
Meta SAM3教程:打造一个“智能打码神器”


前不久,Meta 发布了 Segment Anything Model 3 (SAM 3)。如果说上一代 SAM 2 还是个需要你指令的工具人,那这次的 SAM 3 终于长脑子了。
你不再需要像个苦力一样一个个去点选目标,直接告诉它:“把所有的人脸、车牌或者屏幕都给我找出来”,它就能在图片里,视频里把这些东西精准的抠出来。
这就非常有意思了。既然它能精准识别,那我们能不能用它来干点实用的?比如——隐私保护。
做过视频后期的一定懂那种痛:给视频里的路人、车牌打码,纯体力活,逐帧画遮罩,没有技术含量。今天,咱们就用 SAM 3 搞一个自动隐私过滤器。
不搞复杂的配置,用 Python + Gradio 搓一个带界面的小工具。你上传视频,输入“faces”(人脸),它自动把所有人脸给你糊上高斯模糊。
废话不多说,直接开整。
什么是 SAM 3?
在写代码前,先用说说这模型强在哪。
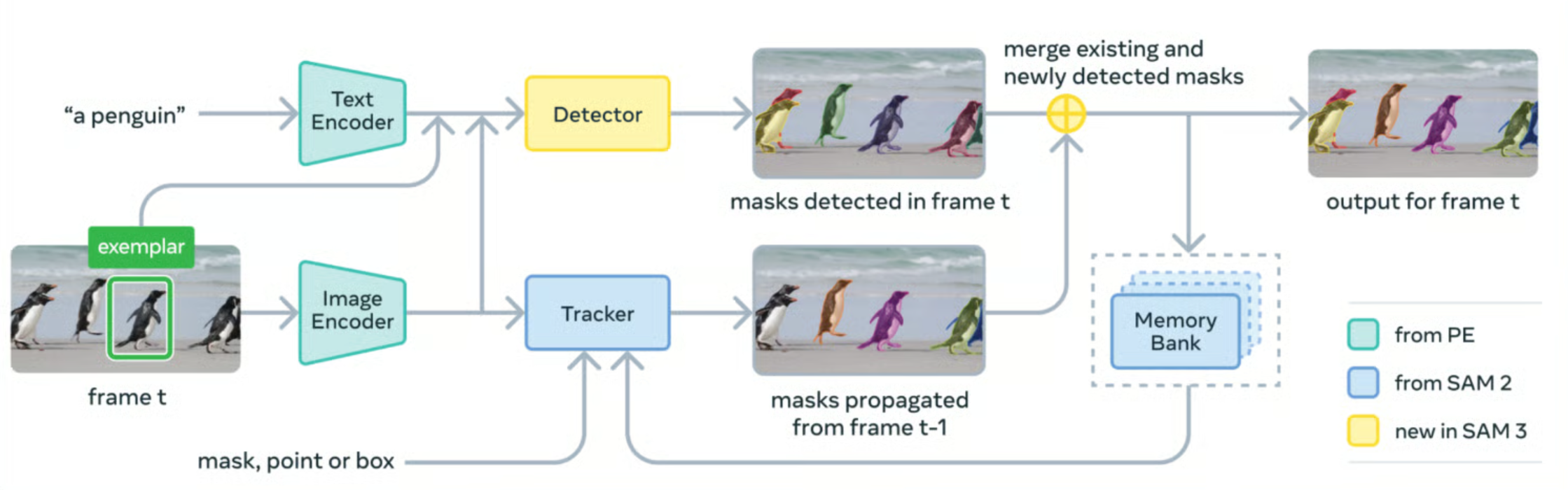
以前的 SAM,你得给它一个点,它才知道你要啥。SAM 3 搞了个融合技术:它把文本编码器和图像编码器缝合在了一起,外加一个类似 DETR 的检测器。
简单说,就是它既有了眼睛,也有了耳朵。你说“狗”,它就在脑子里检索“狗”的概念,接着在画面里把所有符合“狗”这个特征的像素点找出来。官方数据说,它在开放词汇分割上比之前的基线模型强了整整 2 倍。
这就为我们今天的“打码神器”提供了核心能力:能理解文本的批量识别。
实战:从零手开始
我们的目标很明确:做一个网页小工具,支持上传图片或视频,输入想打码的对象(比如 face),一键生成打码后的文件。 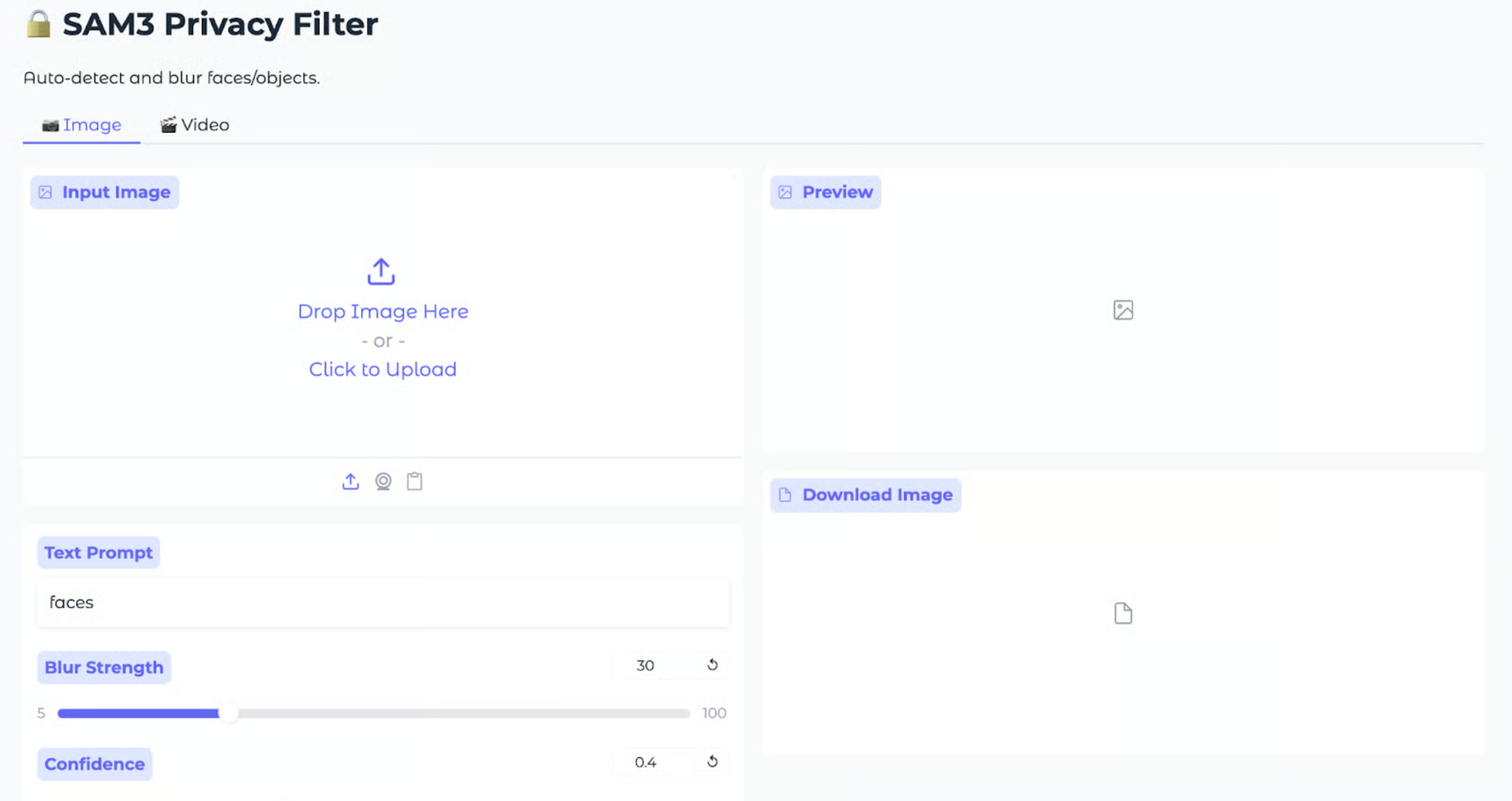
第一步:装环境
我们主要依赖 transformers 来调用模型,gradio 来做界面,以及 imageio 处理视频流。
直接在你的 Python 环境或者 Colab 里跑这段:
import subprocess
import sys
定义一个安装函数,省得一个个敲
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", "-q", package])
print("正在安装最新版 Transformers…")
注意:SAM3 太新了,必须用 Github 上的最新开发版,pypi 里的可能还没更新
install("git+https://github.com/huggingface/transformers.git")
pkgs = [
"accelerate",
"gradio", # 做界面的
"numpy",
"pillow", # 处理图片的
"torch",
"torchvision",
"imageio[ffmpeg]" # 处理视频的神器
]
for p in pkgs:
install(p)
print("环境配置搞定!")
如果运行失败,大概率是网络有问题,建议在你的命令行中执行一个简单的 Git 克隆命令来测试网络连接:
git clone https://github.com/huggingface/transformers.git
第二步:把模型加载进来
在这之前,我们需要Hugging Face 网站上接受模型的使用条款。 打开浏览器,访问模型页面:SAM 3  填写姓名和联系方式,申请获批后拿到令牌。
填写姓名和联系方式,申请获批后拿到令牌。  运行以下命令来安装 Hugging Face CLI:
运行以下命令来安装 Hugging Face CLI:
pip install huggingface-cli
运行登录命令:
huggingface-cli login
命令行会提示您输入令牌:
Token:
接着我们得写个类,把模型加载这一步封装起来。为啥?因为模型加载很慢,咱们不能每处理一张图就重新加载一次,得把它常驻内存。
这里有个细节:post_process_instance_segmentation 这个函数是关键,它负责把模型输出的一堆乱七八糟的张量,转换成咱们能看懂的“掩膜”(Mask)。
import torch
import numpy as np
from PIL import Image
from transformers import Sam3Processor, Sam3Model
class Sam3PrivacyEngine:
def init(self):
# 自动检测你有GPU还是只能用CPU
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model = None
self.processor = None
print(f"正在 {self.device} 上初始化 SAM3…")
try:
# 加载模型权重,第一次运行会自动下载
self.model = Sam3Model.from_pretrained("facebook/sam3").to(self.device)
self.processor = Sam3Processor.from_pretrained("facebook/sam3")
print("SAM3 就绪!")
except Exception as e:
print(f"模型加载翻车了: {e}")
def predict_masks(self, image_pil, text_prompt, threshold=0.4):
if self.model is None: return []
# 把图片和提示词喂给处理器
inputs = self.processor(
images=image_pil,
text=text_prompt,
return_tensors="pt"
).to(self.device)
# 关掉梯度计算,省显存
with torch.no_grad():
outputs = self.model(**inputs)
# 后处理:把结果变成掩膜
results = self.processor.post_process_instance_segmentation(
outputs,
threshold=threshold,
mask_threshold=0.5,
target_sizes=inputs["original_sizes"].tolist()
)[0]
# 把掩膜转成 PIL 图片格式,方便后续处理
masks = []
if "masks" in results:
for mask_tensor in results["masks"]:
mask_np = (mask_tensor.cpu().numpy() * 255).astype(np.uint8)
masks.append(Image.fromarray(mask_np))
return masks
初始化引擎,这步会下载模型,耐心等会儿
engine = Sam3PrivacyEngine()
第三步:“打码”的逻辑
拿到了 Mask 之后,怎么打码? 其实逻辑很简单:
- 先把原图搞一份全糊的版本(高斯模糊)。
- 把 Mask 叠加起来,做成一个“选区”。
- 在选区里显示模糊的图,选区外显示原图。
就像 PS 里的蒙版一样,代码实现也就几行:
from PIL import ImageFilter
def apply_blur_pure(image_pil, masks, blur_strength):
if not masks:
return image_pil
# 1. 制造一张全糊的图
blurred_image = image_pil.filter(ImageFilter.GaussianBlur(radius=blur_strength))
# 2. 合并所有掩膜
composite_mask = Image.new("L", image_pil.size, 0)
for mask in masks:
composite_mask.paste(255, (0, 0), mask=mask)
# 3. 移花接木:只把模糊图贴在掩膜区域
final_image = image_pil.copy()
final_image.paste(blurred_image, (0, 0), mask=composite_mask)
return final_image
第四步:处理视频流
图片处理很简单,那视频呢? 视频本质上就是一秒 24 张或者 60 张的图片。我们用 imageio 把视频拆成帧,一帧帧扔进去处理,再重新拼起来。
虽然听起来笨,但这是最稳妥的办法。
import imageio
def process_video(video_path, text_prompt, blur_strength, confidence, max_frames):
if not video_path: return None, None
reader = imageio.get_reader(video_path)
meta = reader.get_meta_data()
fps = meta.get('fps', 24)
output_path = "privacy_video.mp4"
# 设置视频编码器,确保兼容性
writer = imageio.get_writer(output_path, fps=fps, codec='libx264', pixelformat='yuv420p')
print("开始处理视频...")
for i, frame in enumerate(reader):
if i >= max_frames: # 演示用的,限制帧数防止跑太久
break
# 转换格式 -> 预测 -> 打码
frame_pil = Image.fromarray(frame).convert("RGB")
masks = engine.predict_masks(frame_pil, text_prompt, confidence)
processed_pil = apply_blur_pure(frame_pil, masks, blur_strength)
writer.append_data(np.array(processed_pil))
if i % 10 == 0:
print(f"已处理 {i} 帧...")
writer.close()
reader.close()
print("视频处理完毕!")
return output_path, output_path
图片处理逻辑也顺手写一下
def process_image(input_img, text_prompt, blur_strength, confidence):
if input_img is None: return None, None
image_pil = Image.fromarray(input_img).convert("RGB")
masks = engine.predict_masks(image_pil, text_prompt, confidence)
result_pil = apply_blur_pure(image_pil, masks, blur_strength)
return np.array(result_pil), "privacy_image.png"
第五步:Gradio 上线
逻辑都通了,最后用 Gradio 把它包起来。这样你就不需要天天对着命令行操作了,直接在浏览器里点点点。
import gradio as gr
with gr.Blocks(theme=gr.themes.Soft(), title="SAM3 隐私卫士") as demo:
gr.Markdown("## SAM3 隐私过滤器 \n 输入你想打码的内容(如 faces, license plates),AI自动帮你干活。")
with gr.Tabs():
# 图片模式
with gr.Tab("处理图片"):
with gr.Row():
with gr.Column():
im_input = gr.Image(label="上传图片", type="numpy")
im_prompt = gr.Textbox(label="想打码啥?(英文)", value="faces")
im_blur = gr.Slider(5, 50, value=20, label="模糊程度")
im_conf = gr.Slider(0.1, 1.0, value=0.4, label="识别置信度")
im_btn = gr.Button("开始打码", variant="primary")
with gr.Column():
im_output = gr.Image(label="效果预览")
im_btn.click(process_image, [im_input, im_prompt, im_blur, im_conf], [im_output])
# 视频模式
with gr.Tab("处理视频"):
with gr.Row():
with gr.Column():
vid_input = gr.Video(label="上传视频")
vid_prompt = gr.Textbox(label="想打码啥?(英文)", value="faces")
vid_blur = gr.Slider(5, 50, value=20, label="模糊程度")
vid_limit = gr.Slider(10, 300, value=60, label="最大处理帧数(测试用)")
vid_btn = gr.Button("开始处理视频", variant="primary")
with gr.Column():
vid_output = gr.Video(label="效果预览")
vid_btn.click(process_video, [vid_input, vid_prompt, vid_blur, im_conf, vid_limit], [vid_output])
启动服务!
demo.launch(share=True)
运行这最后一段代码,你会看到一个 URL。点开它,你就拥有了一个完全本地运行、基于 SAM 3 的隐私保护工具。
试着传一张全是人的合影,输入 faces,你会发现 AI 把每个人脸都给你遮得严严实实,而背景毫发无损。
写在最后
以前我们要实现这种视频处理,得训练专门的检测模型(YOLO之类)。
但 SAM 3 这种通用模型的出现,直接把门槛拉到了地板上。你不需要懂计算机视觉的底层原理,只需要会写几行 Python,调一下 Hugging Face 的库,就能做出一款企业级应用雏形。
代码都在上面了,赶紧动手试试吧。别光收藏不运行,跑起来才是你的。
