
既要音质又要速度!DISTAR如何打造文娱产业的“全能嘴替”?

在短视频、有声读物、虚拟人蓬勃发展的文娱产业中,对高质量、个性化语音生成的需求正呈现爆炸式增长。如何让AI只需听一段简短的提示音,就能完美复刻说话人的音色和风格,并稳定、自然地播报长篇内容,一直是业界关注的技术焦点。
来自上海交通大学与字节跳动的研究团队联合提出了一种名为DISTAR(Diffusion over a Scalable Token AutoRegressive Representation)的全新语音生成框架,该研究旨在攻克零样本(Zero-Shot)文本到语音(TTS)的任务,即为未见过的说话人生成自然、可理解的语音。
DISTAR以其独特的架构设计,有望为文娱内容创作、开放域旁白和对话代理等场景带来革命性的“发声”体验。

论文地址:https://arxiv.org/pdf/2510.12210
一、 破局之道:在“离散”与“连续”间寻找最优解
要理解DISTAR的突破性,首先需要了解当前主流语音生成技术的两条路径及其局限性。
第一类路径类似于语言模型(如GPT),将语音视为离散的令牌序列,采用“自回归”方式逐个预测下一个声音片段 。这种方法的优势在于训练稳定,且可以通过温度系数等参数控制输出的多样性。然而,对于长语音序列,自回归模型容易积累误差,导致一致性差,且生成速度较慢 。
第二类路径则是基于“扩散模型”,在连续空间中对语音特征进行建模,有研究尝试结合自回归草稿生成与扩散模型细化,实现了令人印象深刻的零样本克隆。但连续空间建模面临优化复杂、对领域偏移敏感等问题,且往往依赖复杂的辅助模块(如时长预测器),增加了工程负担。
研究团队敏锐地捕捉到了第三条路径的潜力,即使用多码本离散表示。RVQ既能保持高保真音频重建,又保留了离散模型训练的稳定性,但其难点在于需要同时处理“时间”和“深度”两个维度的依赖关系。为了应对这一挑战,DISTAR应运而生。它是一个完全在离散RVQ码空间中运行的零样本TTS框架,创造性地将自回归语言模型与掩码扩散模型紧密耦合。
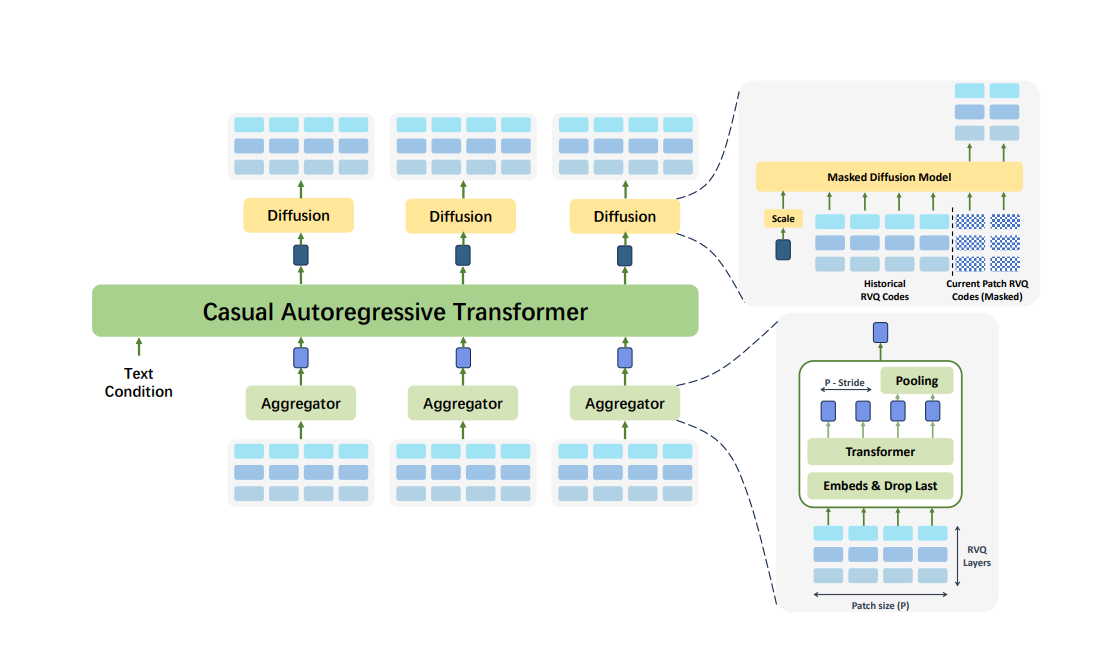
二、 DISTAR核心解密:“自回归草稿”与“扩散精修”的完美协奏
DISTAR的精妙之处在于其“块级并行”的生成策略,就像一位高明的画师与一群填色工匠的完美配合。
1. 自回归“打草稿”:把握全局脉络
首先,DISTAR利用一个因果自回归语言模型来生成“块级RVQ令牌”。这个过程就像是画师在画布上快速勾勒出画作的大致轮廓和时间演进脉络,捕捉粗略的时间依赖关系,生成一个紧凑的隐藏草稿 。
2. 掩码扩散“精修”:并行填充细节
随后,一个并行的掩码扩散Transformer模型接手工作。它基于自回归生成的草稿,在每个块内进行并行的“填充”操作。这并非传统的连续去噪过程,而是受大语言模型启发,在掩码位置上执行迭代的离散“解掩码”过程。
这种设计巧妙地结合了两者的优势。相较于纯自回归模型,DISTAR通过在每个块内建模帧内多码本耦合,提高了连贯性,并支持深度并行细化,在不牺牲稳定性的前提下减轻了长序列带来的暴露偏差问题。相较于连续扩散模型,DISTAR避免了高维连续潜在空间中的复杂优化问题,同时保留了高效的块级并行性。
值得一提的是,得益于全离散的设置,DISTAR无需依赖显式的时长预测器或强制对齐工具,即可实现高质量生成,大大简化了系统流水线。
三、 面向文娱实战:卓越性能与极致可控性
在文娱产业的实际应用中,模型的音质、稳定性和可控性至关重要。DISTAR在以下方面均展现出了显著优势:
1. 零样本复刻,SOTA级表现
在标准的LibriSpeech-PC和SeedTTS零样本基准测试中,DISTAR展现出了强大的实力。实验数据显示,DISTAR在语音生成的稳健性、说话人相似度和自然度方面,均超越或达到了当前最先进系统的水平,主观听感测试也进一步证实了其生成的语音在相似度和自然度上的优越性。
2. 灵活可控,适应多变场景
DISTAR完全在离散码空间运行的特性,为其带来了极高的推理可控性,这对于资源受限或需求多变的文娱应用场景极具价值。
多样性与稳定性的权衡:DISTAR支持在纯贪心解码设置下获得稳健的质量,也支持基于采样的解码方式,从而在生成结果的多样性和确定性之间进行细粒度控制。
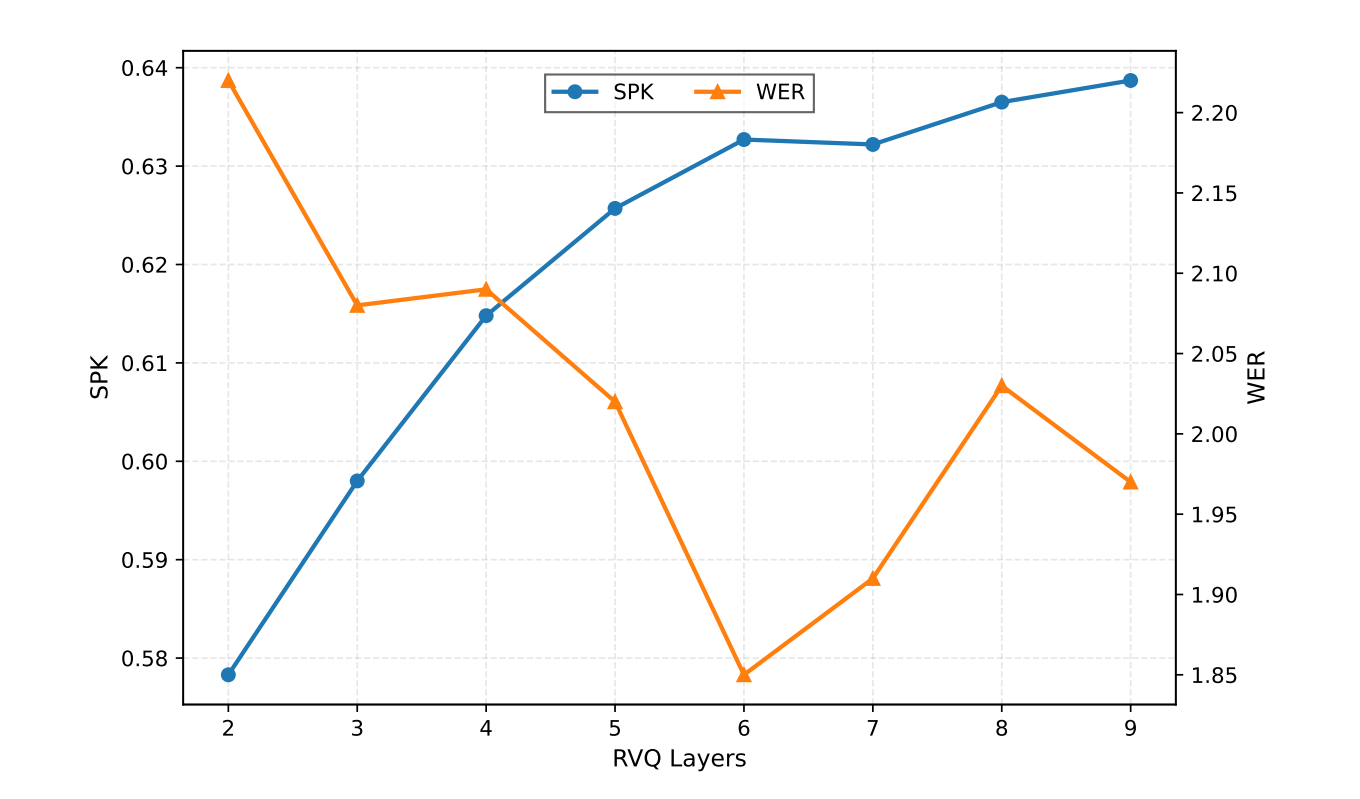
“即插即用”的比特率控制:这是一个非常实用的功能。研究人员发现,RVQ的上层主要编码声学细节而非语言内容。因此,DISTAR允许在推理时直接剪枝上层RVQ层,从而在无需重新训练的情况下,实时控制计算量和比特率,以适应不同的带宽和延迟约束,这意味着在对音质要求极高的电影配音中可以使用全量模型,而在对实时性要求高的移动端游戏中则可以无缝切换到低比特率模式。
结语
DISTAR模型的提出,标志着AI语音生成技术在离散表示与扩散模型结合的道路上迈出了坚实的一步。它不仅在技术层面解决了长程一致性、优化难度和并行效率等核心痛点,更以其卓越的零样本生成能力和灵活的可控性,为文娱产业的内容创作提供了强有力的工具。随着技术的不断迭代,我们有理由期待,未来的虚拟角色、有声读物和影视配音,将拥有更加真实、生动且富有表现力的“灵魂之声”。
