
AI 赋能法律:企业法务真正需要的,不是更快的答案,而是更可靠的思考介质

目录
01 认知入口:为什么最懂业务的法务,反而最容易被知识淹没?
02 时代转折:不是法律在变难,而是知识本身变得无法手工驾驭
03 转向真正的问题:企业法务需要是“能自证出处的答案”
04 关键洞察:一个企业级 RAG 法律助手如何重构你的判断方式
05 操作性落地:律师真正能用的 RAG 工作流长什么样?
06 结尾:真正的转变,在于你敢不敢把判断权重新设计一遍
01 认知入口:为什么最懂业务的法务,反而最容易被知识淹没?
办公室里,总有人习惯在浏览器、微信群、判例库之间跳转,想在最短时间内找出“那个确定的说法”。可越是经验丰富的人,越清楚一个残酷的事实:
法律问题不是找不到答案,而是答案太多。
真正困住企业法务的是信息过载。
你以为你在搜索答案,其实你在穿越一片被碎片化知识搅动的迷雾。你以为看得越多越稳妥,其实你的判断常常被不同来源的冲突描述撕成两半。
这正是悖论所在:
那些最具经验的人,最容易被信息的丰盛反噬。
当我们把“查得快”当作效率,真正的风险却悄无声息地扩大。
02 时代转折:不是法律在变难,而是知识本身变得无法手工驾驭
法律的边界没有突然变得更深奥,但知识的生产速度已经远超个人的处理能力。
每天都有新的监管要求、更新的行业规则、跨境合规提醒、隐私政策变更、政府指引释义……它们像不断蔓延的水纹,一层一层叠在日常工作之上。
过去的路径是:“我知道要去哪查,我知道要怎么搜。”
今天的现实却在悄悄反向:
懂得越多,越知道哪里会造成人为盲区。
依赖越深,越知道纯人工无法覆盖所有风险层级。
03 转向真正的问题:企业法务需要是“能自证出处的答案”
当 AI 的声音越来越大,最普遍的误解也随之放大:
“是不是让一个大模型来回答所有法律问题就可以了?”
事实上,真正的企业法律风险从来不是“答不出来”;
真正的风险是 答不对、答不准、答不敢用。
你需要的不是一个会说话的工具,而是一个 能引用原文、能显示出处、能暴露置信度、能被审计 的法律助手。
当 AI 参与法律工作,最关键的能力反而不是“生成内容”,而是:
把碎裂的信息重新缝合,把原始材料直接呈现,让每一个判断都能溯源。
只有这样的系统,律师才敢真正把它纳入自己的专业决策流程里。
04 关键洞察:一个企业级 RAG 法律助手如何重构你的判断方式
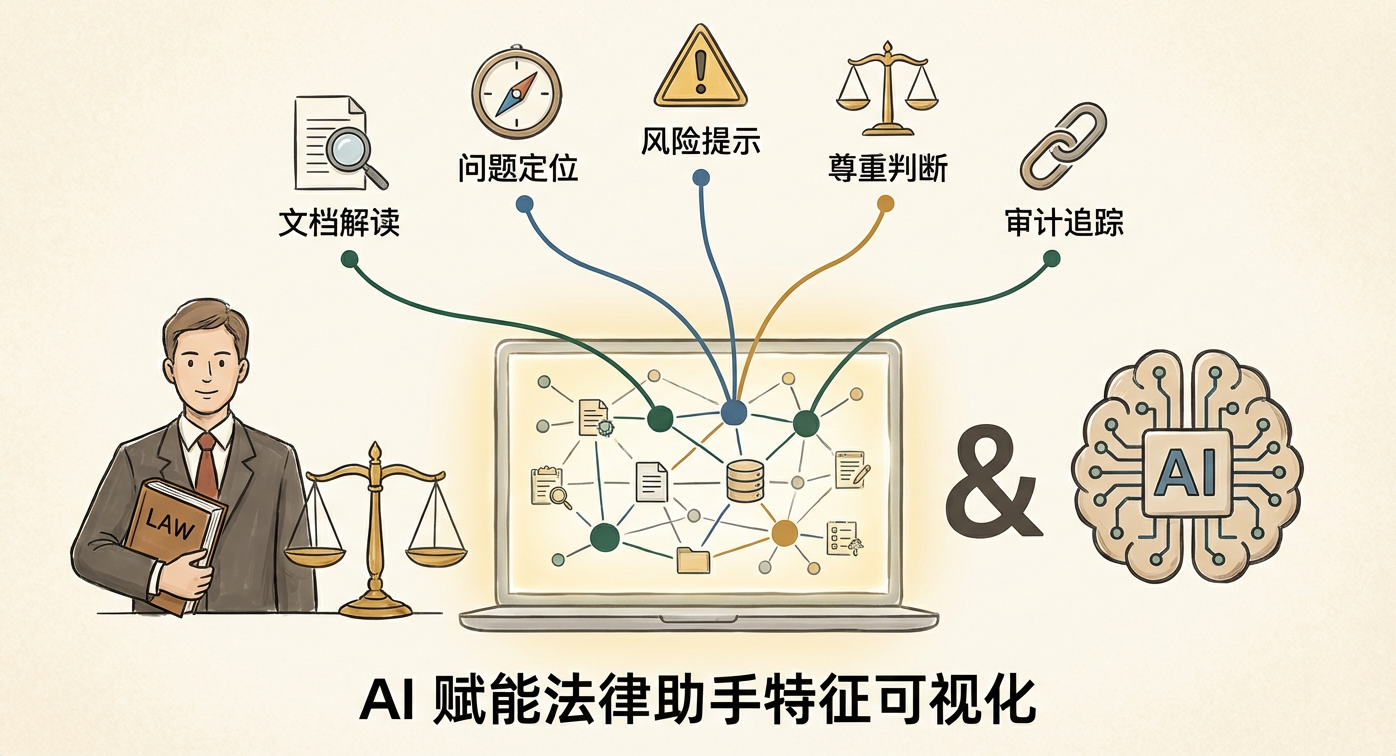
一个真正能被企业法务使用的 AI 法律助手,应该具备以下“隐藏但关键”的特征:
1. 你的文档,它能读懂:合规手册、审计报告、过去的合同、邮件往来、培训材料,都能成为它的知识库。
2. 你的问题,它能定位:不是大模型凭想象回答,而是从你的知识库中找出对应条文、政策、判例。
3. 你的风险,它会提示:答案后会自动标明“需要人工审核”“存在跨条款矛盾”“原始来源如下”。
4. 你的判断,它尊重:你永远是最终审批者,它不越权、不假设、不自作主张。
5. 你的审计,它能追溯:每一个答案都有时间戳、来源、引用段落和置信度。
你会发现:
它不是来替代你,而是来替你整理你原本就必须面对的复杂性。
这一刻,AI 不再是一种“算力”,则是成为一种“治理方式”。
05 操作性落地:律师真正能用的 RAG 工作流长什么样?
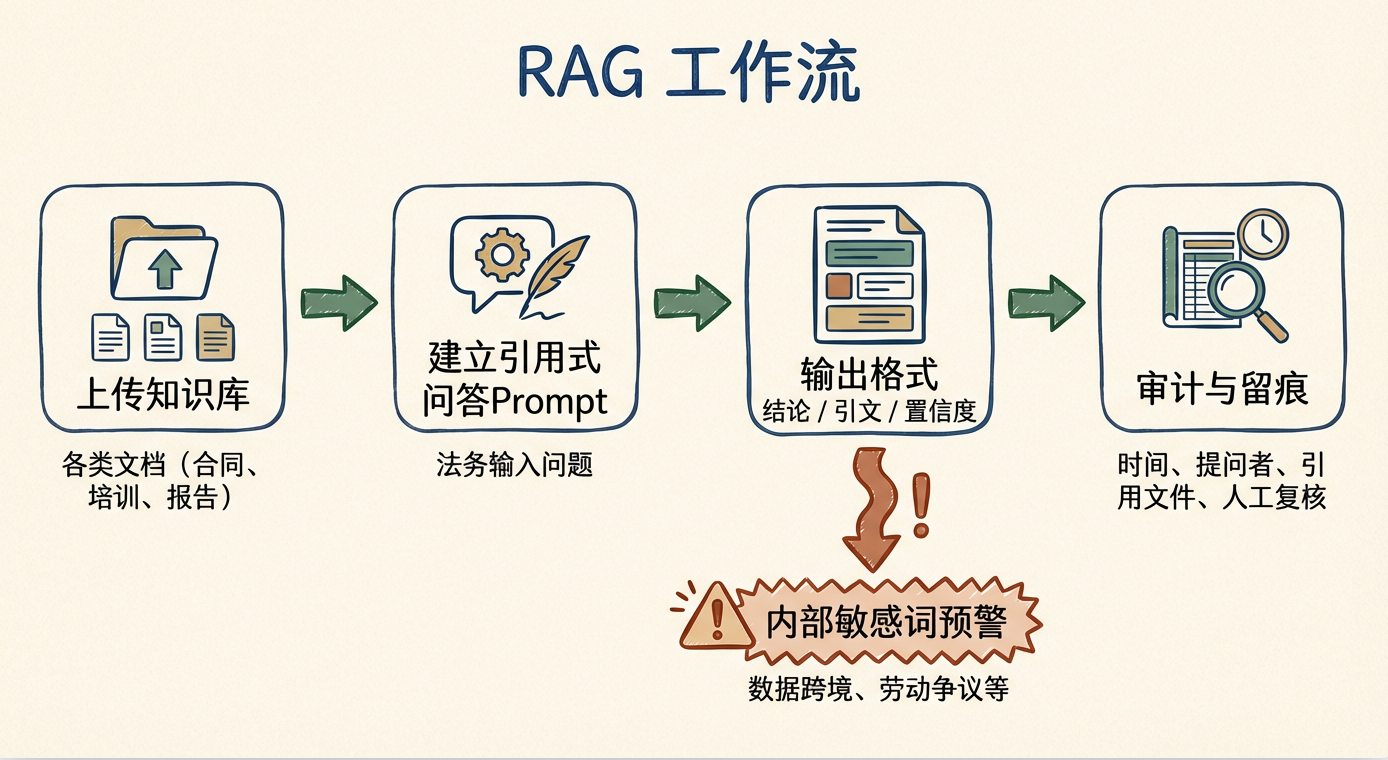
为了让文章是一份可操作的路线,我给出一个律师可以 当场上手 的基础版 RAG 工作流。
第一步:上传知识库(企业内部材料)
● 合规制度
● 部门 SOP
● 历史合同
● 培训文档
● 律师意见书
工具提示(任选其一):
● Pinecone / Weaviate(向量数据库)
● LangChain(检索链路)
● OpenAI API(语言模型调用)
第二步:建立“引用式问答”Prompt
律师可直接复制使用:
第三步:建立“置信度—引文—结论”三栏输出格式
律师在看到“置信度:低”时会自动触发人工审核流程,这也是系统最重要的风控机制。
第四步:配置“内部敏感词”预警规则
例如当问题涉及:
● 数据跨境
● 著作权归属
● 劳动争议
● 广告合规
系统会自动提醒:“该类问题需人工审查。”
第五步:建立审计与留痕
每一个回答都记录:
● 时间
● 提问者
● 引用文件
● 原文片段
● 模型版本
● 人工是否复核
法务合规部门的治理能力因此被整体拉升。
06 结尾:真正的转变,在于你敢不敢把判断权重新设计一遍
AI 赋能法律在逼你重新定义一个问题:
什么东西应该交给系统,什么东西必须由人来判断?
如果你愿意向前迈半步,你会发现一个新的事实:
AI 不会让法律变简单,但它会让“复杂的事情终于有了处理的秩序”。
而下一篇文章,我想邀请你一起深入:
“企业法律问答系统真正的风险在哪里,而律师又该如何建立自己的安全阈值?”
