
影视录音“灾难现场”怎么救?这套AI组合拳堪比百万调音师!

做影视的朋友,大概都做过同一个噩梦:你花了十万块租来RED摄影机,布好大师级的光,演员情绪饱满到足以冲刺奥斯卡,可就在最关键的那句台词处,背景里忽然碾过一辆重型卡车,或者头顶的空调毫无预兆地“嗡”一声响起。
在过去,这意味着什么?要么烧钱重拍,要么硬著头皮进棚做ADR,且不说额外成本,演员事后补录的情绪,往往再也接不上最初的瞬间。
但现在,进入“后AI时代”,如果你硬盘里还躺著几条因音质太差而差点废弃的素材,请先别急着删除。
今天,我们要聊的,正是如何用AI工具把这些“废片”里的声音救回来,甚至还能顺手把环境音效一并重塑。这套工作流核心只围绕三步:智能修复、精准分离、氛围生成。

🎯第一步:起死回生的“手术刀”——Adobe Podcast AI
(专注解决:环境嘈杂、人声空洞、距离感过强)
以前我们用降噪插件,好比是做“减法”,小心翼翼地把杂音抠掉。但Adobe Podcast AI的思路完全不同,它更像是在做“加法”和“重塑”。它不止于消除噪音,更致力于重建一个清晰、饱满的人声。
它是怎么做到的呢?
简单来说,Adobe的语音增强技术,并非传统意义上的均衡器调节。它通过深度学习大量的播客和人声数据,能够分析你那段糟糕录音中的频谱,识别出人声部分,然后用AI“脑补”出丢失的高频和低频细节,让原本听起来像是在浴室里用手机录的声音,瞬间变成在专业录音棚里用舒尔SM7B录出来的质感。
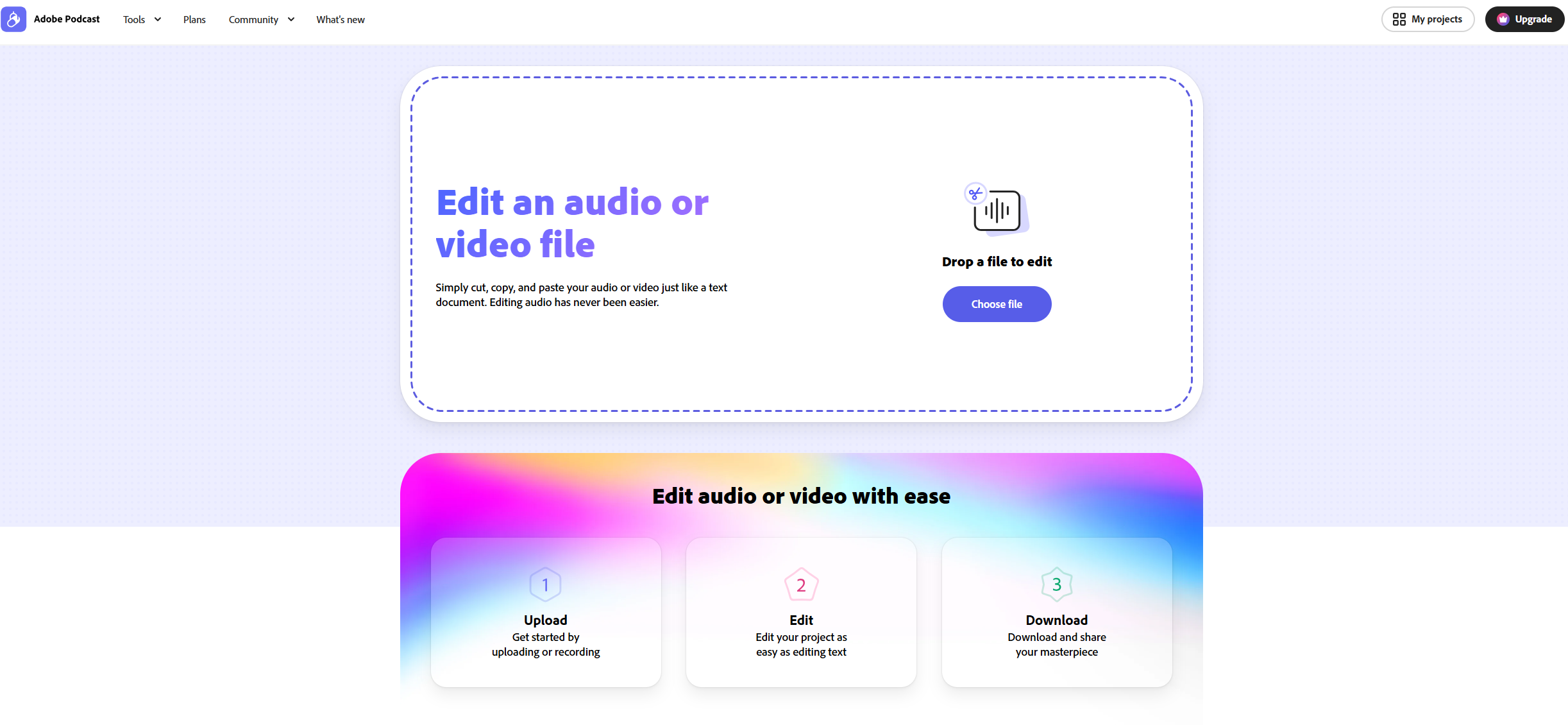
📢 【保姆级实操教程】如何把手机录音变“棚音”
这里我们以一个典型影视拍摄场景为例:你在街边拍摄纪录片采访,风声很大,人声忽大忽小。
•准备素材:导出你的音频文件,建议使用WAV或MP3格式。
•访问工具:打开浏览器,搜索 Adobe Podcast,进入官网找到语音增强功能区。
•一键上传与处理:直接将音频拖入上传框,你会看到一个波形图开始跳动,系统提示“Enhancing speech...”。
•调节“AI浓度”:处理完成后,你会看到一个百分比滑块,通常默认90%或100%,但千万不要无脑100%。如果拉得太满,人声会变得过于“磁性”和机械,甚至会出现吞字现象,导致“恐怖谷”效应,听起来像个机器人。对于影视对白,建议将强度控制在 60%-75% 之间。这样既去除了底噪,又保留了一点点现场的“空气感”,让声音听起来真实而不虚假。
•下载与融合:点击Download,回到你的剪辑软件(Premiere/DaVinci/FCP),将处理后的音轨和原始音轨放在上下两轨。你可以保留原始音轨的一点点底噪(比如音量开到-25db),叠加AI修复后的干声。这样出来的声音,既清晰又自然,不会显得跟画面完全脱节。
🎯第二步:声音的“图层分离”——LALAL.AI
(专注解决:背景音乐干扰、人声与环境音混杂)
Adobe Podcast虽然强,但它是个“大力出奇迹”的工具,有时候会把背景里你需要的声音,例如关门声、脚步声也当成噪音抹掉。这时候,你就需要LALAL.AI——一款基于凤凰算法的音频分离工具。
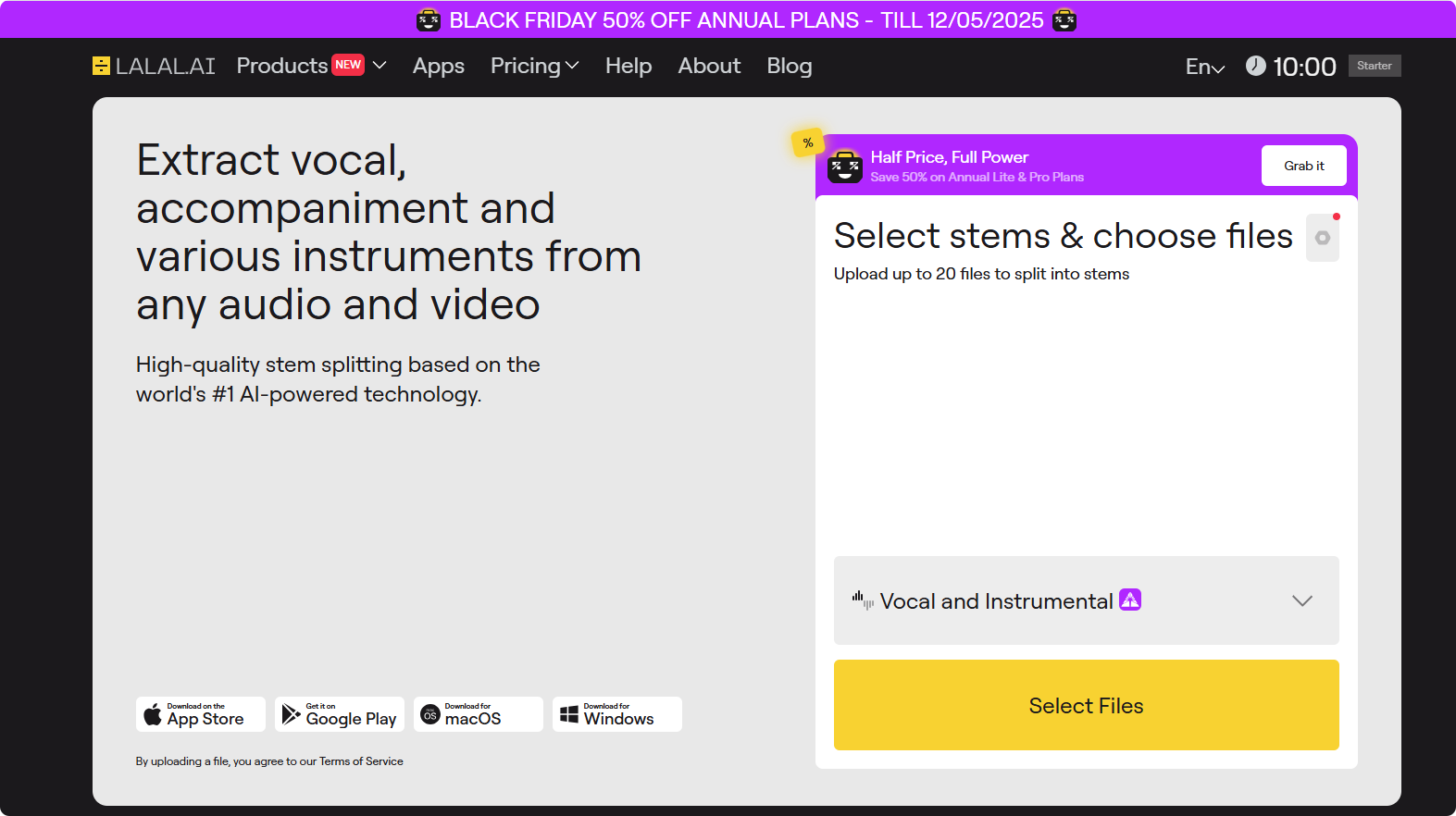
应用场景:
你拍纪录片时,采访对象背景里有一家店在放流行音乐(有版权风险),或者你想把现场嘈杂的人声去掉,只保留环境音作为空镜头的音效。
实操逻辑:
进入LALAL.AI官网,上传你的复杂音频,选择分离模式。它远不止于传统工具简单的“人声”和“伴奏”分离,而是能够将音频精准地剥离成独立音轨,包括人声、鼓、贝斯、钢琴,乃至更新的风声与合成器音效。
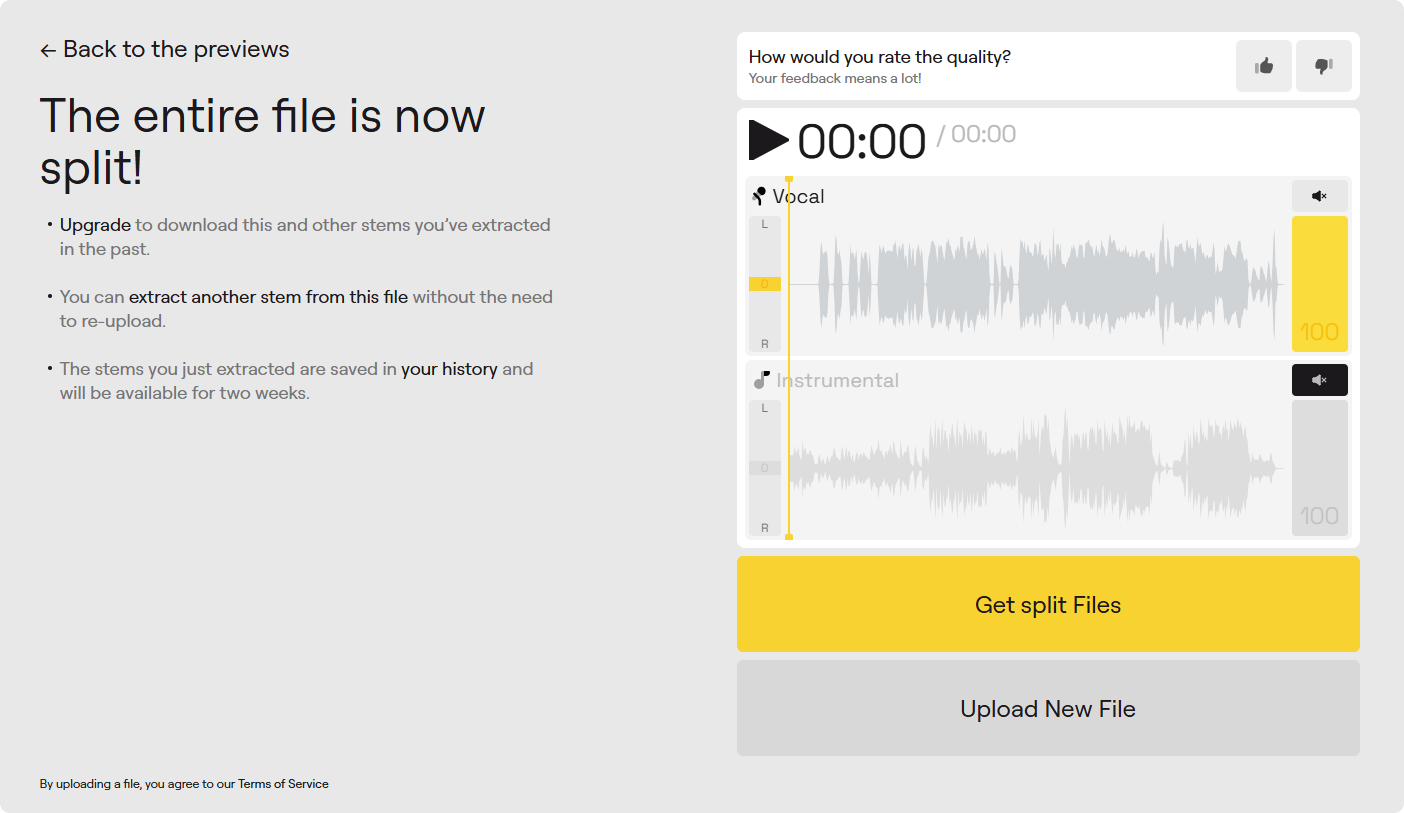
实战技巧:如果你想挽救一段背景音乐干扰的对话时,选择“Vocal and Instrumental”,AI便会将两者拆成两条独立的音轨。你只需下载那份纯净的人声轨,用 Adobe Podcast 做增强处理;而那条分离出来的伴奏轨,如果不需要,直接静音就好。如果想保留一些环境氛围,就在剪辑软件里单独把它的音量拉低一点。
这在以前,需要音频工程师看着频谱图一点点手绘擦除,现在只需30秒。
🎯第三步:无中生有的“情绪大师”——AIVA / Mubert
(专注解决:低成本配乐、版权黑洞、时长不匹配)
声音修好了,接下来是“设计”。
很多独立影视导演在剪辑时最头疼的就是找BGM。要么太贵,要么太俗,要么时长对不上,这时候,生成式AI音乐就是你的救星。
1. AIVA:为你的故事谱写交响乐
如果你在做一部剧情片或情感浓烈的纪录片,需要管弦乐、钢琴曲来烘托气氛,AIVA是首选。
怎么用?
登录AIVA,选择“Create Track”。
你可以选择预设风格,比如电影感、情绪化。
关键功能:你可以指定调性和时长。例如,你的镜头剪辑节奏是2分14秒,就设定生成2分15秒的音乐。AIVA会根据时长自动编排起承转合,高潮点正好落在你需要的地方,而不是像传统剪辑那样生硬地剪断音乐。

2. Mubert:生成环境氛围
如果你在做科幻片、悬疑片,或者只需要一些“不知名但很有感觉”的电子纹理声,Mubert更适合。
怎么用?
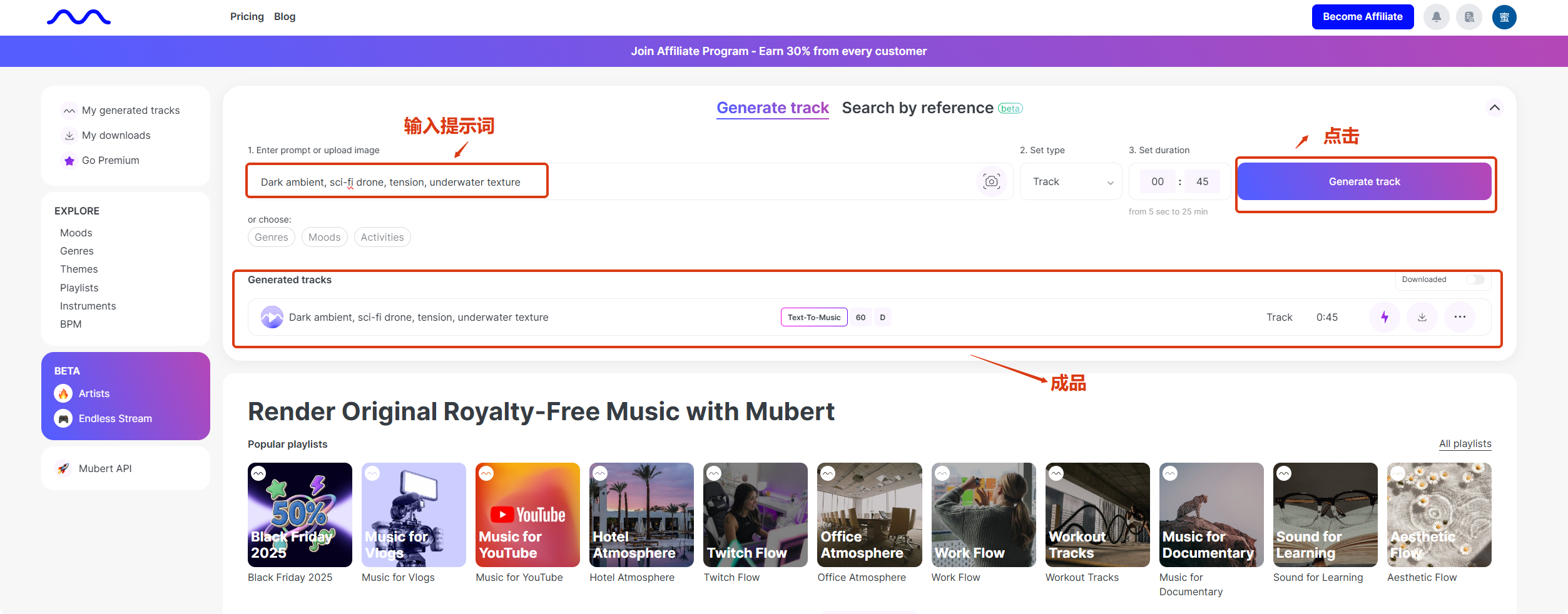
Mubert支持文字生音乐。
输入提示词,例如:"Dark ambient, sci-fi drone, tension, underwater texture"(黑暗氛围、科幻低鸣、紧张感、水下质感)。
它会生成一条无限循环的音流或者固定时长的音频片段,这种非旋律性的氛围音乐,是填补画面空白、增加高级感的利器。
行业思考:工具是手,审美是心
AI工具解决了“温饱问题”——它让低预算剧组不再因为设备简陋或现场失误而废掉整场戏。它消除了技术性的噪音,让对白清晰可闻。但是,声音设计的艺术性是AI暂时无法替代的。
Adobe Podcast可以把声音修得很干净,但它不懂在这场戏里,声音应该显得“空灵”还是“压抑”;AIVA可以生成一段悲伤的音乐,但它不知道在第几秒切入音乐能让观众落泪。
作为新时代的影视创作者,我们要做的是成为那个拥有“百万调音师”工具箱的导演。下次现场录音再“翻车”,别慌。打开这些网页,深吸一口气,然后告诉制片人:“没关系,我们后期能搞定。”
