
给图像生成配“阅卷老师”!RubricRL拒绝黑盒瞎蒙,用细粒度量表驯服大模型,指哪改哪!


论文链接:https://arxiv.org/pdf/2511.20651
亮点直击
- 提出通用化基于量规的奖励设计方案,可同时适用于扩散模型与自回归文生图模型;
- 构建提示词自适应、可分解的监督框架,显著提升模型训练的可解释性与组合能力;
- 设计用户可控可审计的交互接口,使强化学习奖励机制具备透明度与易扩展性。
- 通过动态生成包含明确视觉标准的评估量规来实现对齐目标,RubricRL让文生图强化学习训练过程变得更具可解释性、可扩展性与用户引导性,为视觉生成与人类意图的对齐提供了统一基础。
总结速览
解决的问题
- 奖励机制不透明:现有方法依赖“黑箱”式的单一标量奖励或固定权重复合指标,导致强化学习训练过程可解释性差。
- 奖励设计不灵活:固定的奖励权重或标准缺乏灵活性,难以适应不同提示词的多样化要求,也限制了用户控制和调整的能力。
提出的方案
- 核心框架:提出 RubricRL,一个基于评估量规 的奖励设计框架。
- 核心机制:
- 动态结构化量规:为每个提示词动态生成一个可分解的、细粒度的视觉标准清单(如物体、属性、OCR、真实感)。
- 自适应权重:根据提示词内容自适应地调整各标准的重要性权重。
- 可解释与用户可控:提供模块化的监督信号和允许用户调整奖励维度的接口。
应用的技术
- 多模态大模型作为评判器(如o4-mini):用于对量规中的各项细粒度标准进行独立、自动化的评估打分。
- 提示词自适应加权机制:动态计算并突出与当前提示词最相关的评估维度。
- 强化学习策略优化算法(如GRPO或PPO):利用RubricRL生成的可分解奖励信号来训练和优化生成模型。
达到的效果
- 提升模型性能:有效提升了生成图像在提示词遵循度、视觉细节和模型泛化能力方面的表现。
- 增强训练透明度:通过可分解的量规清单,使强化学习奖励的来源变得可解释、可审计,训练过程不再是一个“黑箱”。
- 实现用户控制:提供了一个灵活、可扩展的基础框架,允许用户根据需要直接干预和调整奖励的维度,实现了用户引导的对齐。
- 保证通用性:该方案被设计为通用框架,可同时适用于扩散模型和自回归文本到图像模型。
方法
本文采用自回归文生图模型验证RubricRL框架有效性,该框架同样适用于扩散模型。本节首先介绍RubricRL整体架构,随后详述基于量规的奖励设计、RL训练方法及动态滚轮采样。
整体架构
如下图3所示,给定文本提示p,我们首先将其令牌化为文本令牌序列,输入自回归文生图模型 以预测图像令牌序列,随后通过预训练冻结的VQ解码器生成最终图像I。
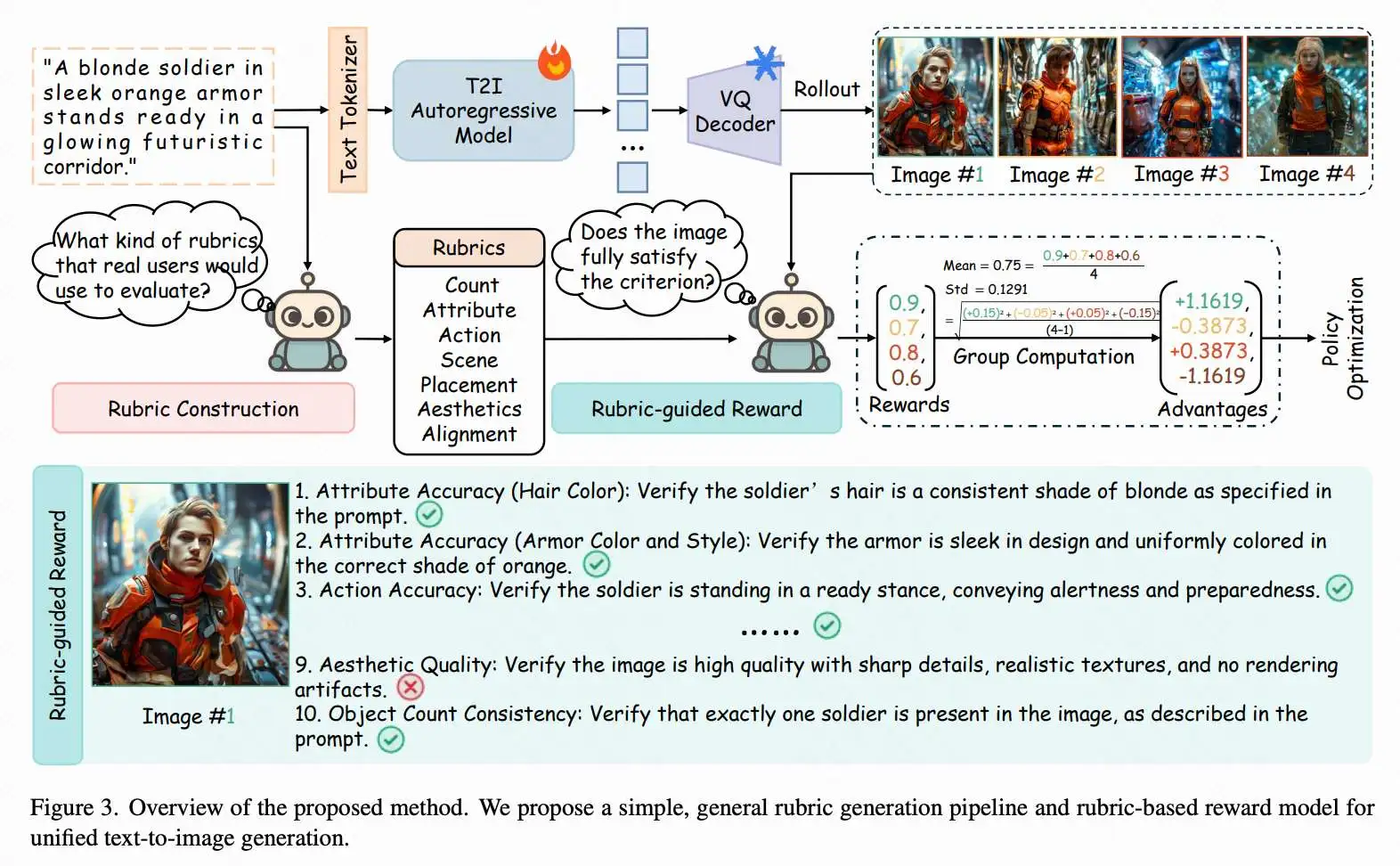
本文重点研究对 进行后RL微调以提升输出质量,其核心挑战在于设计有效、可靠且可解释的奖励函数。现有方法通常采用单一或多个专业模型评估图像质量的不同维度,例如基于CLIP的图文语义对齐奖励 、OCR准确率 及真实感等。但该方法存在显著缺陷:(1) 部署多个专业模型计算成本高且难以扩展至新维度;(2) 需要精细的奖励校准与权重调整。近期研究尝试从成对人类偏好数据学习单一奖励模型,虽简化了优化过程,但因标注成本高且可解释性差而扩展性有限。
受现代多模态大语言模型(如GPT-5)强大多模态理解能力启发,我们提出基于量规的简易统一奖励模型 。该模型使用具备推理能力的视觉语言模型替代多任务评估器集合,通过自动构建可解释的、提示词自适应的评估标准(称为“量规”)来捕捉每个特定提示的质量要求核心维度。
具体而言,给定文本提示p,量规生成模型G(通过大语言模型实现)会生成一组评估量规:

其中 定义了 M 个针对特定提示的标准,涵盖物体数量、属性准确性、文本/OCR保真度、空间关系、美学质量及风格一致性等维度。这确保了评估标准能动态适应每个输入提示的语义与粒度要求。
在强化学习中,其目标是调整模型参数 以在提示分布上最大化基于量规的期望奖励:
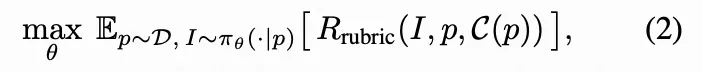
其中D表示提示词集合。一个 rollout 对应从 中根据 p 采样生成的单张图像,其提供的奖励信号用于指导策略更新。相较于多模型奖励系统,我们的基于量规的公式具有三大优势:(1) 简洁性:无需部署多个任务专用评估器;(2) 自适应性:为每个提示词动态生成量规,确保与多样化用户意图的相关性;(3) 可解释性:每个奖励组分均对应可读的评估标准,支持透明的模型诊断与可控的优化过程。
基于量规的奖励
基于量规的奖励函数分两阶段执行:首先,量规生成模型 G 解析用户提示p 并生成候选评估量规集合 ;其次,多模态LLM评分器实施基于量规的奖励 ,针对 中的每个量规对生成图像 I 进行评分。本文采用 GPT-o4-mini 同时承担这两个角色,既生成提示词专用量规,又提供逐准则判断以聚合为标量奖励。
量规构建。 给定用户提示 p,要求 GPT-o4-mini 生成量规列表。每个量规条目包含针对特定维度(如OCR对齐度、物体数量、空间关系、美学质量)的评估关键词,以及对应图像检查要点的简明描述。为促进多样性并减少量规生成时的位置偏差,我们在生成指令中随机排列评估维度,并对 GPT-o4-mini 进行多轮查询。每轮模型生成一组量规(每次查询要求10条;由于一个提示词可能描述多个物体或属性,模型可能为同一评估关键词输出多条量规以确保充分覆盖)。我们将所有有效的关键词-准则对跨轮次聚合为统一量规池,剔除模糊或格式异常的条目。最后,为消除冗余并聚焦关键信号,我们要求 GPT-o4-mini 选择与用户提示 关联最紧密的10条核心准则。
量规引导的奖励。 给定生成图像 、对应文本提示 p 及量规池 ,我们再次要求 GPT-o4-mini 为每条准则输出单一评分 ,以反映生成图像是否完全满足该量规要求( 表示满足, 表示不满足)。整体量规奖励通过以下归一化均值计算:
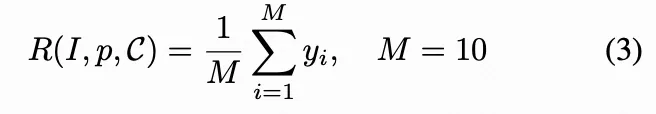
基于GRPO的强化学习
为将自回归图像生成器与基于量规的奖励对齐,我们采用分组相对策略优化(GRPO)——一种专为分组滚轮采样稳定优化设计的PPO变体。对于每个提示词,生成的滚轮采样集合构成一个分组,每个滚轮的奖励会相对于组内其他结果进行归一化处理,以降低方差并改进信用分配。具体而言, 令表示当前策略, 表示分组中第i个滚轮的量规奖励。GRPO通过以下公式计算相对优势度:
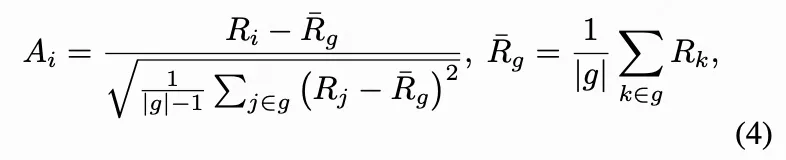
并通过优化类似PPO的剪切目标函数来更新策略:
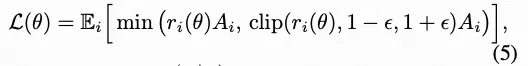
其中 , , 和 分别表示对应于第 i 个轨迹的采样动作与状态, 是 PPO 剪切参数。通过利用这种分组相对优势度,GRPO 稳定了跨提示词的训练过程,使模型对异构的奖励量纲和噪声评估具备鲁棒性。结合我们基于量规的奖励机制及下文将介绍的动态轨迹选择策略,我们发现 GRPO 能有效引导生成模型产出既符合人类偏好又具备高质量的输出图像。
动态轨迹采样
如上所述,GRPO 中的目标策略模型 通过采样多条轨迹来探索生成空间,每条轨迹产生一个用于计算优势度的奖励 。在原始 GRPO 设计中,同一提示词生成的所有 条轨迹被归为一组进行策略更新,即 。后续研究引入了过采样与过滤策略以提升训练效率。例如,DAPO采用提示词级过采样方法:它为每个提示词生成 N 条轨迹,并丢弃所有轨迹奖励均为 1 或 0 的提示词,从而仅保留难度适中的提示词用于策略优化。形式化而言,DAPO 选择性采样用于训练的提示词,同时仍使用每个保留提示词的全部轨迹进行 RL 更新。
本文提出一种新的轨迹级动态采样机制,该机制在单个提示词的轨迹内部进行选择,而非过滤整个提示词。具体来说,给定一个文本提示词,我们并非只采样 N 条轨迹,而是过采样 N' 条轨迹(N' > N),并选择性使用其中 K 条具代表性的轨迹子集进行策略更新。为平衡质量与多样性,采用混合选择策略:选取奖励最高的前 条轨迹,并从其余轨迹中随机采样剩下的 条以促进多样性。形式化而言,轨迹组g 按以下方式构建:
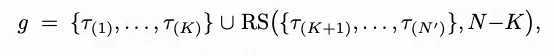
其中 RS 表示随机采样。实验表明该混合设计在稳定性与多样性间取得更优平衡,从而提升模型质量。因此,公式5的损失计算基于更具代表性且信息量更大的轨迹子集,相较于原始GRPO与DAPO的提示词级过滤方案,能实现更稳定高效的学习。
实验
实现细节
遵循SimpleAR方案,从JourneyDB与Synthetic dataset-1M选取11,000张图像,使用GPT-o4-mini重写描述以生成不同长度的提示词并在训练中随机选用。网络架构方面,采用经SFT训练的两个LLM作为骨干网络(Phi3-3.8B与Qwen2.5-0.5B),并分别使用LlamaGen的VQ解码器与Cosmos-Tokenizer作为视觉解码器。RL训练基于TRL框架实施,学习率设为 ,预热比例0.1。默认批次大小为28,训练3轮。两骨干网络的输出图像分辨率分别为512与1024。动态轨迹采样中,每个提示词从16条轨迹中筛选4条候选。推理阶段采用无分类器引导基于条件与非条件逻辑值指导图像生成。所有实验在8张NVIDIA A100 GPU上完成。
与前沿方法对比
我们在DPG-Bench与GenEval基准上,将RubricRL与多种奖励模型在两类文生图SFT模型上进行对比。对比奖励方法按设计理念分为:1) 单一专用奖励模型(CLIPScore、HPSv2、Unified Reward、LLaVA-Reward-Phi);2) 固定权重复合奖励指标(AR-GRPO与X-Omni)。为公平比较,通过复现其方法获取基线数据,并采用相同RL框架(GRPO)与设置,仅奖励函数设计存在差异。为更好理解RL带来的增益,还报告了初始SFT模型性能(各RL奖励均基于此独立应用)。基于Phi3与Qwen2.5骨干网络的量化结果分别呈现在下表1与下表2中。
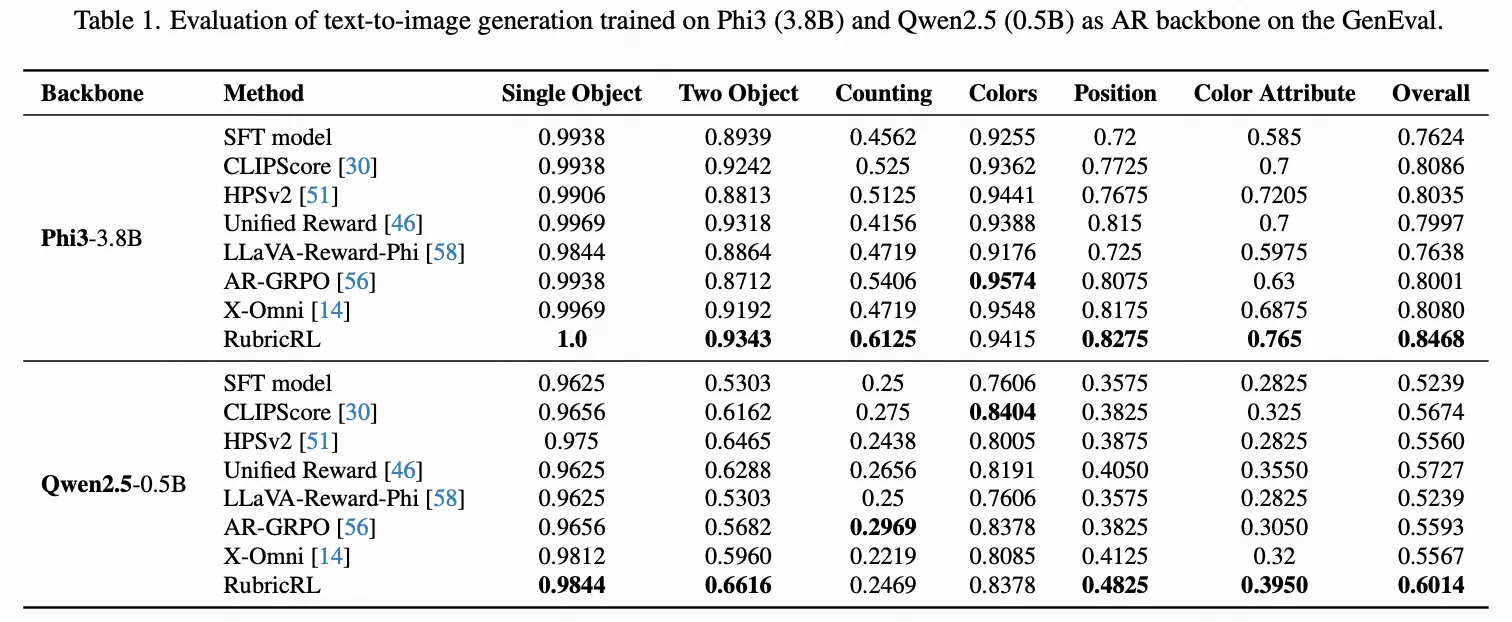
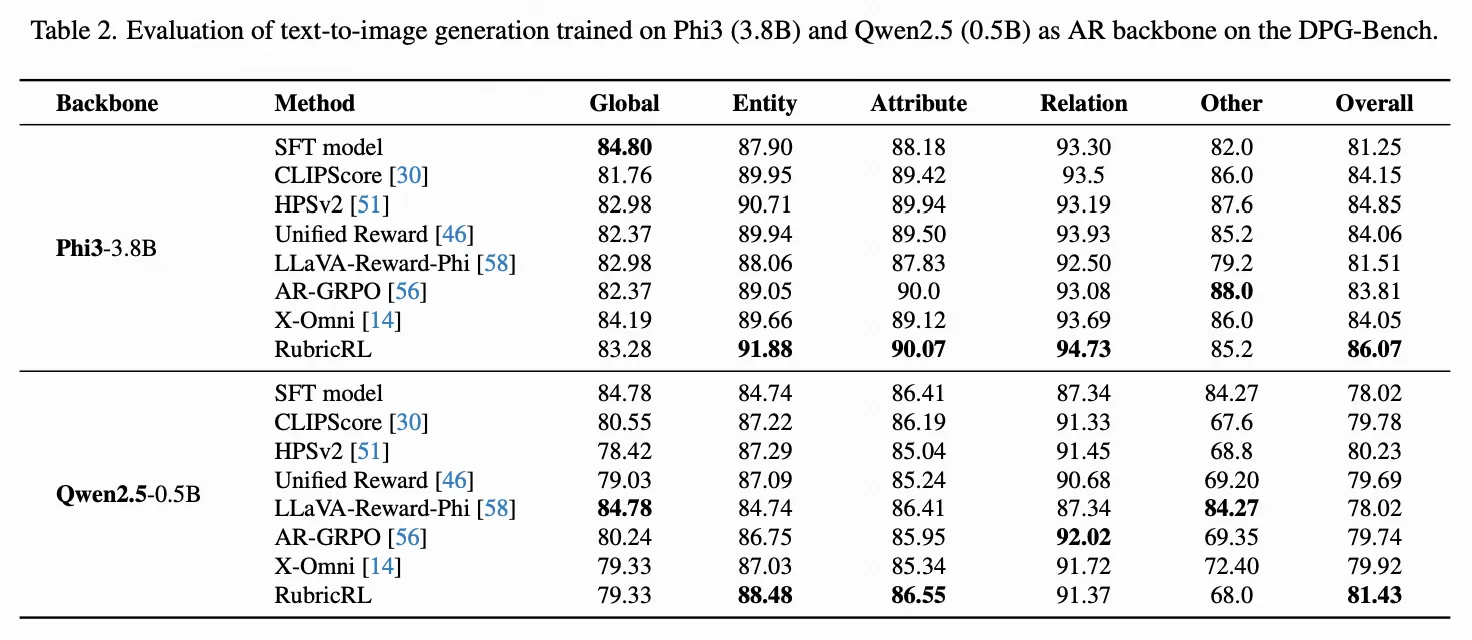
在GenEval上,遵循[10]采用提示词重写以确保评估一致性。结果显示:所有经过RL后训练的方法均持续超越SFT基线,证实了强化学习对图像生成质量的提升作用;且RubricRL取得最佳性能,在两个LLM骨干网络上均以约4%优势超越X-Omni,凸显了我们基于量规的奖励机制的有效性与泛化性。
消融实验
本节开展多组消融分析,默认实验基于Phi3并在GenEval基准上评估。
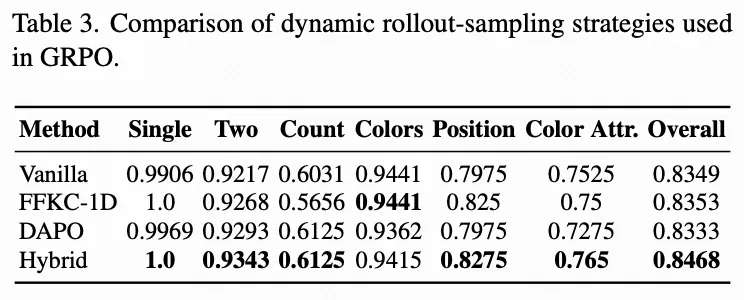
动态轨迹采样策略。 为探究动态轨迹采样中不同选择策略的影响,对比四种方法:未使用动态采样的RubricRL(原始版本)、FFKC-1D、DAPO及我们提出的混合策略,结果记录于下表3。具体而言,FFKC-1D同样过采样更多轨迹,随后通过先选取中位数轨迹(奖励最接近中位数的轨迹),再贪婪添加与已选轨迹奖励差异最大的样本来保持多样性。相较于我们的混合策略,FFKC-1D过度关注多样性而忽略了高质量轨迹的重要性。下表3显示我们的混合采样策略持续取得最佳性能,超越FFKC-1D、DAPO及直接使用四条轨迹而无动态选择的原始基线。值得注意的是,FFKC-1D与DAPO未能超越原始基线,表明其动态提示词采样与纯轨迹多样性驱动的采样策略未能为RL提供额外有效信号。相比之下,我们的混合策略有效平衡了对高奖励轨迹的利用与多样候选的探索,使策略模型能同时利用更高质量与多样性的样本,从而产生更有效的RL信号。
优势度归一化范围。 公式4中GRPO使用的优势度通过对组内轨迹奖励进行归一化(使用均值与标准差)计算。在我们的动态采样策略下,仅保留 个候选中的 条轨迹。这引发关键设计选择:归一化统计量(均值与标准差)应基于全部N'条轨迹计算,还是仅基于保留的N条?我们将这两种变体分别记为“全局归一化”与“局部归一化”。下表4显示“局部归一化”产生更优性能,这是因为在保留子集内归一化能更好反映指导学习的实际奖励分布,防止高方差或低质量轨迹扭曲梯度方向。

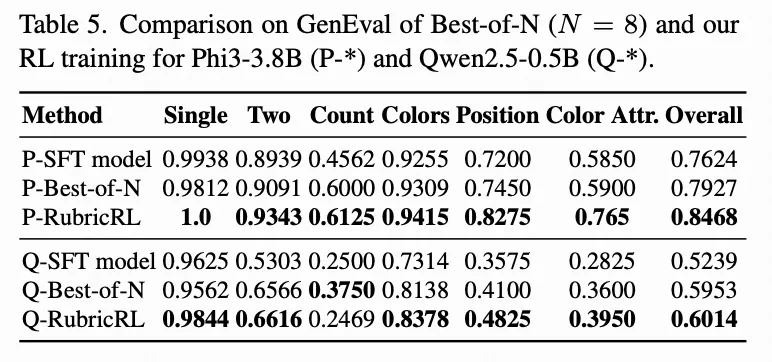
RubricRL vs 采用Best-of-N采样的SFT。 我们进一步将提出的RubricRL与在推理阶段采用Best-of-N采样策略()的SFT模型对比——该策略在先前研究X-Omni中被视为RL方法在语言任务中的“性能上限”。具体而言,对GenEval中每个提示词,我们首先生成量规,随后从SFT模型采样8条轨迹,每条轨迹使用基于量规的奖励评分,并选取前4条在GenEval上评估。下表5显示,尽管Best-of-N采样能显著获得更高分数,RubricRL仍实现明显提升,以超过5%的优势超越前者。该结果与X-Omni的观察一致,再次证实强化学习提供更有效的优化范式。
失败案例分析。 作为评分器,尽管GPT-o4-mini在评估生成图像质量方面具备高度通用性与强大能力,我们观察到其可能给出错误评分(如低估或高估物体数量,尤其在基础模型生成质量较差时)。下图4展示了GenEval计数子类中的若干典型失败案例,如交通灯附近冗余的立柱、交织的自行车及重叠的斑马。这些挑战性场景常误导GPT-o4-mini导致计数不准。但当基础模型生成更高质量图像时,该问题显著缓解。这解释了为何以Qwen2.5-0.5B为基础模型时,RubricRL在GenEval“计数”子类及DPG-Bench“其他”子类(均包含大量计数案例)的表现差于SFT基线;而使用Phi3-3.8B时该问题几乎消失,使RubricRL在计数相关类别中实现大幅性能提升。

可视化结果
下图5中进一步呈现RubricRL与其他基线方法的全面视觉对比。如图所示,经RubricRL训练的模型持续生成不仅更具美学吸引力、且与给定输入提示词语义对齐更佳的图像。为辅助解读,生成图像中未对齐或缺失的元素在图中通过加粗文本强调。例如下图5第三行中,SFT模型未能完整渲染黑色高顶礼帽,而多个基于RL的方法出现部分未对齐:LLaVA-Reward-Phi与Unified Reward生成的图像中黑色手提包未正确手持,甚至在某些案例中双爪描绘两个手提包却完全遗漏木质手杖。这些定性观察印证了RubricRL在增强模型遵循复杂细粒度指令及生成高质量提示一致图像方面的有效性。

结论
RubricRL——一个基于量规奖励的RL框架,为文生图任务提供提示词自适应、可分解的监督机制。通过显式构建可配置的视觉标准(如计数、属性、OCR保真度、真实感)并独立评分,RubricRL产生可解释的模块化信号,无缝集成于标准RL策略优化。实验结果表明RubricRL在增强文生图性能方面超越现有基于RL的方法。
参考文献
[1] RubricRL: Simple Generalizable Rewards for Text-to-Image Generation
