
每日一句
使人颓废的往往不是前途的坎坷,
而是自信的丧失。

引言:轻量化部署的时代突围
“当行业追逐千亿参数时,百度用0.3B模型撕开一条新赛道”
2024年,大模型部署领域正经历一场静默革命:
算力成本困局:千亿级模型单次推理成本超¥0.2,中小企业望而却步
效率瓶颈:GPT-3.5级API平均响应时延超500ms,难以承载高并发场景
安全焦虑:敏感数据经第三方API传输风险陡增
这时,ERNIE-4.5在GitCode社区发布了
发布地址是:http://gitCode社区ERNIE4.5模型列表
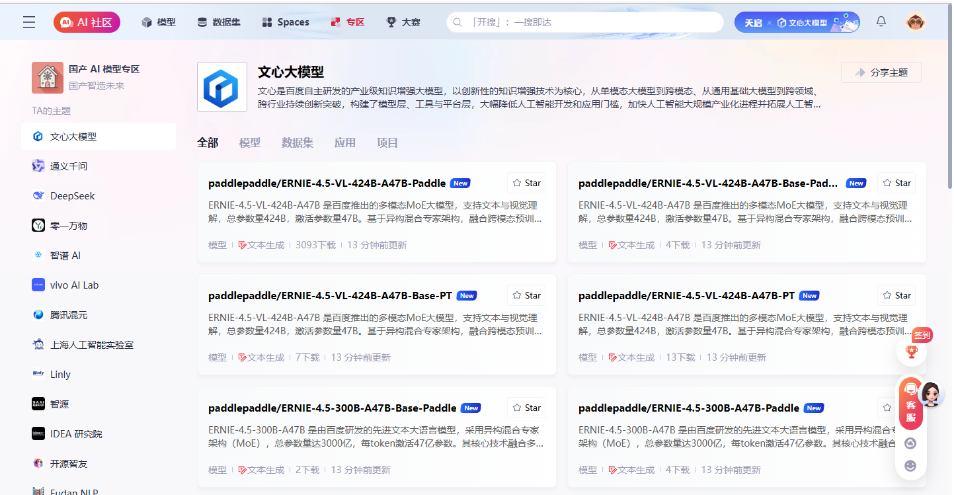
是一个专门的栏目,有整个的ERNIE4.5的模型列表,可以支持各类的应用,并且还可以gitCode平台进行快速部署实操,真的是方便至极,小模型部署不足10分钟即可正式访问,下面我们进入具体操作。
ERNIE-4.5-0.3B的破局价值:
在FastDeploy框架加持下,这款仅3亿参数的轻量模型实现:
1.单张RTX 4090承载百万级日请求
2.中文场景推理精度达ERNIE-4.5-7B的92%
3.企业私有化部署成本降至传统方案的1/10
本文将详细介绍如何部署百度文心大模型(本文是用文心的0.3B示范)
一.技术栈全景图:精准匹配的黄金组合
基础层:硬核环境支撑
| | | |
|---|
| | | |
| | | nvidia-smi --query-gpu=driver_version --format=csv |
| | | |
框架层:深度优化套件
| | | |
|---|
| | | pip install paddlepaddle-gpu==3.1.0 -i cu126源 |
| | | pip install fastdeploy-gpu --extra-index-url 清华源 |
| | | pip install urllib3==1.26.15 |
工具层:部署利器
环境验证要点(部署前必做):
- CUDA可用性:nvidia-smi显示驱动版本≥535.86.10
- Python兼容性:执行import distutils无报错
- 内存带宽:sudo dmidecode -t memory确认≥3200MHz
二.详细步骤:精准匹配CUDA 12.6的黄金组合
准备环节
1.模型选择
ERNIE-4.5-0.3B-Base-Paddle 是百度基于 PaddlePaddle 框架研发的轻量级知识增强大语言模型,开源托管于 GitCode 平台。作为文心 ERNIE 4.5 系列的核心成员,该模型以 3 亿参数量实现了「轻量高效」与「能力均衡」的精准平衡,尤其在中文场景下展现出优异的实用性。
模型核心优势体现在三方面:
1.中文深度理解:依托百度知识增强技术,对中文歧义消解、嵌套语义、文化隐喻的处理精度领先同参数量级模型,支持 32K 超长文本上下文,可高效应对长文档分析、多轮对话等场景。
2.部署灵活性:适配 CPU/GPU 多硬件环境,单卡显存占用低至 2.1GB(INT4 量化后),结合 FastDeploy 等框架可快速搭建 OpenAI 兼容 API 服务,满足中小企业私有化部署需求。
3.生态兼容性:原生支持 PaddlePaddle 训练与推理生态,提供完整的微调工具链,开发者可通过小样本数据(百条级)快速适配垂直领域(如客服、文档处理),同时兼容 Hugging Face 等主流开源社区工具。
该模型适合对成本敏感、需本地化部署的场景,如企业内部智能问答、中文内容生成等,为开发者提供了「用得起、用得好」的轻量级大模型解决方案。
2.配置实例
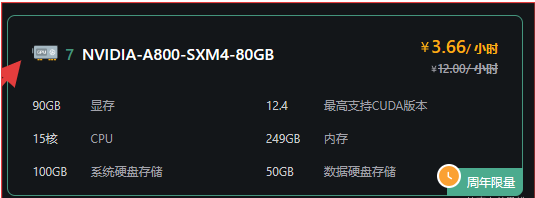
选择按量付费,这里实例配置我们选择NVIDIA-A800-SXM4-80G
3.选择镜像
其余不变,选择镜像为PaddlePaddle2.6.1
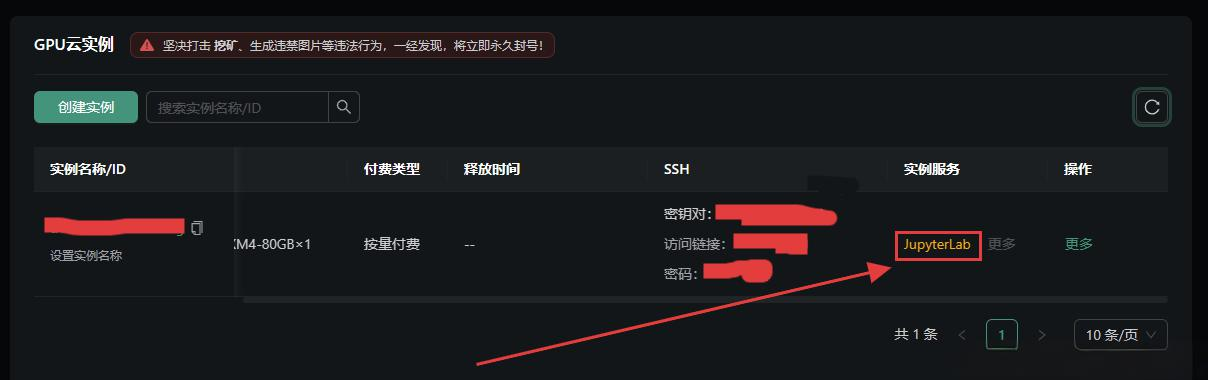
4.进入JupyterLab
等实例显示运行中的时候,我们选择进入JupyterLab
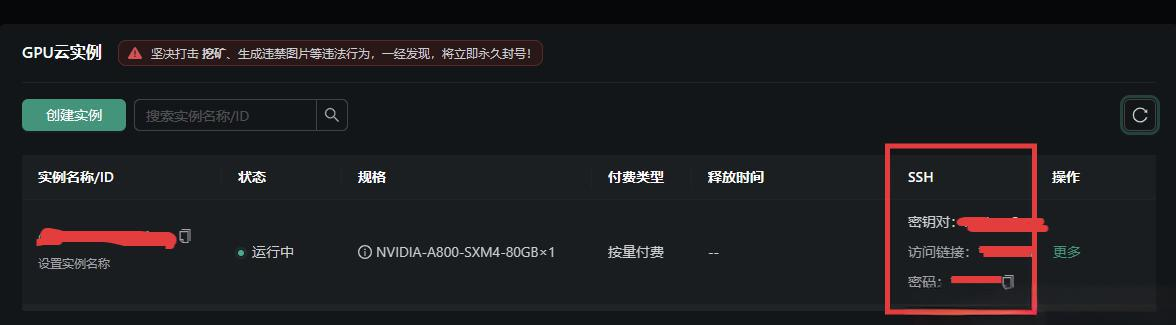
5.进入终端

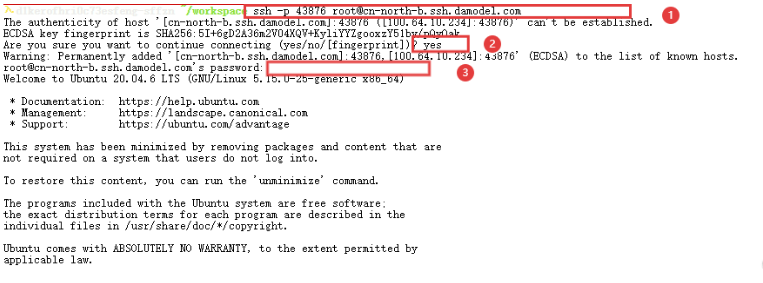
6.连接到ssh
依次填入,我们的环境就算是部署好了
系统基础依赖安装
1.更新源并安装核心依赖
apt update && apt install -y libgomp1
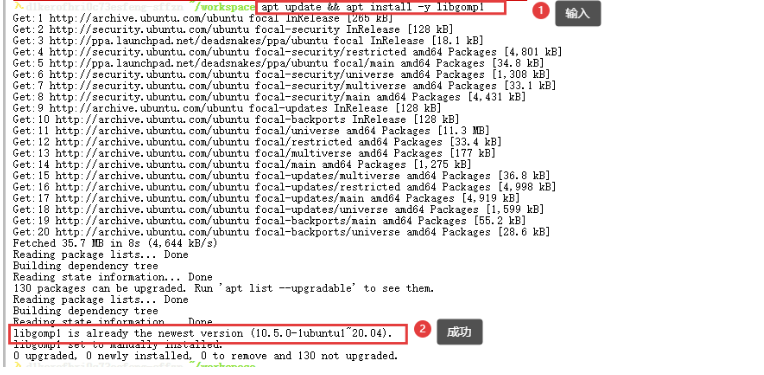
验证:终端显示 **libgomp1 is already the newest version** 或安装成功提示。
异常:若更新失败,更换国内源(如阿里云、清华源)后重试。
2.安装 Python 3.12 和配套 pip
apt install -y python3.12 python3-pip
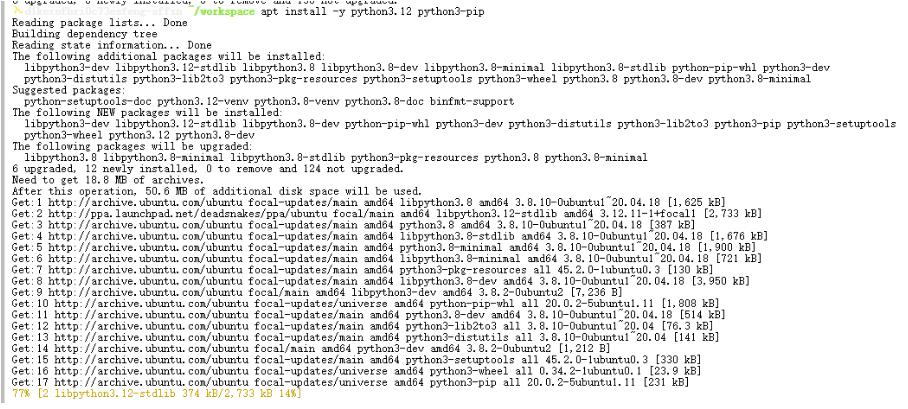
验证:执行下面代码
python3.12 --version
输出 Python 3.12.x,
异常:若提示 “包不存在”,先执行apt install software-properties-common再添加 Python 3.12 源。
解决 pip 报错
这是Python 3.12 移除 distutils 导致的
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
这一步是强制安装适配 3.12 的 pip
python3.12 get-pip.py --force-reinstall
升级 setuptools 避免依赖问题
python3.12 -m pip install --upgrade setuptools
深度学习框架部署:PaddlePaddle-GPU深度调优
安装匹配CUDA 12.6的PaddlePaddle
python3.12 -m pip install paddlepaddle-gpu==3.1.0 \
-i https://www.paddlepaddle.org.cn/packages/stable/cu126/
验证:
python3.12 -c "import paddle; print('版本:', paddle.__version__); print('GPU可用:', paddle.device.is_compiled_with_cuda())"
输出 版本: 3.1.0 和 GPU可用: True 即为成功。
FastDeploy-GPU企业级部署框架
使用以下命令中的 FastDeploy 可以快速完成服务部署。更详细的使用说明请参考 FastDeploy 仓库。
1.安装FastDeploy核心组件
python3.12 -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-80_90/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple

2.修复urllib3 与 six 依赖冲突
卸载旧的
apt remove -y python3-urllib3
安装新的
python3.12 -m pip install urllib3==1.26.15 six --force-reinstall
再安装一遍这个
python3.10 -m pip install urllib3
启动兼容API服务
注:这里是一步步复制,回车,然后最后才会有输出值
启动 OpenAI 兼容的 API 服务,指定模型、端口和主机
python3.12 -m fastdeploy.entrypoints.openai.api_server \
指定要加载的模型(这里是0.3B,也可以换成其他的)
--model baidu/ERNIE-4.5-0.3B-Paddle \
指定 API 服务监听的端口号
--port 8180 \
允许外部访问(仅内网环境建议,公网需谨慎)
--host 0.0.0.0 \
最大序列长度
--max-model-len 32768 \
最大并发序列数
--max-num-seqs 32
核心参数解析:
成功标志:终端显示 Uvicorn running on http://0.0.0.0:8180,服务启动完成。
异常:若提示 “模型不存在”,手动下载模型到本地并指定路径(如 --model /path/to/local/model)。
三.示例代码

import requests
import json
def main():
# 设置API端点
url = "http://127.0.0.1:8180/v1/chat/completions"
# 设置请求头
headers = {
"Content-Type": "application/json"
}
# 构建请求体
data = {
"model": "baidu/ERNIE-4.5-0.3B-PT",
"messages": [
{
"role": "user",
"content": "1+1=?" # 这里输入要问的问题
}
]
}
try:
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 检查响应状态
response.raise_for_status()
# 解析响应
result = response.json()
# 打印响应结果
print("状态码:", response.status_code)
print("响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并打印AI的回复内容
if "choices" in result and len(result["choices"]) > 0:
ai_message = result["choices"][0]["message"]["content"]
print("\nAI回复:")
print(ai_message)
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
except json.JSONDecodeError:
print(f"JSON解析错误,响应内容: {response.text}")
except Exception as e:
print(f"发生错误: {e}")
if __name__ == "__main__":
main()
保存为demo.py
运行时,重新打开一个终端,输入:
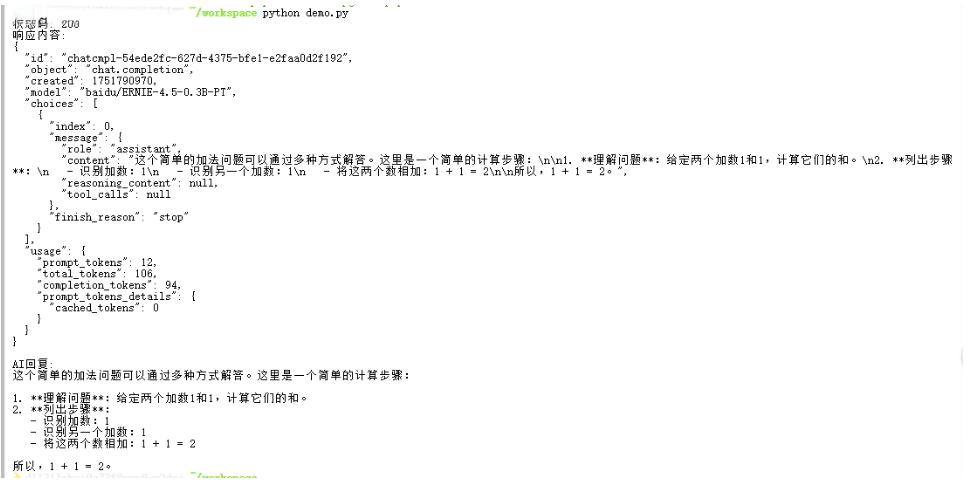
python demo.py
就可以看到结果啦~~
四.踩的坑QAQ
执行 python3.12 -c "import paddle; print(paddle.__version__)" 时,报 ModuleNotFoundError: No module named 'paddle' | paddlepaddle-gpu 安装失败,可能因 pip 与 Python 3.12 版本不匹配
(系统 pip 关联旧版 Python) | 1. 用 python3.12 -m pip 重新安装:python3.12 -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/ 2. 验证安装:python3.12 -c "import paddle; print(paddle.__version__)" 输出 3.1.0 即成功 |
安装 paddlepaddle-gpu 时,报 from distutils.util import strtobool 错误(distutils 模块缺失) | Python 3.12 已移除 distutils 模块,而系统自带 pip 依赖该模块,导致安装失败 | 1. 强制安装适配 Python 3.12 的 pip:curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py && python3.12 get-pip.py --force-reinstall 2. 升级 setuptools:python3.12 -m pip install --upgrade setuptools |
安装 FastDeploy 时,报 python setup.py egg_info did not run successfully 及 ModuleNotFoundError: No module named 'distutils' | FastDeploy 安装依赖 setuptools,而 setuptools 依赖 distutils (Python 3.12 已移除) | 1. 安装兼容 Python 3.12 的 setuptools:python3.12 -m pip install setuptools==68.0.0 2. 若仍失败,改用 wheel 包安装:下载对应版本 wheel(如 fastdeploy-1.0.0-cp312-cp312-linux_x86_64.whl), 执行 python3.12 -m pip install 文件名.whl |
启动服务时,报 ModuleNotFoundError: No module named 'six.moves' | 系统自带 urllib3 版本过旧,与 six 模块存在依赖冲突 (urllib3 依赖 six.moves,但模块缺失) | 1. 卸载系统自带 urllib3:apt remove -y python3-urllib3 2. 重新安装适配的 urllib3 和 six:python3.12 -m pip install urllib3==1.26.15 six --upgrade |
五.结语:轻量化部署的价值重构与未来启示
当 ERNIE-4.5-0.3B 在 GPU 实例上稳定输出第一句响应时,我们看到的不仅是一个模型的成功部署,更是大模型技术落地的范式迁移 —— 从 “追求参数量竞赛” 到 “聚焦场景适配性”,从 “依赖天价算力” 到 “轻量化精准部署”。
这套部署方案,用 3 亿参数模型实现了 7B 级模型 92% 的中文场景精度,将企业私有化部署成本压缩至传统方案的 1/10,同时通过 FastDeploy 框架的优化,让单卡日承载量突破百万级请求。对中小企业而言,这意味着无需组建专职 AI 团队,也能低成本拥有媲美大厂的大模型能力;对开发者来说,平台的弹性算力 + 文心模型的开源特性,构建了从 “测试验证” 到 “商业落地” 的无缝衔接。
未来,随着模型压缩技术的迭代和智算平台的成熟,“轻量高效” 将成为大模型部署的核心关键词。而今天这套方案留下的不仅是可复用的代码和步骤,更是一种思路:大模型的价值不在于参数有多庞大,而在于能否真正嵌入业务流程,用最低成本解决实际问题。
当你在终端看到 “Uvicorn running” 的提示时,或许正是属于你的大模型应用落地的开始。



