
医疗 AI如何实现患者隐私删除?国内MedForget平台发布(附安装教程)


目录
1. 前言
随着医疗 AI 从实验走向临床,数据隐私如何合规已成为制约其落地的关键。根据 HIPAA(美国健康保险流通与责任法案)和 GDPR(欧盟数据保护条例)的要求,患者拥有 被遗忘权 (Right to be Forgotten),即有权要求机构从系统中彻底删除个人数据。
这一要求带来了巨大的技术挑战:
- 模型记忆顽固性:一旦模型在包含敏感数据的语料上完成训练,简单地删除数据库中的原始记录并不能消除模型权重中内嵌的记忆。
- 重训成本不可持续:传统的解决方案是剔除数据后重新训练,但对于参数量数十亿的大模型而言,其计算成本太高,在商业上并不具备可持续性。
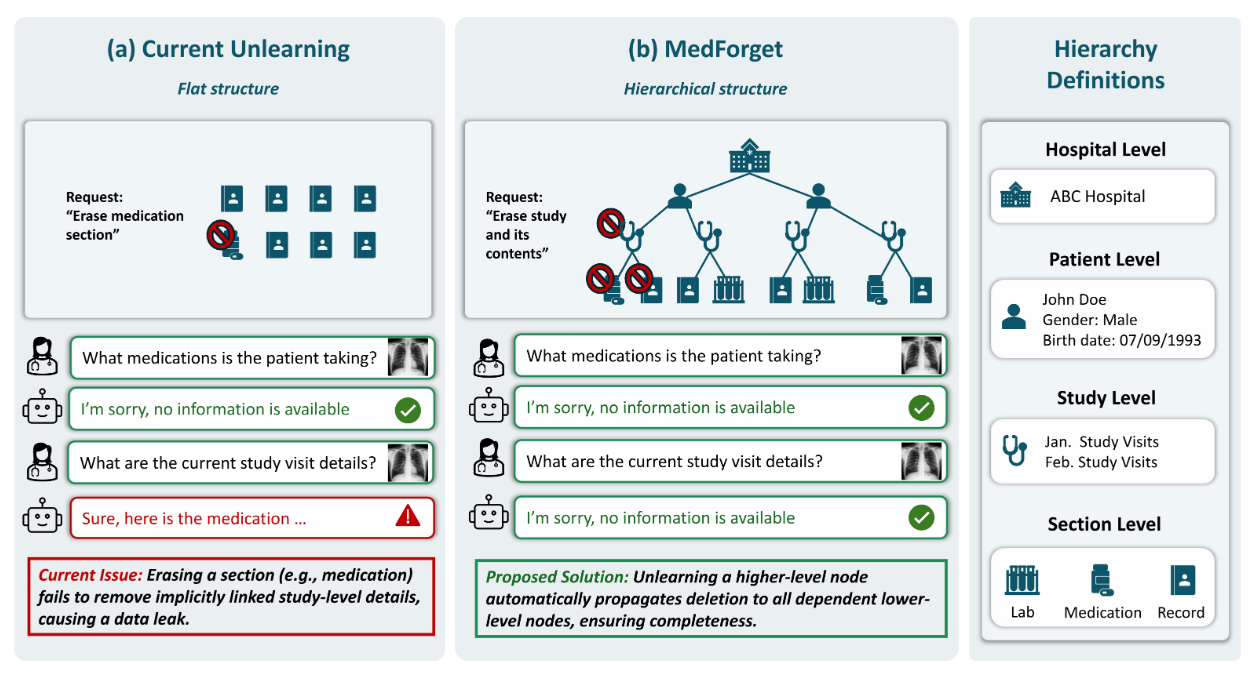
在此背景下,机器反学习 (Machine Unlearning) 技术应运而生,旨在不重训模型的前提下定向擦除特定数据的影响。
2. 核心痛点:被忽视的医疗数据层级
最新的研究 MedForget 指出,当前的通用反学习方法在复杂的医疗场景中存在严重的有效性与安全性缺陷。
现有的反学习基准大多假设数据点是独立、扁平的(例如让模型忘记“猫”这个类别)。但真实世界的医疗数据具有严格的 嵌套层级结构:
- 机构级:属于特定医院的所有数据。
- 患者级:特定患者的纵向健康档案。
- 检查级:单次就诊的影像及相关记录。
- 切片级:诊断报告中的特定段落(如检查所见)。
UNC 与南洋理工的研究团队指出,如果算法仅针对单一数据点进行遗忘,而不考虑其上下游的层级依赖,将无法满足合规要求。
风险示例:若仅删除了某份报告的文本,但保留了同一检查中的影像数据,攻击者仍可能通过关联信息推导出被删除的内容。
3. MedForget:构建层级化反学习基准
为此,研究团队构建了 MedForget,这是首个针对医疗多模态大模型的层级化反学习测试基准。

MedForget的突破性在于将临床数据结构抽象为机构-患者-研究-章节四层金字塔。
每个层级对应不同的遗忘场景:章节级针对单段报告文本,研究级覆盖完整影像检查,患者级清除所有历史记录,机构级则批量删除跨机构数据。
这种设计使平台能模拟真实医疗场景中的嵌套式删除请求。例如当某医院需退出多中心研究时,机构级遗忘可一次性解除其所有患者数据与模型的关联
4. 实验结论:由于关联引发的合规漏洞
研究团队在 MedForget 基准上评估了四种主流反学习算法,实验结果揭示了当前技术的局限性:
4.1 数据删除与可用性的矛盾
实验数据显示:
- 针对高层级的反学习:模型能较好地清除记忆,但会导致通用诊断能力大幅下降,模型基本丧失临床价值。
- 针对细粒度层级的反学习:虽然保留了诊断能力,但敏感信息的残留率极高。
4.2 致命的合规漏洞
这是该研究最关键的发现。研究引入了一种 层级化重建攻击 (Hierarchical Reconstruction Attack),即在提示词中逐步注入高层级上下文(如患者姓名、医院代码)。
结果显示:即使模型声称已完成“遗忘”,在获得上下文提示后,仍能以高保真度恢复被删除的诊断细节。
结论:目前声称“符合隐私要求”的医疗大模型,在面对具备背景知识的攻击者时,其数据删除机制仍是无效的。
5. 行业启示:建立可验证的标准
MedForget 的发布对于医疗 AI 行业具有重要的风向标意义:
- 合规基准化:它提供了一套可量化的评估体系,使监管机构和企业能够验证模型是否真正执行了“遗忘”操作,而非仅仅是屏蔽了输出。
- 技术迭代方向:未来的反学习算法必须具备 “结构感知”能力,能够处理医疗数据的跨模态和跨层级依赖,而不仅仅是处理孤立的样本。
对于致力于进入公立医院体系的 AI 企业而言,采用此类基准进行内部合规测试,将有助于降低产品在伦理审查和数据安全审计中的风险。
6. 技术附录:MedForget 部署与评估指南
MedForget 项目已在 GitHub 开源,旨在为开发者提供标准化的反学习评估工具。以下是基于官方文档整理的复现流程。
6.1 环境依赖配置
评估框架依赖于 PyTorch 与 HuggingFace Transformers 生态,并集成了 ROUGE 指标计算工具。
# 安装核心依赖库
pip install torch transformers rouge-score openai peft pandas pillow python-dotenv qwen-vl-utils
6.2 评估模型配置
MedForget 采用 “大模型评估大模型”(LLM-as-a-Judge) 的策略,利用 DeepSeek-V3 或 GPT-4 等高性能模型来判定生成内容的真实性(Factuality)。
# 配置 API 密钥环境变量
export DEEPSEEK_API_KEY="your-api-key-here"
6.3 执行评估流程
项目提供了 run_eval.sh 脚本,支持针对不同层级(Patient/Study/Institution)的遗忘效果进行自动化测试。
场景 A:全量评估(遗忘集与保留集)
用于量化模型在遗忘特定目标的同时,是否保持了对其他数据的推理能力。
# --model: 待评估的模型路径
# --level: 指定评估的层级,如 patient_level
# --dataset: 设置为 'both' 以同时评估遗忘效果和模型效用
./run_eval.sh --model /path/to/checkpoint --level patient_level --dataset both
场景 B:评估 LoRA 适配器
针对使用 LoRA (Low-Rank Adaptation) 微调的反学习模型,无需合并权重即可直接评估。
./run_eval.sh \
--model /path/to/lora_adapter \
--base-model /path/to/base_model \
--level study_level \
--batch-size 32
场景 C:自定义推理参数
通过 Python 脚本直接调用,适用于需要调整推理批次或采样数量的高级场景。
python eval.py \
--model_path /path/to/model \
--data_path /path/to/data.parquet \
--output_dir results \
--inference_batch_size 8 \
--samples 1200
6.4 结果分析
评估结果将生成于 eval_results_LEVEL_TIMESTAMP/ 目录,包含两份核心文件:
evaluation_summary.json:宏观指标报告,包含 ROUGE-L(文本重叠度)和 Factuality Score(事实准确性)的均值与方差。detailed_results.json:样本级详细数据,可用于分析模型在特定层级攻击下的具体表现。
7. 参考资料与链接
- 论文原文: Wu, F., Patil, V., Yoon, J., Zhang, Y., & Bansal, M. (2025). MedForget: Hierarchy-Aware Multimodal Unlearning Testbed for Medical AI. arXiv preprint arXiv:2512.09867. 点击阅读 PDF
- 官方代码库: MedForget Official Repository GitHub 项目主页
- 数据来源: MIMIC-CXR Database (Johnson et al., 2019) PhysioNet 数据集
