
Anthropic 发布 AI Agent 上下文工程指南:让你的AI Agent更聪明

前言
如果你关注AI领域,大概率听说过“提示词工程”(Prompt Engineering)。在过去几年里,我们似乎都卷入了一场“文字炼金术”的比拼中:如何用最精妙的语言,让大模型输出最完美的结果。但现在,风向变了。Anthropic、Andrej Karpathy等行业先锋纷纷指出,真正的挑战早已不是写好那几句开场白,而是如何精心策划和管理AI在整个工作流程中接触到的所有信息——这就是“上下文工程”(Context Engineering)。

![]()
简单来说,提示词工程关心的是“说什么”,而上下文工程关心的是“在什么环境下、看到哪些信息后、再说什么”。 随着AI智能体(Agent)从简单的问答机器人,进化到能独立执行多步骤、长周期复杂任务(比如编码、研究、数据分析)的得力助手,后者的重要性变得愈发突出。
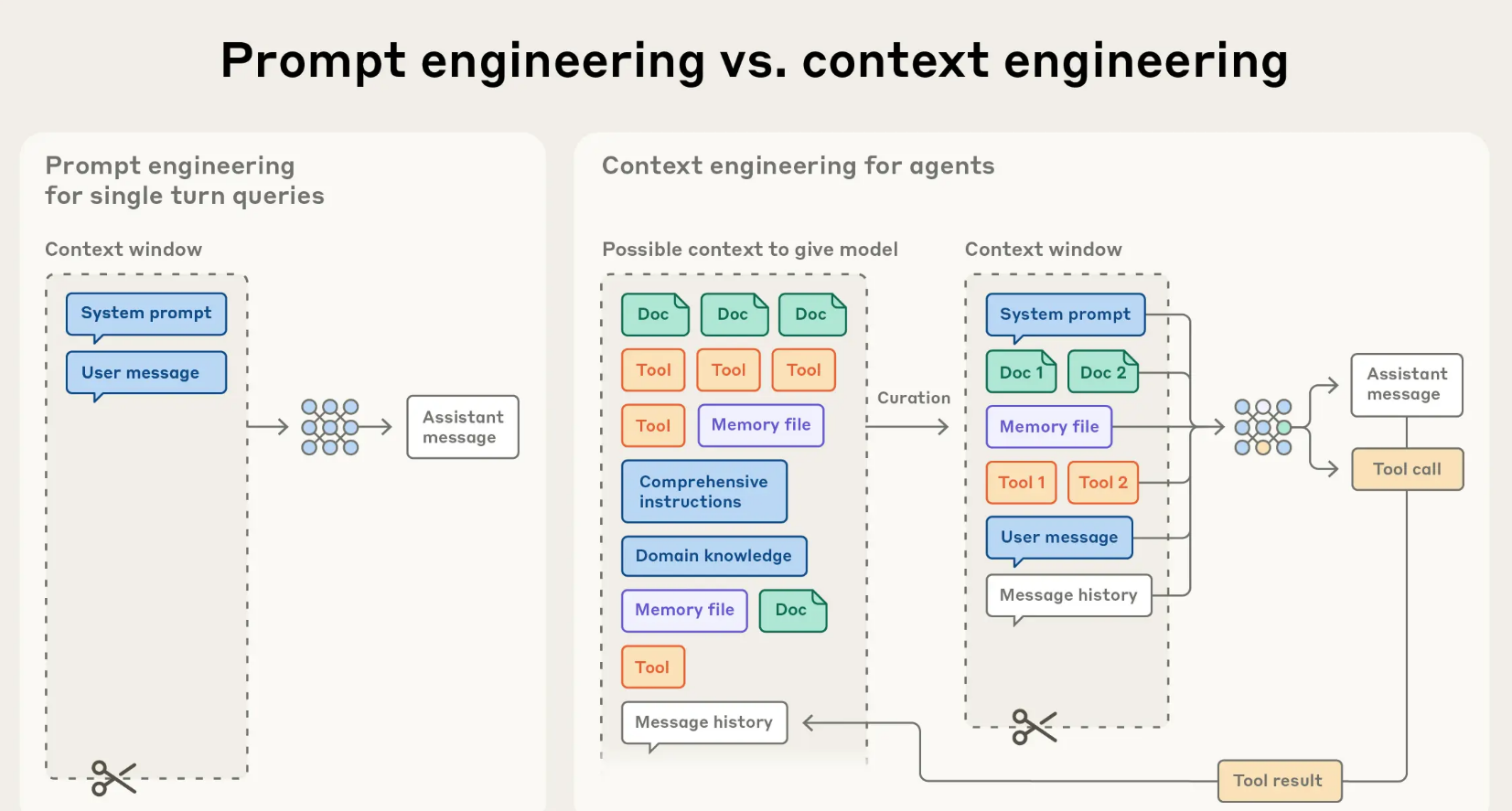
![]()
一、AI为什么会“健忘”?聊聊“上下文腐烂”
你是否有过这样的体验:和一个AI助手聊了很久,给了它很多背景信息,但聊到后面,它却把前面提过的关键细节给忘了?这并非你的错觉,而是一个普遍现象,技术上称之为“上下文腐烂”(Context Rot)。
这背后有两个核心原因:
(1)注意力的“预算”有限:大模型的底层是Transformer架构,它允许每个字(Token)关注到上下文里的其他所有字。这意味着信息量越大,需要处理的关系就越多(n个token有n²个关系),模型的“注意力”被稀释得越厉害。就像一个人参加一场信息量爆炸的会议,时间一长,就很难记住所有细节。
(2)训练数据的“偏科”:模型在训练时,见到的短文本远比长文本多。因此,它们天生更擅长处理短程依赖,对于需要贯穿几千上万字才能理解的“长程依赖”任务,能力会有所下降。
所以,我们必须把上下文看作一种像内存一样宝贵的、有限的资源。每往里增加一个token,都在消耗AI本已有限的“注意力预算”。上下文工程的核心,就是要做一个“注意力管理大师”。
二、如何打造一个高效的“上下文”环境?
一个设计良好的上下文,应该像一个干净整洁、工具齐全的工作台,让AI能高效地工作。我们可以从以下几个方面入手:
(1)系统提示:不做“霸道总裁”,也不做“甩手掌柜”
系统提示是给AI设定的“人设”和“行为准则”。这里有个“金发姑娘原则”——既不能太具体,也不能太模糊。
* 太具体:把复杂的if-else逻辑写进提示里,会让系统变得非常脆弱,难以维护。
* 太模糊:只给一些高大上的空洞指令,AI会不知所措。
最佳实践:用清晰的模块(比如用Markdown标题或XML标签)来组织提示,如`<背景信息>`、`<核心指令>`、`<工具使用指南>`、`<输出格式要求>`等。先从最精简的提示开始测试,然后根据AI的“犯错”情况,逐步补充和调整指令。
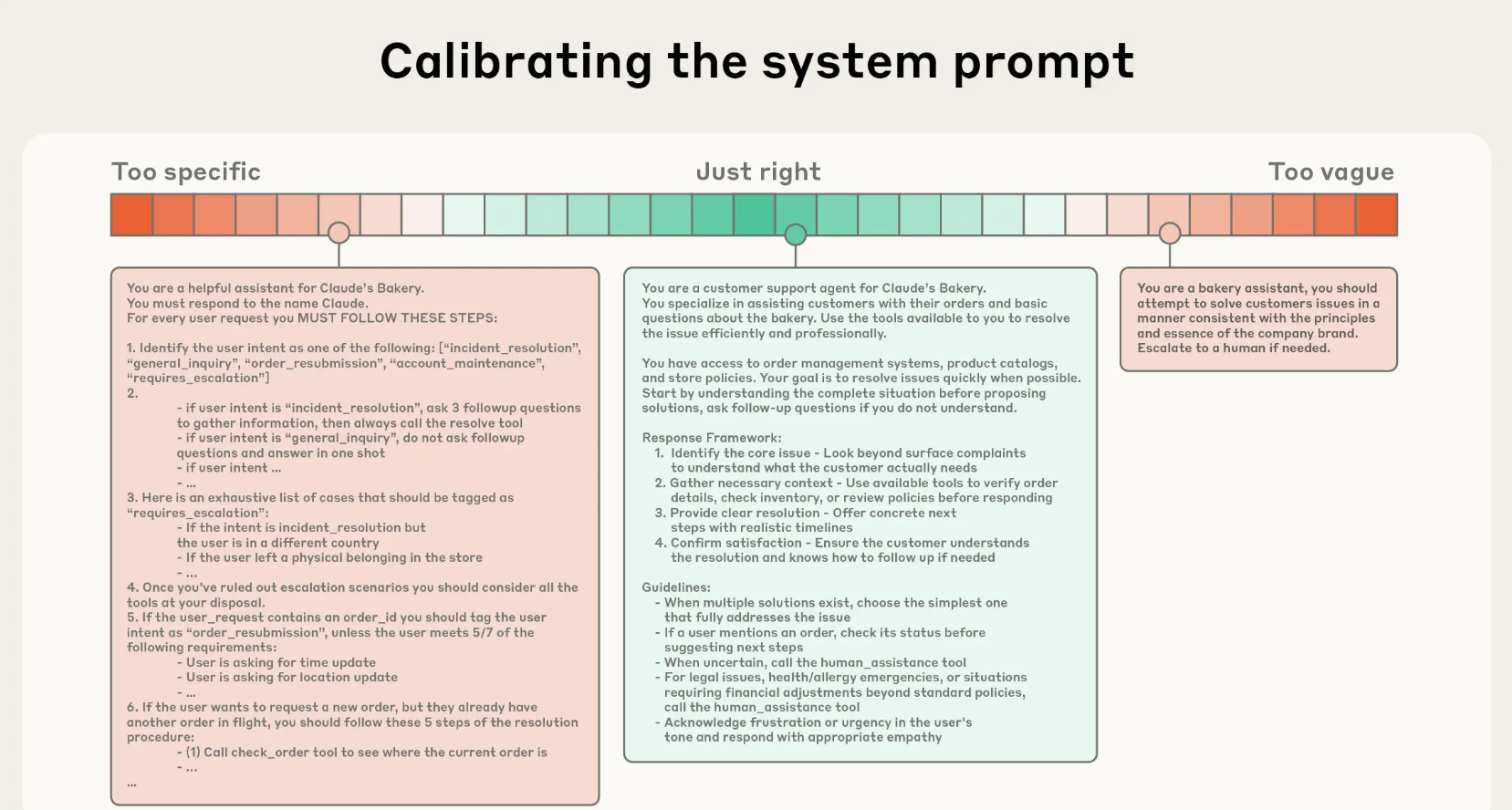
![]()
(2)工具设计:像设计一套优秀的API
工具是AI与外部世界交互的“手和脚”。设计工具时,要牢记“token效率”和“行为效率”。
* 功能正交:每个工具功能应该单一、明确,避免出现“这个任务到底该用A工具还是B工具”的模糊地带。如果人类都分不清,别指望AI能想明白。
* 返回精简:工具返回给AI的信息应该是结构化、高度提炼的,而不是把冗长的原始日志或整个网页一股脑塞回来,污染宝贵的上下文。
(3)示例(Examples):质量远比数量重要
“少样本提示”(Few-shot Prompting)是提升效果的利器,但这不意味着要给AI一本“错题大全”,把所有边缘案例都塞进去。
最佳实践:精心挑选几个具有代表性的、多样化的“输入-行为”范例,让AI“照葫芦画瓢”。一个好例子,胜过千言万语的规则描述。
三、让AI学会“随用随取”,而不是“一次塞满”
传统的做法是,在任务开始前,就把可能用到的所有文档、资料都通过RAG(检索增强生成)等方式塞进上下文。但更先进的“即时”(Just-in-time)策略,则是让AI自己去“取”信息。
我们只给AI提供一些轻量级的“指针”,比如文件路径、数据库查询语句、API接口等。让AI在需要时,通过工具(如`ls`查看文件, `head`预览内容, `grep`搜索关键字)自己去探索和获取数据。
这样做的好处显而易见:
* 信息永远是新的:避免了因信息过时导致的问题。
* 上下文保持“瘦身”:AI只加载当前步骤最需要的信息,极大节省了“注意力预算”。
* 利用环境信号:文件名、目录结构、修改时间等元数据本身,就为AI提供了决策的线索。
四、挑战“马拉松任务”的三大高级技巧
当任务周期非常长,比如持续数小时的代码重构或撰写深度研究报告,token总量远超上下文窗口上限时,怎么办?Anthropic提供了三大“长时记忆”法宝:
(1)压缩(Compaction):给记忆“瘦身”
在上下文窗口快满时,让模型自己对之前的对话进行总结,提炼出关键决策、待办事项、核心成果等,然后用这个“摘要”开启一个新的会话。最简单安全的压缩,就是直接丢弃掉历史工具的调用和返回结果,因为AI通常不需要再看一遍原始输出。
(2)结构化笔记(Structured Note-taking):AI的“备忘录”
让AI养成写笔记的习惯,定期把关键进展、中间状态、重要发现等写入一个外部文件(如`TODO.md`, `NOTES.md`)。当上下文重置或开启新会话时,AI可以先“阅读笔记”,从而无缝衔接之前的工作。Claude玩《宝可梦》的著名案例中,就是通过不断记录和读取自己的“游戏笔记”,才完成了长达数千步的复杂策略。
(3)子智能体架构(Sub-agent):团队分工,各个击破
与其让一个“全能”AI承担所有压力,不如组建一个“专家团队”。由一个“主智能体”负责顶层规划和任务分解,然后将具体的子任务(如“数据搜集”、“代码实现”、“报告撰写”)分派给多个“子智能体”。每个子智能体可以在自己的独立上下文中尽情探索,消耗大量token,最后只将提炼后的精华结果(通常几百到一两千token)返回给主智能体。这种“分而治之”的策略,能极大提升处理复杂研究型任务的效率和成功率。
结论:像珍惜“内存”一样,珍惜“上下文”
从“提示词工程”到“上下文工程”,标志着我们与AI协作方式的成熟。模型越强大,我们越不需要在“遣词造句”上花费过多精力,而应将智慧用于设计一个高效、清晰、低噪的信息环境。
无论你采用哪种技术,核心原则始终如一:用最小的高信噪比token集合,去最大化地激发期望的行为。 在可预见的未来,“把上下文当宝贝”这条铁律,将是构建一切高效、可靠AI智能体的基石。
参考原文: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
Claude 开发者平台: https://docs.anthropic.com
记忆和上下文管理 Cookbook: https://github.com/anthropics/claude-cookbooks/blob/main/tool_use/memory_cookbook.ipynb
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!
