1. 作品展示
1.1. 首页
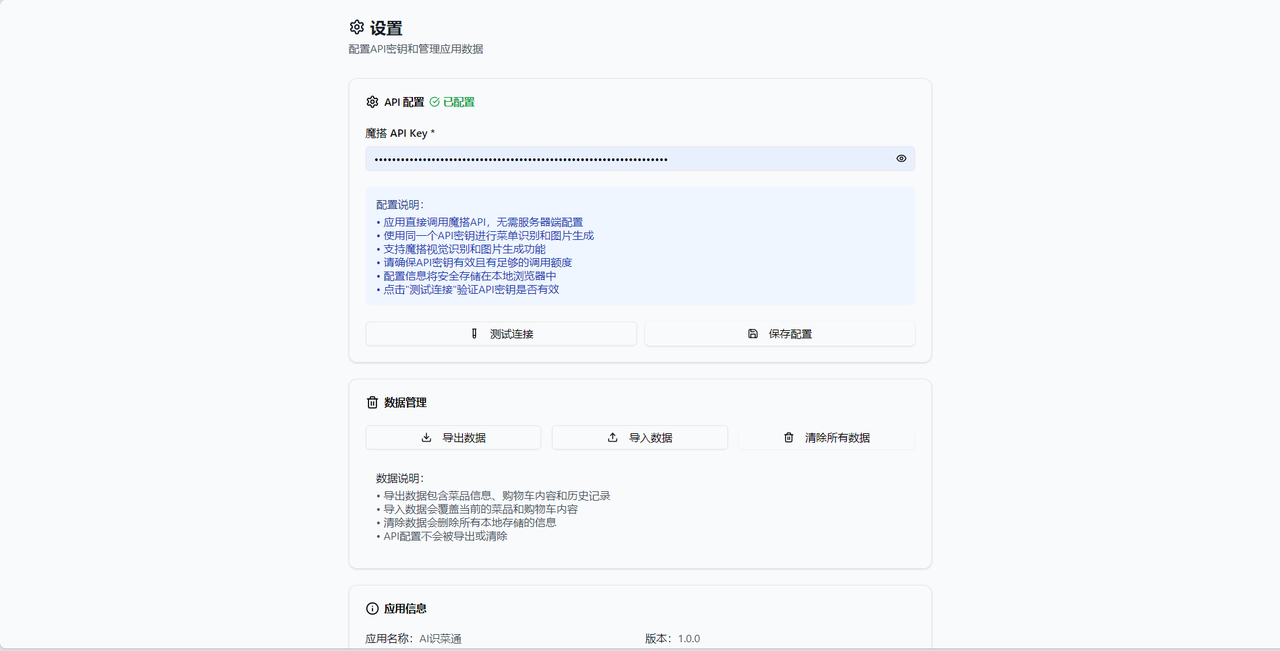
1.2. 设置API密钥
首先设置魔搭社区API密钥,用户自己的API密钥存放在本地的storage中,并不会上传到云端,确保用户的密钥安全。
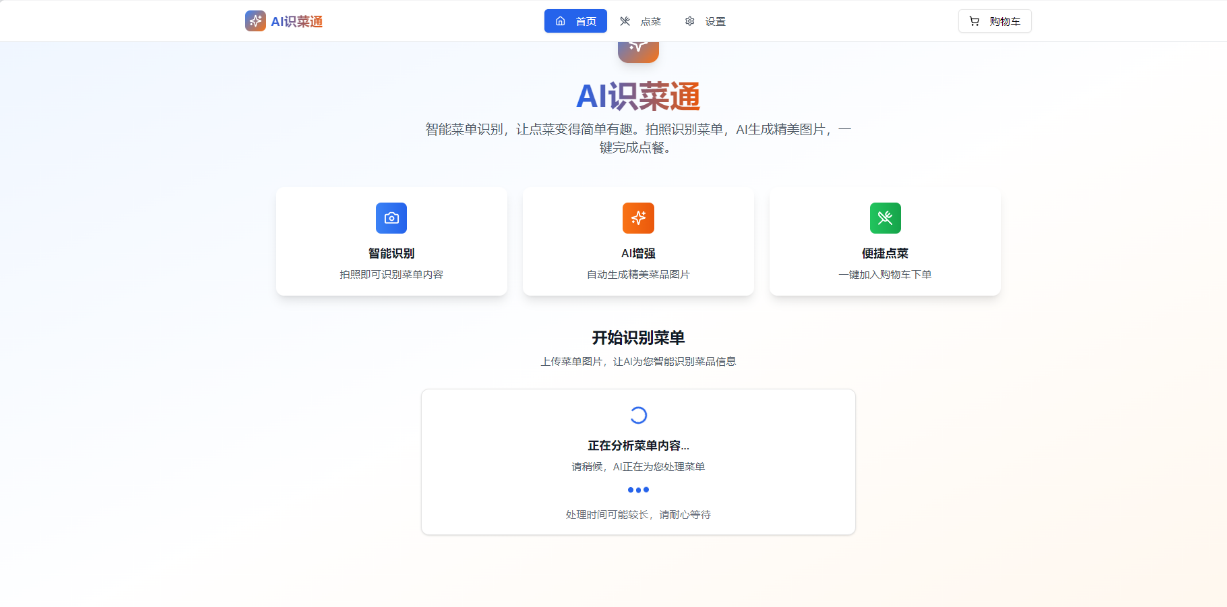
1.3. 识别菜单
前置条件准备好之后,我从网上下载了一份英文菜单进行测试:

上传图片之后项目就会调用豆包大模型进行分析,整体的时间根据菜单内容的多少会有些出入,静静等待几分钟就好:
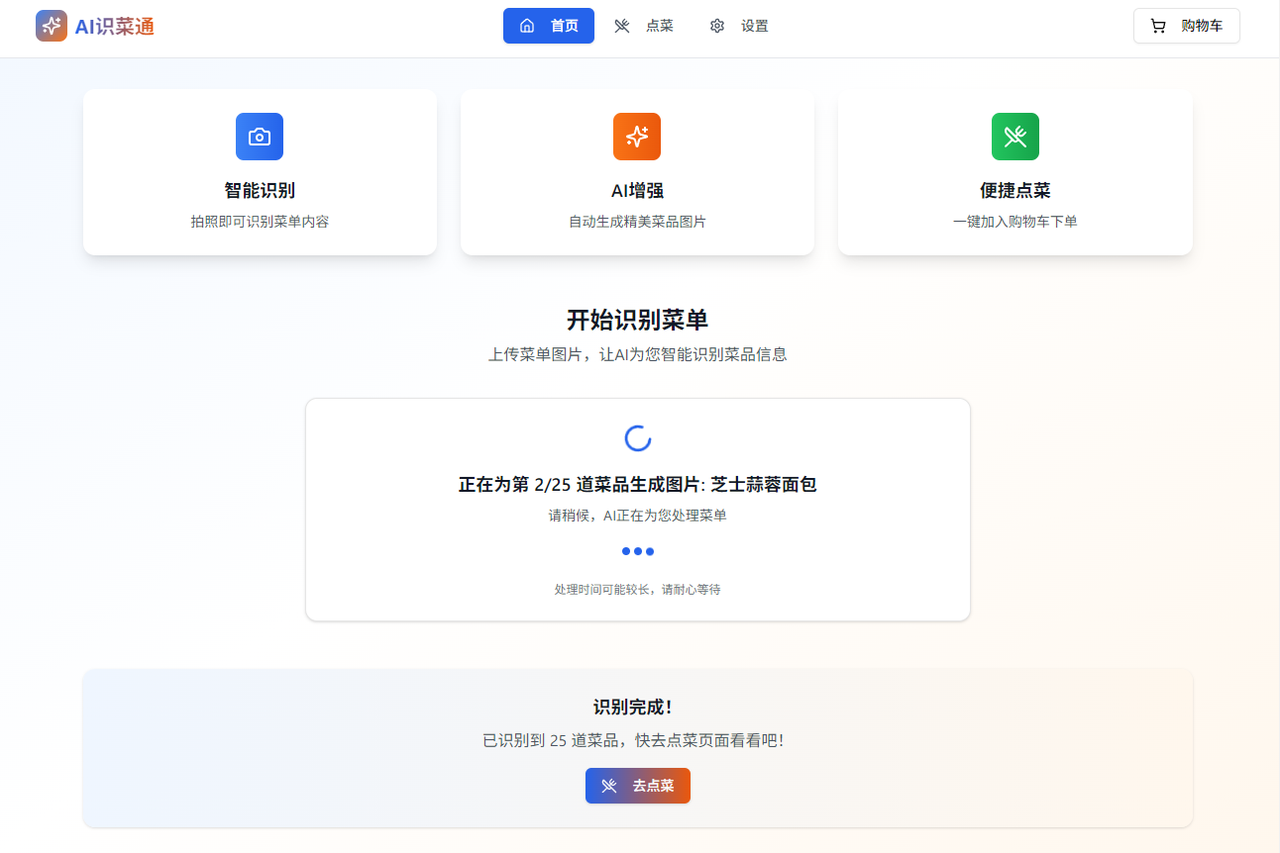
菜单识别完毕之后,首页会提示,点击去点菜即可看到生成的中文菜单
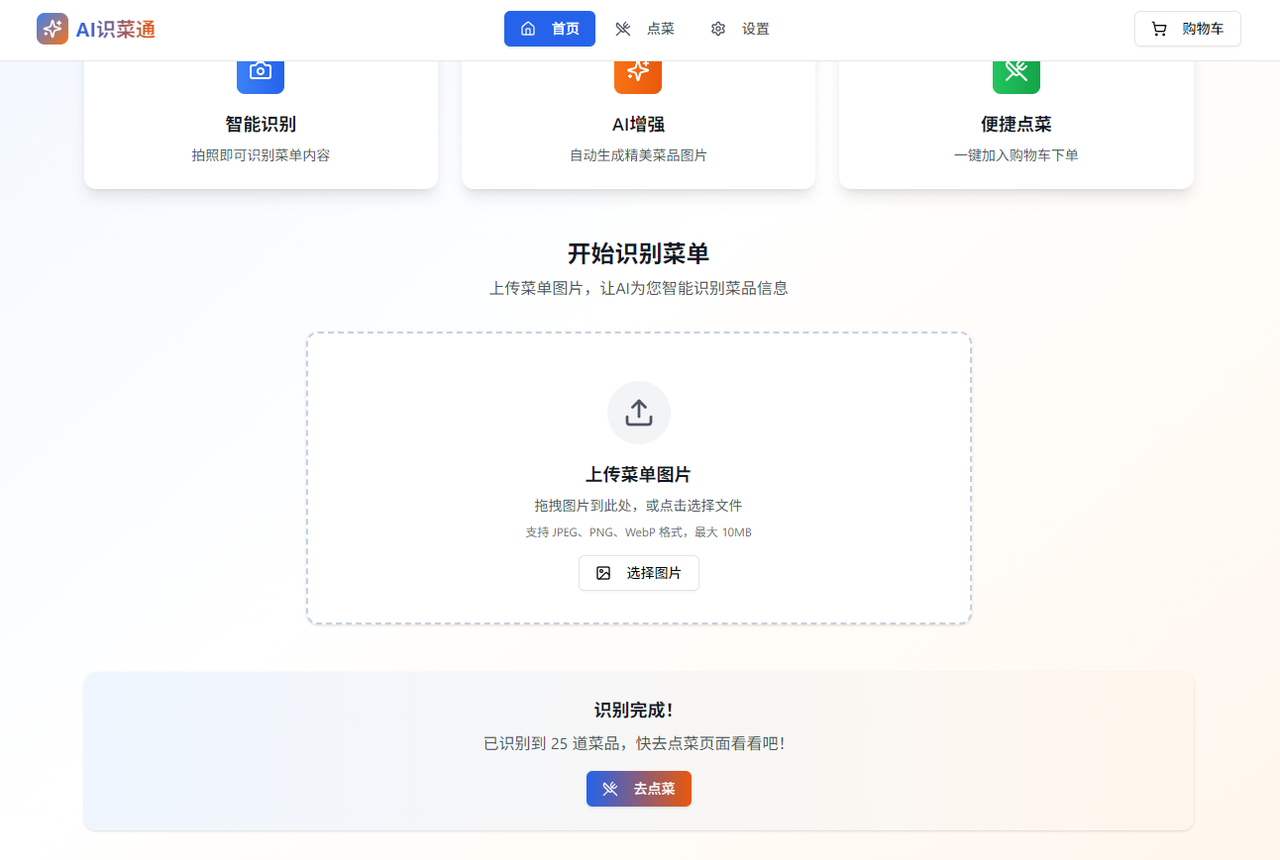
以下是生成后的结果,可以看到,生成的图片是很符合菜单中的样子的,这样让本来晦涩难懂的菜单有了活力,这也许就是科技带给我们的意义吧,服务生活,然后这样就可以顺利点菜了:
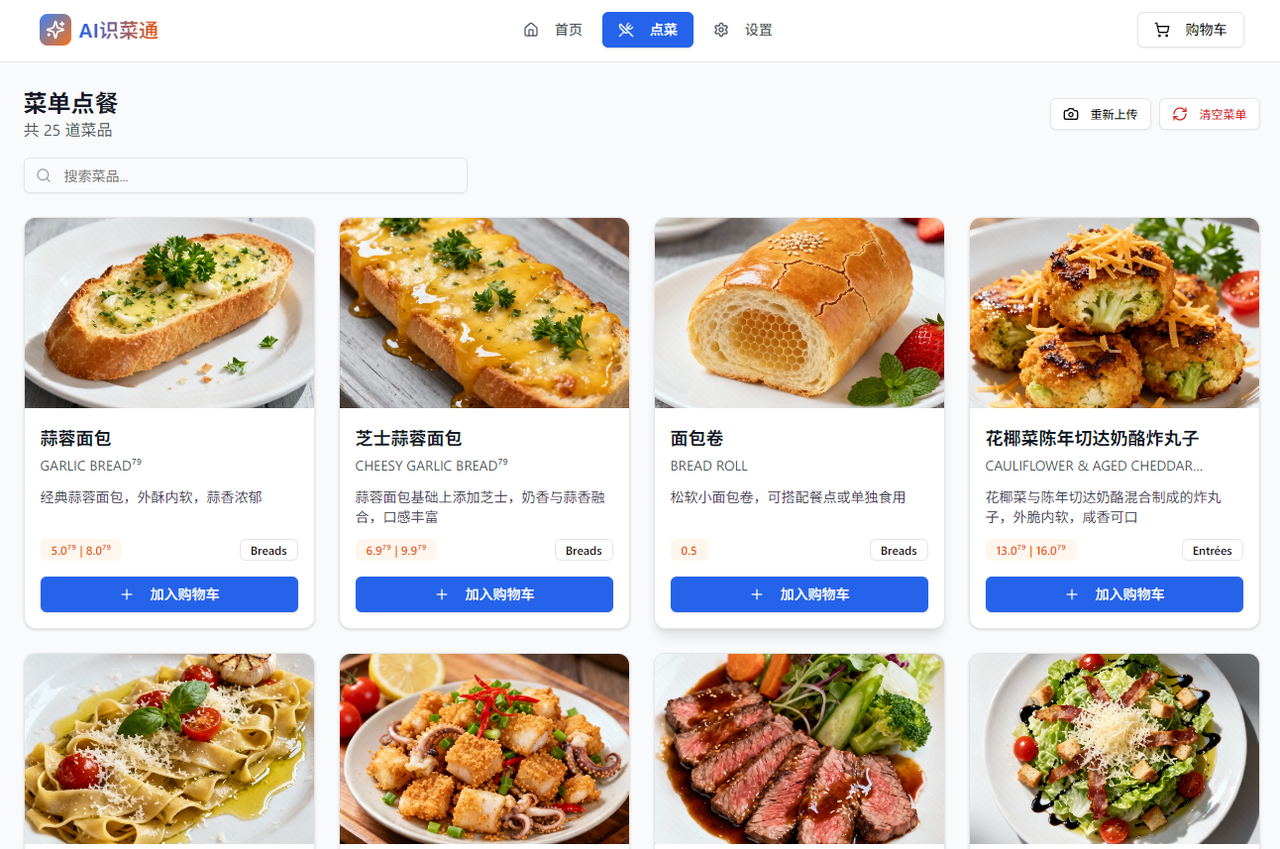
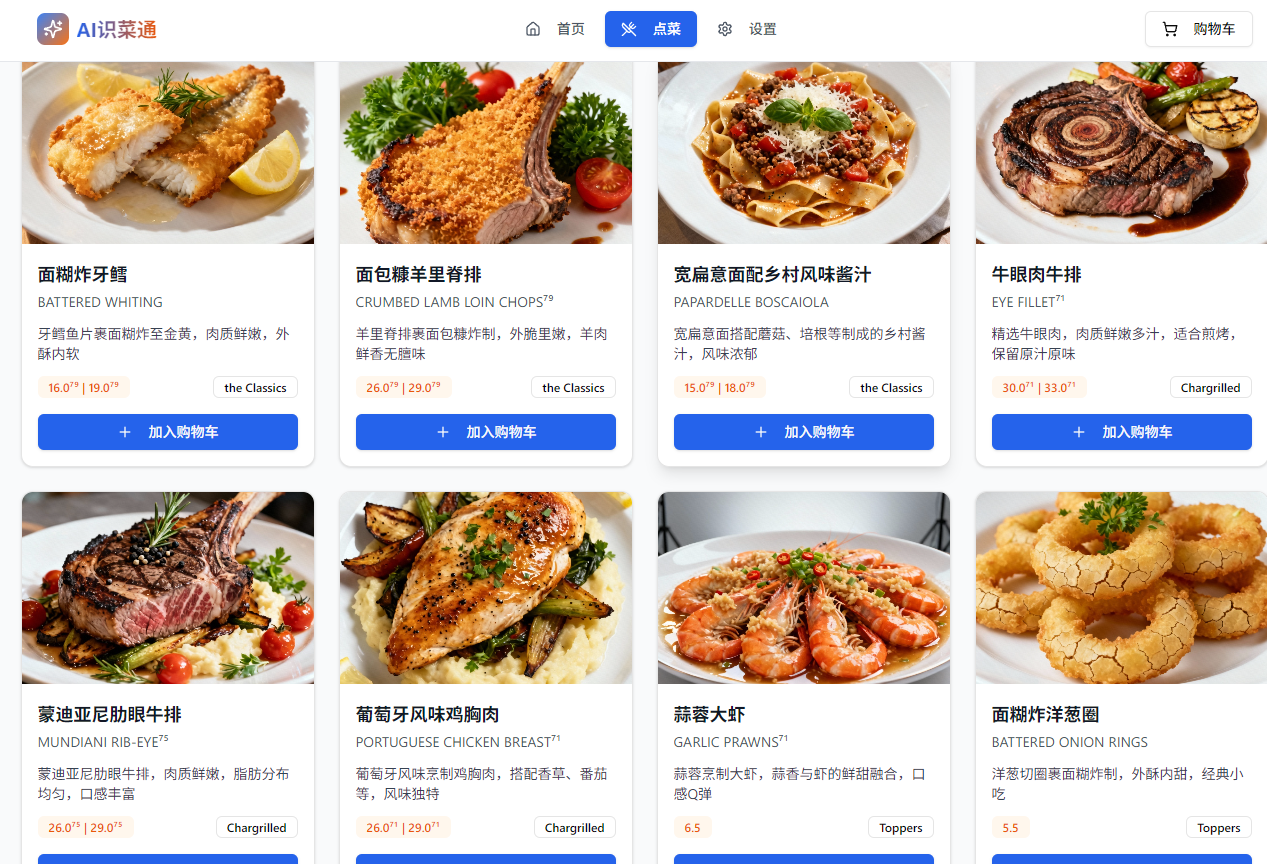
1.4. 点餐进入购物车
选择自己需要点的视频加入购物车
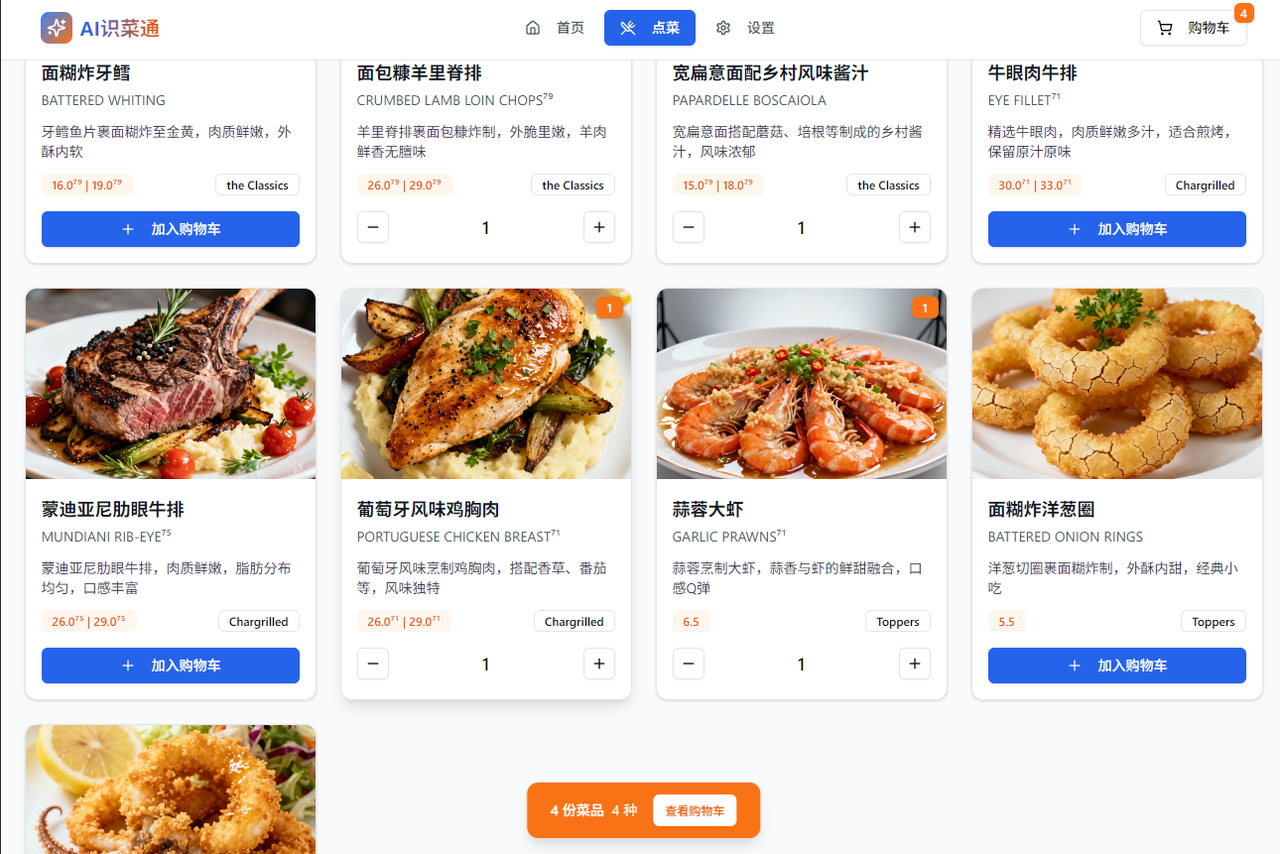
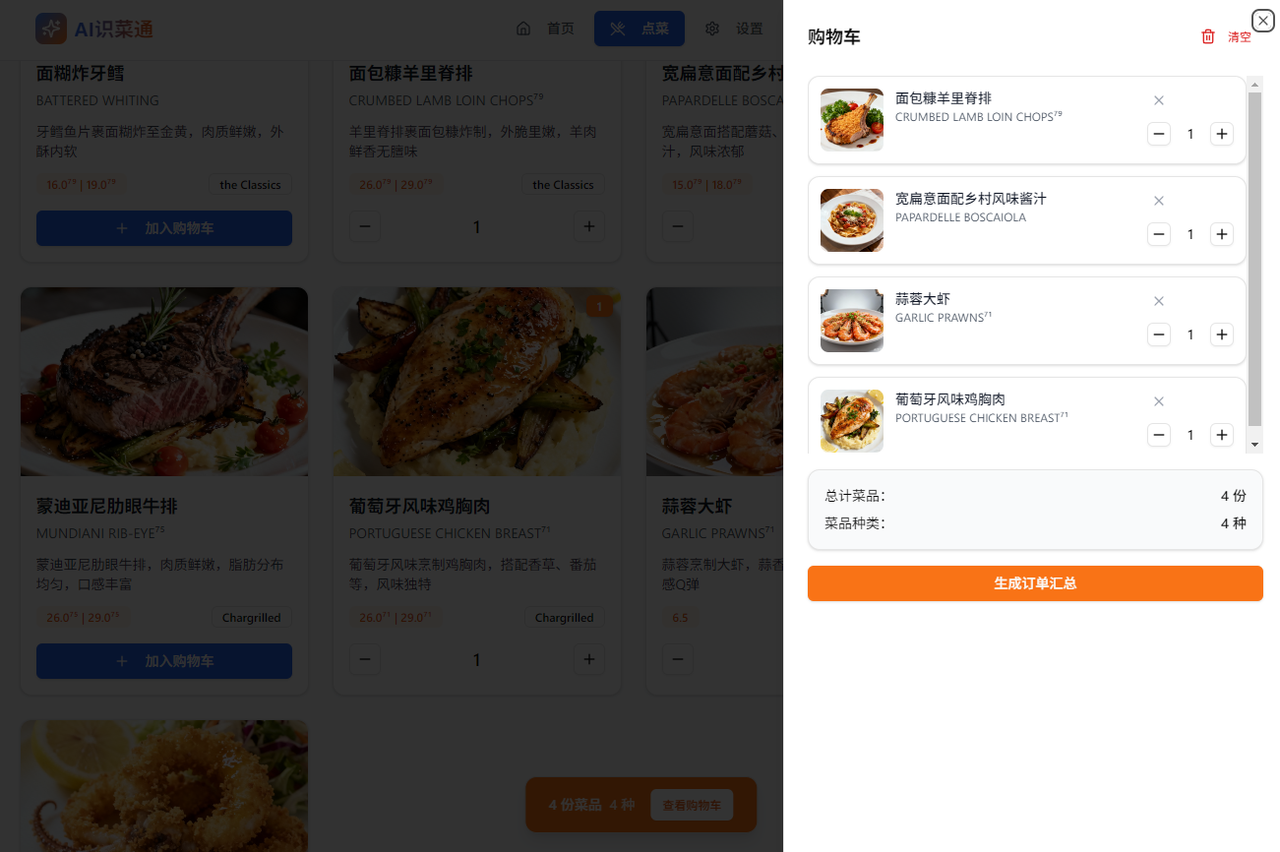
点击生成订单汇总,会生成一份刚刚的点菜TXT格式的清单:

2. 摘要
本文介绍了基于 TRAE 智能开发平台 与 魔搭社区(ModelScope)多模态大模型 所打造的“AI识菜通”应用。该应用允许用户上传任意语言的菜单图片,通过调用 Qwen3-VL-235B-A22B-Instruct 多模态大模型进行菜品识别与精准中文翻译,并利用 Qwen-Image 文生图模型为每道菜生成高清美食图片。用户可在点菜页面浏览菜品卡片、加入购物车,并最终生成格式化的点菜清单(如“宫保鸡丁(Kung Pao Chicken)”),便于向服务员点单。整个系统采用 React + TypeScript 构建,UI 使用 shadcn/ui 与 Radix UI,API 密钥安全存储于本地 localStorage 中,保障用户隐私。开发过程依托 TRAE 的 SOLO 模式,通过自然语言提示词自动完成需求分析、架构设计、编码、调试与部署,极大提升了开发效率。
3. TRAE
TRAE是一款深度融合AI能力的智能开发工具,它如同一位全能的"AI开发工程师",能够理解开发需求、调用专业工具并独立完成从编码、调试到测试、重构、部署等全链路开发任务。TRAE不仅提供智能代码补全、多行修改等基础功能,更构建了开放的智能体生态,让开发者可以根据不同场景灵活配置和组合AI助手,真正实现人机协同的高效开发体验。
SOLO模式是TRAE 2.0版本的核心创新,基于"Context Engineering"(上下文工程)理念设计。在此模式下,AI完全主导开发流程,用户只需通过自然语言描述、语音交互或上传本地文件等方式输入需求,系统便会自动进行需求感知、任务拆解、代码生成、测试验证,直至产出可预览和部署的应用成果。SOLO模式包含SOLO Coder和SOLO Builder两大智能体,分别面向复杂项目开发和快速Web应用构建,让开发过程从传统的手动操作转变为智能化的自主推进。
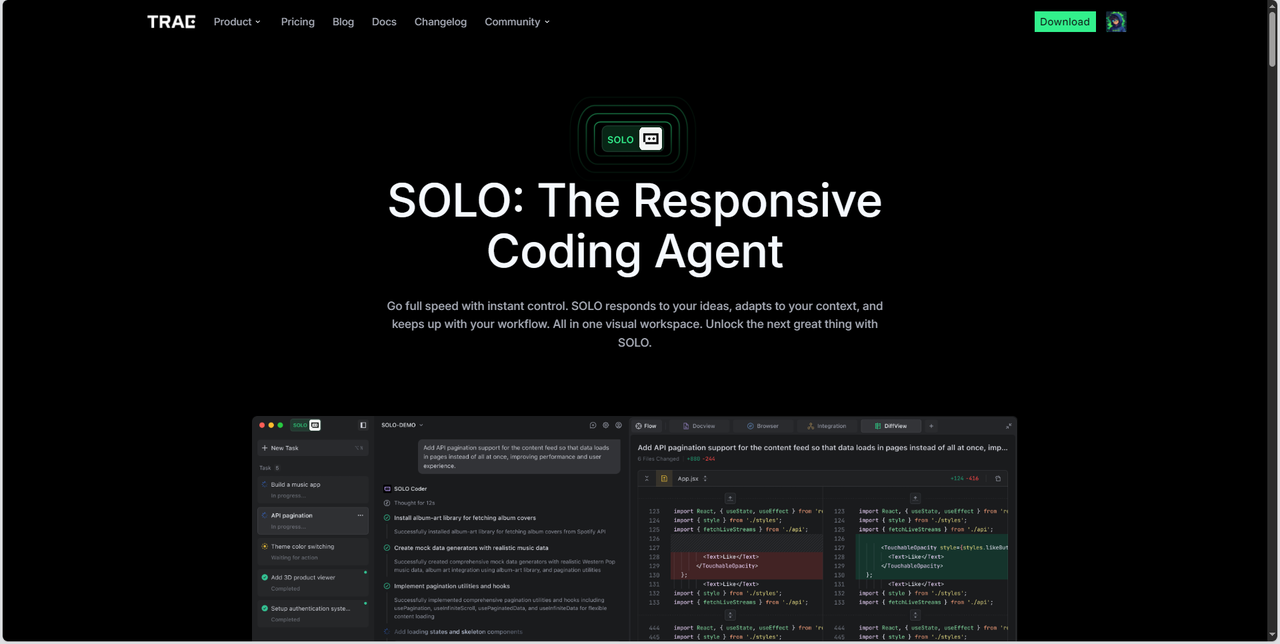
TRAE SOLO模式重新定义了人机协作的边界,它打破了传统编程工具的局限,将开发效率提升至全新高度。通过多任务并行管理、丰富的工具面板集成(如Figma设计稿自动转代码、Supabase数据库服务、Vercel一键部署等),以及智能的对话流节点折叠功能,SOLO模式不仅大幅降低了技术门槛,更让产品经理、设计师等非技术人员也能参与到应用构建中。这种"需求即产品"的开发范式,正在引领软件开发进入智能化、自动化的新时代。
4. 魔搭社区
魔搭社区——作为国内领先的模型开放平台,魔搭(ModelScope)以"模型即服务"(MaaS)为核心理念,构建了一个汇聚数千个优质机器学习模型的开源生态。其模型库覆盖计算机视觉、自然语言处理、语音识别、多模态理解等全领域,从基础的Qwen系列大模型到专业的DeepSeek-OCR、HunyuanOCR等垂直领域模型,开发者只需几行代码即可调用这些经过工业级验证的AI能力,将复杂的算法能力快速集成到自己的应用中。在Vibe Coding的创作过程中,我正是通过魔搭模型库的API接口,轻松实现了智能文本处理和多模态理解功能,让应用具备了强大的AI内核。
MCP广场是魔搭社区最具创新性的功能之一,它基于Model Context Protocol协议,为开发者提供了一个标准化的工具集成平台。在这里,您可以找到地图服务(如高德地图MCP)、支付接口(支付宝订阅服务)、数据库连接(Supabase集成)、浏览器自动化、知识记忆系统(MemOS)等数百种即插即用的智能工具。这些MCP服务就像乐高积木一样,让开发者能够快速构建具备真实世界交互能力的AI应用。在我的Vibe Coding作品中,我集成了多个MCP服务,实现了从用户需求理解到外部API调用的完整闭环,让应用不再局限于简单的对话,而是能够真正解决实际问题。
除了模型库和MCP广场,魔搭社区还提供Studios应用展示空间、数据集平台以及Swift训练框架等完整工具链。特别值得一提的是,魔搭的开放生态支持一键部署和快速迭代,让开发者能够专注于创意实现而非技术细节。参加魔搭研习社的Vibe Coding比赛,正是体验这种"AI赋能开发"理念的绝佳机会——通过魔搭社区的丰富资源,我们能够将天马行空的创意快速转化为具有实用价值的智能应用,真正实现"让AI触手可及"的愿景。
5. 接入教程
5.1. 获取API KEY
魔搭通过API-Inference,将开源模型服务化并通过API接口进行标准化,让开发者能以更轻量和迅捷的方式体验开源模型,并集成到不同的AI应用中,从而展开富有创造力的尝试,包括与工具结合调用,来构建多种多样的AI应用原型。
在访问令牌界面可以看到自己专属的API KEY
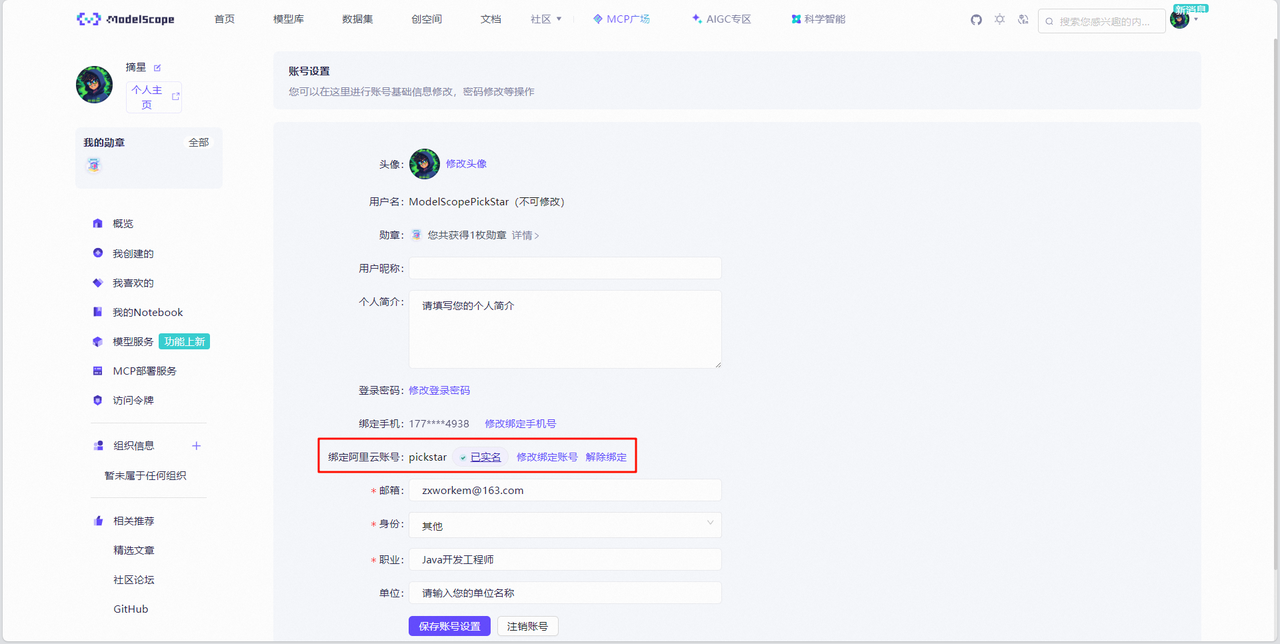
不过调用魔搭社区API的前提是绑定阿里云社区账号,这个很关键,否则会提示API调用报错。
5.2. Qwen3-VL-235B-A22B-Instruct
5.2.1. 模型简介
Qwen3-VL — 迄今为止 Qwen 系列中最强大的视觉语言模型。这一代在各个方面都进行了全面升级:更优秀的文本理解和生成能力、更深入的视觉感知和推理能力、更长的上下文长度、增强的空间和视频动态理解能力,以及更强的代理交互能力。提供从边缘到云端可扩展的 Dense 和 MoE 架构,并提供 Instruct 和增强推理的 Thinking 版本,以实现灵活、按需部署。
5.2.2. 模型架构
- 交错 MRoPE:通过鲁棒的位置嵌入在时间、宽度和高度上进行全频率分配,增强长距离视频推理。
- DeepStack:融合多层 ViT 特征,捕捉细粒度细节并锐化图像-文本对齐。
- 文本-时间戳对齐:超越 T-RoPE,实现精确的时间戳基础事件定位,以增强视频时间建模。
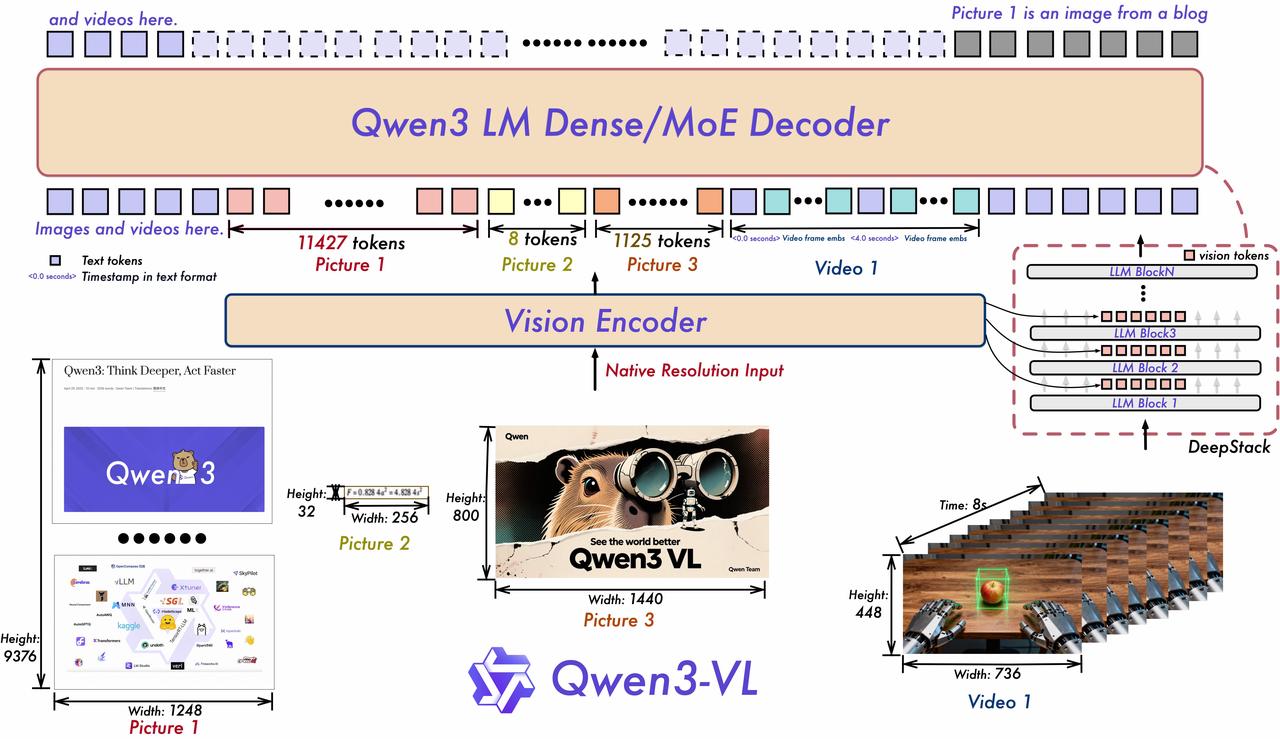
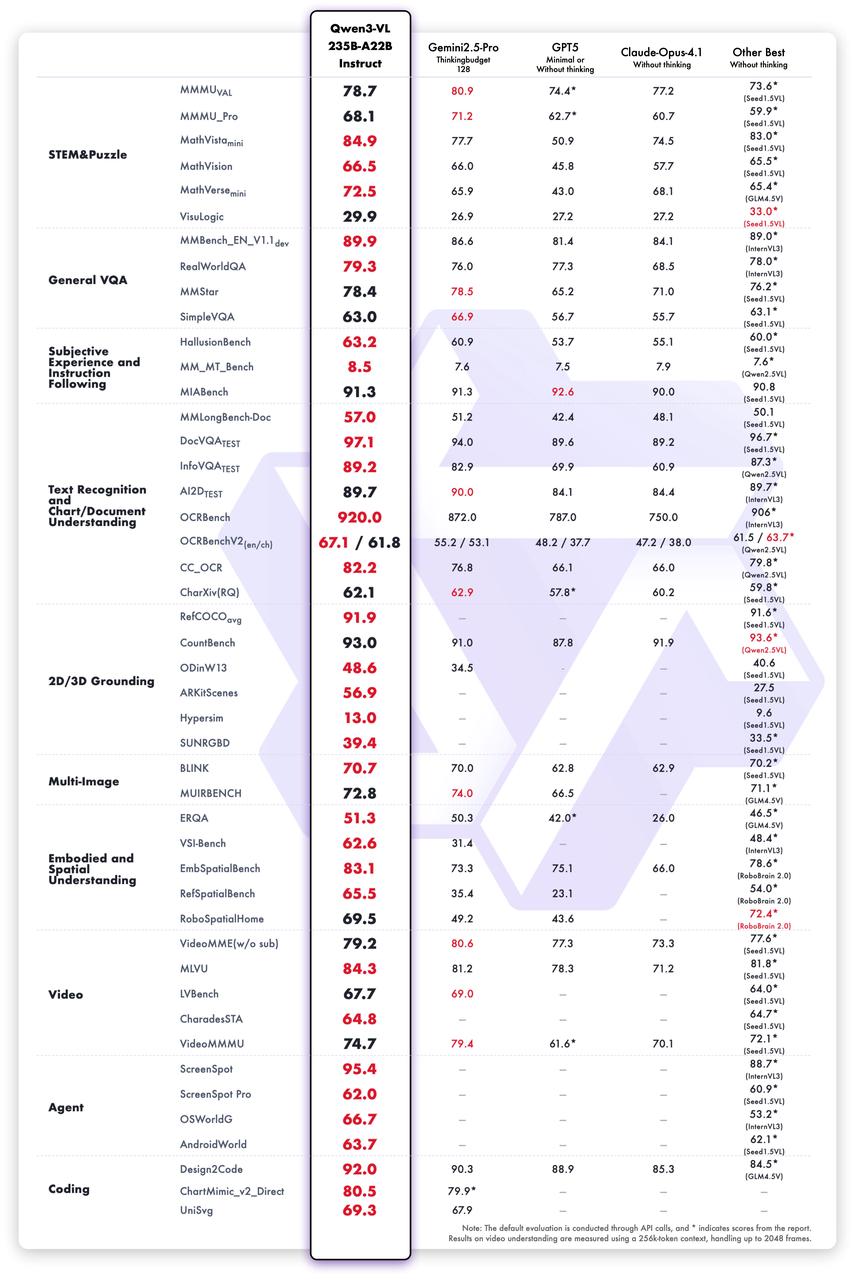
5.2.3. 模型性能
多模态性能:
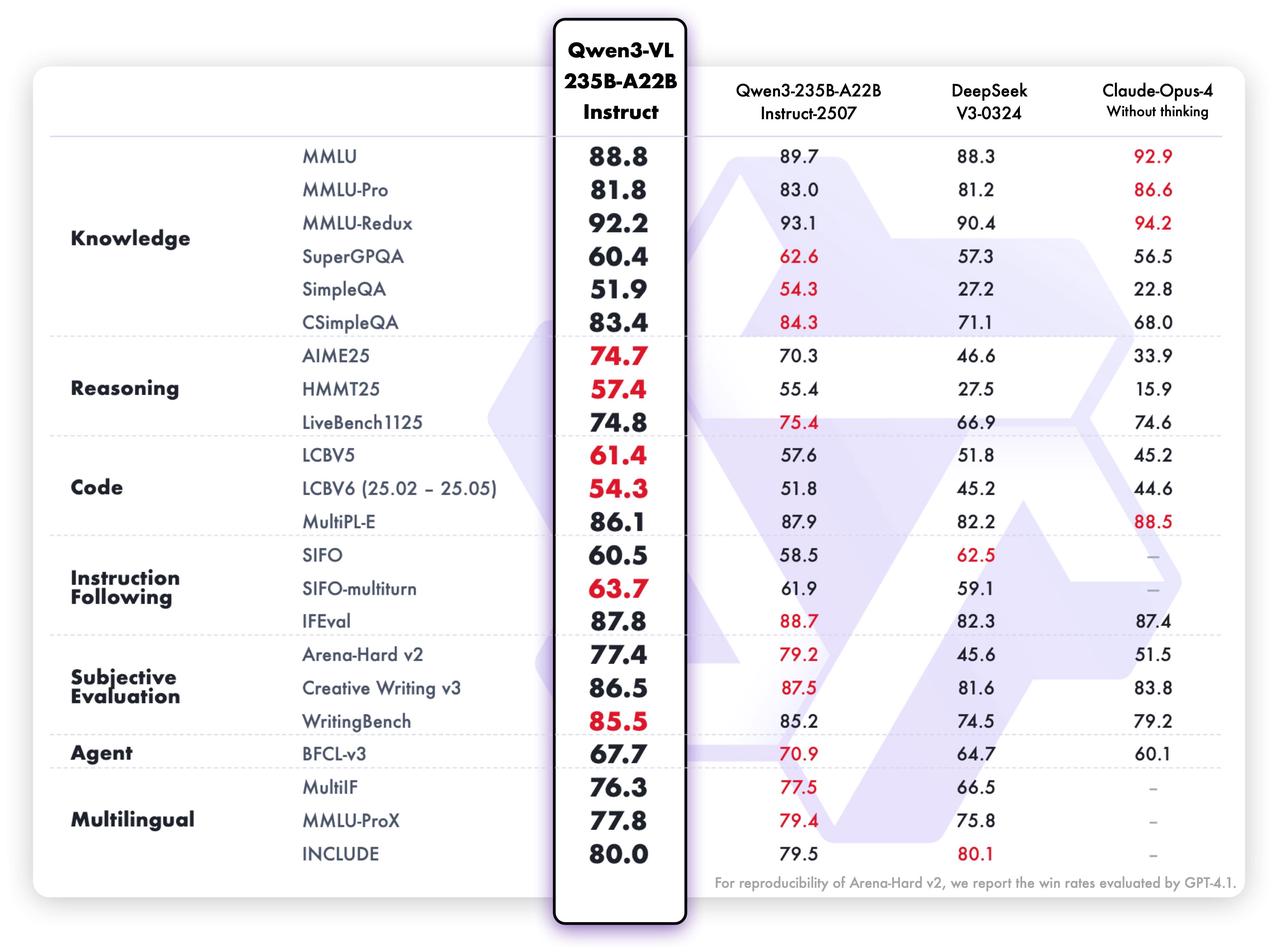
纯文本性能:
5.2.4. API接入示例
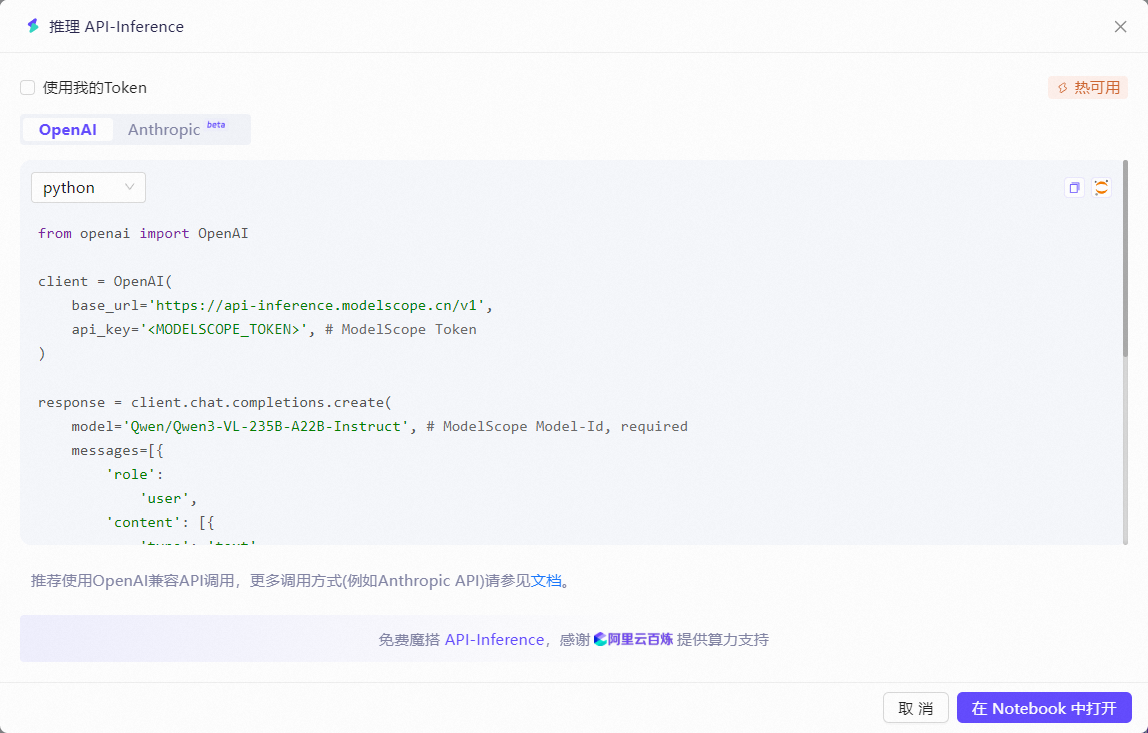
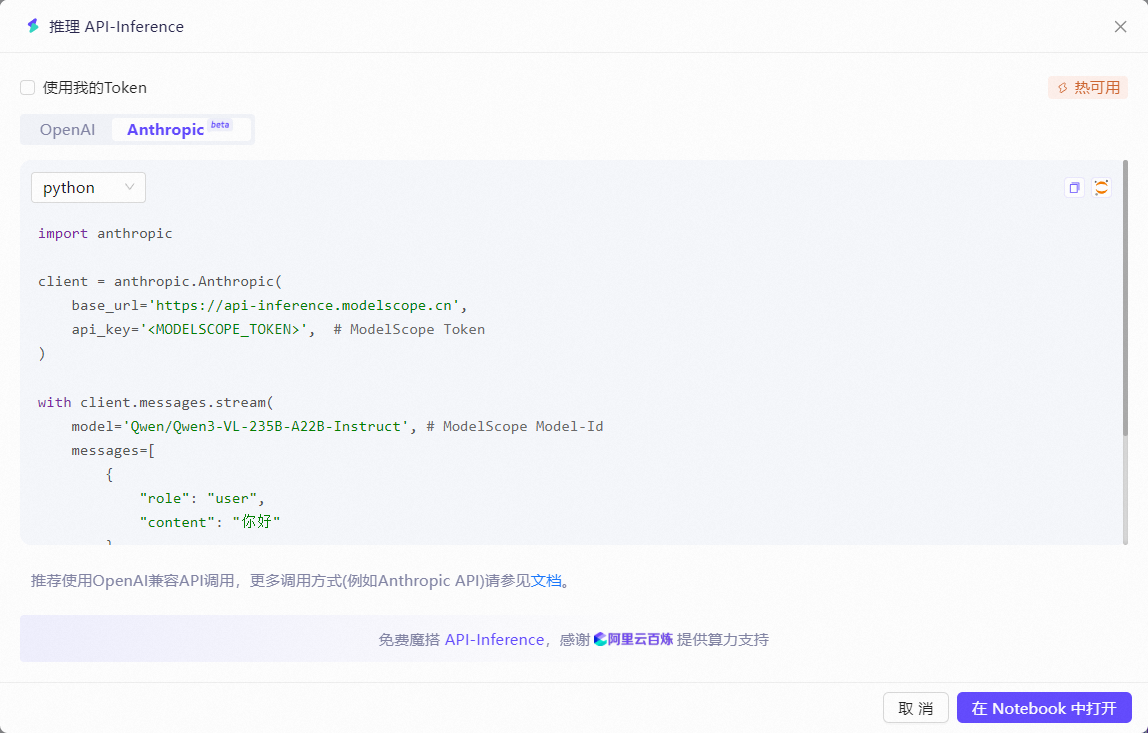
在Qwen3-VL-235B-A22B-Instruct的模型介绍界面右侧可以看到魔搭社区和通义千问官方给出的推理 API-Inference代码示例
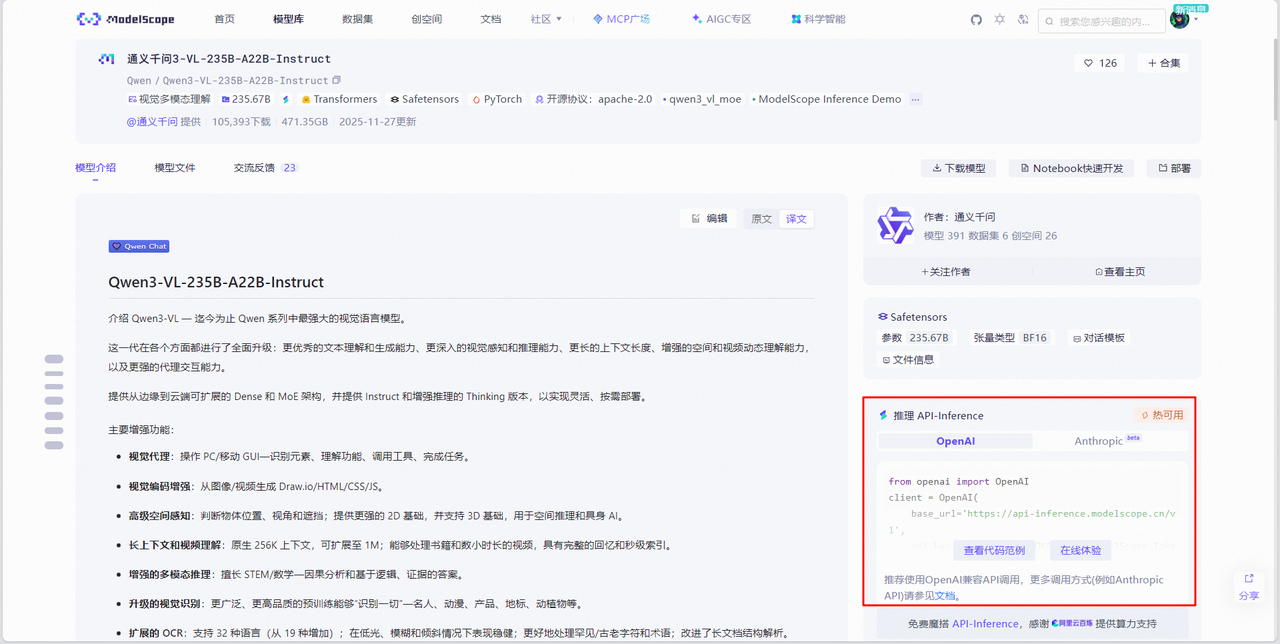
支持OpenAI和Anthropic的API格式
、
from openai import OpenAI
client = OpenAI(
base_url='https://api-inference.modelscope.cn/v1',
api_key='<MODELSCOPE_TOKEN>', # ModelScope Token
)
response = client.chat.completions.create(
model='Qwen/Qwen3-VL-235B-A22B-Instruct', # ModelScope Model-Id, required
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': '描述这幅图',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/audrey_hepburn.jpg',
},
}],
}],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end='', flush=True)
5.3. Qwen-Image
5.3.1. 模型简介
Qwen 系列中的一个图像生成基础模型,在 复杂文本渲染 和 精确图像编辑 方面取得了显著进展。实验显示,该模型在图像生成和编辑方面具有强大的通用能力,特别是在文本渲染方面表现出色,尤其是在中文上。
5.3.2. 模型优势
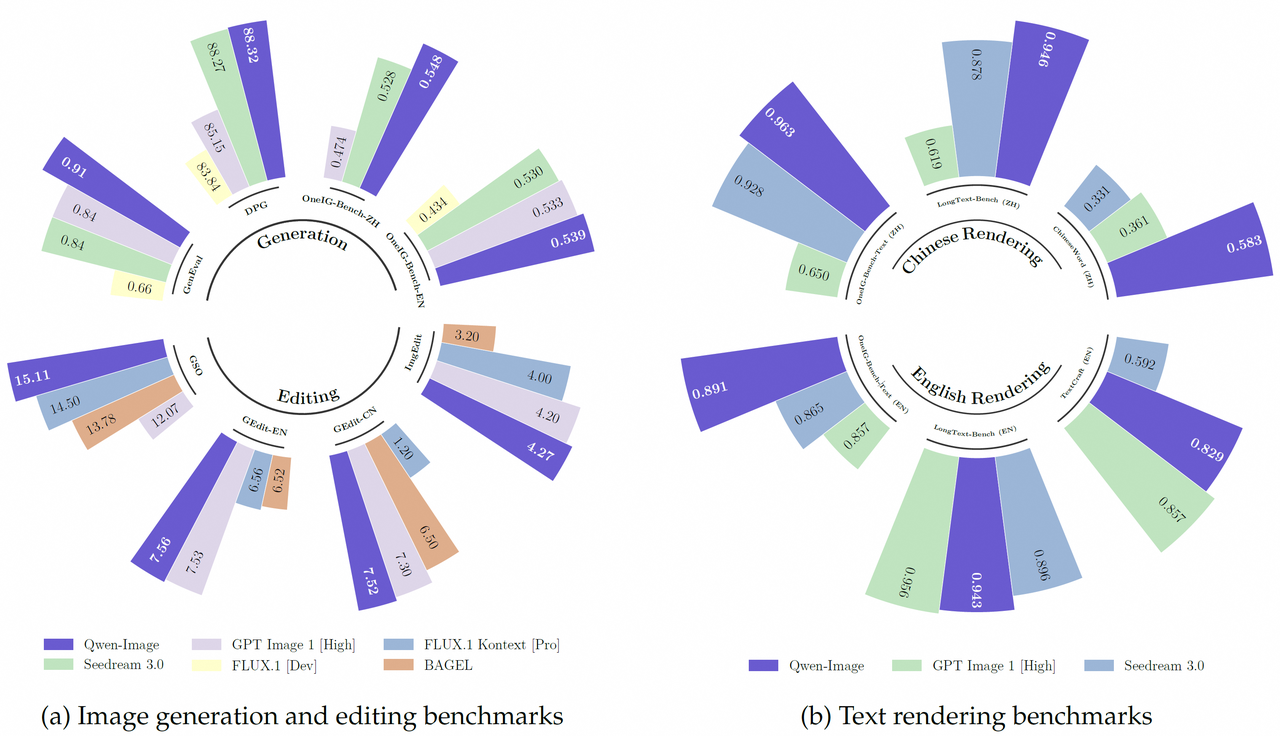
5.3.3. 部分案例展示

5.3.4. API接入示例
在Qwen/Qwen-Image的模型介绍界面右侧可以看到魔搭社区和通义千问官方给出的推理 API-Inference代码示例
import requests
import time
import json
from PIL import Image
from io import BytesIO
base_url = 'https://api-inference.modelscope.cn/'
api_key = "<MODELSCOPE_TOKEN>" # ModelScope Token
common_headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(
f"{base_url}v1/images/generations",
headers={**common_headers, "X-ModelScope-Async-Mode": "true"},
data=json.dumps({
"model": "Qwen/Qwen-Image", # ModelScope Model-Id, required
"prompt": "A golden cat"
}, ensure_ascii=False).encode('utf-8')
)
response.raise_for_status()
task_id = response.json()["task_id"]
while True:
result = requests.get(
f"{base_url}v1/tasks/{task_id}",
headers={**common_headers, "X-ModelScope-Task-Type": "image_generation"},
)
result.raise_for_status()
data = result.json()
if data["task_status"] == "SUCCEED":
image = Image.open(BytesIO(requests.get(data["output_images"][0]).content))
image.save("result_image.jpg")
break
elif data["task_status"] == "FAILED":
print("Image Generation Failed.")
break
time.sleep(5)
6. Vibe Coding开发实践
6.1. 开发提示词
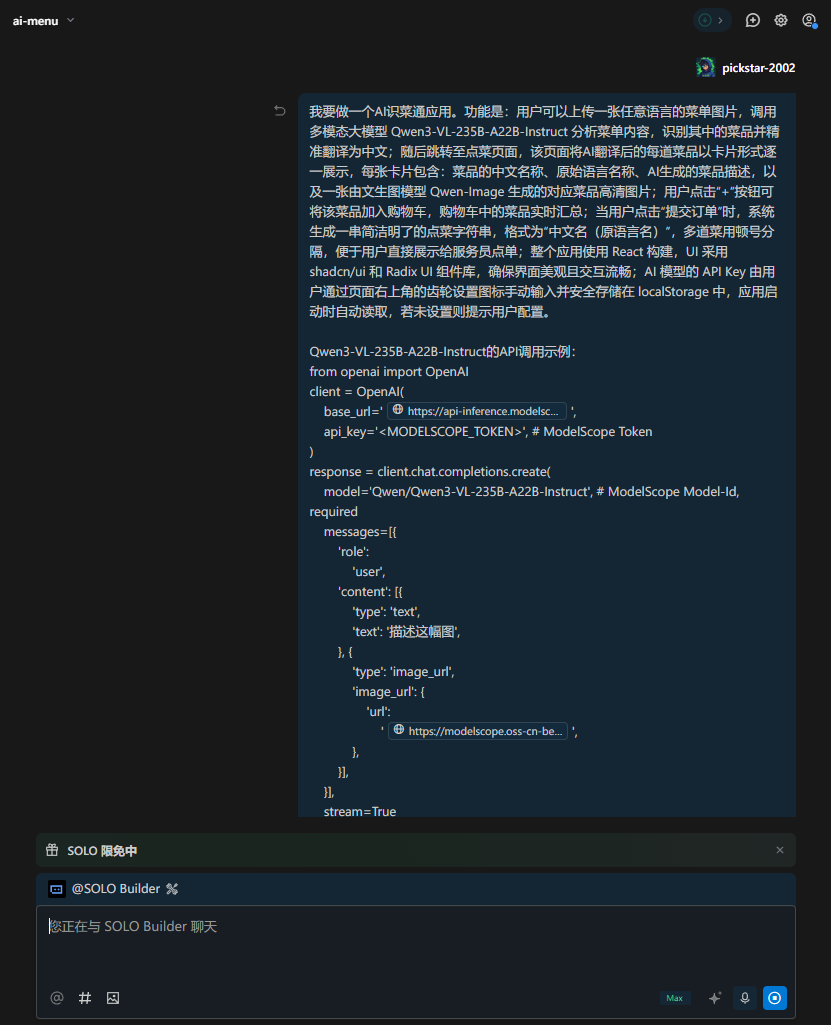
准备好如下开发提示词:
我要做一个AI识菜通应用。功能是:用户可以上传一张任意语言的菜单图片,调用多模态大模型 Qwen3-VL-235B-A22B-Instruct 分析菜单内容,识别其中的菜品并精准翻译为中文;随后跳转至点菜页面,该页面将AI翻译后的每道菜品以卡片形式逐一展示,每张卡片包含:菜品的中文名称、原始语言名称、AI生成的菜品描述,以及一张由文生图模型 Qwen-Image 生成的对应菜品高清图片;用户点击“+”按钮可将该菜品加入购物车,购物车中的菜品实时汇总;当用户点击“提交订单”时,系统生成一串简洁明了的点菜字符串,格式为“中文名(原语言名)”,多道菜用顿号分隔,便于用户直接展示给服务员点单;整个应用使用 React 构建,UI 采用 shadcn/ui 和 Radix UI 组件库,确保界面美观且交互流畅;AI 模型的 API Key 由用户通过页面右上角的齿轮设置图标手动输入并安全存储在 localStorage 中,应用启动时自动读取,若未设置则提示用户配置。
Qwen3-VL-235B-A22B-Instruct的API调用示例:
from openai import OpenAI
client = OpenAI(
base_url='https://api-inference.modelscope.cn/v1',
api_key='<MODELSCOPE_TOKEN>', # ModelScope Token
)
response = client.chat.completions.create(
model='Qwen/Qwen3-VL-235B-A22B-Instruct', # ModelScope Model-Id, required
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': '描述这幅图',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/audrey_hepburn.jpg',
},
}],
}],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end='', flush=True)
Qwen-Image的API调用示例:
import requests
import time
import json
from PIL import Image
from io import BytesIO
base_url = 'https://api-inference.modelscope.cn/'
api_key = "<MODELSCOPE_TOKEN>" # ModelScope Token
common_headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(
f"{base_url}v1/images/generations",
headers={**common_headers, "X-ModelScope-Async-Mode": "true"},
data=json.dumps({
"model": "Qwen/Qwen-Image", # ModelScope Model-Id, required
"prompt": "A golden cat"
}, ensure_ascii=False).encode('utf-8')
)
response.raise_for_status()
task_id = response.json()["task_id"]
while True:
result = requests.get(
f"{base_url}v1/tasks/{task_id}",
headers={**common_headers, "X-ModelScope-Task-Type": "image_generation"},
)
result.raise_for_status()
data = result.json()
if data["task_status"] == "SUCCEED":
image = Image.open(BytesIO(requests.get(data["output_images"][0]).content))
image.save("result_image.jpg")
break
elif data["task_status"] == "FAILED":
print("Image Generation Failed.")
break
time.sleep(5)
将上方准备好的开发提示词输入TRAE:
6.2. 项目文档
Trae Solo会自动帮你创建两份文档,分别是需求文档和架构文档:
6.2.1. 产品需求文档
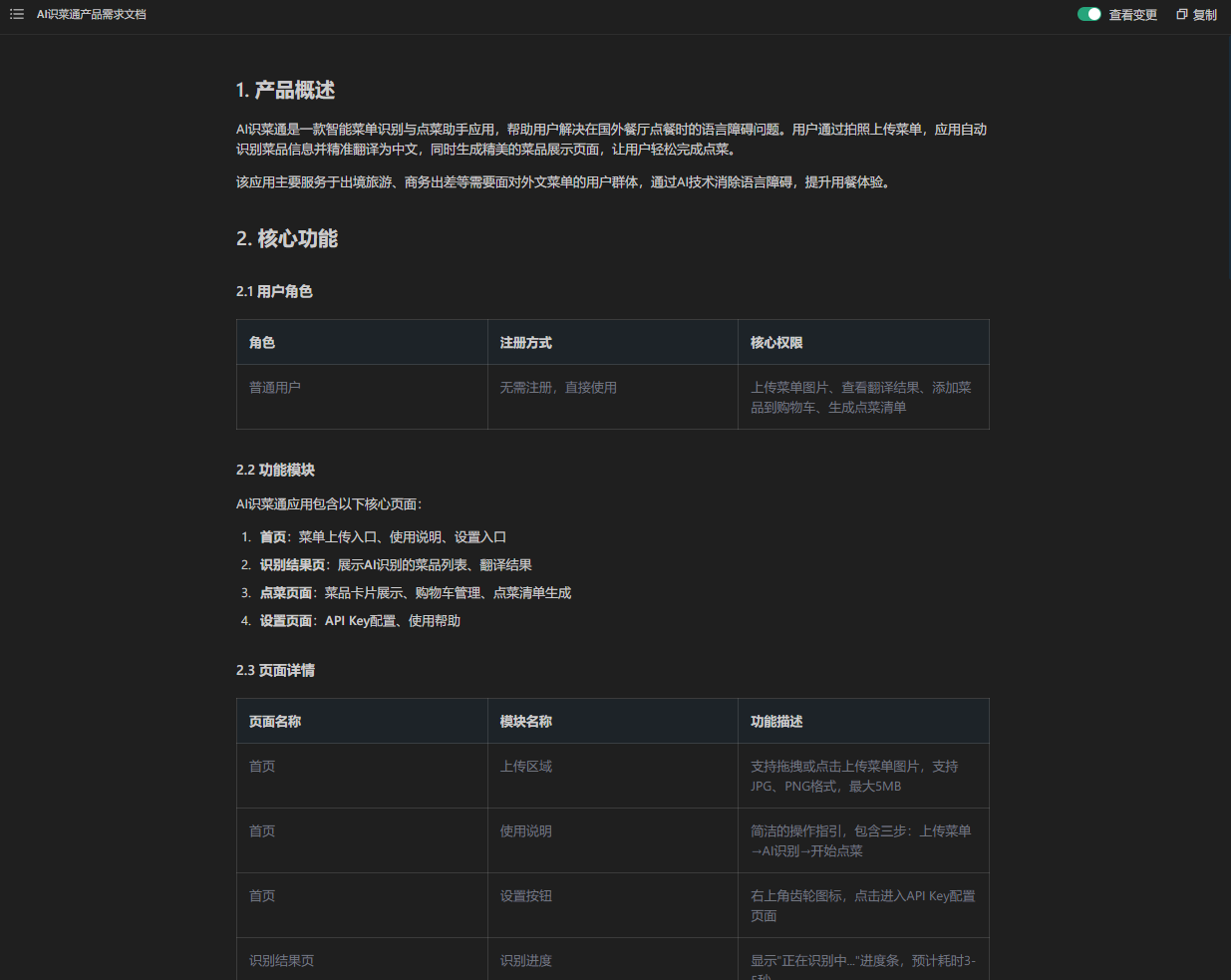
## 1. 产品概述
AI识菜通是一款智能菜单识别与点菜助手应用,帮助用户解决在国外餐厅点餐时的语言障碍问题。用户通过拍照上传菜单,应用自动识别菜品信息并精准翻译为中文,同时生成精美的菜品展示页面,让用户轻松完成点菜。
该应用主要服务于出境旅游、商务出差等需要面对外文菜单的用户群体,通过AI技术消除语言障碍,提升用餐体验。
## 2. 核心功能
### 2.1 用户角色
| 角色 | 注册方式 | 核心权限 |
|------|----------|----------|
| 普通用户 | 无需注册,直接使用 | 上传菜单图片、查看翻译结果、添加菜品到购物车、生成点菜清单 |
### 2.2 功能模块
AI识菜通应用包含以下核心页面:
1. **首页**:菜单上传入口、使用说明、设置入口
2. **识别结果页**:展示AI识别的菜品列表、翻译结果
3. **点菜页面**:菜品卡片展示、购物车管理、点菜清单生成
4. **设置页面**:API Key配置、使用帮助
### 2.3 页面详情
| 页面名称 | 模块名称 | 功能描述 |
|----------|----------|----------|
| 首页 | 上传区域 | 支持拖拽或点击上传菜单图片,支持JPG、PNG格式,最大5MB |
| 首页 | 使用说明 | 简洁的操作指引,包含三步:上传菜单→AI识别→开始点菜 |
| 首页 | 设置按钮 | 右上角齿轮图标,点击进入API Key配置页面 |
| 识别结果页 | 识别进度 | 显示"正在识别中..."进度条,预计耗时3-5秒 |
| 识别结果页 | 菜品列表 | 展示识别出的所有菜品,包含原始语言名称和中文翻译 |
| 识别结果页 | 操作按钮 | "开始点菜"按钮,点击进入点菜页面 |
| 点菜页面 | 菜品卡片 | 每张卡片包含:菜品图片、中文名称、原始语言名称、AI描述、价格、"加入购物车"按钮 |
| 点菜页面 | 购物车 | 底部悬浮栏显示已选菜品数量和总价,点击展开详情 |
| 点菜页面 | 点菜清单 | 生成格式化的点菜字符串,包含菜品中文名和数量,便于展示给服务员 |
| 设置页面 | API配置 | 输入框用于设置Qwen3-VL和Qwen-Image的API Key,保存至localStorage |
| 设置页面 | 使用帮助 | 简明的使用教程和常见问题解答 |
## 3. 核心流程
### 用户操作流程
1. **菜单识别流程**:
- 用户进入首页 → 上传菜单图片 → 系统调用Qwen3-VL-235B-A22B-Instruct模型识别 → 展示识别结果 → 进入点菜页面
2. **点菜流程**:
- 浏览菜品卡片 → 点击"加入购物车" → 查看购物车 → 调整数量 → 生成点菜清单 → 展示给服务员
```mermaid
graph TD
A[首页] --> B{上传菜单图片}
B --> C[AI识别中]
C --> D[识别结果页]
D --> E[点菜页面]
E --> F[添加菜品到购物车]
F --> G[生成点菜清单]
G --> H[完成点菜]
A --> I[设置页面]
I --> A
```
## 4. 用户界面设计
### 4.1 设计风格
- **主色调**:温暖橙色(#FF6B35)搭配纯净白色,营造食欲感
- **辅助色**:深灰色(#2D3748)用于文字,浅灰色(#F7FAFC)用于背景
- **按钮风格**:圆角矩形设计,主要按钮使用渐变色,悬停效果明显
- **字体**:中文使用思源黑体,英文使用Inter,确保跨语言显示效果
- **布局风格**:卡片式布局,左右留白充足,突出内容重点
- **图标风格**:使用圆润的线性图标,符合餐饮行业温馨氛围
### 4.2 页面设计概述
| 页面名称 | 模块名称 | UI元素 |
|----------|----------|----------|
| 首页 | 上传区域 | 大尺寸虚线框,中央上传图标,支持拖拽效果,上传后显示缩略图 |
| 首页 | 使用说明 | 三步骤横向排列,每步配简洁图标和简短文字说明 |
| 识别结果页 | 进度条 | 顶部细长进度条,带百分比显示,使用橙色渐变 |
| 识别结果页 | 菜品列表 | 简洁列表形式,左右分栏显示原文和译文,使用分隔线清晰区分 |
| 点菜页面 | 菜品卡片 | 网格布局,每张卡片圆角阴影,图片占2/3高度,文字信息层次清晰 |
| 点菜页面 | 购物车 | 底部圆形悬浮按钮,显示数量角标,展开后为抽屉式面板 |
| 设置页面 | API配置 | 简洁表单布局,带密码隐藏功能,保存成功显示toast提示 |
### 4.3 响应式设计
- **移动端优先**:针对手机使用场景优化,确保单手操作便利
- **断点设计**:320px(手机)、768px(平板)、1024px(桌面)三档适配
- **触摸优化**:按钮最小44px触摸区域,支持滑动手势操作
- **图片适配**:菜品图片采用object-fit: cover,确保各种比例图片显示效果一致
6.2.2. 技术架构文档
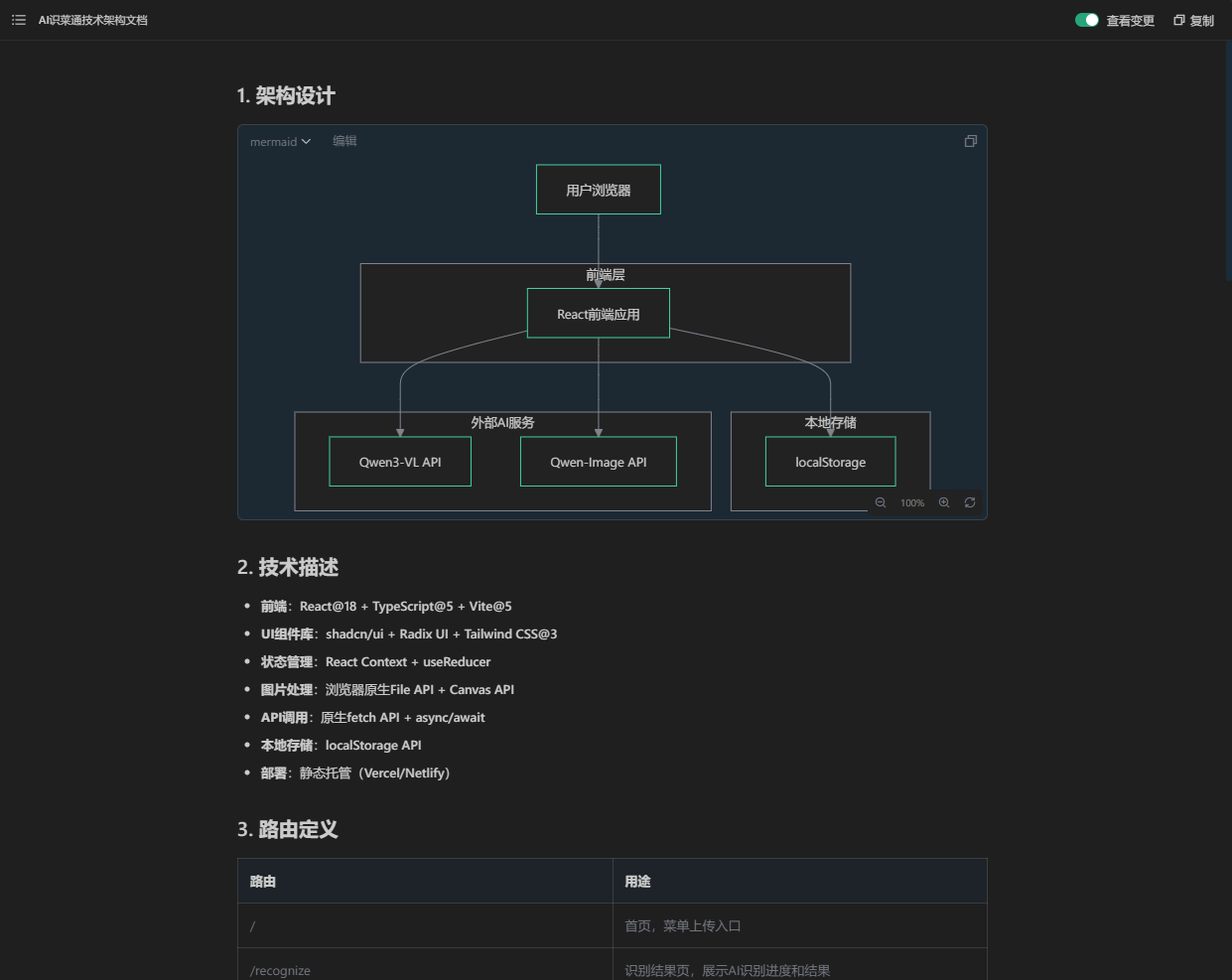
## 1. 架构设计
```mermaid
graph TD
A[用户浏览器] --> B[React前端应用]
B --> C[localStorage]
B --> D[Qwen3-VL API]
B --> E[Qwen-Image API]
subgraph "前端层"
B
end
subgraph "本地存储"
C
end
subgraph "外部AI服务"
D
E
end
```
## 2. 技术描述
- **前端**:React@18 + TypeScript@5 + Vite@5
- **UI组件库**:shadcn/ui + Radix UI + Tailwind CSS@3
- **状态管理**:React Context + useReducer
- **图片处理**:浏览器原生File API + Canvas API
- **API调用**:原生fetch API + async/await
- **本地存储**:localStorage API
- **部署**:静态托管(Vercel/Netlify)
## 3. 路由定义
| 路由 | 用途 |
|-------|---------|
| / | 首页,菜单上传入口 |
| /recognize | 识别结果页,展示AI识别进度和结果 |
| /order | 点菜页面,菜品展示和购物车管理 |
| /settings | 设置页面,API Key配置 |
## 4. 核心组件架构
### 4.1 状态管理结构
```typescript
interface AppState {
// 全局状态
apiKeys: {
qwenVL: string;
qwenImage: string;
};
// 识别相关
recognition: {
isLoading: boolean;
progress: number;
menuImage: File | null;
recognizedDishes: Dish[];
};
// 点菜相关
order: {
cart: CartItem[];
totalAmount: number;
};
}
interface Dish {
id: string;
originalName: string;
chineseName: string;
description: string;
price: string;
imageUrl: string;
category?: string;
}
interface CartItem {
dish: Dish;
quantity: number;
}
```
### 4.2 API服务层
```typescript
class QwenAPIService {
// 菜单识别
async recognizeMenu(imageFile: File, apiKey: string): Promise<Dish[]> {
const base64Image = await this.fileToBase64(imageFile);
const response = await fetch('https://api.qwen.com/vl/analyze', {
method: 'POST',
headers: {
'Authorization': `Bearer ${apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
model: 'qwen3-vl-235b-a22b-instruct',
prompt: '识别菜单中的所有菜品,包括名称、价格、描述,并翻译成中文',
image: base64Image
})
});
return this.parseMenuResponse(response);
}
// 生成菜品图片
async generateDishImage(dishName: string, apiKey: string): Promise<string> {
const response = await fetch('https://api.qwen.com/image/generate', {
method: 'POST',
headers: {
'Authorization': `Bearer ${apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
model: 'qwen-image',
prompt: `美食摄影:${dishName},专业餐厅摆盘,高清,诱人`
})
});
return response.json().data.url;
}
private fileToBase64(file: File): Promise<string> {
return new Promise((resolve) => {
const reader = new FileReader();
reader.onload = () => resolve(reader.result as string);
reader.readAsDataURL(file);
});
}
}
```
## 5. 关键技术实现要点
### 5.1 图片上传与预处理
- 使用React的useRef获取文件输入元素
- 实现拖拽上传功能,监听dragover和drop事件
- 图片压缩:使用Canvas API将大图压缩至合适尺寸
- 格式验证:检查文件类型和大小限制
### 5.2 进度条实现
- 使用setInterval模拟识别进度(0-90%)
- 真实进度:根据API响应完成度更新(90-100%)
- 平滑动画:CSS transition实现进度条平滑移动
### 5.3 菜品卡片懒加载
- 使用Intersection Observer API实现图片懒加载
- 骨架屏:加载过程中显示灰色占位块
- 错误处理:图片加载失败显示默认菜品图标
### 5.4 购物车状态管理
- 使用Context API跨组件共享购物车状态
- 持久化:localStorage保存购物车数据
- 数量更新:防抖处理频繁的状态更新
### 5.5 响应式图片处理
- 多尺寸适配:根据屏幕密度提供不同尺寸图片
- 对象适配:object-fit: cover保持图片比例
- 加载优化:WebP格式优先,降级至JPEG
## 6. 错误处理与用户体验
### 6.1 API错误处理
```typescript
interface APIError {
code: string;
message: string;
details?: any;
}
class ErrorHandler {
static handleAPIError(error: APIError): string {
const errorMap: Record<string, string> = {
'INVALID_API_KEY': 'API密钥无效,请检查设置',
'RATE_LIMIT_EXCEEDED': '请求过于频繁,请稍后再试',
'IMAGE_TOO_LARGE': '图片过大,请压缩后重试',
'RECOGNITION_FAILED': '识别失败,请尝试更清晰的图片'
};
return errorMap[error.code] || '服务暂时不可用,请重试';
}
}
```
### 6.2 离线支持
- Service Worker缓存静态资源
- 图片本地缓存:IndexedDB存储已生成的菜品图片
- 网络检测:navigator.onLine判断网络状态
### 6.3 性能优化
- 代码分割:按路由懒加载组件
- 图片预加载:提前加载可视区域内的菜品图片
- 防抖节流:优化搜索和滚动事件处理
6.3. 开发交互
在确保AI完全理解我们的意思,发出命令:按照文档进行开发!
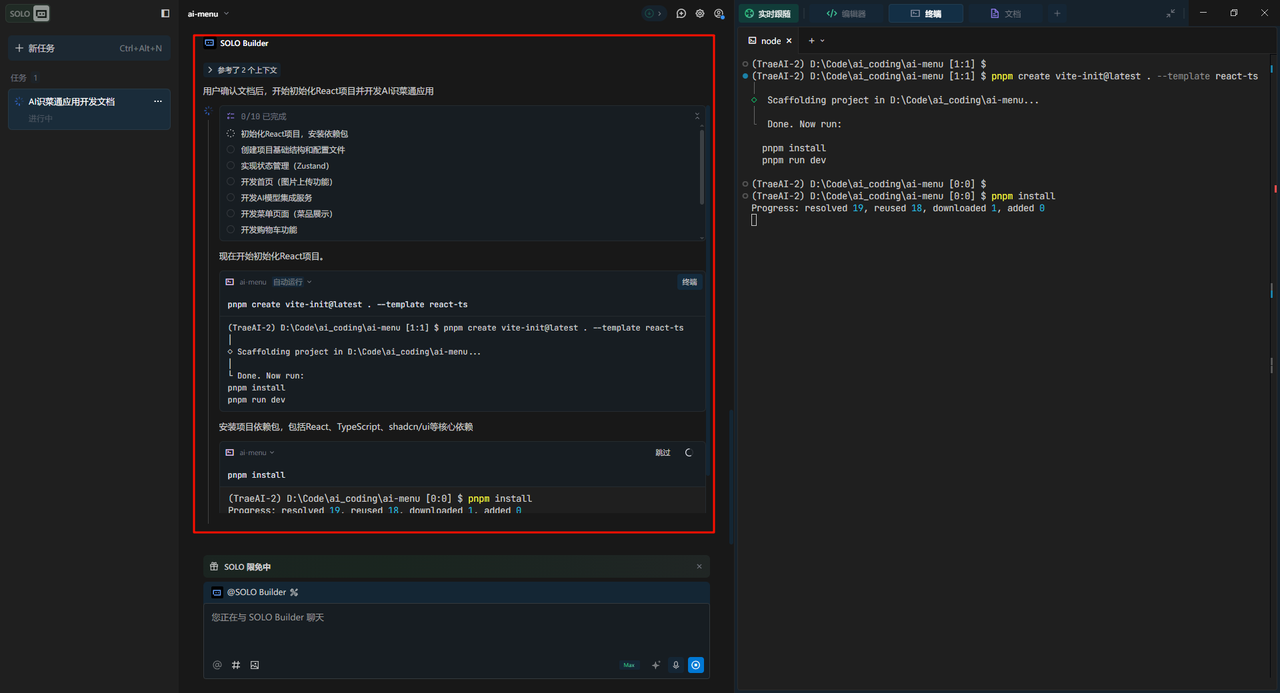
Trae Solo会在开发的过程中自动下载依赖、创建配置文件、生成函数、运行终端,运到的问题也都会被当做上下文继续完善开发:
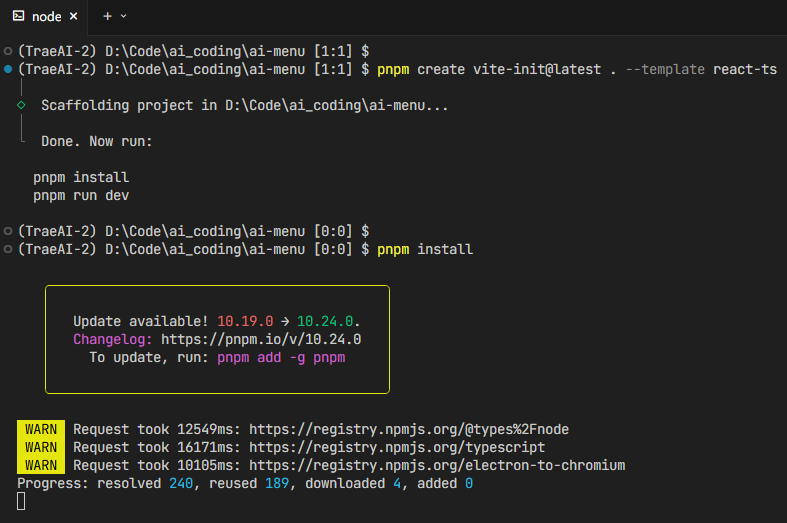
Trae Solo 不仅能自动创建文件、下载依赖,还能智能识别并修复依赖过程中的错误;即使你中途打断并提出新问题,它也会结合已有内容与新输入进行上下文感知的重新思考,全程从容不乱,且支持一键将错误加入上下文自动修复并自测,远比传统复制错误信息再手动调试的方式更让程序员安心。
最终形成完整的作品: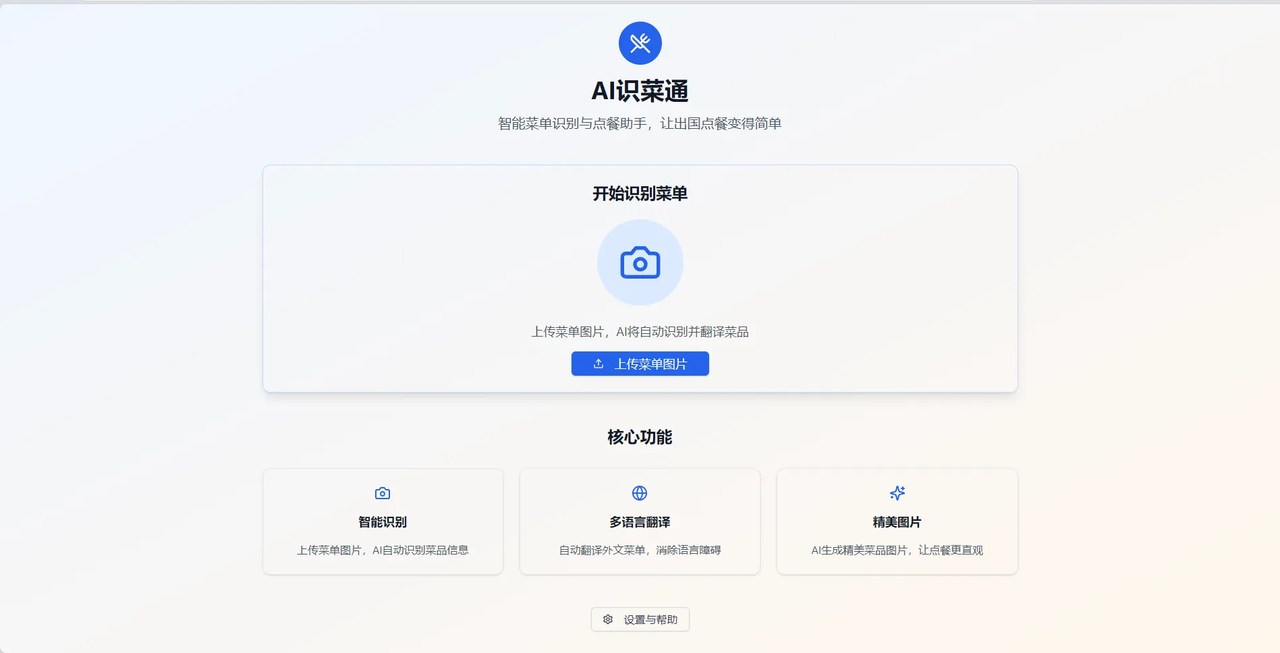
7. 总结
“AI识菜通”展示了 AI 赋能垂直场景 的典型范例——将前沿多模态大模型能力与实际生活痛点(如海外点餐语言障碍)相结合。其技术实现融合了魔搭社区的模型即服务(MaaS)能力(包括视觉语言理解与图像生成)与 TRAE 的智能全栈开发能力,实现了从“想法”到“可运行产品”的高效转化。
- 技术亮点:
- 利用 Qwen3-VL 实现高精度菜单识别与翻译;
- 利用 Qwen-Image 生成高逼真菜品图,增强用户体验;
- 前端安全本地存储 API 密钥,兼顾功能与隐私;
- 全流程由 TRAE SOLO 模式自动构建,体现“需求即产品”的新开发范式。
- 应用价值: 为出境游客、留学生等群体提供实用工具,降低跨语言餐饮沟通门槛,体现“科技服务生活”的理念。
- 开发启示: 借助 TRAE + 魔搭社区的生态组合,开发者(甚至非技术人员)可快速将创意落地为具备真实世界交互能力的 AI 应用,标志着 AI 原生开发时代的到来。


