
医疗机构如何建立私有数据集


目录
很多医生问我,为什么我用 DeepSeek 问诊,它总是说一些正确的废话?
原因很简单:通用模型是学的全互联网的知识,缺少你在科室里沉淀了十几年的经验。
对于医疗机构而言,真正有价值的 AI 不是模型本身(尽管现在开源模型已经很强了),而是沉睡在电子病历(EMR)、影像系统(PACS)里的临床数据。
要把这些数据变成 AI 能听懂的训练教材,你就需要构建一个私有数据集
今天,我将教你利用国内最大的模型社区,魔塔社区(阿里),搭建属于你医院的私有数据仓库。
一、 为什么选择魔塔社区?

在构建医疗 AI 的技术栈选择上,只有两个核心考量:合规和速度。
- 合规性:Hugging Face 虽然是全球最大的社区,但在国内访问困难,且将敏感的医疗数据上传至境外服务器存在极大的合规风险。
- 本土优势:魔塔社区(ModelScope) 是阿里达摩院推出的,服务器在国内,上传下载速度极快,且原生支持中文环境。
最关键的是,DeepSeek 等顶流开源模型在魔塔上都有第一时间同步。这意味着你的数据一旦上传,可以无缝对接这些模型进行微调。
你可以去魔塔社区搜索关键词“医疗”或“medical”。你会发现已经有大量公开数据集,但那些都是别人的。今天,你要建立的是属于自己的数据壁垒。
二、 实操拆解:从数据准备到上传
不需要复杂的编程,只要会基础的 Python 操作,就能跑通全流程。
1. 数据准备
不要直接把 Excel 表格丢上去。大模型训练(微调)最喜欢的数据格式是 JSONL,通常包含以下字段:
- Instruction(指令)
- Input(输入)
- Output(输出)
小技巧: 可以直接使用 DeepSeek 帮你转换格式,DeepSeek 最多支持 50 个,每个 100MB 的文档分析。

假设你有一批问诊记录,可以将其整理成如下格式(保存为 train.jsonl):
{"instruction": "患者主诉胸痛,心电图显示ST段压低,请给出诊断建议。", "output": "结合患者症状及心电图表现,优先考虑非ST段抬高型心肌梗死(NSTEMI),建议立即进行心肌酶谱检查..."}
{"instruction": "糖尿病患者,二甲双胍治疗后出现乳酸酸中毒风险,如何调整?", "output": "应立即停用二甲双胍,进行补液和纠正酸中毒治疗..."}
注意:数据的质量决定了 AI 的智商(Garbage in, Garbage out)。
2. 环境配置
你需要安装 ModelScope 的 Python SDK。在你的本地终端或者服务器上运行:
pip install modelscope
3. 创建云端仓库
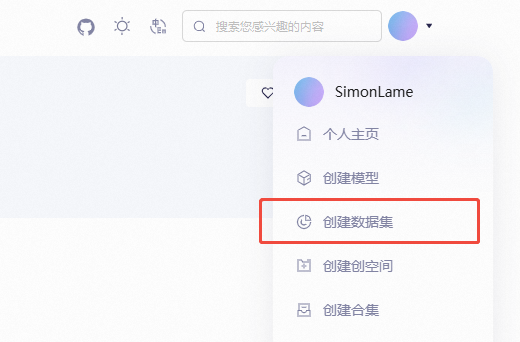
-
点击右上角头像,选择 “创建数据集”。
-
填写信息: 中文名:例如“某医院心内科问诊微调数据”。 英文名:例如
cardiology_instruction_tuning。 License:如果是私有数据,随便选一个即可。 可见性:一定要选择“非公开”。这样除了你授权的账号,没人能看到这些数据。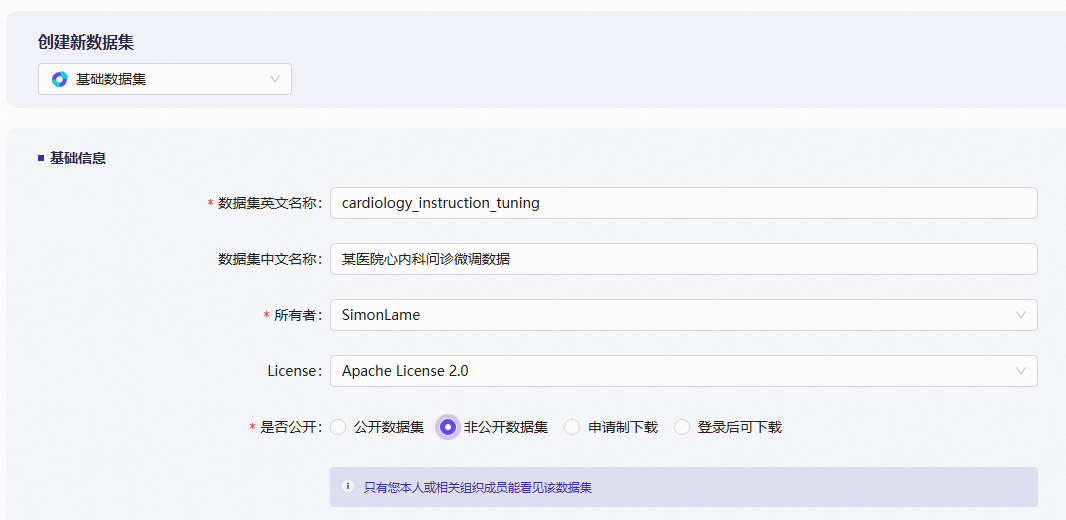
4. 上传数据
很多教程教你用 Git 命令,对于非程序员来说太繁琐。我推荐直接用 Python SDK 上传,更稳定,且能做自动化集成。
首先,你需要获取一个访问令牌。在魔塔社区个人中心的访问令牌页面复制。
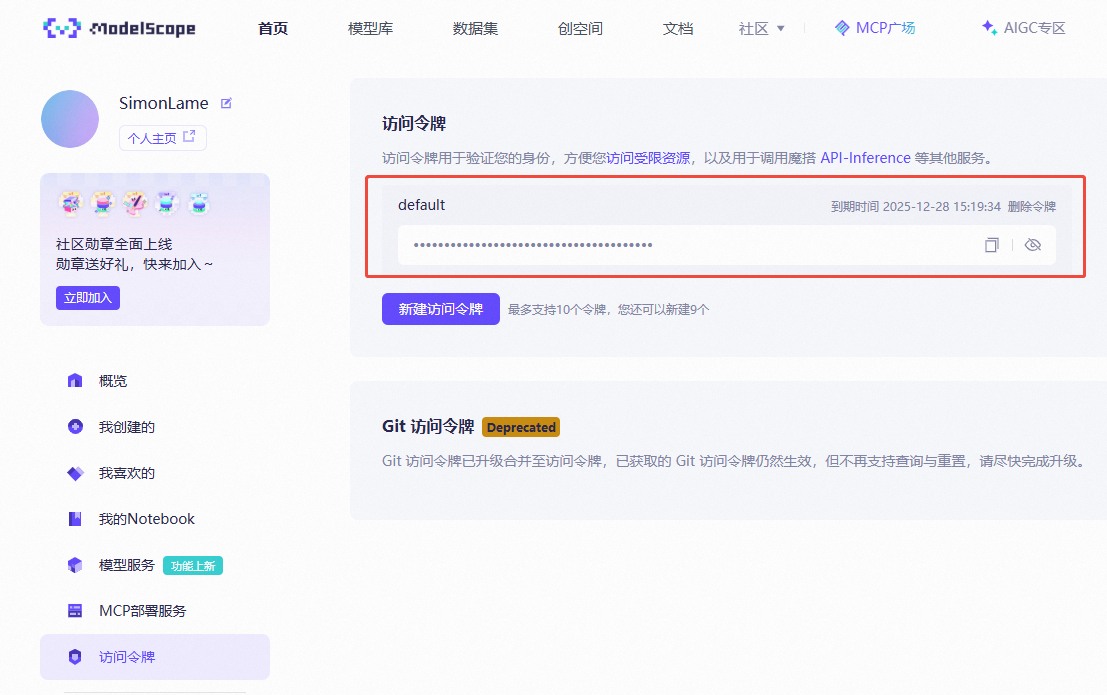
新建一个 Python 文件 upload_data.py,粘贴以下代码:
from modelscope.hub.api import HubApi
1. 登录
将下面的字符串替换为你自己的 Access Token
YOUR_ACCESS_TOKEN = ‘你的访问令牌粘贴在这里’
api = HubApi()
api.login(YOUR_ACCESS_TOKEN)
2. 配置参数
你的用户名(在个人中心看)
owner_name = ‘你的用户名’
你刚才创建的数据集英文名
dataset_name = ‘cardiology_instruction_tuning’
本地文件路径
local_file_path = ‘./train.jsonl’
3. 上传文件
print("开始上传…")
try:
api.upload_file(
path_or_fileobj=local_file_path, # 本地文件在哪里
path_in_repo=‘train.jsonl’, # 上传到云端叫什么名字
repo_id=f"{owner_name}/{dataset_name}", # 仓库ID
repo_type=‘dataset’, # 指定类型为数据集
commit_message=‘upload initial medical data’ # 提交备注
)
print("上传成功!")
except Exception as e:
print(f"上传失败: {e}")
运行这段代码,你的数据就躺在魔塔社区的私有仓库里了。
5. 验证与使用
数据上传后,如何让模型读取呢?非常简单。
from modelscope import MsDataset
加载你的私有数据集
注意:如果是私有数据集,运行此代码的环境也需要先通过 api.login() 登录
ds = MsDataset.load(
‘你的用户名/cardiology_instruction_tuning’, # 数据集ID
split=‘train’ # 读取训练集
)
打印第一条数据看看效果
print(ds[0])
看到控制台输出了你刚才整理的病例数据,就说明打通了 数据 - 仓库 - 代码 的闭环。
三、 如何管理数据版本?
医疗数据是动态更新的。今天修正了几个错误的诊疗方案,明天新增了 100 个病例,怎么办?
魔塔社区底层基于 Git 版本控制。
你不需要每次都删了重传,只需要重新运行上面的上传代码,修改 commit_message(例如改为“新增100例高血压病例”),系统会自动帮你记录数据的演变历史。如果某次更新出错了,你甚至可以回滚到上一个版本,这对科研的可复现性至关重要。
四、 总结
通过魔塔社区,你不需要自建昂贵的机房和数据中台,就能拥有一个安全、高速、版本可控的私有数据集仓库。
下一步,你只需要把 DeepSeek 或者 Qwen 拉下来,指向这个仓库,就能训练一个真正懂你医院业务的专属 AI。
