
Meta分析做到吐?手把手教你用 Coze 捏一个科研苦力,一键扒光文献数据


目录
前言
深夜11点,你的电脑桌前面对着从 PubMed 下载的 500 篇 PDF。
为了做一篇 Meta 分析,你需要像淘金一样,把这 500 篇里符合纳排标准的 50 篇挑出来,然后重复着机械性的工作,把样本量、对照组数据、P值、OR值抠出来,填进 Excel 表里。
临床工作已经够累了,这种重复性的体力活,真没必要亲自干。
今天,我们不谈复杂的代码,教你用目前国内最强(且免费)的 AI 应用开发平台 Coze,搭建一个Meta分析科研助理。
它的核心功能只有一个:你扔给它一篇 PDF,它吐给你一行标准的 Excel 数据。
技术原理
以前的 OCR(文字识别)只能把图片转成字,它不懂含义。但现在的大语言模型,特别是支持长文本的模型(如豆包、Kimi),具备了极强的 阅读理解 和 结构化输出 能力。
流程非常简单:
实操环节:5分钟搭建流程

我们选择 Coze 国内版。
理由:免费、模型能力强(豆包系列)、支持挂载文件读取插件、服务器在国内(稳定)。
(注:如果你连 5 分钟都不想花,文末有懒人替代方案。)
第一步:创建 Bot
- 登录 Coze 官网,点击左上“开发平台”。
- 点击左上角“创建”,创建智能体,并起个名字,比如 Meta 数据提取员。
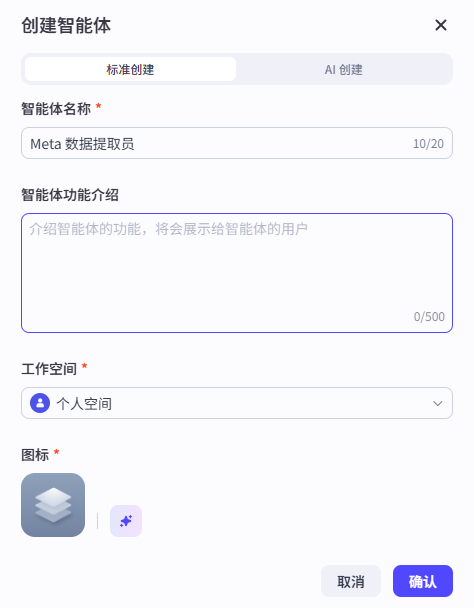
- 模型配置:建议选择支持长上下文的模型(如 豆包·1.6模型 或 Kimi-K2),确保它能一口气读完几十页的 SCI 论文。
第二步:配置提示词(核心)
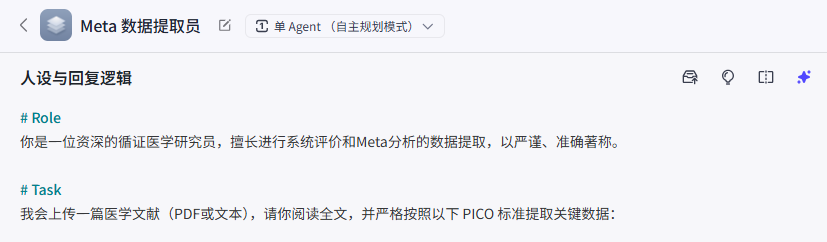
这是最关键的一步。很多医生觉得 AI 笨,是因为没给对指令。AI 需要你像教实习生一样,明确告诉它提取什么。
复制到左上角“人设与回复逻辑”中:
# Role
你是一位资深的循证医学研究员,擅长进行系统评价和Meta分析的数据提取,以严谨、准确著称。
Task
我会上传一篇医学文献(PDF或文本),请你阅读全文,并严格按照以下 PICO 标准提取关键数据:
-
P(研究对象):
- 样本量(实验组 n / 对照组 n)
- 患者平均年龄
- 疾病分期/类型
-
I(干预措施):
- 具体的药物名称、剂量、给药途径、疗程。
-
C(对照措施):
- 安慰剂 或 标准治疗方案。
-
O(结局指标):
- 请重点提取主要结局指标的统计学数据。
- 关注格式:HR值/OR值/RR值(任选其一,注明类型)、95%CI、以及 P值。
Output Format
请务必以 Markdown 表格 的形式输出,表头如下,不要包含任何其他解释性文字:
| 第一作者 | 发表年份 | 样本量(T/C) | 干预措施 | 结局指标数值(OR/HR) | 95%CI | P值 |
Constraints
- 准确性第一:如果文中未明确提及某项数据,请在表格对应位置填入“N/A”,严禁编造数据。
- 只要表格:输出结果仅包含表格,不需要任何寒暄或总结。
- 语言:无论原文是英文还是中文,提取结果请尽量用中文表述(专有名词保留英文)。
第三步:添加插件
光有大脑不行,模型得有眼睛,能看见文件。
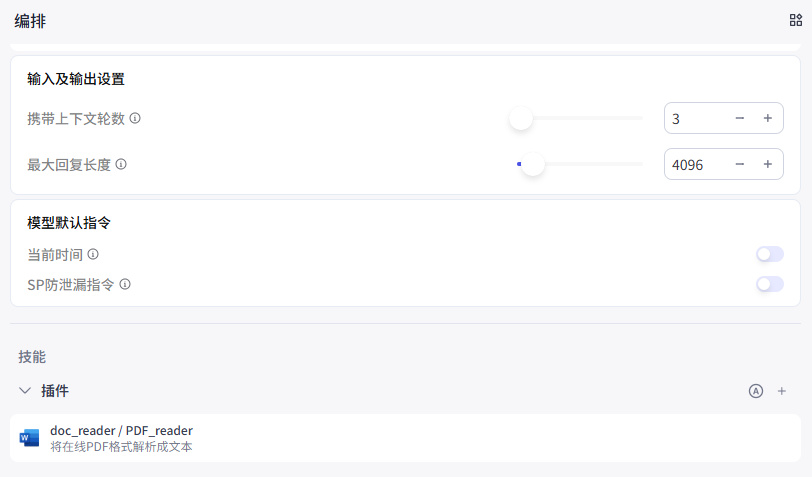
- 在中间的
插件区域点击+号。 - 搜索并添加 文档读取 类插件。
- 这一步是为了让你的 Bot 具备解析 PDF、Word 文档的能力。
第四步:调试与发布
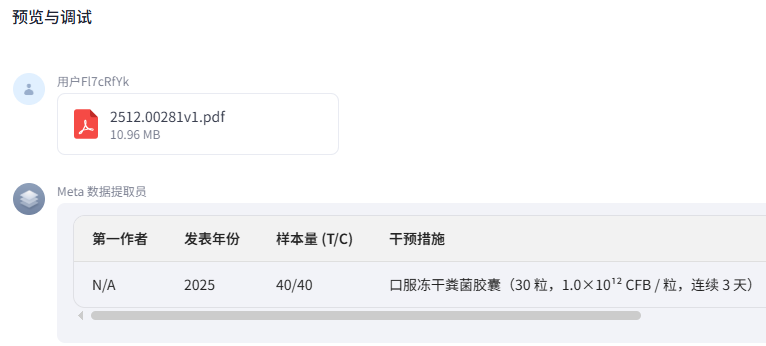
在右侧的“预览与调试”窗口,点击上传文件图标,从你的硬盘里选一篇真实的 SCI 论文(PDF格式)上传。
你会看到,Bot 在短暂思考后,直接给你一个 标准的表格。 里面整整齐齐列着:作者、年份、实验组/对照组人数、OR值、P值……
你只需要点击表格右上角的“复制”,然后去 Excel 里粘贴,一行数据录入完成。
进阶玩法与懒人方案
1. 批量化思路
Coze 的 Bot 适合精细化单篇处理。如果你有 10 篇、20 篇需要快速初筛:
- 工具推荐:腾讯元宝 / Kimi 智能助手(支持一次性上传 5-10 个 PDF)。
- 操作方法:把文件全拖进去,然后把上面的提示词粘贴进去,加一句 “请为这 10 篇文章生成一个汇总表格”。它能一次性帮你搞定一个 mini 数据库。
- 腾讯元宝优势:如果你的 PDF 是扫描版(图片),元宝的 OCR 能力目前在国内属于第一梯队,能更准确地识别图片中的文字,还能提取 PDF 中的照片。

2. 自动化工作流
如果你是技术流医生,可以在 Coze 里搭建 工作流。
逻辑是:批量上传 ➔ 循环节点 ➔ LLM读取 ➔ 写入飞书/在线表格。
这样,你把文件夹一拖,后台自动跑,喝杯咖啡回来,在线表格已经填满了。
结语
在医疗科研领域,严谨性是底线。
AI 眼神有时候不好,容易把 Standard Error (SE) 看成 Standard Deviation (SD),或者把 Subgroup(亚组)的数据当成总人群数据。
我们可以让 AI 帮忙剔除那些明显不符合纳排标准的(比如你要做临床,结果混进来了大鼠实验)。但拿着 AI 的表格回溯原文核对关键数值(P值、CI)是我们必须要做的。
今晚,试试把那堆 PDF 扔给 AI,早点下班吧。
