
医疗 AI 实战:零成本“饮食安全计算器”


目录
前言
在慢病管理和康复医疗中,饮食记录是核心环节。但长久以来,让患者把每日菜谱发给医生,效率太差,也无法精准计算热量。
引入大模型可以很好地解决问题。但在医疗领域,直接调用云 API 面临数据隐私合规问题,同时还有额外的长期运营成本——随着用户量增加,API 调用费用是一笔不小的开支。
本文将介绍一套本地化的解决方案,利用 Ollama 本地部署阿里 Qwen2.5 模型,配合 LangChain 的格式控制功能,构建一个无需联网、隐私安全且零 API 调用费用的饮食分析工具。
一、 技术选型
为了实现这一目标,我们需要三个核心组件配合:
1. 本地部署工具:Ollama
我们选择 Ollama 来在本地服务器运行模型。

优势:部署极其简单,且完全在内网运行,物理隔绝了数据泄露风险。
2. 基础模型:Qwen2.5-7b
在信息提取任务上,70 亿参数(7b)的模型已经在速度和精度之间取得了很好的平衡。

优势:阿里的 Qwen2.5 在理解中文指令和输出标准格式方面表现优秀,特别适合此类结构化提取任务。
3. 流程控制:LangChain v1
大模型有时候会废话连篇。LangChain v1 提供了一项关键功能——结构化输出(Structured Output)。

优势:通过严格的格式检查,强制模型只输出我们需要的数据格式,避免系统解析报错。
二、 实操步骤
Step 1. 环境准备
首先,我们需要在本地服务器上把模型跑起来。Ollama 让这一步变得非常简单,只需几行命令即可完成服务启动。
# 1. 安装 Ollama (以 Linux 为例)
curl -fsSL https://ollama.com/install.sh | sh
2. 下载 Qwen2.5 7b 模型
ollama pull qwen2.5:7b
3. 启动后台服务
ollama serve
Step 2. 定义数据标准
为了让后续的程序能计算热量,我们必须规定好模型输出的数据格式。模型不能只回一句“好的”,而必须返回计算机能读取的结构化数据。
LangChain 允许我们利用 Pydantic 预先定义好这个**“数据模板”**:
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
定义单个食物的数据格式
class FoodItem(BaseModel):
food_name: str = Field(description="食物的标准名称,例如’肉包’、‘豆浆’")
quantity: str = Field(description="食物的数量或预估重量,例如’2个’、‘300ml’")
estimated_calories: int = Field(description="基于常识预估的单项总热量(卡路里)")
定义整体输出格式(支持一餐包含多种食物)
class DietLog(BaseModel):
items: List[FoodItem] = Field(description="这一餐中包含的所有食物列表")
Step 3. 构建提取流程
接下来,我们将本地模型与刚才定义的数据标准结合起来。这一步的核心是告诉模型:“你是一个营养师助手,请严格按照我给定的 JSON 格式提取信息,不要说废话。”
from langchain_community.chat_models import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
1. 连接本地运行的 Ollama 服务
llm = ChatOllama(model="qwen2.5:7b", temperature=0, format="json")
2. 启用格式控制功能
这一步确保模型输出的结果一定符合我们在第二步定义的 DietLog 格式
structured_llm = llm.with_structured_output(DietLog)
3. 设定指令
system_prompt = """你是一位专业的营养师助手。
你的任务是从用户的自然语言描述中,提取出食物信息。
请严格按照 JSON 格式输出,不要包含任何额外的解释性文字。
对于热量估算,请依据中国常见食物标准进行保守估计。"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}"),
])
4. 串联流程
chain = prompt | structured_llm
Step 4. 业务逻辑对接
模型提取出的数据只是第一步。在实际应用中,为了保证医学严谨性,我们不能完全依赖模型“乱猜”的热量,而是应该拿模型提取出的食物名去查询标准的营养数据库。
以下代码展示了如何将 AI 提取的数据与标准数据库结合:
# 模拟一个本地的标准营养数据库
def query_nutrition_db(food_name: str):
# 实际场景中,这里会连接 SQL 数据库
db_mock = {
"肉包": 250, # 单位热量
"豆浆": 35 # 每100ml热量
}
# 简单的匹配逻辑
for key, val in db_mock.items():
if key in food_name:
return val
return None
主处理函数
def process_diet_input(user_input: str):
print(f"用户输入: {user_input}")
# 1. 使用模型将自然语言转化为结构化数据
try:
result: DietLog = chain.invoke({"input": user_input})
except Exception as e:
return f"解析失败: {e}"
# 2. 用标准数据库校准数据
final_report = []
for item in result.items:
# 查询标准库
db_cal = query_nutrition_db(item.food_name)
source = "AI预估"
if db_cal:
source = "标准库修正"
# 注:实际开发中需增加单位换算的逻辑
final_report.append({
"食物": item.food_name,
"份量": item.quantity,
"热量": item.estimated_calories,
"数据来源": source
})
return final_report
— 运行效果测试 —
if name == "main":
text = "早上吃了两个肉包子和一杯豆浆"
report = process_diet_input(text)
import json
print(json.dumps(report, indent=2, ensure_ascii=False))
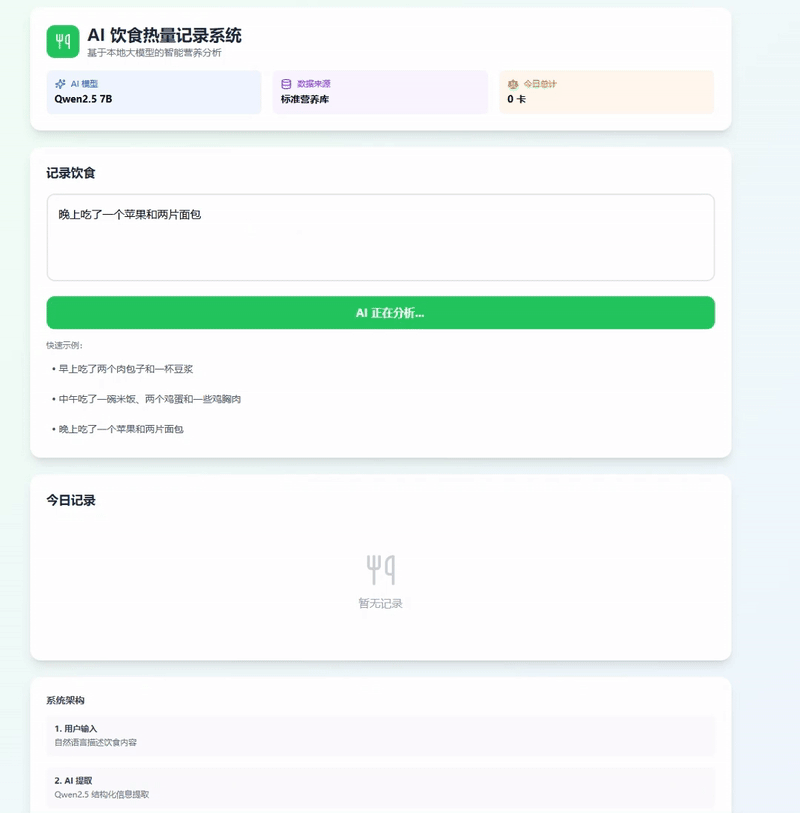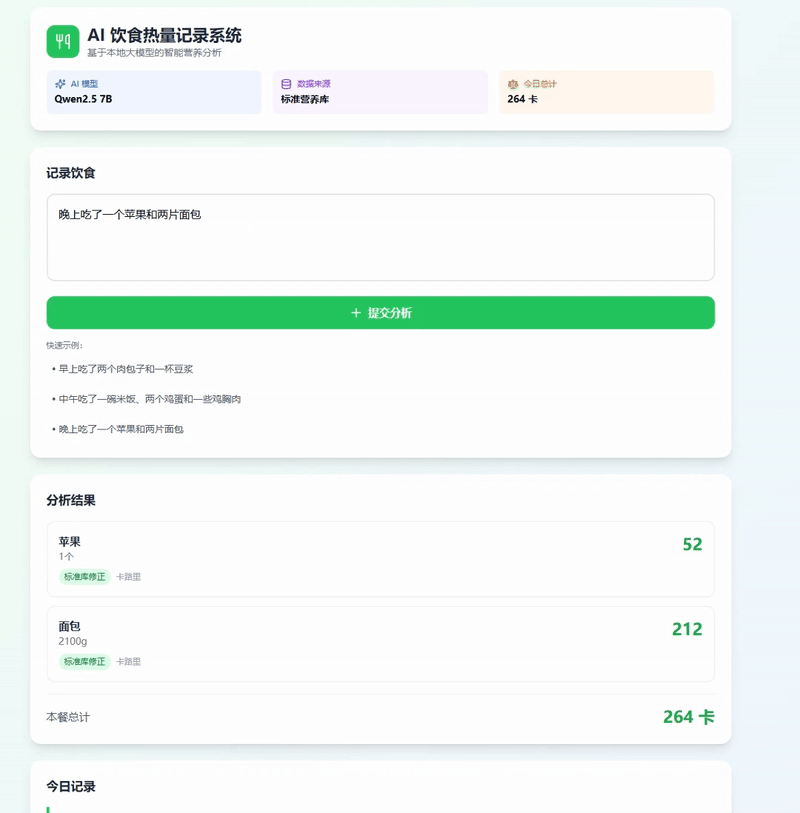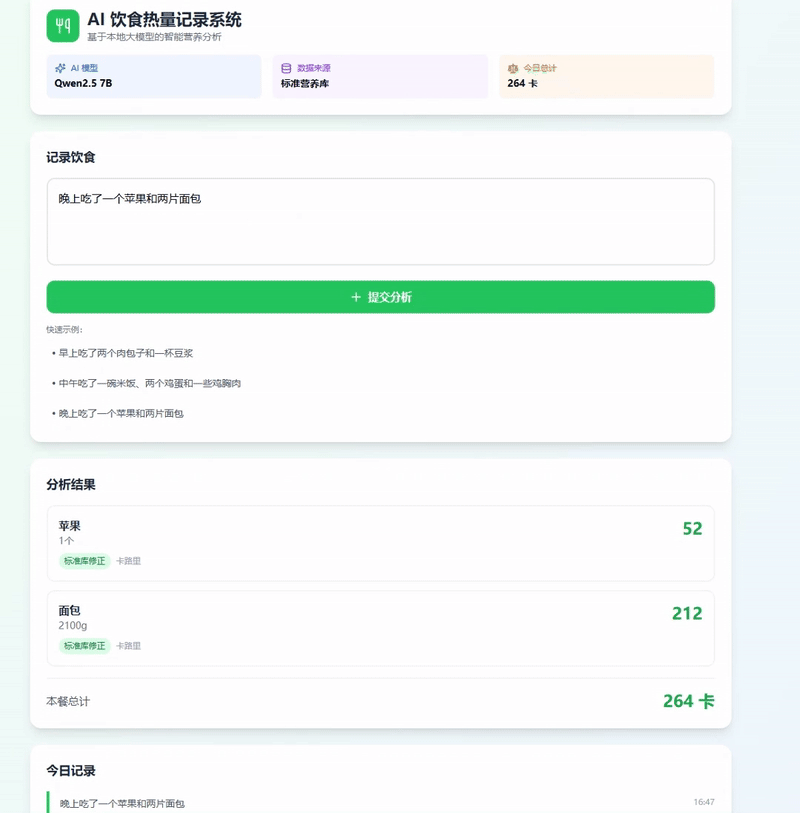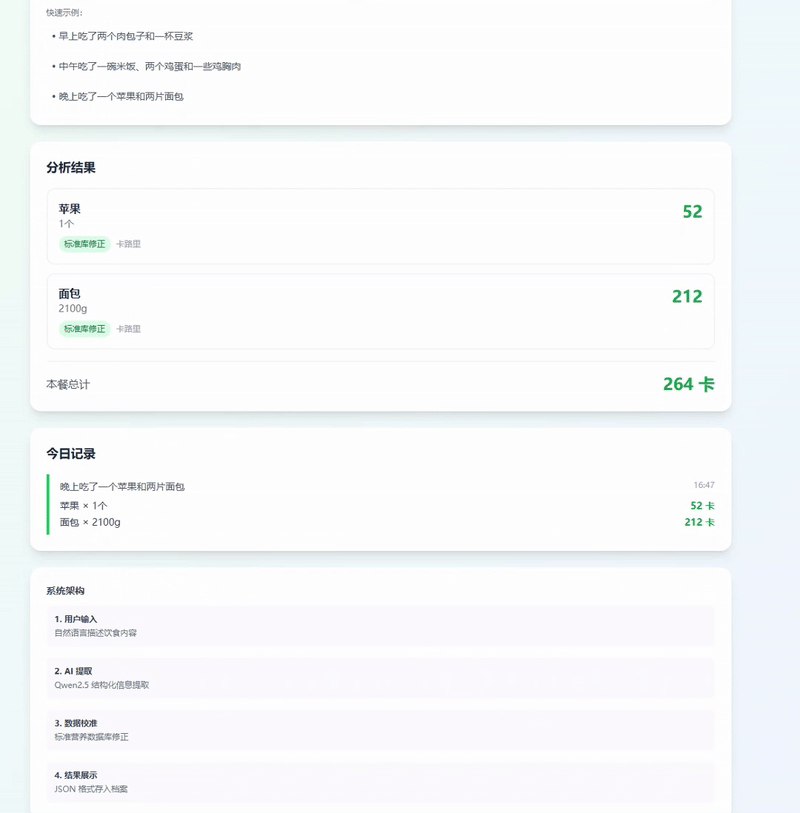
Step 5. 实际运行效果
当用户输入:“早上吃了两个肉包子和一杯豆浆”
系统后台会输出标准的 JSON 数据,可以直接存入患者的健康档案中:
[
{
"食物": "肉包子",
"份量": "2个",
"热量": 500,
"数据来源": "标准库修正"
},
{
"食物": "豆浆",
"份量": "1杯",
"热量": 150,
"数据来源": "标准库修正"
}
]
总结与建议
相比于按次收费的云 API,本地部署属于一次性硬件投入,后续无论用户量怎么增长,都不会产生额外的 Token 费用。
而且患者不再需要复杂的录入操作,只需像聊天一样说话,系统即可自动完成记录。
利用这套方案,我们能以更低的门槛提升饮食管理的智能化水平,帮助慢性病患者实现长周期的精细化管理。
