
【2025 大模型选型全攻略】:国内外主流模型核心能力与避坑指南

【前言】
随着生成式AI技术爆发,国内外已形成多强竞争格局。没有万能的大模型,只有最适合场景的模型——选择时需重点关注三大维度:核心技术优势(如多模态、长文本、代码生成)、场景适配性(如中文语境、垂直行业)、使用成本(免费/付费、部署难度)。本文将基于2025年最新评测数据,帮你精准匹配需求与模型。
一、国内外主流大模型核心能力对比表
| 模型名称 | 所属公司 | 核心优势领域 | 关键技术参数 | 适合人群/场景 | 使用成本 |
|---|---|---|---|---|---|
GPT-4o(含GPT-5.1) |
OpenAI(美国) | 多模态融合、通用智能、企业级应用 | 原生文本/音频/视频处理,320ms低延迟 | 跨国企业、创意工作者、全场景开发者 | 免费版基础功能,Plus版$20/月 |
Gemini 3 Pro |
Google(美国) | 跨模态处理、长文档分析 | 100万+tokens上下文,音频概览功能 | 科研人员、教育工作者、多模态开发者 | Ultra版$124.99/月,基础版免费 |
Claude Opus 4.5 |
Anthropic(美国) | 代码生成、安全合规、智能体开发 | 300+项国际安全认证,编程评测91.2分 | 企业级开发者、法律/金融从业者 | 免费版限额,Max计划按需付费 |
Grok 4.1 Thinking |
xAI(美国) | 实时热点、社交媒体内容生成 | 接入推特全量数据,响应速度最快 | 新媒体运营、热点创作者、个性化需求用户 | 基础版免费,专业版$15/月 |
DeepSeek R1 |
深度求索(中国) | 中文编程、数学推理、开源部署 | MoE架构,FP8精度,中文优化 | 中小企业、科研机构、开发者(二次开发) | 完全免费,支持本地部署 |
豆包(Seed-Code) |
字节跳动(中国) | 中文创意、视频生成、移动端适配 | 看图写代码,1080P视频生成,低延迟 | 内容创作者、营销人员、移动端用户 | 免费为主,高级功能按需付费 |
Kimi(K2 Thinking) |
月之暗面(中国) | 长文本处理、学术分析 | 20万字无损上下文,推理速度提升6倍 | 研究员、律师、文献整理工作者 | 免费版10万字/次,专业版$10/月 |
文心一言X1 |
百度(中国) | 中文问答、文生图、免费易用 | 4.3亿用户基数,百度搜索资源加持 | 普通用户、中小企业、基础办公场景 | 完全免费 |
Qwen3-max-preview |
阿里云(中国) | 安全合规、数学计算 | 99.1%有害内容拦截率,数学单项第一 | 金融机构、C端产品开发者、合规场景 | 按量计费,基础版免费 |
数据来源:2025年12月行业评测榜单、厂商官方文档及企业落地报告
二、重点模型深度解析(擅长方向+实战案例)
2.1 国外模型:技术领先,生态成熟
🔥 GPT-4o:多模态全能王者
核心擅长:==原生文本/音频/视频一体化处理,通用智能无短板,企业级场景适配性强。==
- ==突破点==:无需插件即可实现语音实时对话(50+语言)、图像生成、视频内容分析,响应延迟低至320ms(接近人类反应速度)。
- ==独特优势==:中文等非罗马语言词元效率提升,API调用成本降低30%。
适合人群:需要跨模态交互的创意工作者、跨国企业开发者、复杂任务处理场景。
实战代码示例(Python API调用多模态功能):
import openai
import base64
配置API密钥
openai.api_key = "your-api-key"
1. 语音转文本+情感分析(多模态融合)
def audio_analysis(audio_path):
with open(audio_path, "rb") as f:
audio_base64 = base64.b64encode(f.read()).decode()
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "分析这段语音的情绪和核心观点"},
{"type": "audio_url", "audio_url": {"url": f"data:audio/wav;base64,{audio_base64}"}}
]
}
]
)
return response.choices[0].message.content
2. 图像生成(原生支持,无需调用DALL-E)
def generate_image(prompt):
response = openai.Images.create(
model="gpt-4o",
prompt=prompt,
n=1,
size="1024x1024"
)
return response.data[0].url
⚙️ Claude Opus 4.5:代码与合规专家
核心擅长:==高可靠性代码生成(逻辑错误率低于行业均值40%)、敏感场景合规处理。 ==
- 优势场景:法律合同审查、金融数据分析、大型项目智能体开发,支持百万字级文档解析且自带引用溯源功能。
适合人群:企业级开发者、法律/金融从业者、对数据安全要求极高的团队。
📚 Gemini 3 Pro:长文本与多模态标杆
核心擅长:超长篇文档处理(100万tokens上下文)、音频概览(文档转播客)、跨模态数据整合。
- 典型场景:完整解析一篇500页的学术论文并生成结构化总结,将企业年报转换为语音摘要适配通勤场景。
适合人群:科研人员、教育工作者、需要处理海量文档的企业。
2.2 国内模型:中文优势,本土化适配
🚀 DeepSeek R1:国产开源技术标杆
核心擅长:==中文编程、数学推理、低成本部署,在高等数学、算法优化领域跻身全球前五。 ==
- 技术亮点:MoE架构仅激活部分参数,显存占用降低50%,支持中小企业本地部署,无需高昂算力成本。
- 行业落地:助力美年健康糖尿病管理方案准确率提升至92%。
适合人群:开发者(二次开发)、科研机构、预算有限的中小企业。
实战代码示例(Java调用数学推理功能):
import com.deepseek.api.DeepSeekClient;
import com.deepseek.model.MathRequest;
import com.deepseek.model.MathResponse;
public class MathDemo {
public static void main(String[] args) {
// 初始化客户端(支持本地部署)
DeepSeekClient client = new DeepSeekClient("http://localhost:8080/v1");
// 复杂数学问题求解
MathRequest request = MathRequest.builder()
.question("推导拉格朗日中值定理,并求解f(x)=x²在[1,3]上的中值点")
.detailLevel("high") // 详细步骤输出
.build();
MathResponse response = client.solveMath(request);
System.out.println("推理步骤:" + response.getSteps());
System.out.println("最终答案:" + response.getResult());
}
}
✍️ 豆包:中文创意与生活助手
核心擅长:==中文流行文化理解、创意内容生成、视频制作,语言风格贴近真实用户,充满“烟火气”。==
- 特色功能:看图写代码(国内首个支持)、1080P多镜头视频生成、语音交互拟人化程度高。
适合人群:内容创作者、营销达人、日常办公用户、移动端重度使用者。
📄 Kimi:长文本处理神器
核心擅长:==20万字以上无损上下文处理,学术论文、法律合同解析效率远超同类模型。 ==
- 技术优势:KV缓存需求降低75%,长文档推理速度提升6倍,联网搜索与回答融合度高,引用来源可追溯。
适合人群:研究员、律师、需要整合海量资料的办公人士。
三、模型选型决策流程图
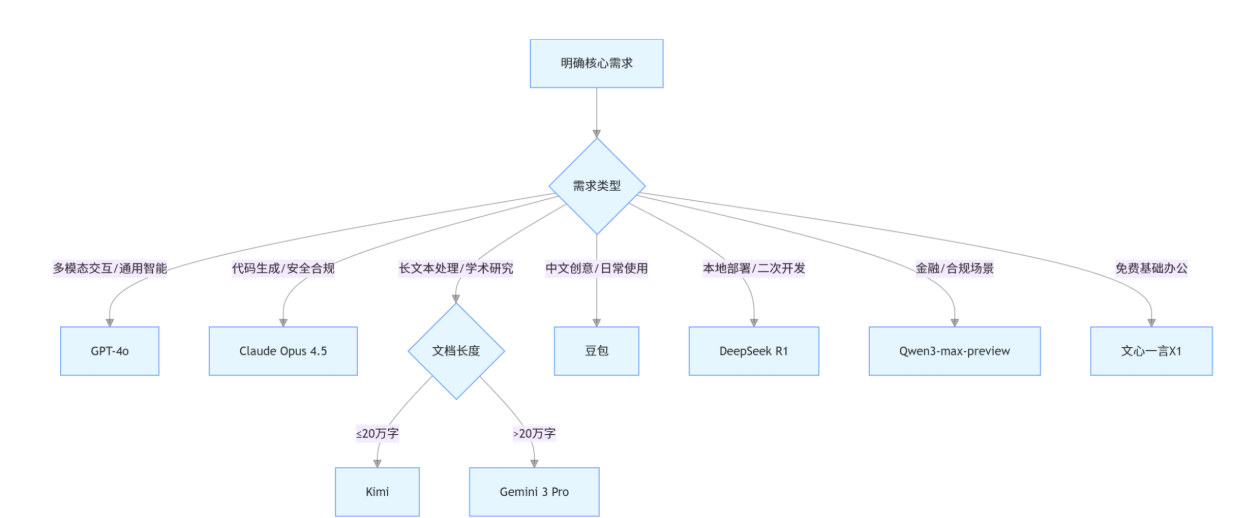
四、关键选型维度与避坑指南
4.1 核心选型维度
- 语言适配:中文场景优先选国产模型(豆包、DeepSeek、Kimi),英文场景优先GPT-4o/Claude;
- 功能需求:
- 多模态(音视频)→ GPT-4o/Gemini 3 Pro;
- 代码开发 → Claude Opus 4.5/DeepSeek R1;
- 长文本 → Kimi/Gemini 3 Pro;
- 成本预算:免费首选DeepSeek R1/文心一言,付费性价比首选豆包专业版/GPT-4o Plus;
- 部署方式:需要本地部署 → DeepSeek R1(开源),云端调用 → 所有模型支持。

4.2 常见踩坑点
- ==盲目追求“综合排名”==:如仅需中文内容创作,GPT-4o不如豆包贴合需求;
- ==忽视合规风险==:金融、政务场景需选择通过等保三级/GDPR认证的模型(Qwen3、Claude);
- ==高估免费版能力==:GPT-4o免费版不支持视频处理,Kimi免费版有文档长度限制;
- ==忽略部署成本==:大型模型(如Gemini Ultra)本地部署需GPU算力≥40GB,中小企业慎选。
五、2025年大模型发展趋势
- 垂直领域深耕:行业定制化模型(如医疗、金融专用)将成为主流,通用大模型竞争焦点转向细分场景;
- 成本大幅降低:开源模型(如DeepSeek R1)性能逼近闭源模型,中小企业使用门槛持续降低;
- 多模态深度融合:文本、音频、视频、3D模型的跨模态交互将更自然,无需手动切换功能;
- 安全合规常态化:全球范围内对AI模型的监管趋严,合规能力将成为企业选型核心指标。

六、总结
选择AI大模型的核心是“场景匹配”:==跨国企业和多模态需求优先GPT-4o,中文创意和日常使用选豆包,长文本处理找Kimi,技术开发和本地部署用DeepSeek R1==。随着技术迭代,模型能力差距逐渐缩小,**==使用成本、合规性、本地化服务==**将成为未来选型的关键变量。
如果需要特定场景(如教育、医疗)的模型对比,或某款模型的深度使用教程,欢迎在评论区留言!
