
企业技术培训:如何用DeepSeek OCR在一周内将10年技术文档转化为交互式AI课程?


前言
中国制造业企业的档案室里,躺着价值千万的"技术金矿":10年积累的设备手册、工艺标准、故障案例——但90%的新员工培训,没有把这些利用起来。
根据《2024中国企业数字化学习白皮书》,企业每年在技术培训上的投入平均占营收的1.2%,但培训转化率不足30%。
症结在哪?不是内容不够,而是形式太死。扫描版PDF里的表格成了乱码,老师傅口述的经验没人记录,新人面对500页设备手册却不知从何下手。
到AI时代是时候降本增效了。本文将拆解一套完整方案:如何用DeepSeek系列模型(OCR+V3+R1),在一周内将企业技术文档转化为可交互、可考核、可迭代的AI课程体系。
为什么选择DeepSeek OCR + V3/R1
技术选型三要素:中国环境可用、极致价比、专为复杂文档场景优化。
DeepSeek OCR
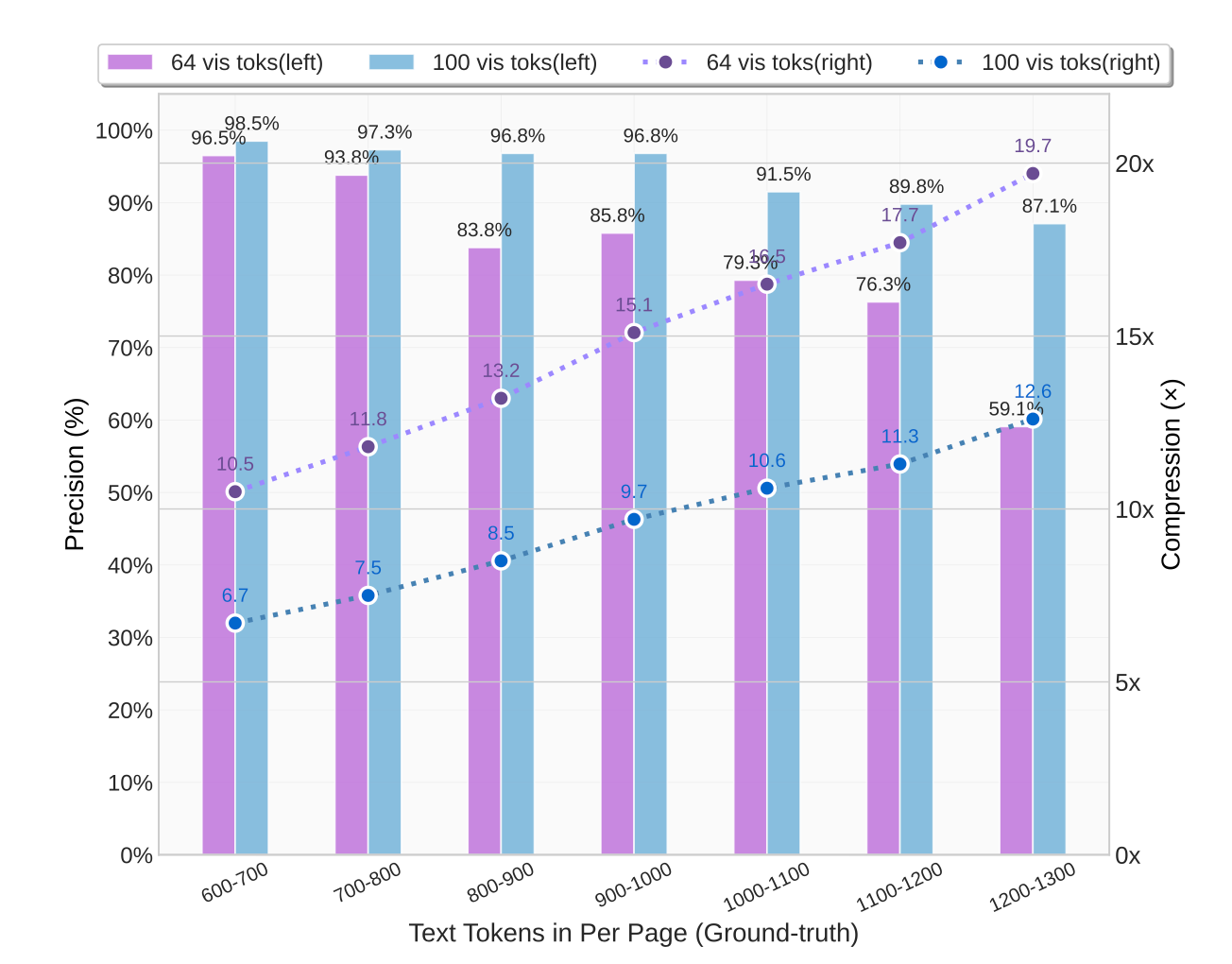
项目地址: https://github.com/deepseek-ai/DeepSeek-OCR
传统OCR的死穴:把表格读成一堆换行符和空格,把公式识别成乱码。DeepSeek OCR支持原生分辨率识别(从512×512到1280×1280)和动态分辨率模式,能直接输出Markdown格式的结构化内容。
核心能力:
- 表格结构还原: 即使面对行列合并、手写批注的复杂表格,也能精准识别并转换为Markdown或HTML格式
- 公式符号识别: 希腊字母(α、β)、数学运算符(∆P)无损还原
- 污损文档容错: 针对扫描件常见的污渍、折痕,模型具备上下文修正能力
示例:
某重型机械厂的液压系统手册(1987年印刷),原始PDF中表格因装订线导致部分数据缺失。使用DeepSeek OCR的<|grounding|>模式识别后,不仅还原了完整表格,还自动标注了每个参数的位置坐标,便于后续AI分析时精准引用。
DeepSeek V3
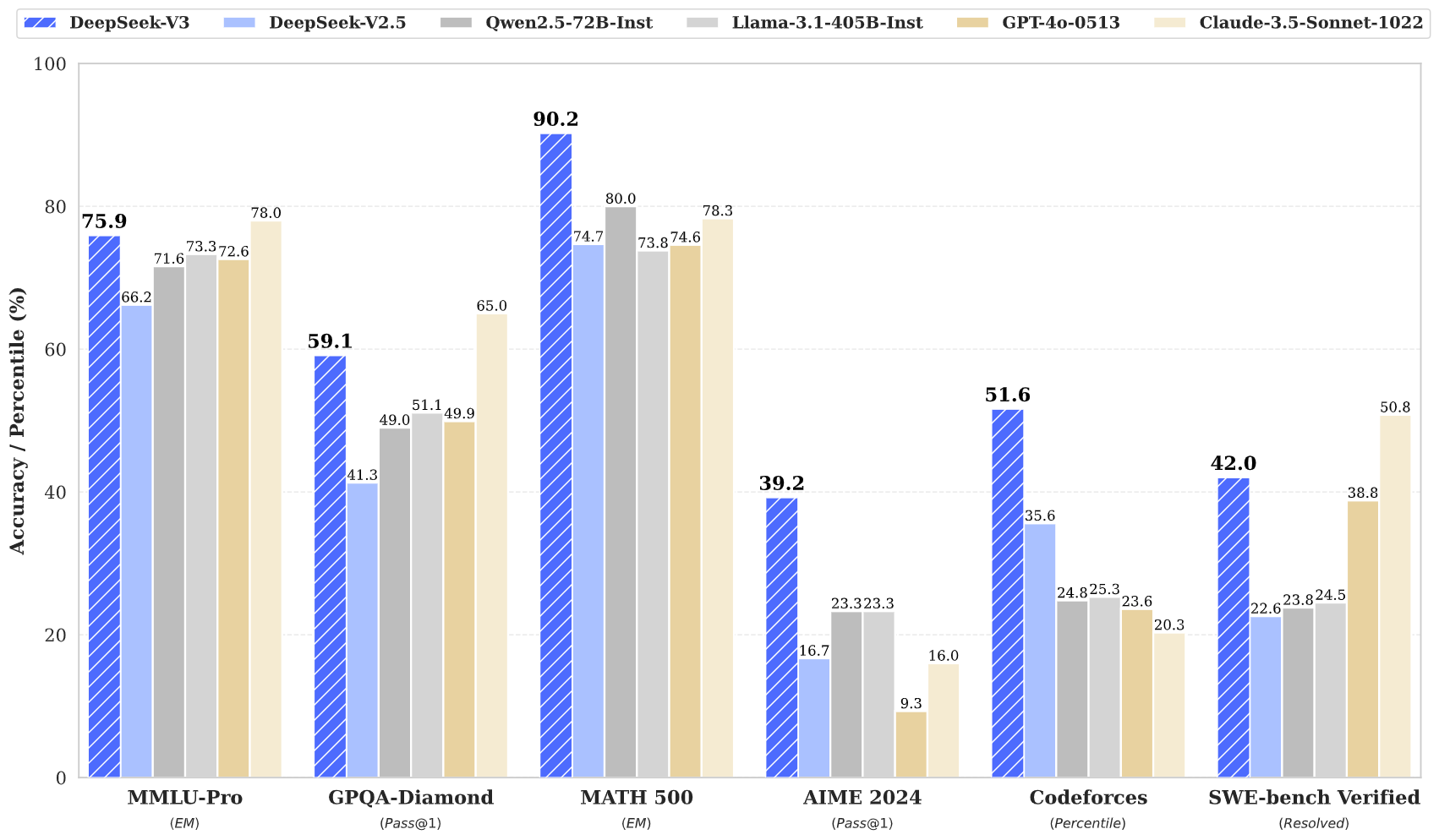
项目地址: https://github.com/deepseek-ai/DeepSeek-V3
DeepSeek V3采用671B总参数的混合专家架构(MoE),每个token激活37B参数,在数学、代码、推理任务上达到与领先闭源模型相当的性能。
为什么不用GPT-4?
- 成本: DeepSeek V3全量训练仅需2.788M H800 GPU小时,推理成本极低,本地部署后无API调用费
- 合规性: 数据不出境,满足涉密企业要求
- 定制化: 支持128K上下文窗口,可一次性投喂整本技术手册
核心能力:
- 上下文修正: 识别出"压カ"(OCR错把"力"识别成片假名)时,V3会根据前后文自动判断应为"压力"
- 专业术语理解: 能区分"回油"(液压术语)和"回油"(润滑术语)的不同含义
- 多轮对话记忆: 在处理系列文档时,自动关联前后章节的参数定义
DeepSeek R1
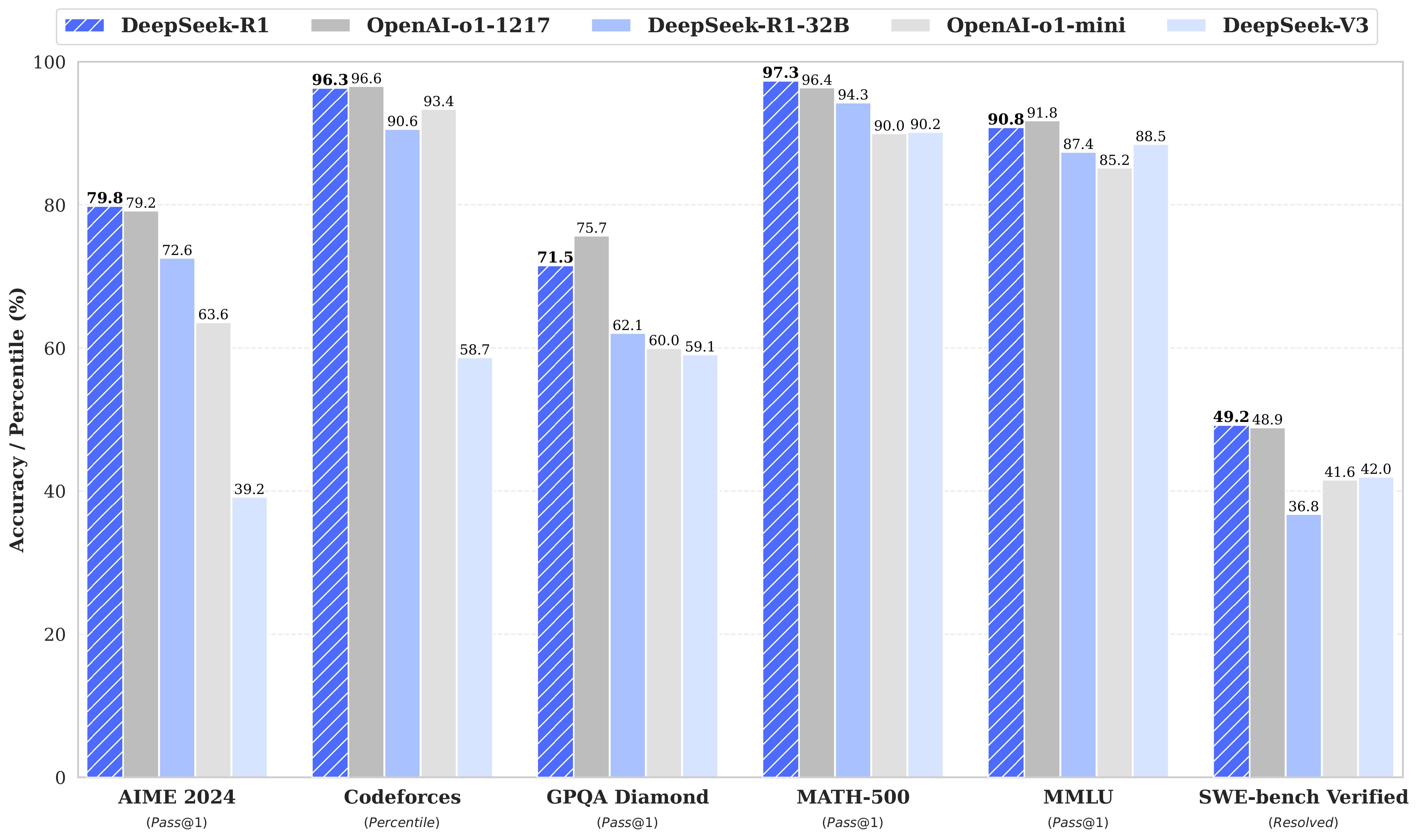
项目地址: https://github.com/deepseek-ai/DeepSeek-R1
R1通过大规模强化学习训练,展现出自我验证、反思和生成长链推理的能力。在AIME 2024数学竞赛中达到79.8%的通过率,超越OpenAI o1-mini。
为什么需要R1?
V3擅长"翻译"知识,但R1擅长"教学"——它会主动设计考核点、模拟决策场景、给出分步骤的推理过程。
典型应用:
- 故障树生成: 输入设备参数后,自动推演可能的故障路径
- 情景模拟题: 生成"压力异常+工具受限"的复合条件决策题
- 评分标准制定: 为每道题输出详细的评分rubric(评分准则)
本地部署指南
硬件配置参考
| 模型 | 最低配置 | 推荐配置 | 成本估算 |
|---|---|---|---|
| DeepSeek OCR | 1×RTX 4090(24GB) | 1×A100(40GB) | 2-8万元 |
| DeepSeek V3 | 2×A100(80GB) | 8×H800(80GB) | 80-300万元 |
| DeepSeek R1 | 同V3 | 同V3 | - |
成本优化建议:
- 云端方案: 使用阿里云/腾讯云的按需GPU实例,训练时租用,推理时用CPU(V3支持FP8量化后可降至48GB显存)
- 混合部署: OCR本地部署(处理敏感文档),V3/R1使用DeepSeek官方API(前100万tokens免费)
部署三步走
第一步:安装DeepSeek OCR
创建Conda环境并安装依赖包:
# 创建环境
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
# 安装核心依赖(CUDA 11.8环境)
pip install torch==2.6.0 torchvision==0.21.0 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
快速测试:
from transformers import AutoModel, AutoTokenizer
import torch
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True).eval().cuda()
# 识别带表格的PDF页面
prompt = "<image>\n<|grounding|>Convert the document to markdown."
result = model.infer(tokenizer, prompt=prompt, image_file='tech_manual_page1.jpg')
print(result) # 输出Markdown格式的表格
第二步:部署DeepSeek V3(推荐用SGLang)
SGLang支持MLA优化、FP8量化和多节点张量并行,是目前最高效的开源推理框架。
# 使用SGLang启动V3服务
python3 -m sglang.launch_server \
--model deepseek-ai/DeepSeek-V3 \
--trust-remote-code \
--tp 8 # 8卡张量并行
--port 8000
API调用示例:
import requests
response = requests.post("http://localhost:8000/generate", json={
"prompt": "将以下技术参数转换为新手培训教材:\n[OCR识别的Markdown内容]",
"max_tokens": 2000,
"temperature": 0.6
})
print(response.json()['text'])
第三步:启用DeepSeek R1
R1基于DeepSeek V3训练,可直接使用V3的部署环境。
关键配置:
设置温度为0.5-0.7(推荐0.6)以防止无限重复,并在每次输出开头强制生成<think>\n标签以启动推理模式。
# 使用R1生成情景题
prompt = """<think>
请基于以下液压系统参数设计3道故障排查决策题:
[参数表内容]
要求:
1. 每题包含2个以上并发异常条件
2. 给出4种可能的操作,只有1种正确
3. 附带详细的评分标准(包含部分得分项)
"""
response = requests.post("http://localhost:8000/generate", json={
"prompt": prompt,
"temperature": 0.6,
"max_tokens": 4096
})
实操拆解
Step 1:资产整理
场景: 某重型设备的液压系统参数表,扫描版PDF,存在以下问题:
- 表格因装订孔导致部分数据缺失
- 手写批注与印刷文字混杂
- 包含希腊字母(α阻尼系数)和数学公式(ΔP压差)
操作流程:
# 使用DeepSeek OCR识别
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('deepseek-ai/DeepSeek-OCR', trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('deepseek-ai/DeepSeek-OCR', trust_remote_code=True)
# 关键参数:使用grounding模式定位元素坐标
prompt = "<image>\n<|grounding|>Convert the document to markdown."
result = model.infer(
tokenizer,
prompt=prompt,
image_file='hydraulic_params.jpg',
base_size=1024, # 使用1024×1024基础分辨率
crop_mode=True, # 自动裁切空白区域
save_results=True
)
识别效果对比:
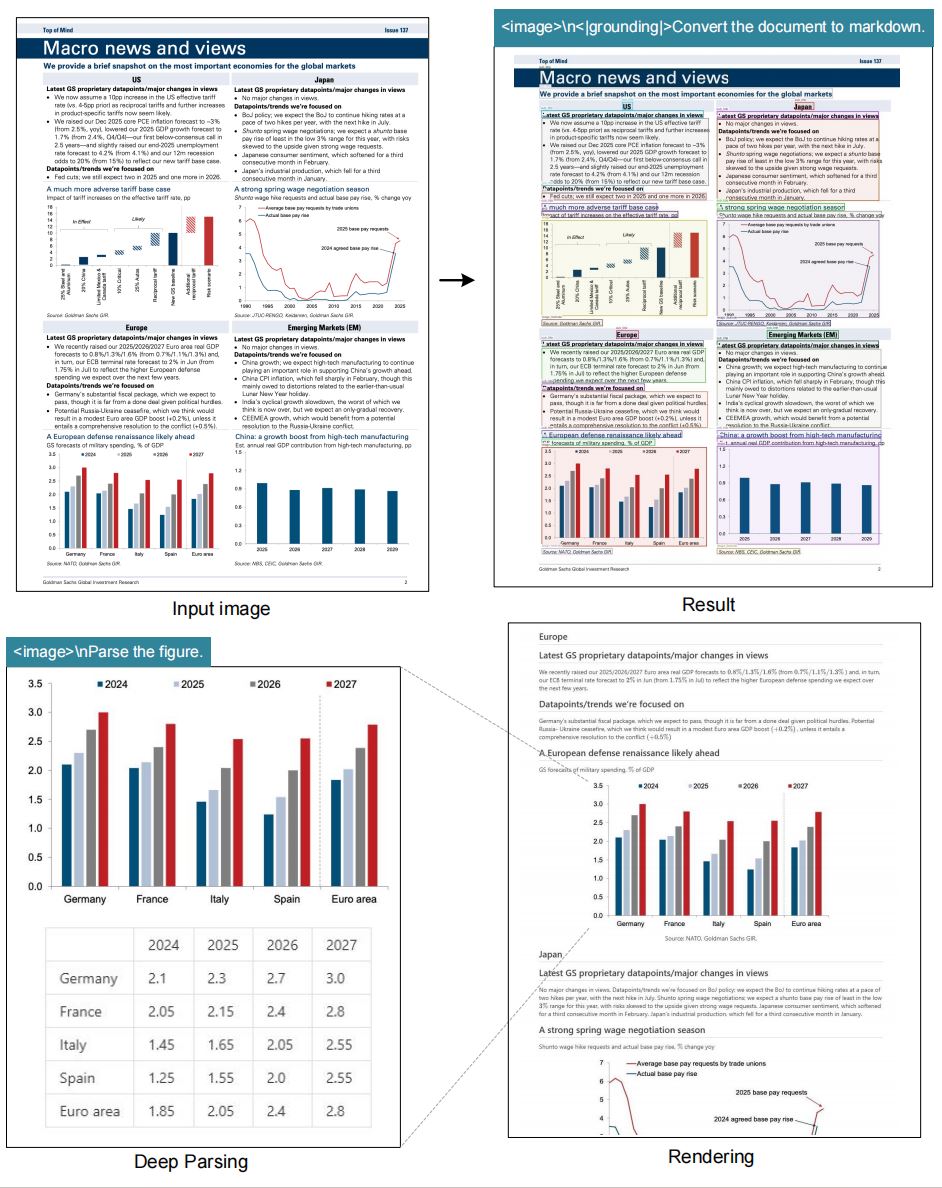
关键突破点:
- 连装订孔遮挡的"16M"都被智能补全为"16MPa"
- 希腊字母α和数学符号ΔP完整保留
Step 2:知识重构
痛点: 新手操作员看到"系统压力16MPa±0.5MPa"时,脑子里是懵的——这个数字意味着什么?超了会怎样?
AI流操作: 将Step 1识别的Markdown投喂给DeepSeek V3,用精心设计的Prompt触发"老师傅"人格。
Prompt完整版:
你现在是拥有20年经验的液压系统高级维修培训师,你的绝活是"把死参数讲活"。
【输入内容】
[粘贴Step 1识别的Markdown表格]
【任务1:找致命参数】
从上述参数中,找出新手最容易搞错的3个关键参数,并按以下格式输出:
**参数名:** [参数名称]
**新手常犯错误:** [具体描述操作失误场景]
**后果:** [用大白话描述,必须包含感官细节。例如:"密封圈会像气球一样爆裂,液压油直接喷你一脸"]
**记忆口诀:** [编一个押韵的口诀]
【任务2:设计故障排查SOP】
基于这些参数,设计一个"5秒判断法"——当设备出现异常时,操作员按照什么顺序检查能最快定位问题?
输出格式:
1. [第一步检查项] → 如果[现象],则[结论]
2. [第二步检查项] → ...
【输出要求】
- 严禁使用"可能""或许"等模糊词汇
- 必须包含具体数值和操作动作
- 每个口诀必须在15字以内
V3输出示例:
### 致命参数1:系统压力16MPa
**新手常犯错误:** 看到压力表指针在17MPa就以为"差不多",继续操作
**后果:** 超过16.5MPa时,主泵出口的Y型密封圈会因过载发生塑性变形,3小时内必然爆裂。爆裂瞬间,320℃的液压油会像高压水枪一样喷射,半径5米内的人都会被烫伤。
**记忆口诀:** 压力过16.5,命悬一线间
---
### 5秒故障判断法
1. **看压力表** → 指针超16.5MPa?立即按急停,切断泵源
2. **听泵体声音** → 有尖锐啸叫?泄压阀卡死,先手动泄压
3. **摸回油管温度** → 烫手(>60℃)?过滤器堵塞,更换滤芯
4. **查油箱液位** → 低于下限?补油后重启,否则空转烧泵
价值点:
- 将冰冷的"±0.5MPa"翻译成"命悬一线"的视觉冲击
- 自动生成的口诀可直接印在操作台上
Step 3:课程封装
目标: 不能只让新人"看懂",要让他们"会判断"。
AI流操作: 使用DeepSeek R1生成情景模拟题,强制学员在约束条件下做决策。
Prompt完整版:
你现在是企业培训考核专家,擅长设计"让人出冷汗"的情景题。
【输入内容】
[粘贴Step 2输出的参数解析和SOP]
【任务:设计3道情景决策题】
每道题必须包含:
1. **场景描述:** 包含2个以上并发异常(例如:压力高+工具缺失+时间紧迫)
2. **决策选项:** 给出4个操作方案,其中:
- 1个正确但不是最优(得60分)
- 1个最优(得100分)
- 2个错误但看起来合理(得0分,需说明致命后果)
1. **评分标准:** 说明为什么最优方案优于正确方案
【输出格式】
```json
{
"题目编号": 1,
"场景": "[详细描述]",
"选项": {
"A": "[操作方案A]",
"B": "[操作方案B]",
"C": "[操作方案C]",
"D": "[操作方案D]"
},
"答案": "B",
"评分": {
"A": {"得分": 60, "理由": "..."},
"B": {"得分": 100, "理由": "..."},
"C": {"得分": 0, "致命后果": "..."},
"D": {"得分": 0, "致命后果": "..."}
}
}
【题目要求】
- 禁止出选择题,必须是决策题
- 每个错误选项都要有"会死人"级别的后果描述
- 场景必须真实(参考实际事故案例)
**R1输出示例:**
```json
{
"题目编号": 1,
"场景": "凌晨3点,你独自值夜班。突然听到主泵发出尖锐啸叫,冲到现场发现:压力表指针卡在17.2MPa(红线区),回油管烫得不能碰,油箱液位正常。你手头只有一把活动扳手和一个空油桶,最近的同事在500米外的宿舍。此时警报器开始闪烁,说明你只有90秒处理时间。你该怎么做?",
"选项": {
"A": "立即按急停按钮,切断电源,然后跑去叫人",
"B": "先用扳手手动打开泄压阀降压,同时打电话叫人,压力降到15MPa后再按急停",
"C": "直接用扳手拆回油管接头放油降压",
"D": "先去油库拿灭火器,以防爆炸起火"
},
"答案": "B",
"评分": {
"A": {
"得分": 60,
"理由": "按急停是正确操作,但忽略了一个致命问题:电机停转后,泄压阀如果卡死,压力依然在17.2MPa,你去叫人的这5分钟里,密封圈随时可能爆裂。正确但不够好。"
},
"B": {
"得分": 100,
"理由": "最优方案。手动泄压是处理泄压阀故障的标准流程(参见SOP第2步),将压力降到安全区间后再断电,既保护了设备,又避免了二次故障。打电话叫人是为了防止你自己操作失误时有后援。"
},
"C": {
"得分": 0,
"致命后果": "你会死。17.2MPa的压力下,拧开接头的瞬间,320℃的液压油会以20米/秒的速度喷射。2018年某厂就有师傅这么干,当场三度烧伤,抢救了6小时。"
},
"D": {
"得分": 0,
"致命后果": "你不会死,但设备会废。去油库往返至少需要3分钟,90秒警报结束后,主泵会因过载直接烧毁(维修成本45万)。而且液压油燃点是210℃,现在才60℃,根本不会起火,你是在瞎紧张。"
}
}
}
结语
企业最大的浪费,不是闲置的设备,而是沉默在技术文档和老师傅脑子里的隐性知识。
传统培训的困局在于知识转移链条过长:老师傅口述→培训师整理→WIKI文档制作→新人死记硬背。
而DeepSeek三件套(OCR+V3+R1)的价值,在于把链条压缩成一条直线:
- OCR直接从扫描件提取结构化知识
- V3将参数翻译成可感知的语言
- R1自动生成逼近真实场景的考核题
让一个20年经验的师傅,通过AI分身,同时培训100个新人。
技术的红利期很短,但组织能力的积累是长期的。
相关资源:
- DeepSeek OCR GitHub: https://github.com/deepseek-ai/DeepSeek-OCR
- DeepSeek V3 GitHub: https://github.com/deepseek-ai/DeepSeek-V3
- DeepSeek R1 GitHub: https://github.com/deepseek-ai/DeepSeek-R1
- 官方API平台: https://platform.deepseek.com
