
AI 透明化反而增加误诊风险?国内最新研究发现


文 | 小A
核心资料来源
论文: When Medical AI Explanations Help and When They Harm (2025.12) 发布机构: 武汉大学与北京大学联合研究团队 查阅链接: arXiv:2512.08424
目录
一、 核心发现:AI 解释的双面效应
研究团队构建了 15 个典型的临床处方场景(如心肌梗死、高脂血症的药物选择),并将 AI 的基础准确率设定为 73.4%。
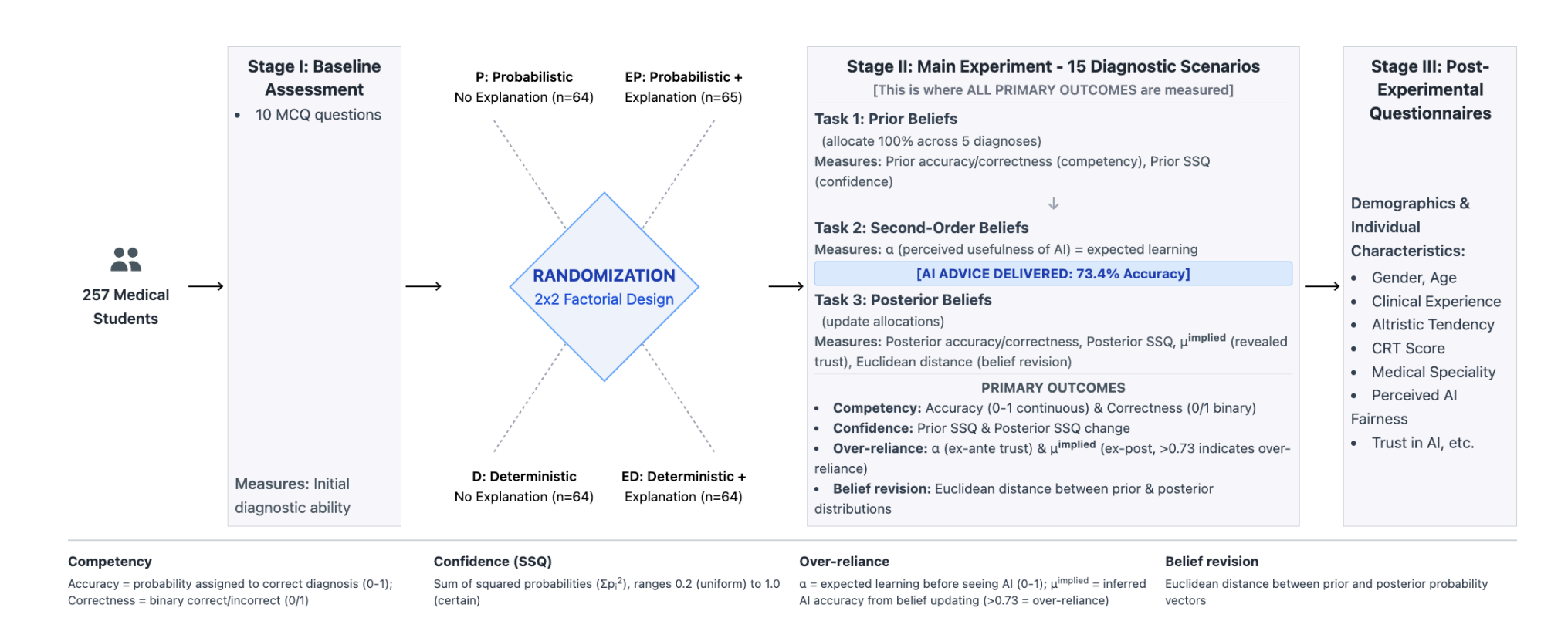
实验数据表明,AI 提供的解释对医生决策的影响呈现出显著的不对称性:
1. 正向效应:锦上添花 当 AI 建议正确时,附加解释能将医生的诊断准确率从 87.4% 提升至 93.7%。这表明,在 AI 准确的情况下,解释确实有助于医生理解并采纳建议。
2. 负向效应:误导加深 当 AI 建议错误时:
- 无解释:医生凭借自身专业知识,准确率维持在 14.3%;
- 有解释:一旦 AI 提供了看似合理的解释,医生的准确率跌至 9.4%。
为什么会出现这种情况?
大模型具备极强的语言组织能力,即使在生成错误的诊断结果时,它仍能调用专业的医学术语和逻辑进行论证。这种**“不管对错,听起来都很专业”**的特性,导致医生难以分辨,从而被误导。
二、 被掩盖的不确定性
为了降低误导风险,业内常采用概率提示的策略,即让 AI 输出“建议 A 药(可信度 70%)”,而非绝对的“建议 A 药”。
但本研究发现,概率 + 解释 的组合反而加剧了误判。
- 在直接推荐下,AI 犯错时的解释导致医生准确率只下降 3.1%。
- 在概率推荐下,AI 犯错时的解释导致医生准确率下降 6.6%。
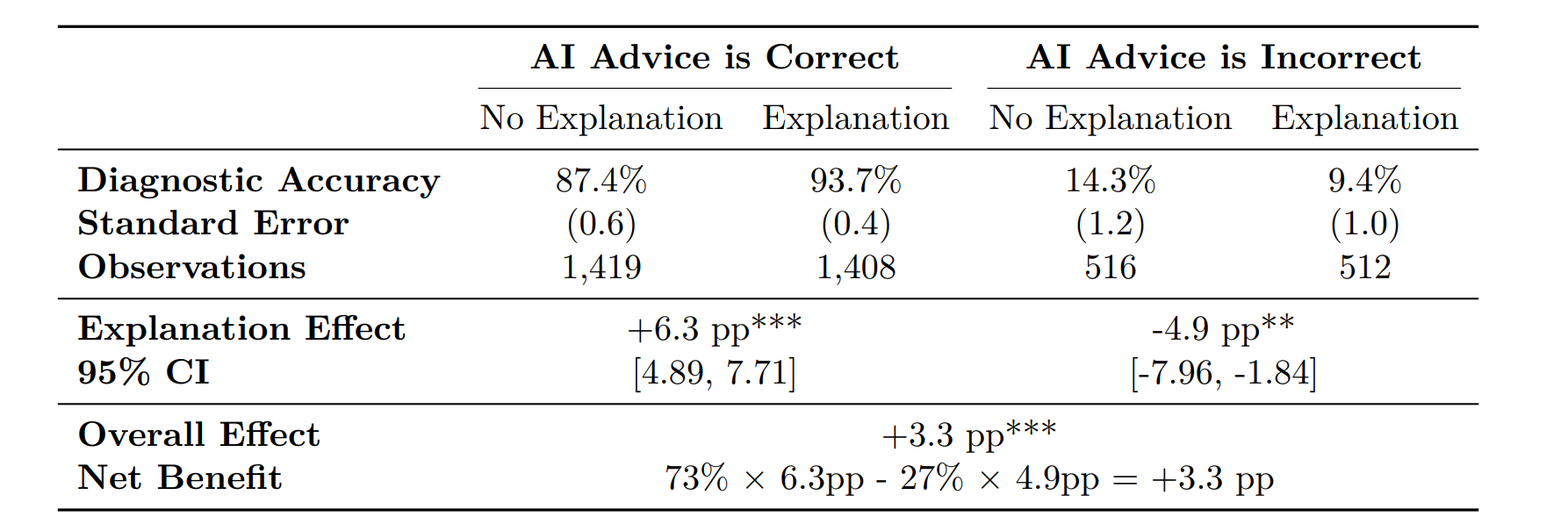
人类的反逻辑心理: “我不确定”本身应是一种风险提示,但详细的解释加上逻辑论证,反而消解了医生对低概率的警惕。医生倾向于认为:“既然 AI 能分析得如此透彻,这个 70% 的概率应该是可靠的。”
这种“我不确定”的表述,反而让医生更相信 AI 的判断。
三、 受影响群体:新手受益,专家受损
研究进一步分析了不同能力水平的医生受到的影响,结果令人深思:
-
自信的新手 他们是从 AI 解释中获益最大的群体。由于自身诊断准确率较低,AI 的介入(哪怕只有 73% 的准确率)对他们而言起到了纠错作用,净收益为正。
-
谨慎的专家 他们受到的负面影响最大。 这类医生在面对疑难病例时通常保持审慎。单当 AI 给出一个错误的诊断并附带详尽解释时,这种权威感容易动摇他们的判断。
数据显示:当 AI 犯错时,这类医生的准确率下降幅度最大,达到 12.4%。
这表明,目前的 AI 解释机制可能会惩罚那些谨慎的专业人士,导致高质量的人类判断被低质量的 AI 建议带偏。
四、 独家洞察与建议
基于上述研究结论,对于医疗机构管理者和 AI 产品开发者,我们提炼出以下三点建议:
-
设定解释阈值 并非所有 AI 都适合提供解释功能。有时战略性沉默可能是更安全的策略。只有当 AI 的置信度极高时,才展示详细解释。
-
4针对医生的反向培训 医院在进行 AI 辅助诊疗培训时,不应仅关注系统操作,更应强调对 AI 解释的批判性阅读。特别是当 AI 给出概率性建议时,医生应被训练去主动寻找反面证据,而非顺着 AI 的逻辑进行验证。
-
可隐藏的交互界面 透明度设计应因人而异,建议默认隐藏解释,避免干扰专家的直觉判断,仅在医生主动点击时展开。 据测算,这种动态的透明度设计,能将因误诊造成的社会成本降低约 14.3%。
结语
这项研究提醒我们,在医疗 AI 领域,技术透明并不等同于临床有效。
未来的医疗 AI 发展,不应仅仅追求生成更长的解释文本,而应致力于构建更科学的人机协作机制。让 AI 在该解释的时候解释,该沉默的时候沉默,才能真正成为医生的得力助手,而非干扰源。
