
Google DeepMind 最新论文:医疗 AI 的尽头不是“千亿参数”


核心资料来源
1. 论文:Training and Evaluation of Guideline-Based Medical Reasoning in LLMs ,由海德堡大学(Heidelberg University)和 Google DeepMind 联合发表。 2. 数据集:MIMIC-III 重症监护数据库(电子健康记录 EHRs),包含 4 万多名患者的 ICU 数据。 3. 医学指南:Sepsis-3 共识定义(脓毒症相关的器官衰竭评估 SOFA 评分)。
前言
现有的医疗大模型(如 Gemini, ChatGPT)虽然在执业医师考试中表现优异,但在真实的临床预警场景下,却陷入了高分低能的怪圈。
它们能像背书一样回答医学问题,却无法像医生一样,依据临床指南,一步步推导出诊断结果。这种缺乏逻辑链条的诊断,让医院不敢信,也不敢用。
近日,海德堡大学与 Google DeepMind 联合发表的一项重磅研究,提出了一种全新的思路:与其让 LLM 自己去悟医学知识,不如直接教它们背指南,并按照指南的逻辑一步步推理。
这项研究不仅让小参数模型(8B)在推理准确性上吊打 70B 的大模型,更重要的是,它为医疗 AI 的可解释性开辟了全新路径。
一、 AI 会做题,但不会看病
 目前的医疗 AI 存在两个核心问题:
目前的医疗 AI 存在两个核心问题:
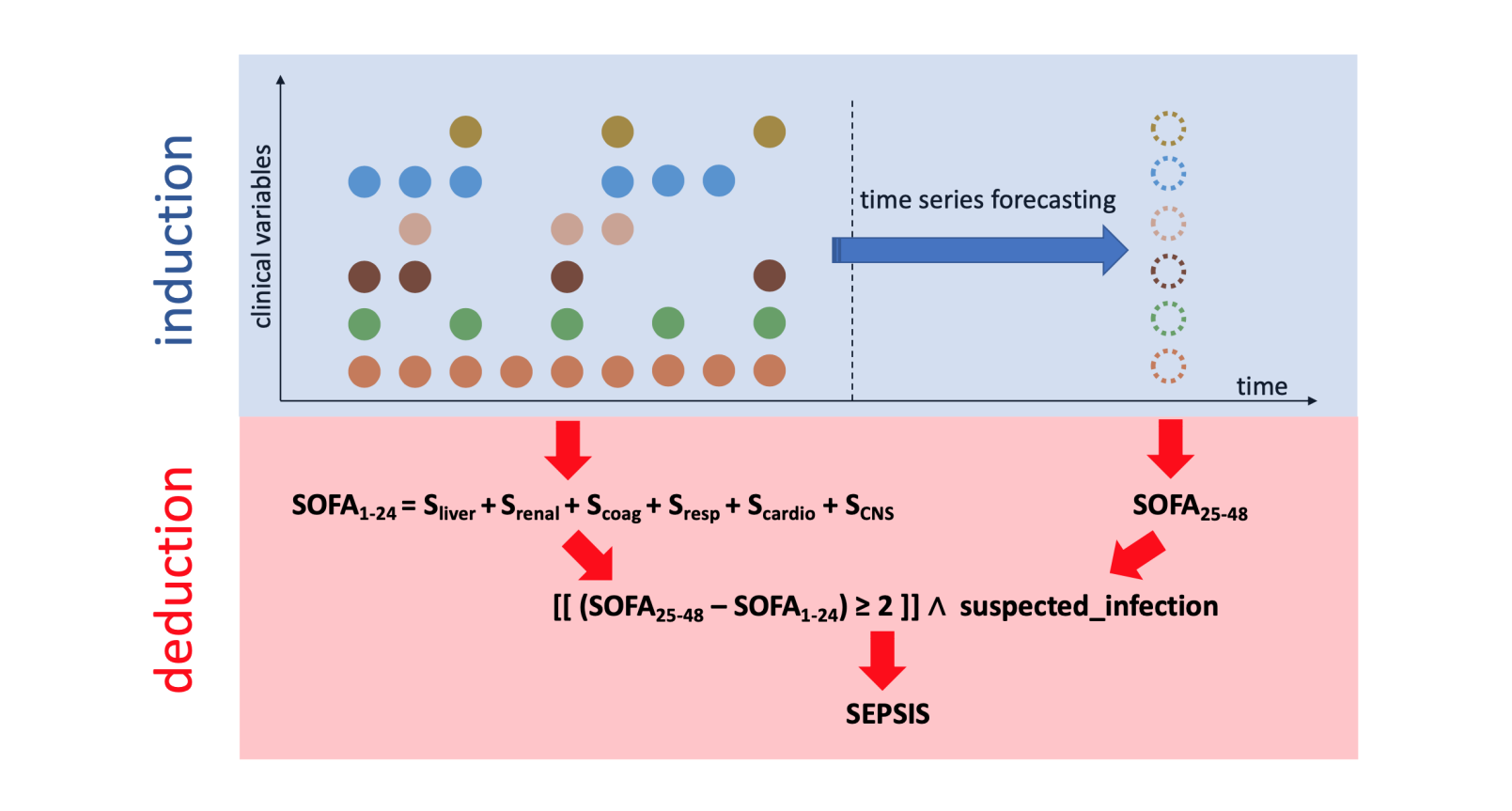
- 缺乏演绎推理能力:医学诊断往往依赖于严格的共识指南。例如诊断脓毒症(Sepsis),医生需要根据 Sepsis-3 指南,计算 6 个器官系统的 SOFA 评分,还要结合感染疑虑。这是一个严密的逻辑推导过程。而通用模型都是通过海量数据训练出的概率相关性来推测结果,缺乏逻辑链。
- 缺乏归纳推理能力:临床预警需要预测未来的病情。这要求模型不仅能理解当下的数据,还要能从稀疏、不规则的时间序列数据中,归纳出未来的趋势(如预测 24 小时后的血压变化)。这是通用模型的天然弱项。
二、 教 LLM 像医生一样“按图索骥”
研究团队提出了一种基于口语化推理规则的微调方法。简单来说,就是把医学指南和电子病历数据,翻译成通用能听懂的逻辑链。
1. 核心战绩:小模型逆袭大模型
研究者基于 Llama-3-8B 模型进行了微调。结果显示,在 Sepsis-3 诊断任务中:
推导正确性: 微调后的 8B 模型在逻辑推导上达到了 99.8% - 100% 的准确率,几乎完美复刻了指南的逻辑。
对比表现: 相比之下,直接使用 Prompt 工程的 Llama-3-70B 模型,即使把指南喂给它,逻辑正确率也仅有 50%-80% 左右。
 这意味着:在特定医疗垂直领域,通过高质量的思维链微调,小模型完全可以战胜通用大模型。
这意味着:在特定医疗垂直领域,通过高质量的思维链微调,小模型完全可以战胜通用大模型。
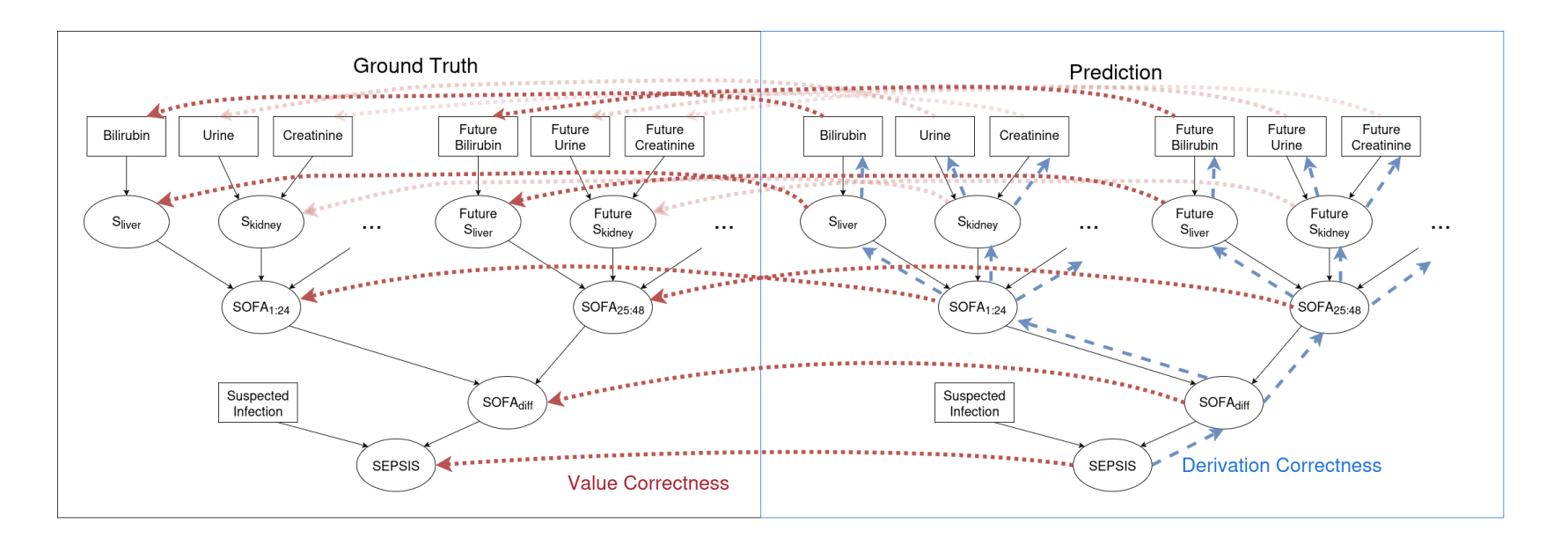
2. 方法论:演绎与归纳结合
研究团队设计了一个精妙的架构,将医学推理拆解为两部分:
演绎推理: 处理生硬规则。例如,“如果平均动脉压 < 70 mmHg,则心血管 SOFA 评分为 1”。这部分通过微调模型,让其死记硬背并严格执行。
归纳推理: 处理弹性预测。例如,“基于过去 24 小时的体征,预测未来 24 小时的指标”。研究引入了一个专门的时间序列预测模型,将其输出作为外置大脑喂给模型。
三、 颠覆认知:瓶颈不在推理,而在预测
这项研究最令人深思的发现是:医疗 AI 的真正瓶颈,可能并不在于我们担心的逻辑推理能力。
数据显示,经过微调的模型在执行 SOFA 评分规则时,准确率极高(接近 100%)。哪怕是遇到了从未见过的例外情况(如慢性肾病患者计算 SOFA 分时需排除肾脏评分),模型也能通过微调学会处理,展现出惊人的泛化能力。
真正的死穴在于归纳预测。 当模型试图预测未来 24 小时的临床指标(如胆红素、肌酐)时,准确率断崖式下跌。即使是引入了专门的 TSF 模型,在处理稀疏、不规则的医疗数据时,F1 分数依然徘徊在低位(0.2 - 0.3)。
换句话说,AI 已经学会了像医生一样背书和算分,但它还学不会像老中医一样预测你今晚背疼。
独家洞察
垂直微调 > 通用大参数
目前行业内普遍追求千亿参数的通用医疗大模型,但本研究证明,在依从性要求极高的临床场景,小模型 + 高质量思维链微调才是性价比最高的路径。
建议: 医疗 AI 企业应将资源投入到将临床指南转化为结构化、口语化的微调数据集上,构建特定病种专家小模型,这才是商业化落地的捷径。
下一代医疗 AI :多模态时间序列预测
论文揭示了模型在处理时序数据上的无能。文本大模型天生不擅长处理心率、血压这种高频、稀疏的数值流。
建议: 单纯的自然语言处理技术无法解决临床预警问题。未来的技术高地在于LLM + TSF(时间序列预测)的深度融合。谁能率先解决 EHR 数据中普遍存在的稀疏性和不规则采样问题,谁就能真正掌握重症监护、慢病管理等高价值场景的主动权。
