
AI肺癌筛查最新进展:以0.5次假阳性实现99.3%灵敏度


核心资料来源
1.论文:Rethinking Lung Cancer Screening: AI Nodule Detection and Diagnosis Outperforms Radiologists, Leading Models, and Standards Beyond Size and Growth ,由欧洲和美国多机构团队(巴黎大学、哈佛医学院等)联合发表。
2.NLST(国家肺癌筛查试验)数据集:美国多中心肺癌筛查项目,用于训练和测试AI模型。
3.独立临床队列(IC)数据:来自欧美多中心(如法国AIR研究、美国Gradient等),包含慢性阻塞性肺病(COPD)患者群体。
全球肺癌死亡率高居榜首,优化早期诊断是降低死亡率的关键。现行的临床手段依赖结节尺寸和体积倍增时间(VDT)作为恶性风险核心指标,但这类方法存在滞后性,小结节需持续随访数月甚至数年,直至满足增长阈值才触发干预,错失最佳治疗窗口。
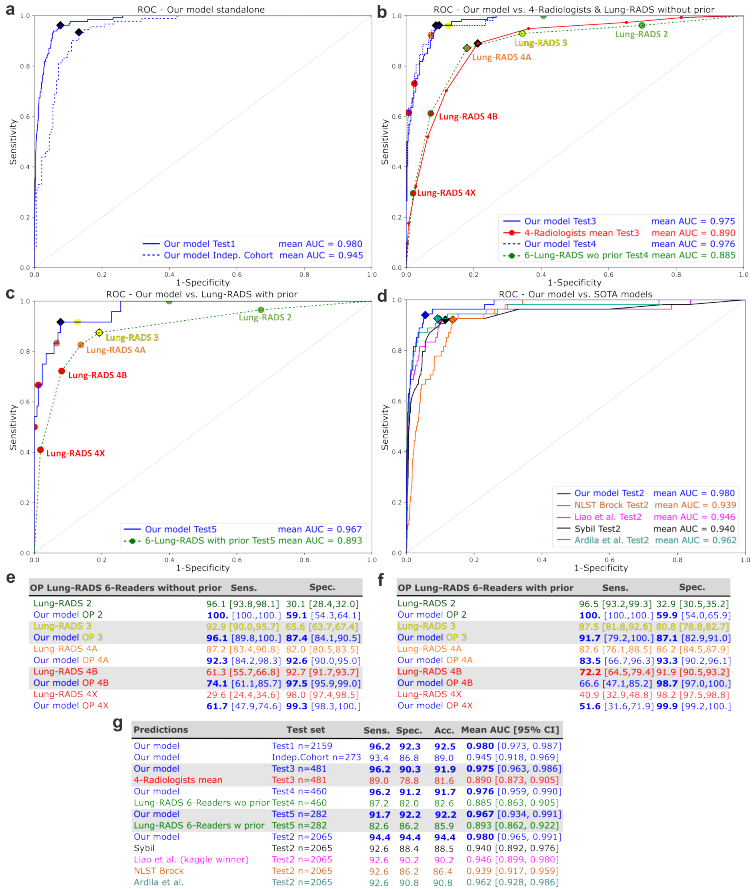
这项最新的研究通过集成化AI系统,在NLST和独立队列中实现了“检测-诊断”的一体化突破。曲线下面积(AUC)在内部测试达0.98,独立验证达0.945,显著优于放射科医生(平均AUC 0.89)和Sybil、Google等顶尖模型(AUC 0.92-0.96)。更关键的是,在每扫描仅0.5个假阳性的苛刻条件下,模型对恶性结节灵敏度高达99.3%,远超传统计算机辅助检测(CADe)系统。
一、 模型的全面碾压
研究团队使用了包含NLST(国家肺癌筛查试验)、LIDC-IDRI及独立队列(IC)在内的25709次扫描和69449个注释结节进行训练和评估。数据规模之大,使其成为仅次于谷歌私有数据集的公开领域最大规模研究之一。
1. 0.5 FP下的99.3%灵敏度
传统检测系统的痛点在于“宁可错杀三千”,导致假阳性率极高。例如,DL-LND模型在7 FP/scan下才达到93%灵敏度。而本研究的AI模型通过集成检测与诊断模块,在Test1数据集上,仅需0.5 FP/scan即可达到99.3%的灵敏度。这意味着,AI在几乎不产生噪音干扰的情况下,几乎捕获了所有恶性结节。
2. 单挑放射科医生
在Test 3(481例样本,含132例癌症)的人机对决中:
AI vs 放射科医生: AI模型的AUC达到0.975,显著优于20位放射科医生(平均AUC 0.89)。统计显示,AI的表现优于每一位参与测试的医生(p < 0.0001)。
AI vs Lung-RADS®: 即使在放射科医生拥有先验CT影像的情况下,其基于Lung-RADS®的评估(AUC 0.893)仍完败于AI模型(AUC 0.967)。
3. 吊打科技巨头
研究将该模型与当前最先进的模型进行了同台竞技,包括:
Sybil(MIT/哈佛开发): AUC 0.940
Liao et al.(Kaggle百万美元大奖得主): AUC 0.946
Ardila et al.(谷歌团队): AUC 0.962
本研究模型: AUC 0.980
在Test2数据集上,该模型以显著优势超越了上述所有明星模型。更关键的是,Sybil和谷歌模型仅提供患者级别的预测,属于“黑盒”,而本研究的模型能提供结节级别的精确定位和特征分析,具备临床急需的可解释性。
二、 技术创新
在Transformer和端到端大模型横行的今天,该研究反其道而行之,并未采用庞大的单一网络,而是设计了一个“浅层深度学习与特征工程的因子化集成架构”。
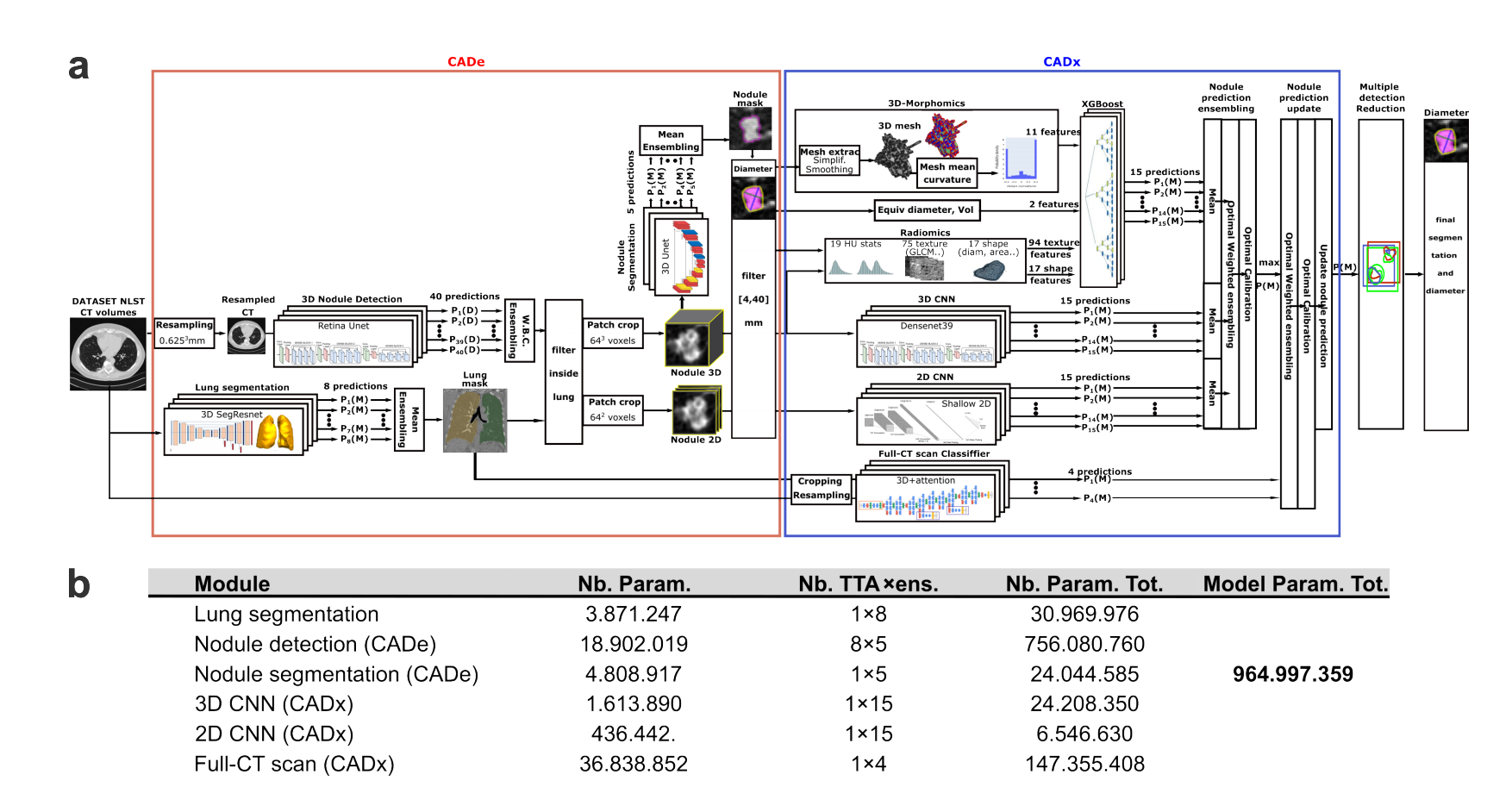
1. 因子化设计(
受人类视觉皮层腹侧和背侧通路的启发,模型将任务拆解为检测(Where)和表征(What):
检测模块(CADe): 使用Retina U-Net和3D-SegResnet进行肺部和结节分割,专注于把结节找出来。
表征模块(CADx): 这是核心亮点。它没有依赖单一网络,而是并行集成了15个浅层3D-CNN(DenseNet)、15个2D-CNN、以及15个基于XGBoost的分类器(利用122个影像组学和3D形态学特征)。
2. 为什么“小模型集成”更强?
论文犀利地指出,医学影像数据集(约1万例)远小于自然语言模型的数据量。在有限数据下,巨大的Vision Transformer(如ViT-Huge)或通用医学大模型(如Med-Gemini)往往效率低下且难以训练。
相反,这种“弗兰肯斯坦式”的专家集成策略(Frankenstein modeling),让每个小模型专注于特定的特征提取(纹理、形态、上下文),最后通过最优凸堆叠(Convex Optimal Stacking)融合决策。这不仅降低了算力门槛,更在只有中等规模数据集的情况下实现了SOTA性能。
3. 上下文感知
模型还引入了一个基于Sybil改进的全CT扫描3D分类器,捕捉结节之外的背景特征(如肺气肿、结节密度分布),进一步修正结节层面的预测。
三、 结节大小不再是金标准
目前的临床指南(如Lung-RADS®、NELSON协议)极度依赖结节大小和体积倍增时间(VDT)来判断良恶性。这项研究用数据证明:在AI面前,大小和生长速度已不再是最佳指标。
1. 大小失效论
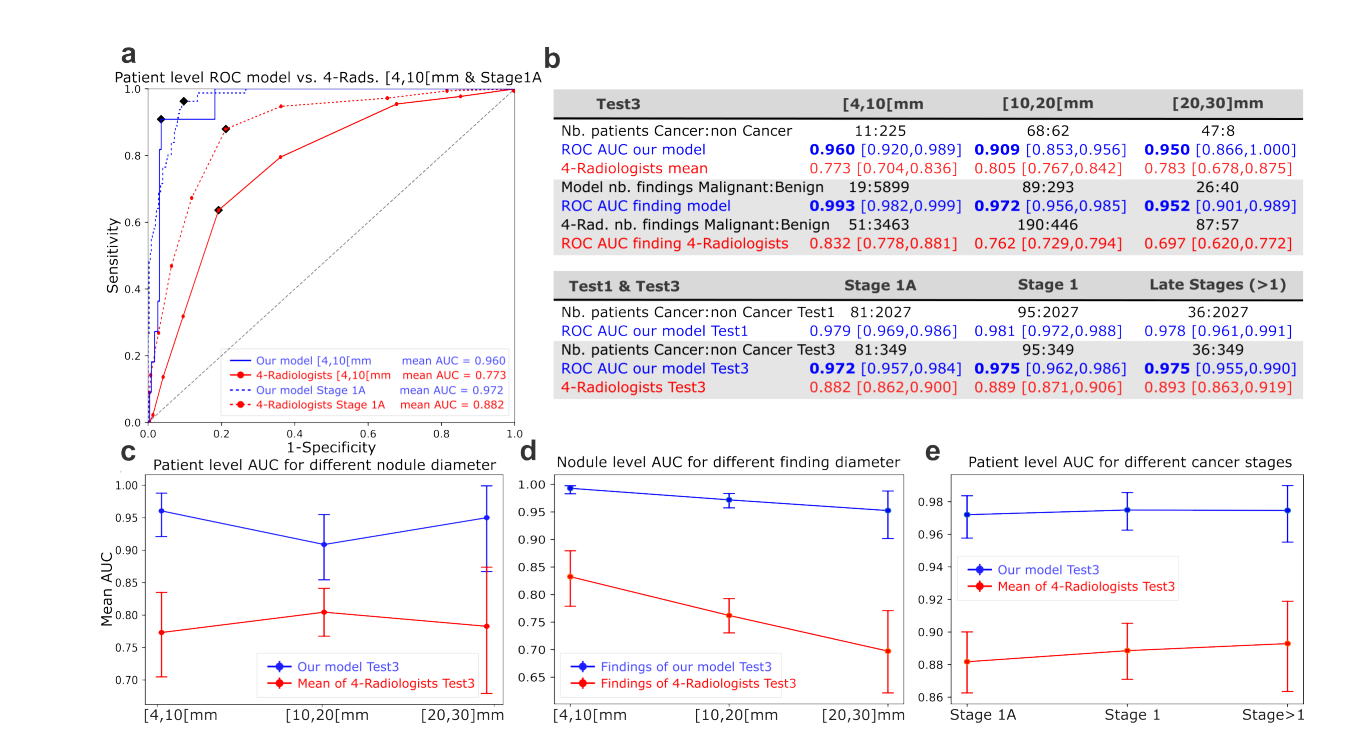
研究发现,AI预测值与结节大小的相关性仅为中等(Pearson ρ = 0.499)。在4-10mm的小结节区间(通常被认为是低风险),AI的AUC高达0.960,而放射科医生仅为0.773。这意味着,大量被医生因“太小”而忽略的早期恶性结节,能被AI精准捕获。
2. 扼杀VDT
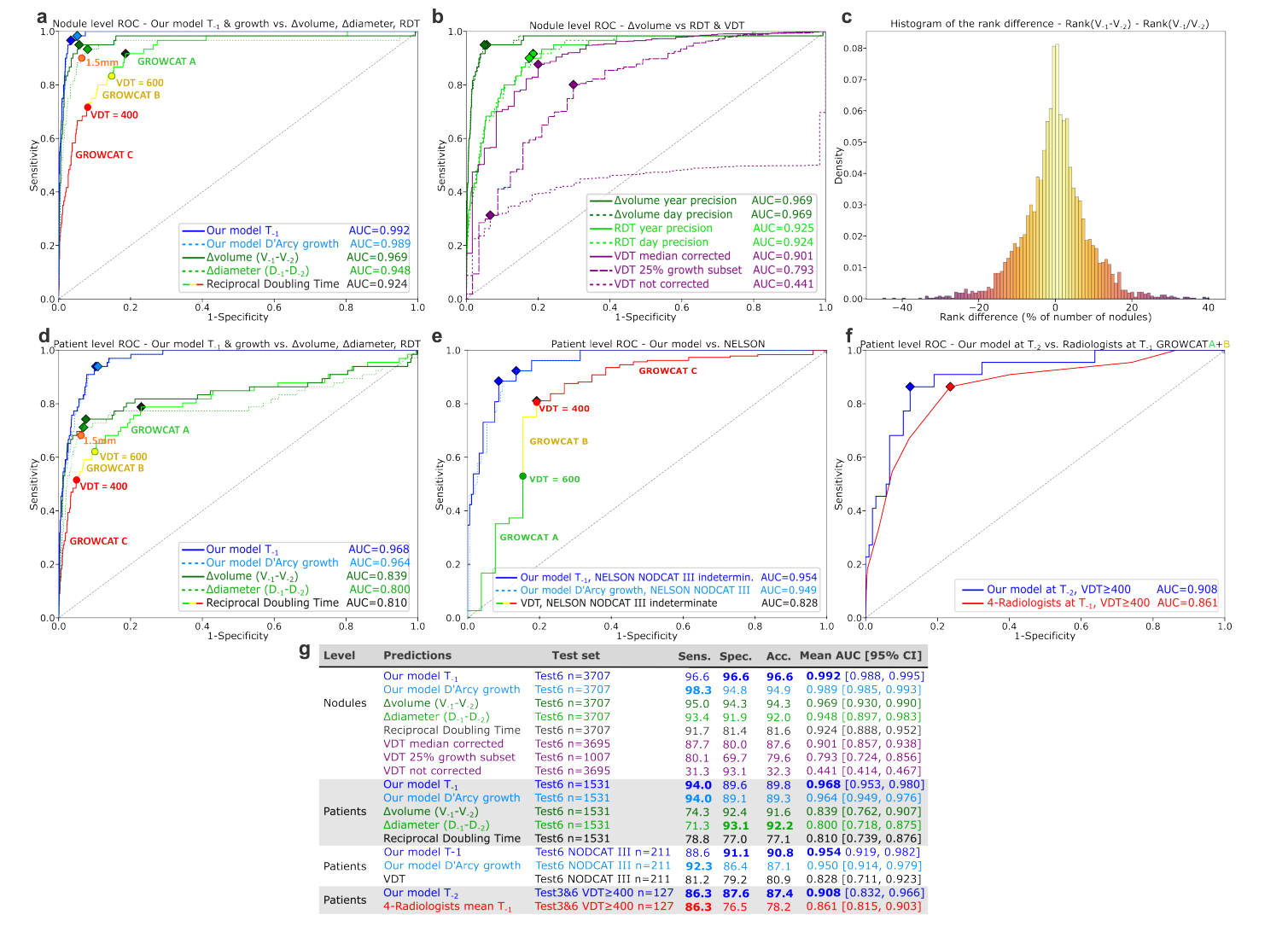
VDT长期以来被视为评估恶性程度的“首选方法”。然而数据显示,AI在
时间点(诊断前1年)的瞬时预测能力(AUC 0.992),完爆了基于时间序列计算的VDT(AUC 0.901)。即使是NELSON协议中定义的“快速生长”结节,AI的预测也比传统的体积增长指标更准确。
3. 抢回1年的生命窗口
对于生长缓慢或不确定的结节(Indeterminate/Slow-growing, VDT ≥ 400天),临床通常建议随访。但在这意味着,AI可以在医生确诊前整整一年,就锁定那些隐蔽的慢速生长肿瘤。

回归工程化集成或许是医疗AI落地的捷径
目前科技界对端到端大模型存在过度迷信。本研究证明,在医疗垂类,由于高质量标注数据的稀缺性,通用的巨大参数模型并非最优解。
医疗AI创业公司不应盲目卷参数量或Transformer架构,将传统的影像组学与深度学习结合,利用浅层网络的强泛化能力,是在中等规模数据下突破性能瓶颈、降低部署成本、提高可解释性的最佳路径。
AI将把癌症筛查成本降低
肺癌筛查推广的最大阻力并非漏诊,而是医疗资源缺乏和患者恐慌。该模型在99.3%灵敏度下仅0.5 FP/scan的表现,意味着AI终于跨过了临床实用性的阈值。
极低的误报率意味着保险公司和医保基金将更有动力覆盖LDCT筛查,当人们不再害怕因AI误诊而产生的昂贵检查费,这类检查类AI产品将比其他医疗AI更具商业变现潜力。
