
谷歌 File Search 教程:别再手搓 RAG 了


做过 RAG(检索增强生成)开发的都知道,这东西听起来原理简单,找资料,喂 AI,生成答案,落地的时候才明白为什么被称为噩梦。
文档切片怎么才不丢语义? 向量数据库选 Pinecone 还是 Chroma? Embedding 模型更新了,老数据要不要重刷?
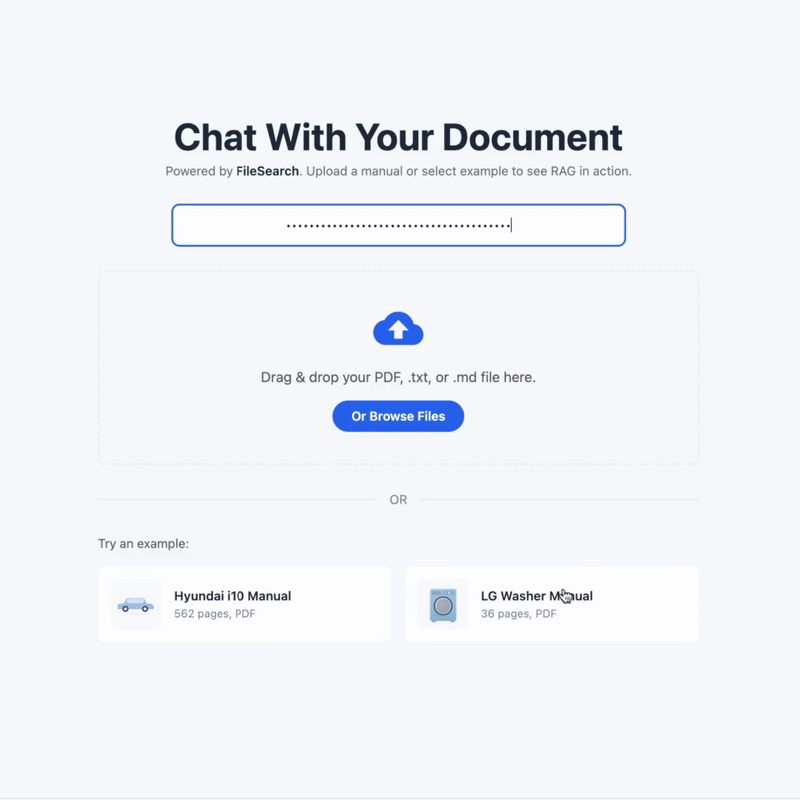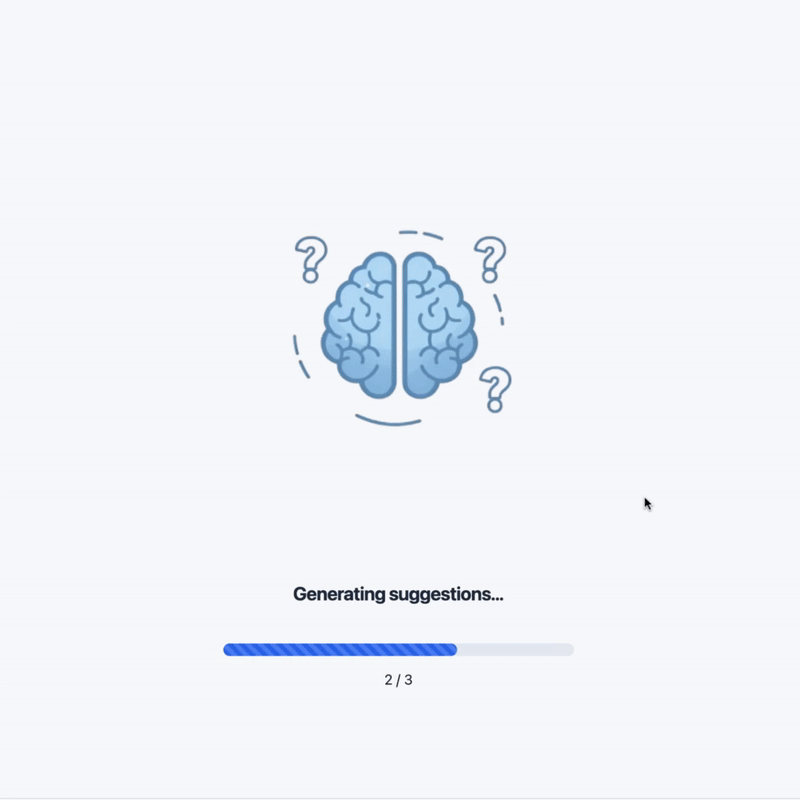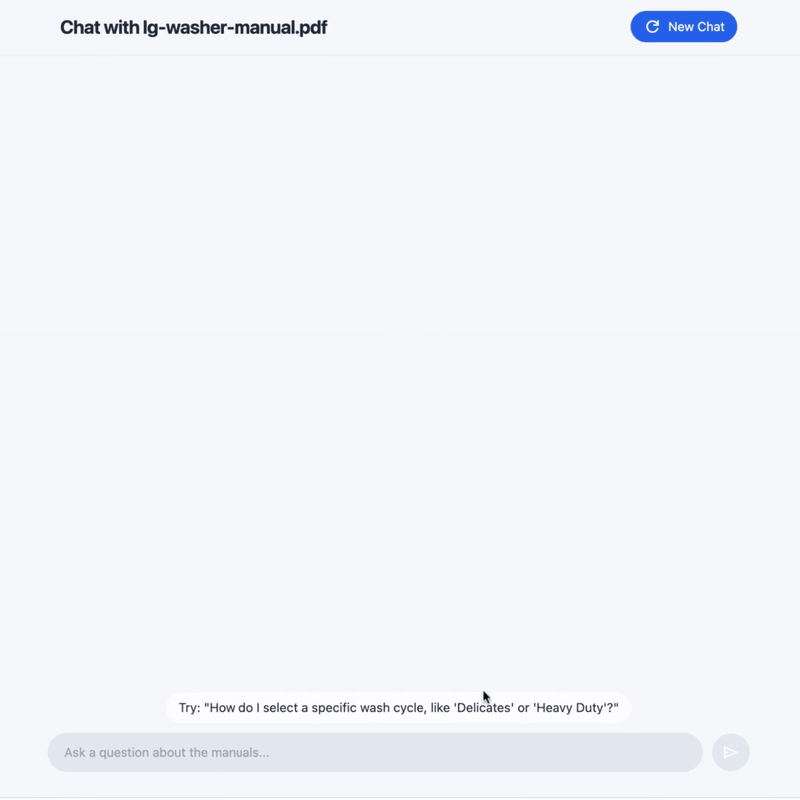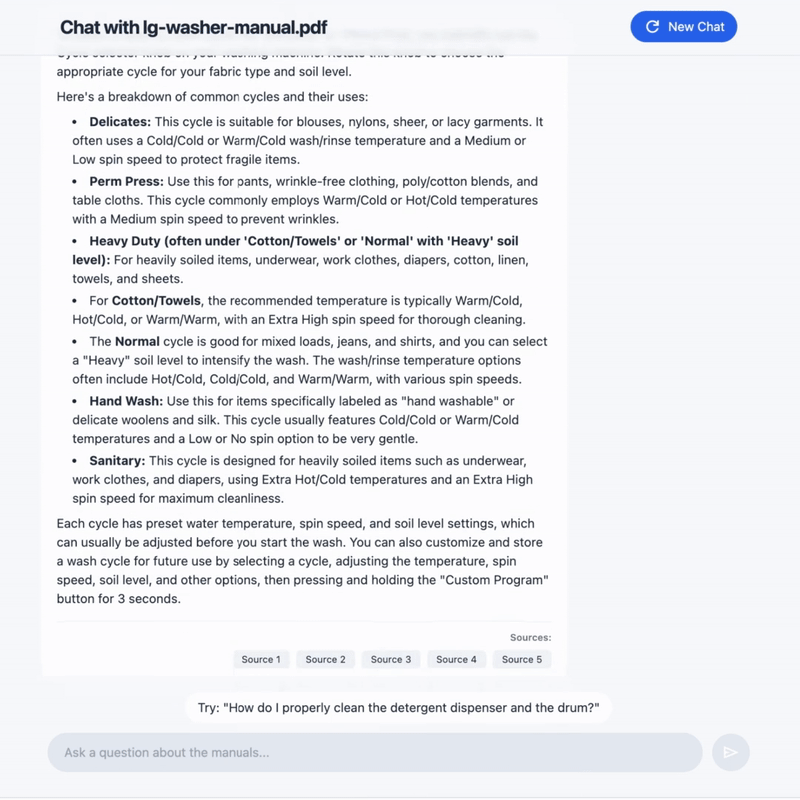
谷歌最近更新的 File Search Tool,我觉得是真正把 RAG 的门槛给降低了,操作起来不要太简单。
它提供了一个全托管的 RAG 系统。你不需要自己维护向量数据库,不需要管切片策略,也不需要写检索算法。你只需要把文件给它,直接问 Gemini,就能根据文档回答,标出引用来源。
今天,我们就以医疗文档助手,带大家跑通这个流程。我们将使用 FDA 的药品说明书作为数据源,看看 Google File Search 是如何处理这些专业数据的。
为什么要用全托管 RAG?
在动手写代码之前,我们要想清楚一件事:为什么要放弃自己搭建的系统?
如果你自己手搓一套 RAG,你需要维护下面这一长串链路:
- 解析器:把 PDF/Word 转成文本。
- 切片器:设计滑动窗口,防止上下文断裂。
- Embedding 流水线:调用模型把文本转成向量。
- 向量数据库:存储和索引这些向量(还得考虑扩容)。
- 检索器:写算法做语义匹配。
而 Google File Search 把这些全部封装起来。对于大多数应用场景,这种“开袋及食”的开发效率,让我们只需要关注两件事:上传什么数据,用户问什么。 
实战拆解
免责声明:本教程仅用于技术演示。医疗建议请务必咨询专业医生。
我们将构建一个系统,它能阅读 FDA 的药品说明书(如二甲双胍、立普妥等),并回答关于副作用、禁忌症的问题。
准备工作
首先,我们需要安装 Google 的 GenAI SDK。
pip install google-genai python-dotenv
接着,你需要一个 Google AI Studio 的 API Key。在项目目录下创建一个 .env 文件:
GOOGLE_API_KEY=你的_API_KEY
第一步:初始化客户端
这步很简单,加载环境变量并初始化客户端。
import os
import time
from dotenv import load_dotenv
from google import genai
from google.genai import types
load_dotenv()
初始化客户端,它会自动读取环境变量中的 API_KEY
client = genai.Client()
第二步:创建一个知识库
在 Google File Search 中,Store(存储库) 是核心概念。你可以把它理解为一个云端的文件夹,专门用来放你的私有数据。
这与普通的临时文件上传不同,Store 里的数据是持久化的。你只需要索引一次,以后就可以无限次查询,不需要每次对话都重新上传文件。
# 创建一个名为 "fda-drug-labels" 的存储库
file_search_store = client.file_search_stores.create(
config={"display_name": "fda-drug-labels"}
)
print(f"知识库已创建,ID 为: {file_search_store.name}")
这里的 store.name 类似于 "fileSearchStores/xxxx-xxxx"
建议在生产环境中把它存到数据库里,下次直接调用
第三步:上传并自动索引文档
这是最体现全托管优势的一步。
我们将上传三份药品说明书的 PDF。在这个过程中,Google 会在后台自动完成以下工作:
- 文档解析:提取文本。
- 智能切片:根据语义进行分块。
- Embedding:生成向量并存入 Google 的向量库。
为了方便演示,假设本地目录下有 metformin.pdf (二甲双胍) 等文件。
pdf_files = ["metformin.pdf", "atorvastatin.pdf", "lisinopril.pdf"]
# 实际上你可以去 FDA 官网下载任意药品的说明书 PDF 进行测试
for pdf_file in pdf_files:
print(f"正在上传并索引: {pdf_file} …")
# 上传文件到指定的 Store
operation = client.file_search_stores.upload_to_file_search_store(
file=pdf_file,
file_search_store_name=file_search_store.name,
config={"display_name": pdf_file.replace(".pdf", "")},
)
# 关键点:文件处理是异步的,我们需要轮询状态直到处理完成
while not operation.done:
time.sleep(2) # 每2秒检查一次
operation = client.operations.get(operation)
print(f"✅ {pdf_file} 索引完成!")
注意:不要省略那个 while 循环。大文件的索引需要时间,如果不等待直接查询,可能会查不到数据。
第四步:发起查询
数据准备好了,现在我们来问一个专业问题。
我们不需要自己去数据库检索,只需要在调用 generate_content 时,把我们刚才创建的 store 作为一个 Tool (工具) 传给模型。Gemini 会自动判断是否需要查阅文档。
query = "二甲双胍(Metformin)有哪些禁忌症?请详细列出。"
response = client.models.generate_content(
model="gemini-2.0-flash", # 推荐使用 Flash 模型,速度快且便宜
contents=query,
config=types.GenerateContentConfig(
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[file_search_store.name]
)
)
]
),
)
print("-" * 20 + " AI 回答 " + "-" * 20)
print(response.text)
回答示例:
二甲双胍在以下情况下禁用:
- 严重肾功能损害(eGFR 低于 30 mL/min/1.73 m2)。
- 急性或慢性代谢性酸中毒,包括糖尿病酮症酸中毒。
- 对二甲双胍过敏者。
第五步:验证引用
在医疗、法律等严肃领域,AI 的幻觉是不可接受的。我们需要知道 AI 的回答到底依据了哪段话。
Google File Search 的响应中包含了 grounding_metadata,它精确地指出了回答引用了哪个文件的哪一段内容。
print("\n" + "-" * 20 + " 引用来源 " + "-" * 20)
遍历所有的引用片段
if response.candidates[0].grounding_metadata.grounding_chunks:
for i, chunk in enumerate(response.candidates[0].grounding_metadata.grounding_chunks, 1):
source_title = chunk.retrieved_context.title
# 我们只打印前100个字符作为预览
source_text = chunk.retrieved_context.text[:100].replace("\n", " ") + "…"
print(f"[{i}] 来源文档: {source_title}")
print(f" 原文片段: {source_text}\n")
else:
print("本次回答未使用文档引用。")
输出结果会清晰地告诉你,第一条禁忌症来自 metformin.pdf 的第几页的哪段文字。这种可解释性是企业级应用最看重的功能之一。
进阶:多文档对比推理
RAG 不仅仅是搜索。Gemini 的强大之处在于它可以同时读取多个文档,并进行逻辑推理。
试着问它一个跨文档的问题: query = "同时服用立普妥(Atorvastatin)和二甲双胍会有药物相互作用吗?"
模型会自动从两份不同的 PDF 中提取信息,并综合生成答案。它可能会告诉你:“通常可以同服,但需要监测血糖...”并分别引用两份文档作为依据。
写在最后
通过上面几十行代码,我们实际上已经完成了一个生产级别的 RAG 后端核心逻辑。
如果我们用传统方法,达到同样的效果(解析、索引、语义检索、引用追踪),代码量至少是现在的十倍,而且还得维护一个独立的向量数据库实例。
不过谷歌 File Search 也有缺点。如果你需要自定义化,自己搭建 pipeline 依然是必要的。但对于绝大多数“基于文档回答问题”的需求来说,这种全托管方案是目前性价比最高的选择。
