
写长篇小说记不住配角设定?用 Dify 打造创作记忆库


如果你正在写一部长篇小说或剧本,那你一定经历过这些时刻:
第 20 章精心塑造了一个性格鲜明的龙套角色,咖啡馆老板,身高 180cm,戴黑框眼镜,爱讲冷笑话。
第 60 章老张再次出场,你已经完全记不得他的名字,长什么样了,只能疯狂往前面翻找。
根据米勒定律,人类大脑的工作记忆容量只有7±2个信息单元,我们的记忆是有限的。
当你写到 50 万字时,前面 30 万字的细节已经模糊了。
通常我们怎么做?开个 Excel 表拉人设,费时费力。
一部长篇小说通常包含:
- 字数:30-100 万字
- 主要角色:10-30 个
- 次要角色/龙套:50-200 个
- 地点设定:20-50 个
- 时间跨度:数月到数十年
今天给各位创作者安利一个神器,Dify(扣子同理)。简单说,我们要用它给你的 AI 装一个硬盘,把你的小说设定塞进去。以后你问它:“吴邪上次出场穿的啥?”它就能秒回,绝不瞎编。
目录
一、Dify 知识库
很多宝子平时习惯用 Deepseek 或者文心一言,他们的确好用,但最大的问题是 没有长期记忆。
Dify 是一个免费的模型应用开发平台,其中的知识库功能,就是专门解决 "AI 没有记忆" 这个问题。
1.1 核心原理:RAG
当对话过长时:
你:第100章时林立什么境界
AI:林立是谁?(一脸懵逼)
使用 Dify 知识库后:
你:第100章时林立什么境界
Dify:正在检索"林立"相关信息...
找到匹配内容:林立,炼气七层...
名词解释:
- RAG:检索增强生成。简单说就是 先查资料,再回答。
- Embedding:向量化。把文字转成数字,让 AI 能快速找到相关内容。你不需要懂原理,只需要知道 它能帮你秒速查资料。
二、为什么选 Dify?
理由一:完全免费且开源
- Dify Cloud(在线版):每月 10000 次免费调用
- 本地电脑版:完全免费,数据在自己服务器上
理由二:支持多种文件格式
- TXT、DOCX、PDF、Markdown
- 单个文件最大 15MB,单次可上传 5 个文件
- 图片也能提取(JPG、PNG、GIF,< 2MB)
理由三:灵活的索引模式
- 经济型:速度快,成本低,适合日常查询
- 高质量:精度高,适合复杂设定查询
理由四:与主流大模型无缝对接
- OpenAI(GPT-4、GPT-3.5)
- Anthropic(Claude)
- DeepSeek(V3、R1)
- 国产模型(通义千问、文心一言、豆包等)
三、实战演练
我们以一个武侠小说《江湖往事》为例,手把手教你搭建知识库。
准备工作:整理你的创作资料
在开始之前,先把你的创作资料整理成以下文件(TXT 格式即可):
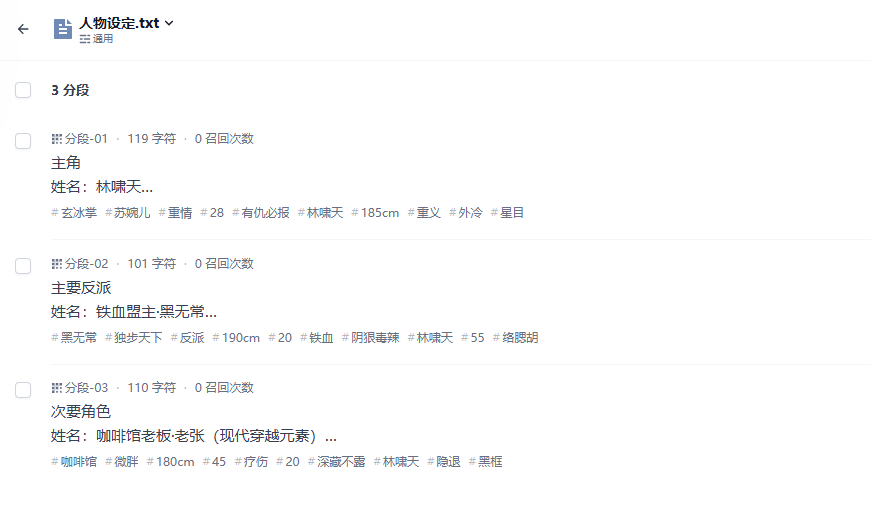
文件 1:人物设定.txt
# 主角
姓名:林啸天
年龄:28岁
外貌:身高185cm,剑眉星目,左脸颊有一道刀疤
性格:外冷内热,重情重义,但有仇必报
武功:玄冰掌(七成功力),轻功卓绝
背景:天山派第三代弟子,师父是掌门林无尘
恋人:苏婉儿(青楼女子,第15章初遇)
主要反派
姓名:铁血盟主·黑无常
年龄:55岁
外貌:身高190cm,满脸络腮胡,双目赤红
性格:阴狠毒辣,心机深沉
武功:铁血神功(大成),刀法独步天下
背景:20年前灭了林啸天全家,夺取《玄冰心法》
次要角色
姓名:咖啡馆老板·老张(现代穿越元素)
年龄:45岁
外貌:身高180cm,微胖,戴黑框眼镜
性格:话痨,爱讲冷笑话,实则深藏不露
秘密:前朝锦衣卫高手,隐退江湖开咖啡馆
初次出场:第20章,林啸天在咖啡馆疗伤
文件 2:地点设定.txt
# 天山派
位置:西域天山之巅,海拔4000米
建筑:青石砌成,共108间房屋,主殿名"凌霄殿"
特产:雪莲(可疗伤),寒冰剑(镇派之宝)
初次出场:第1章,林啸天童年回忆
黑市拍卖行
位置:长安城西三十里,地下三层
特色:每月初一午夜开市,交易违禁武功秘籍和奇珍异宝
守卫:八大金刚(每人都是一流高手)
初次出场:第35章,林啸天潜入寻找《玄冰心法》下半部
老张的咖啡馆
位置:长安城东街17号
装修:复古风,墙上挂满了古剑和字画
招牌:蓝山咖啡(实则掺了药材,能助人凝神)
初次出场:第20章
文件 3:时间线.txt
第1-5章:林啸天童年,天山派被灭(公元1850年)
第6-10章:林啸天隐姓埋名,拜入少林学艺(1850-1860年)
第11-15章:林啸天下山复仇,遇见苏婉儿(1860年)
第20章:林啸天在老张咖啡馆疗伤(1861年春)
第35章:黑市拍卖行夺宝(1861年秋)
第50章:决战黑无常(1862年冬)
步骤 1:注册 Dify 并创建知识库
1.1 注册 Dify 账号
访问 https://cloud.dify.ai/signin (也可以在塔猴搜索本地部署教程)。用邮箱注册,免费版足够个人使用。
1.2 创建知识库
点击上方导航栏 "知识库" → 选择 "创建知识库"。
1.3 选择数据源
选择 "导入已有文本",然后上传刚才准备的 3 个 TXT 文件。
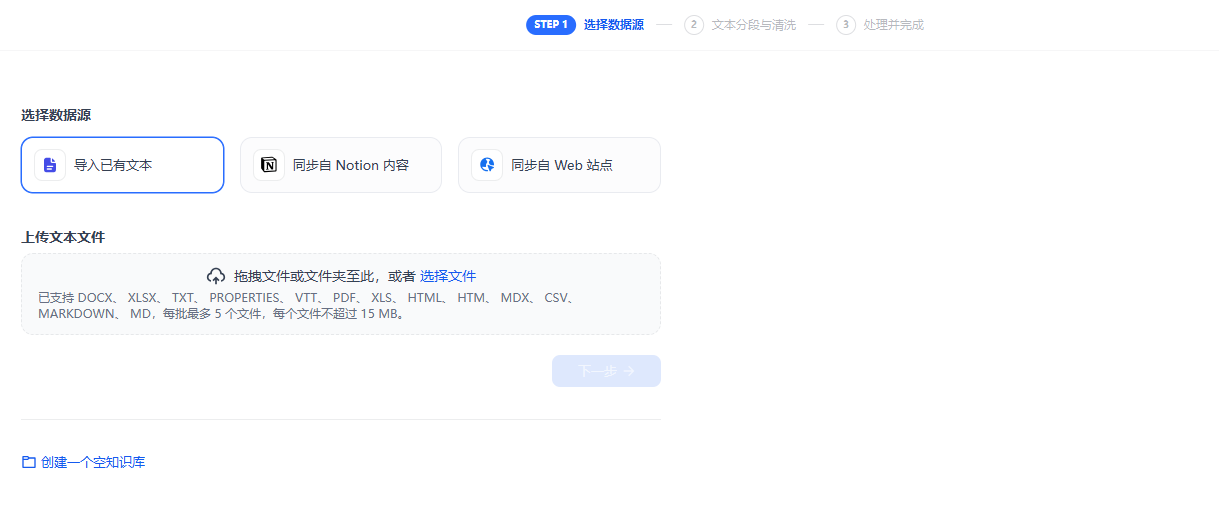
注意事项:
- 单个文件最大 15MB(对于纯文本,足够容纳 50 万字)
- 单次最多上传 5 个文件(如果文件多,可以分批上传)
- 知识库创建后,数据源无法更改(所以文件命名要清晰)
步骤 2:选择索引模式(重点!)
上传文件后,系统会让你选择 "索引模式":
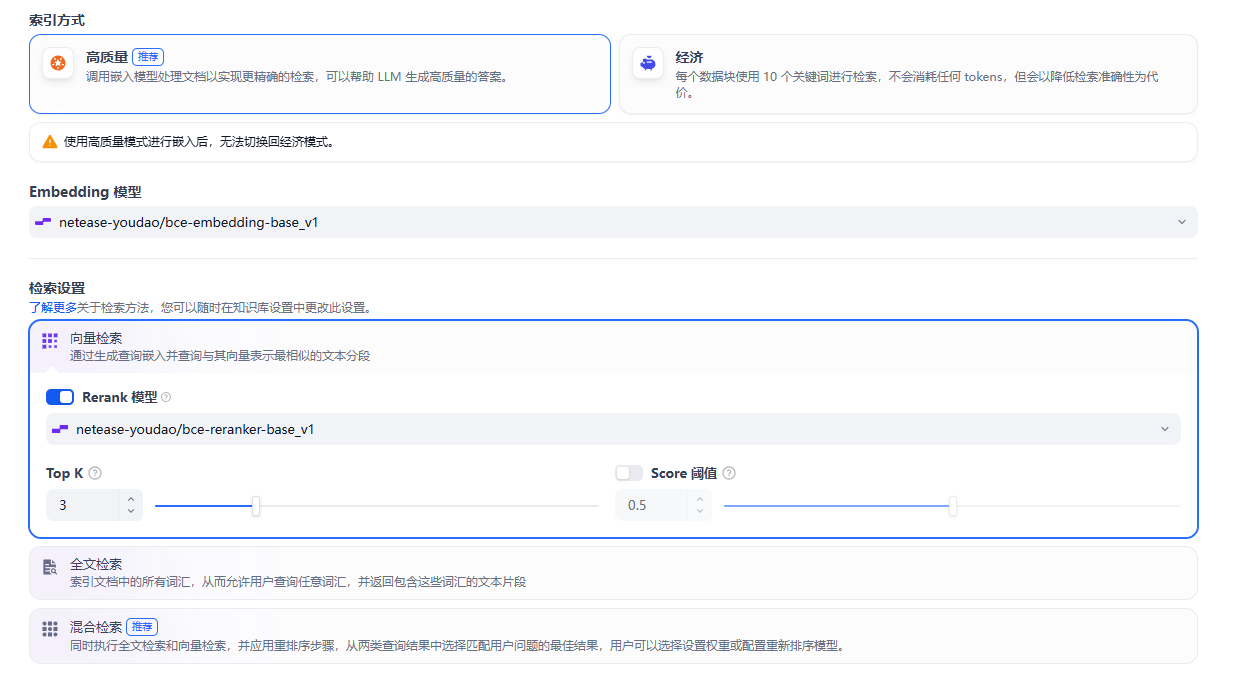
| 模式 | 适用场景 | 成本 | 速度 | 精度 |
|---|---|---|---|---|
| 经济型 | 日常查询,简单设定 | 低 | 快 | 中 |
| 高质量 | 复杂设定,精细查询 | 高 | 较慢 | 高 |
如何选择?
选经济型的情况:
- 你的设定比较简单(人物 < 50 个,地点 < 20 个)
- 主要查询 "某个角色叫什么名字"、"某个地点在哪里" 这类基础信息
- 预算有限,省钱
选高质量的情况:
- 设定非常复杂(人物 > 50 个,地点 > 30 个,时间线交错)
- 需要查询 "A 角色和 B 角色的关系"、"C 地点发生过哪些事件" 这类关联信息
- 对精度要求极高,不能出错
实测对比(以人物设定.txt 为例):
| 查询问题 | 经济型结果 | 高质量结果 |
|---|---|---|
| "林啸天的师父是谁?" | ✅ 正确:林无尘 | ✅ 正确:林无尘 |
| "老张的咖啡馆在哪条街?" | ✅ 正确:东街 17 号 | ✅ 正确:东街 17 号 |
| "林啸天和苏婉儿是在第几章相遇的?" | ❌ 未找到(信息分散) | ✅ 正确:第 15 章 |
| "天山派被灭是哪一年?" | ✅ 正确:1850 年 | ✅ 正确:1850 年,并补充细节 |
结论:如果你的查询大多是 单点信息,用经济型。如果需要 关联查询,用高质量。 对于已经有 10 万字的长篇创作,我推荐 高质量模式,虽然贵一点,但能避免前后矛盾。
步骤 3:配置分段规则
上传文件后,Dify 会把长文本 切成小段(分段),以便 AI 快速检索。
分段规则配置:
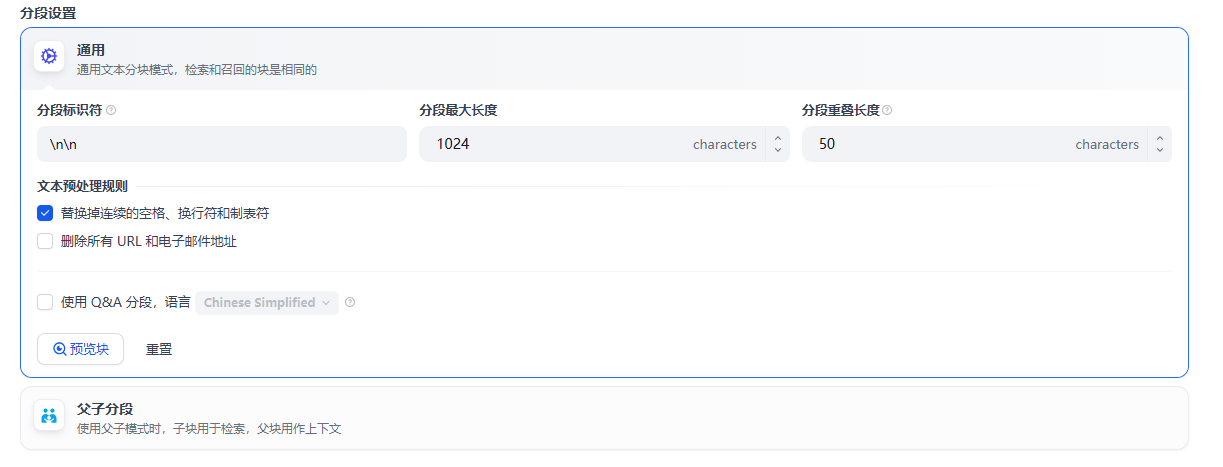
- 自动分段(推荐):Dify 根据段落、标题自动切分
- 自定义分段:你可以设置 "按多少字切分"、"按标识符切分"
最佳选择:
如果你的文件结构清晰(用了 # 标题标记),选 自动分段。
如果文件是一整段文字,建议选 自定义分段,每 500-1000 字切一段。
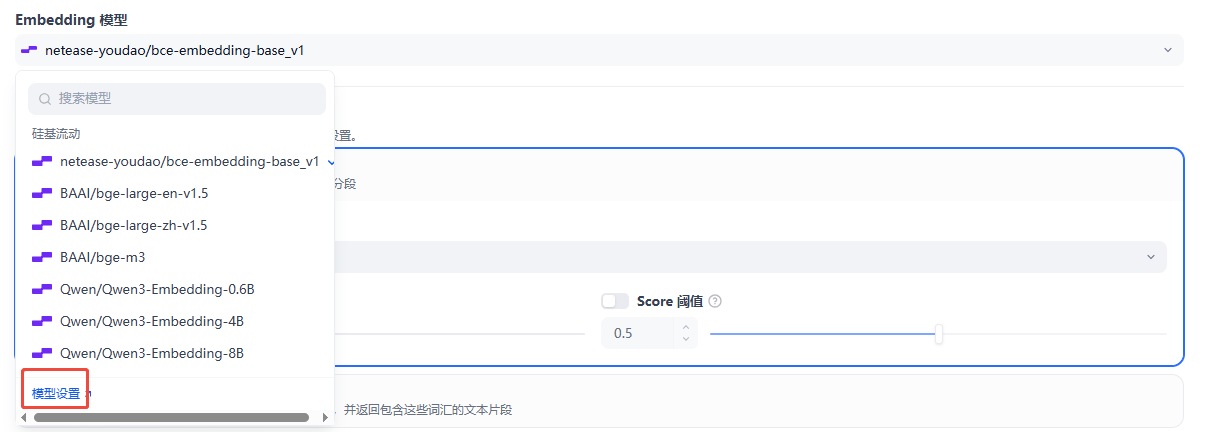
步骤 4:配置嵌入模型(Embedding 模型)
什么是嵌入模型? 简单说,就是 把文字转成数字 的工具,让 AI 能快速匹配相关内容。
步骤 5:创建 AI 应用
知识库搭建完成后,接下来创建一个 AI 应用,把知识库关联上去。
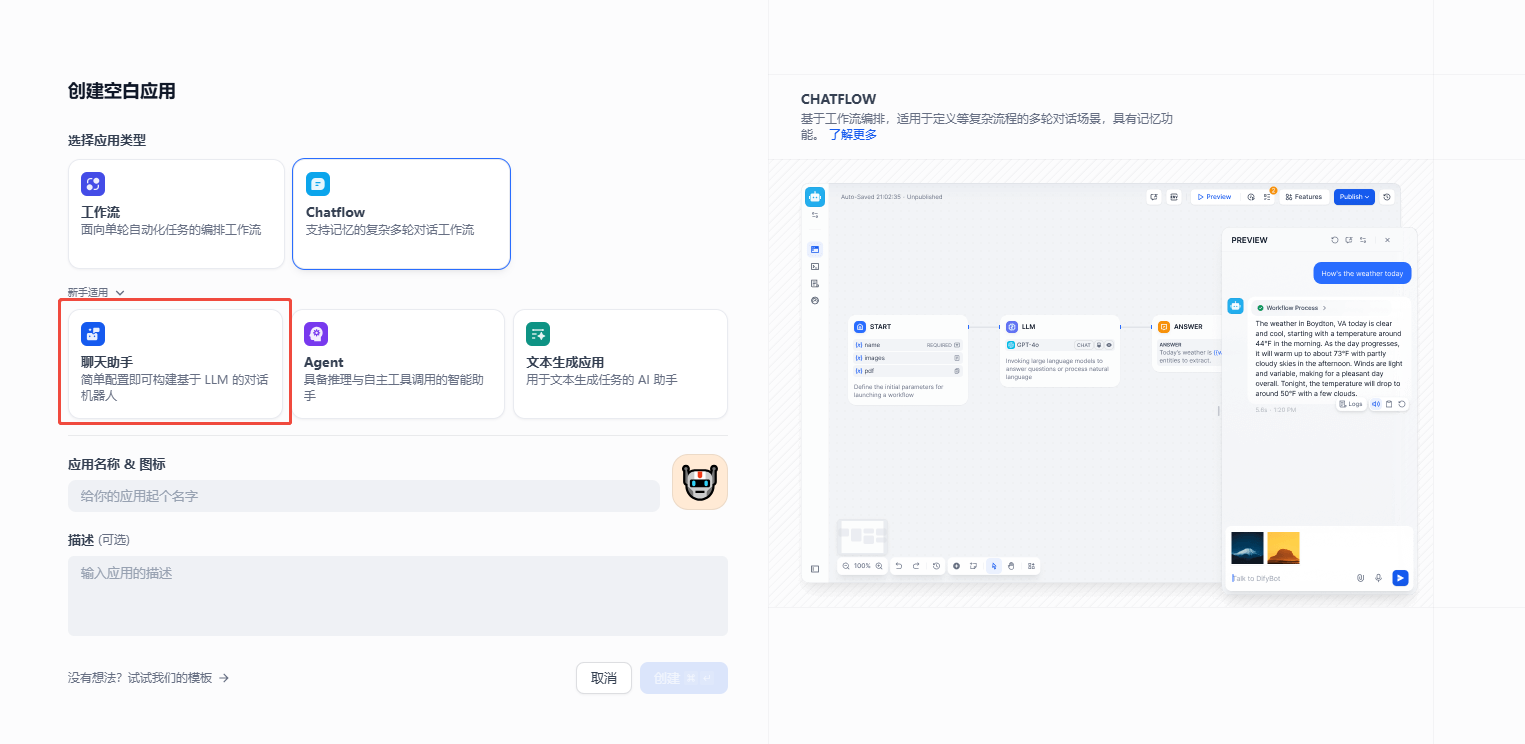
5.1 创建聊天助手
点击上方 "工作室" → "创建应用" → 选择 "聊天助手"。
5.2 配置应用信息
- 名称:"江湖往事创作助手"
- 描述:"帮我记住《江湖往事》的所有人物、地点、时间线"
5.3 关联知识库
在开始节点这里 添加 知识检索,添加上传的知识库。
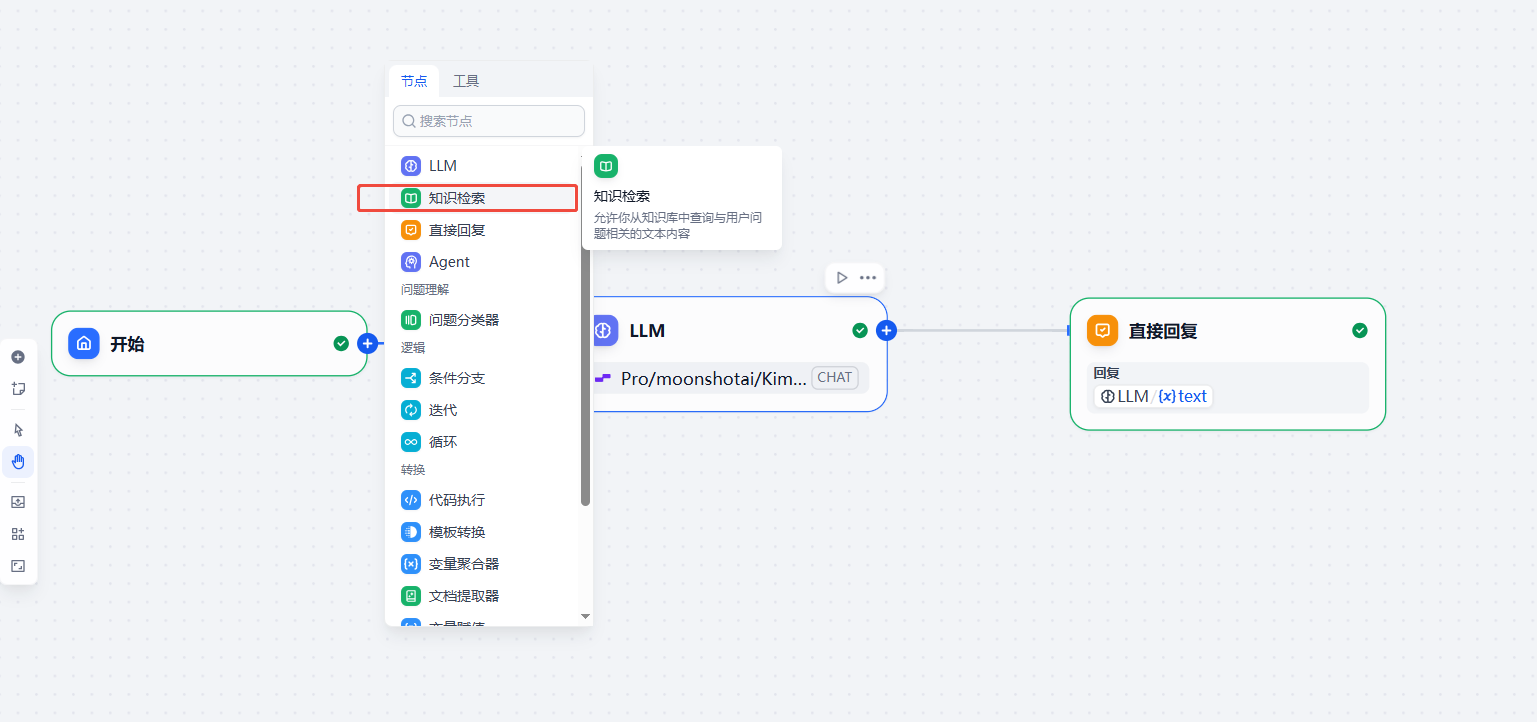
5.4 编写提示词
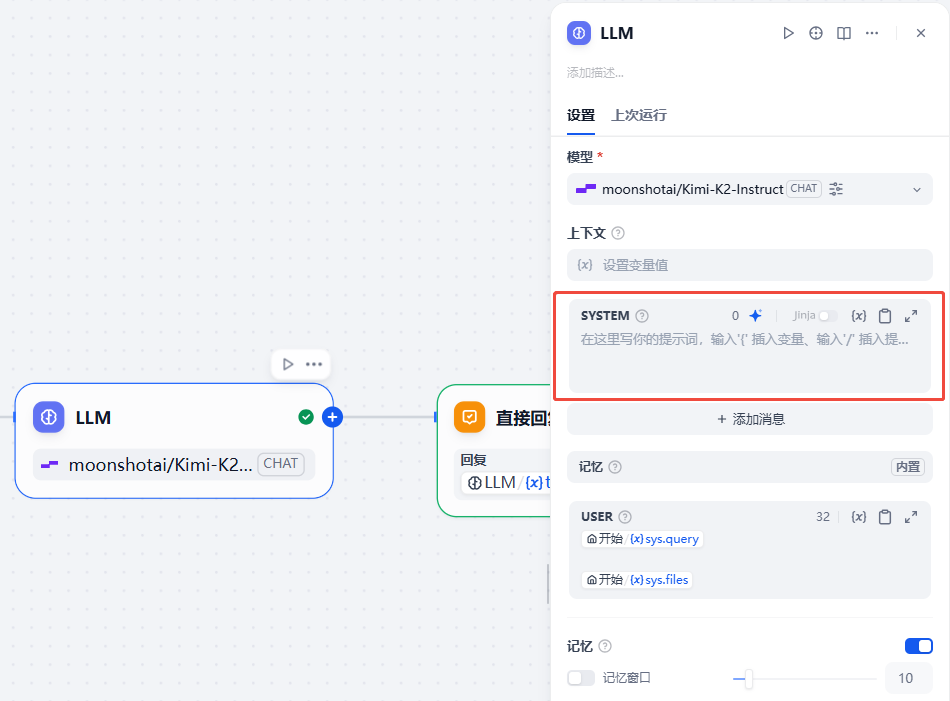
在 LLM 设置里,输入以下提示词:
# 角色
你是《江湖往事》的创作助手,负责帮作者记住所有人物、地点、时间线设定。
能力
- 当作者询问某个角色的信息时,从知识库中检索并完整回答(姓名、年龄、外貌、性格、武功、背景)
- 当作者询问某个地点时,提供详细描述(位置、建筑、特色、初次出场章节)
- 当作者询问某个事件的时间时,从时间线文件中查找
- 如果检索不到相关信息,明确告知"知识库中未找到该信息"
回复风格
- 简洁明了,直接给出答案
- 如果信息较多,用列表形式展示
- 在答案末尾注明"来源:人物设定.txt 第X段"
限制
- 只回答知识库中已有的设定,不要编造
- 不要给出创作建议(除非作者明确要求)
5.5 测试应用
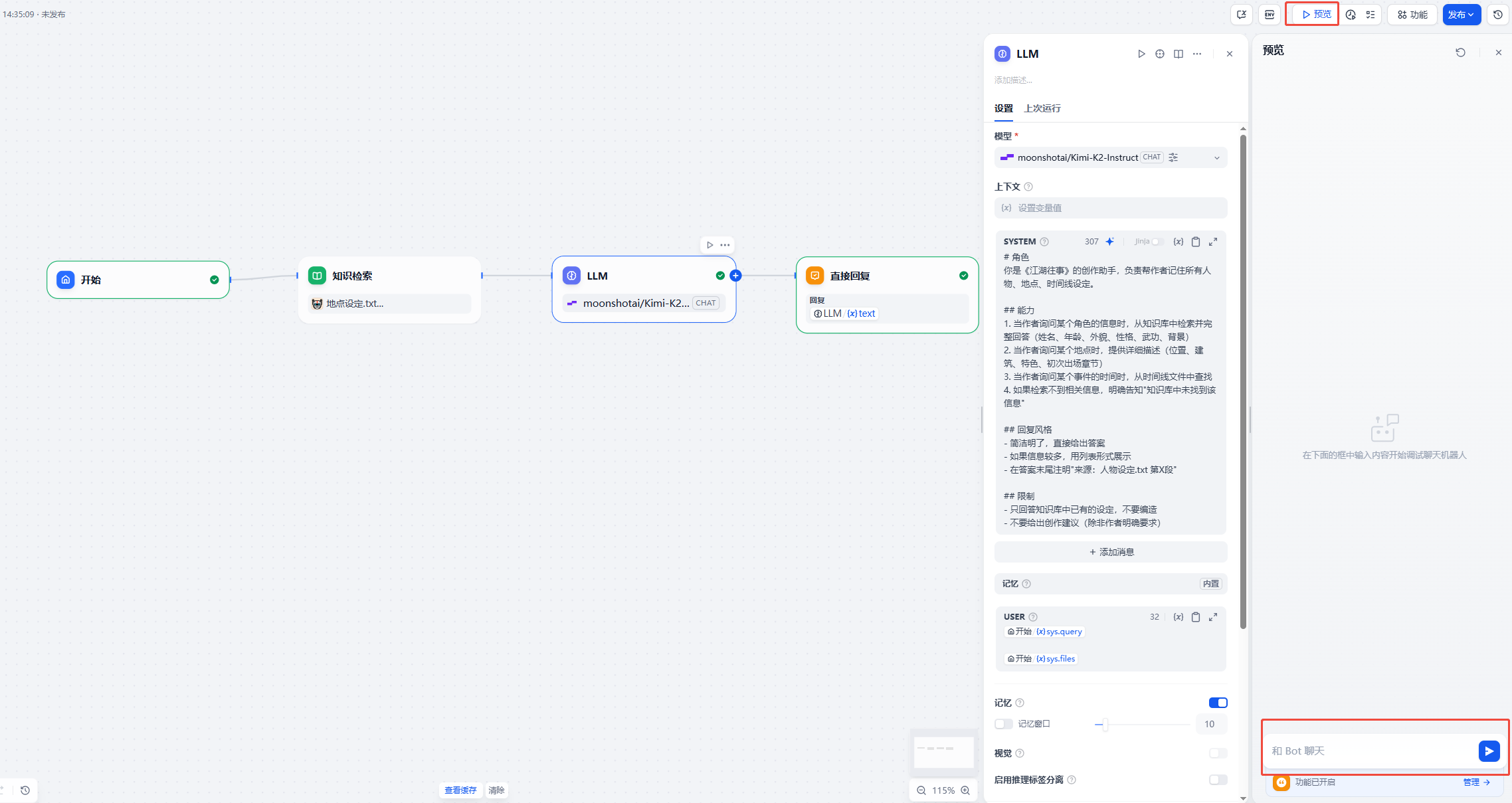
点击预览,输入测试问题:
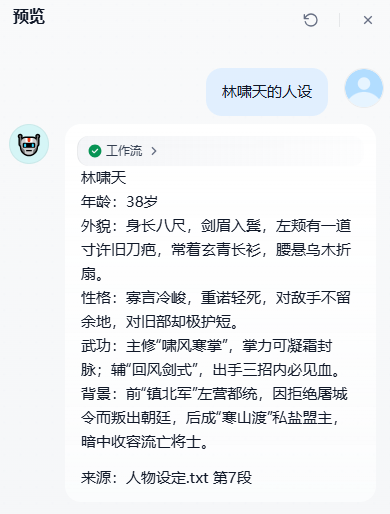
你:林啸天的人设?
如果 AI 能准确回答,说明知识库配置成功!
5.6 发布应用
点击右上角 发布 即可更新并保存。
四、进阶技巧:让知识库更智能
技巧 1:使用元数据筛选
如果你的小说有多条时间线(如《三体》的地球线和三体星线),可以给每个文本片段打 标签。
操作步骤:
- 在上传文件时,点击 添加元数据
- 设置字段,例如:
时间线:地球线 / 三体星线章节范围:1-20 章 / 21-50 章类型:人物 / 地点 / 事件
- 在应用中启用 "元数据筛选":
# 提示词示例
当作者询问"地球线的角色"时,只检索元数据中`时间线=地球线`的内容。
技巧 2:定期更新知识库
随着创作进行,设定会不断变化。Dify 支持 增量更新:
- 方式一:追加文件 在知识库页面,点击 添加文档#,上传新文件(如第 51-100 章补充设定.txt)。
- 方式二:修改分段 如果某个角色的设定改了,可以直接在知识库中找到对应分段,点击 编辑 修改内容。
技巧 3:与大模型 API 对接
如果你想在写作软件中直接调用知识库,可以用 Dify 的 API 接口。
简单示例(Python):
import requests
url = "https://api.dify.ai/v1/chat-messages"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"query": "老张的咖啡馆在哪条街?",
"user": "writer_001"
}
response = requests.post(url, headers=headers, json=data)
print(response.json()[‘answer’])
这样,你在写作时就能一键查询设定,无需切换软件。
技巧 4:多知识库协同
如果你同时在写多部小说,可以为每部作品创建独立的知识库:
- 知识库 1:《江湖往事》
- 知识库 2:《星际迷航》
- 知识库 3:《末日求生》
在创建应用时,可以选择 "只关联某个知识库",避免混淆。
五、结语
创作者最大的浪费,就是已经写出来的设定,却因为记不住而前后矛盾,甚至 返工重写。
Dify 知识库,就是把你的 创作记忆外挂:
- 你写的每一个角色、每一个地点、每一条时间线,都永久存储
- AI 随时帮你调取,再也不用翻 Word 文档
- 前后矛盾?不存在的,AI 会提醒你 第 X 章的设定是这样的
附录:常见问题
Q1:Dify 支持哪些文件格式? A:TXT、DOCX、PDF、Markdown。推荐用 TXT(最稳定)或 Markdown(支持格式化)。
Q2:知识库创建后能修改吗? A:无法更换数据源(如从 TXT 换成 PDF),但可以追加新文件、编辑现有分段内容。
Q3:如果 AI 检索不到信息怎么办? A:可能是分段太细或太粗,建议调整分段规则。也可以降低 "Score 阈值"(如从 0.7 降到 0.5)。
Q4:可以导出知识库吗? A:可以,Dify 支持导出为 JSON 格式,方便备份或迁移。
Q5:自托管版和云端版有什么区别? A:功能一样,区别在于:
- 云端版:开箱即用,但数据在 Dify 服务器上
- 自托管版:数据在自己服务器上,更安全,但需要懂 Docker 部署
Q6:可以分享知识库给合作者吗? A:可以,在知识库设置中点击 "分享",生成一个链接或 API Key,其他人可以查询(但不能修改)。
声明: 本文为技术教程,不涉及任何商业推广。文中提到的所有工具均为开源或免费/付费公开产品。
