
谁来给AI演员打分?EvalTalker重塑文娱产业数字人制作标准

在当前的AI文娱领域,生成逼真的“单人”数字人已非难事。然而,一旦镜头中出现第二个人,或涉及复杂的“多人同台”场景,现有技术往往立刻暴露出肢体僵硬、身份混淆等明显缺陷。
正因如此,目前的AI视频多以“独角戏”为主,极少出现真正的“群像剧”。
近日,上海交通大学联合美团等机构发布了一项名为EvalTalker的重要研究。该研究并未停留在算法层面的展示,而是构建了首个大规模的“多说话人”视频数据集,并提出了一个能够像导演一样系统评估画面质量、肢体协调与身份一致性的评价框架。
这篇论文传递出一个清晰的产业信号,AI数字人技术正从“个体仿真”迈向“群体交互”。这一跨越,对于致力于实现全流程AI制作的文娱产业来说,无疑将成为打开新世界的一把钥匙。

论文链接:https://arxiv.org/pdf/2512.01340
从“独角戏”迈向“群像剧”
在深入技术之前,我们先得搞清楚一个概念:Talker与Multi-Talker。
过去的两年,是属于Talker(单主体说话人)的时代。无论是直播带货还是知识口播,只需要一张照片、一段音频,AI就能让照片“活”过来。但这在电影、游戏或者复杂的短剧制作中,远远不够。
真实的娱乐场景是什么样的?是两个人坐在咖啡馆聊天,是一个团队在会议室争论,是一群人在街头互动。这就是论文中提到的Multi-Talker(多主体说话人系统)。
论文指出现有的技术大多只能驱动单个面部区域,忽略了人类交流中复杂的多主体动态交互。简单说,以前的AI是“复读机”,现在的AI要想进军影视圈,必须得学会“演对手戏”。
为了摸清行业的家底,研究团队干了一件狠事:他们收集了400张涵盖各种难度的真实肖像,找来了市面上最顶尖的15个多说话人系统(包括HeyGen、MuseTalk、SadTalker等),一口气生成了5492个多主体视频。
结果如何?惨不忍睹,但也充满希望。这就像是一场大规模的“海选试镜”。结果发现,当画面中出现多个人时,AI这台“造梦机器”开始频繁卡壳。有的系统(如MultiTalk)表现尚可,但有的系统(如AniTalker)在处理复杂场景时,质量会出现断崖式下跌。
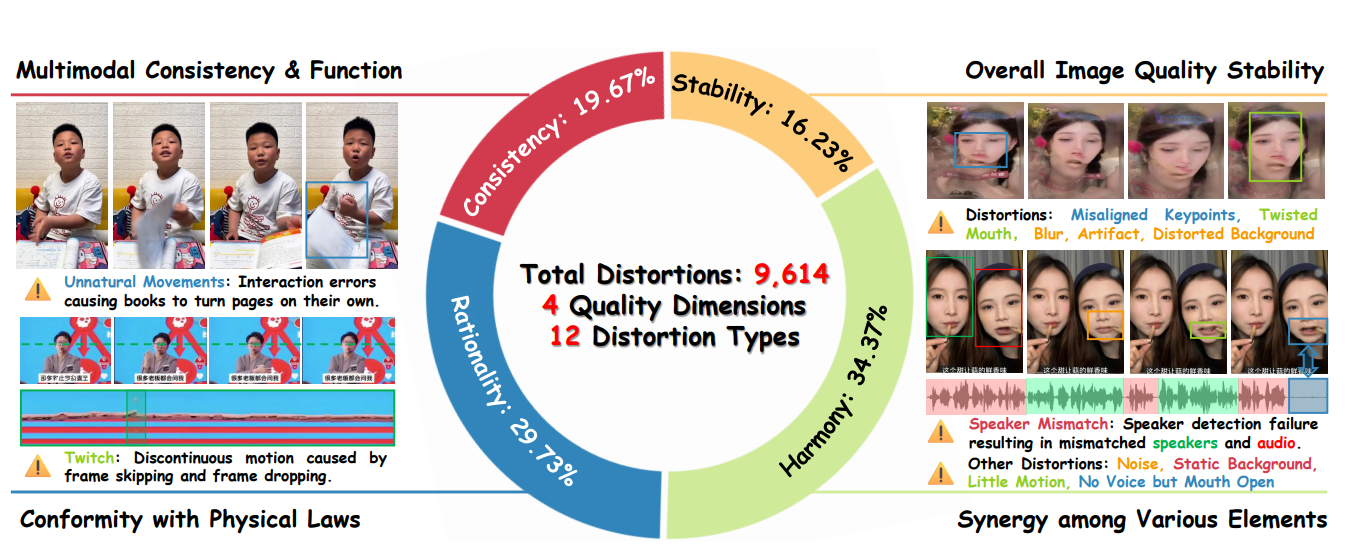
AI群演的“十二种硬伤”
如果说单人视频的bug通常是口型对不上,那么多人视频的bug简直就是“群魔乱舞”。
在这项名为THQA-MT的大规模数据集中,研究团队通过海量的用户主观测试,总结出了AI在生成多人视频时的12种“失真罪状”。对于文娱从业者来说,这份清单简直是避坑指南。
•身份大挪移:这是一个致命伤。明明输入的是A和B两张脸,生成出来视频里,A突然长得像B了,或者两个人长得越来越像。在影视制作中,演员“换脸”可是大忌。
•幽灵肢体:当两个数字人靠得太近,AI搞不清胳膊是谁的,就会出现肢体穿模、残影,甚至多出一只手的惊悚画面。
•背景冻结:人动了,影子没动;或者人在走,背景却是死得像贴图。这种“抠图感”是目前数字短剧廉价感的来源。
•多模态不同步:这不仅仅是嘴巴没跟上声音。更高级的尴尬是声音听起来很生气,但数字人的肢体动作却很僵硬,或者眼神还在放空。“听其声而观其行,完全是两个人”,这种割裂感瞬间打破沉浸感。
研究发现,用户对“稳定性”的要求最高,但对“一致性”的容忍度相对较高。这意味着,先把画质做稳,是AI群像剧落地的第一步。
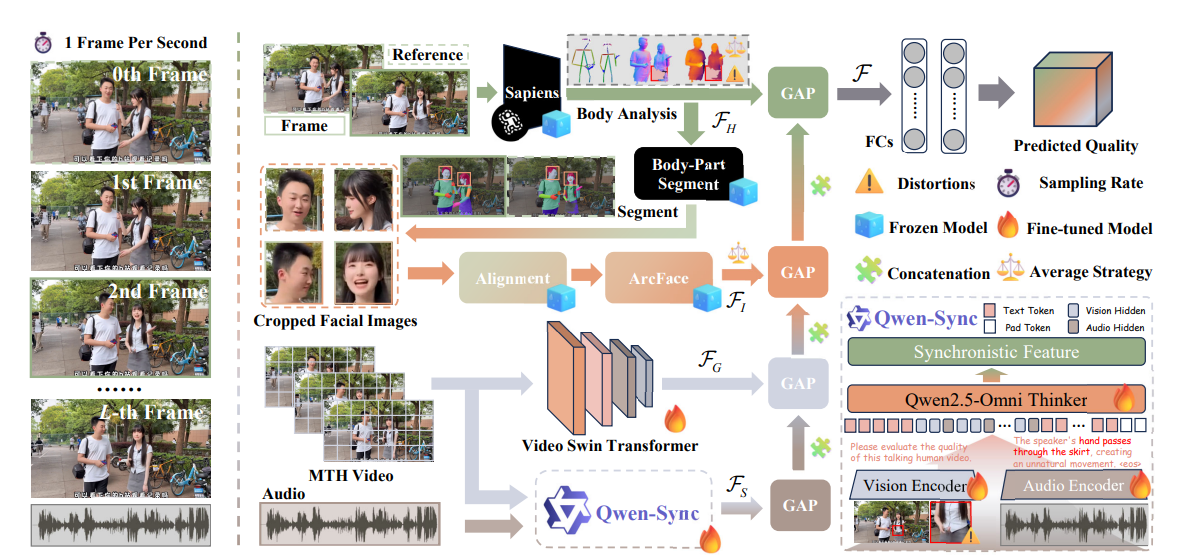
给算法装上“导演之眼”
既然问题这么多,怎么修?这就轮到论文的主角——EvalTalker登场了,你可以把它理解为一位AI界的“铁血导演”兼“质检员”。
在过去,评价一个AI视频好不好,往往靠人眼看,效率低且主观。EvalTalker提出了一套全自动的评估框架,它能像人一样,从四个维度给视频打分。
•看画质:就像摄影师检查底片,看画面是否清晰、噪点是否过多。
•看身段:这是一个巨大的突破。EvalTalker引入了一种强大的人体分析模型,它不再只盯着脸看,而是开始关注身体姿态。AI生成的动作自然吗,肩膀的抖动符合物理规律吗?这对于“全身皮套”的虚拟主播至关重要。
•查户口:它会死死盯住每一帧画面,确保演员没有“演着演着换人了”。
•对台词:这是最黑科技的一点。研究团队开发了Qwen-Sync模块(基于Qwen2.5-Omni大模型)。它不仅能听懂声音,还能看懂视频,判断声音、嘴型、表情、动作是否在同一个“频道”上。
“你虽然嘴在动,但你的眼睛里没有戏。” 以前只有资深导演能说出的话,现在EvalTalker也能通过算法计算出来了。
实验数据显示,EvalTalker在5个主流数据集上的评分表现,均拿下了当前最优,其判断结果与人类主观评分的高度一致性令人咋舌。

文娱内容的“无人化图景”
读懂了这篇论文,我们就能看清未来3-5年文娱产业的风向。
1. 短剧与广告的“无人化”生产
目前的AI短剧大多是“PPT式”过场。随着EvalTalker这类质量评估体系的成熟,反向倒逼生成端技术的进步,我们很快将看到能够处理双人对白、甚至多人冲突的AI视频生成工具。这意味着,低成本、高产量的“AI情景剧”将迎来爆发。
2. 游戏NPC的觉醒
游戏里的NPC不再是站在原地念台词的木桩。多主体驱动技术的发展,将让NPC之间产生自主的交互。当你路过游戏里的街角,可能会看到三个NPC在自然地聊天、推搡,且这一切都是实时生成的。
3. 虚拟偶像团体的进化
现在的虚拟女团大多依靠昂贵的中之人动捕。当AI能够完美处理Multi-Talker场景下的肢体协调和同步问题,真正的“全AI驱动”偶像团体将成为可能,24小时不间断的团综直播或许不再是梦。
结语
这篇《EvalTalker》论文的价值,不仅在于它提出了一个算法或一个数据集,更在于它标志着数字人技术正在跨越“个体仿真”的初级阶段,迈向“社会化交互”的高级阶段。
我们在屏幕上看到的每一个自然的微笑、每一次流畅的转身、每一场生动的对话,背后都是算力对物理世界的极致解构。
当AI不仅有了好看的皮囊,还拥有了协调肢体、理解语境、甚至把控对手戏节奏的能力时,文娱产业的“寒武纪大爆发”就不远了。
