窗口的优点。
- FastText:Facebook AI 提出的改进版。它将每个词视为“字符 n-gram”的集合(例如 apple 可以表示为 <ap, app, ppl, ple, le>)。这种方法的巨大优势在于能够处理 未登录词(OOV) 问题——即使从未见过“GooglePlus”,只要见过“Google”和“Plus”,模型就能推断出其含义。
2.2 句法分析:从词序列到树结构
情感分析不仅仅依赖孤立的词汇。否定词的位置(如“不”)、转折连词(如“但是”)以及形容词修饰的对象,都深刻影响情感极性。句法分析(Syntactic Parsing)通过揭示句子的语法结构来解决这一问题。
2.2.1 依存句法分析 (Dependency Parsing)
相较于短语结构句法(Constituency Parsing),依存句法更关注词与词之间的二元支配关系,更适合处理多语言和长距离依赖。
在依存树中,核心动词通常作为根节点(ROOT),其他词通过特定关系(如 nsubj 主语、dobj 宾语、amod 形容词修饰)依附于核心词。
情感分析中的应用实例:
句子:“这部电影画面很美,但是剧情很烂。”
如果没有句法分析,简单的词袋模型可能会中和“美(正向)”和“烂(负向)”,得出中性评价。但在依存句法树中:
- “美” 通过
nsubj关系指向 “画面”。 - “烂” 通过
nsubj关系指向 “剧情”。 - “但是” 标记了转折关系。 这使得**基于属性的情感分析(Aspect-based Sentiment Analysis)**成为可能,系统可以精确输出:{画面: +1, 剧情: -1}。
2.2.2 基于转换的依存解析算法
目前主流的解析器(如 spaCy)采用基于转换(Transition-based)的算法。该算法包含三个核心组件:
- 栈(Stack):存储正在处理的词。
- 缓冲区(Buffer):存储待处理的词序列。
- 动作集合(Actions):包括 Shift(移入)、Left-Arc(左弧)、Right-Arc(右弧)。
解析过程即分类器根据当前状态预测下一个动作的过程,这一过程通常由深度神经网络(如 BiLSTM)来驱动。
2.3 命名实体识别(NER):锁定情感主体
在舆情监控或金融情感分析中,仅仅知道“很生气”是不够的,必须知道是对“谁”生气。NER 任务旨在识别文本中的专有名词,如人名(PER)、地名(LOC)、组织机构(ORG)等。
2.3.1 序列标注问题与 BIO 体系
NER 本质上是一个序列标注(Sequence Labeling)问题。常用的标注体系是 BIO:
- B-ORG:组织机构名称的开头(Begin)。
- I-ORG:组织机构名称的中间(Inside)。
- O:非实体(Outside)。
2.3.2 主流架构:BiLSTM-CRF
虽然 BERT 等预训练模型表现优异,但在资源受限场景下,BiLSTM-CRF 依然是工业界最经典的 NER 架构。
- 嵌入层:输入词向量 + 字向量(Character Embedding)。
- BiLSTM 层:双向长短期记忆网络。前向 LSTM 捕捉上文信息,后向 LSTM 捕捉下文信息,输出每个词对应各个标签的发射分数(Emission Score)。
- CRF(条件随机场)层:这是架构的关键。如果只用 BiLSTM + Softmax,模型可能会预测出非法的序列(例如
O后面直接跟I-ORG,这在逻辑上是不通的)。CRF 层引入了转移矩阵(Transition Matrix),学习标签之间的转移概率,从而从全局最优的角度约束预测结果。
CRF 的数学表达: 对于输入序列 $X$ 和预测序列 $Y$,其得分 $S(X, Y)$ 定义为:
$$ S(X, Y) = \sum_{i=0}^{n} A_{y_i, y_{i+1}} + \sum_{i=1}^{n} P_{i, y_i} $$
其中 $A$ 是转移矩阵,$P$ 是 BiLSTM 的发射分数。
2.3.3 代码实战:构建一个简单的 NER 抽取器
为了具体展示 NER 在情感对象提取中的作用,以下代码使用 spaCy 库演示如何从非结构化文本中提取实体并结合依存关系。
import spacy
加载英文模型 (需要预先运行: python -m spacy download en_core_web_sm)
nlp = spacy.load("en_core_web_sm")
def extract_sentiment_targets(text):
"""
分析文本,识别实体及其关联的形容词
"""
doc = nlp(text)
results = []
print(f"Analyzing Sentence: '{text}'\n")
print(f"{'Entity':<15} | {'Label':<10} | {'Dependency Head':<15} | {'Head POS':<10}")
print("-" * 60)
# 1. 遍历识别到的实体 (NER)
for ent in doc.ents:
head_token = ent.root.head
print(f"{ent.text:<15} | {ent.label_:<10} | {head_token.text:<15} | {head_token.pos_:<10}")
# 2. 简单的基于规则的情感关联:查找修饰实体的形容词
# 实际项目中这里会连接情感打分模型
sentiment_words = [child.text for child in ent.root.head.children if child.dep_ == 'acomp' or child.dep_ == 'amod']
if sentiment_words:
results.append({
"target": ent.text,
"type": ent.label_,
"context_sentiment_words": sentiment_words
})
return results
测试案例:科技评论
text_sample = "Apple released a new iPhone yesterday. The screen is brilliant, but Siri is stupid."
analysis = extract_sentiment_targets(text_sample)
print("\n[Extraction Result]")
for item in analysis:
print(item)
代码解析: 上述代码首先利用 NLP 管道进行实体识别(识别出 Apple, iPhone, Siri),然后利用依存句法树(Dependency Parsing)寻找这些实体在句法上的中心词或修饰词。例如,在 "Siri is stupid" 中,NER 识别出 "Siri" (ORG/PRODUCT),句法分析将其与形容词 "stupid" 关联。这就是现代情感分析系统“理解”文本的基础逻辑。
2.4 本章小结
本章详细探讨了自然语言处理的技术底座。从 Word2Vec 将离散符号转化为连续的语义空间,到依存句法分析解构句子的逻辑骨架,再到 NER 技术精准定位情感主体,这些技术共同构成了情感分析系统的“感知器官”。
然而,有了这些感知能力,机器还只是“看懂”了结构。如何真正像人类一样感知文本背后的喜怒哀乐?这需要引入更高级的情感建模方法和深度学习网络,我们将在第三章“情感分析的原理与深度计算中深入探讨。
