
不愧是国内首个视觉编程模型,一张草稿图直接做了一个电子版City Walk


“City Walk”太费腿?那就让AI替你走一遍。
本文记录我如何用 Doubao-Seed-Code —— 国内首个具备原生视觉理解能力的AI编程模型,把一张手绘草图变成一个可交互的“电子城市漫步”应用。全程零代码基础,仅靠对话完成编程。
一.背景
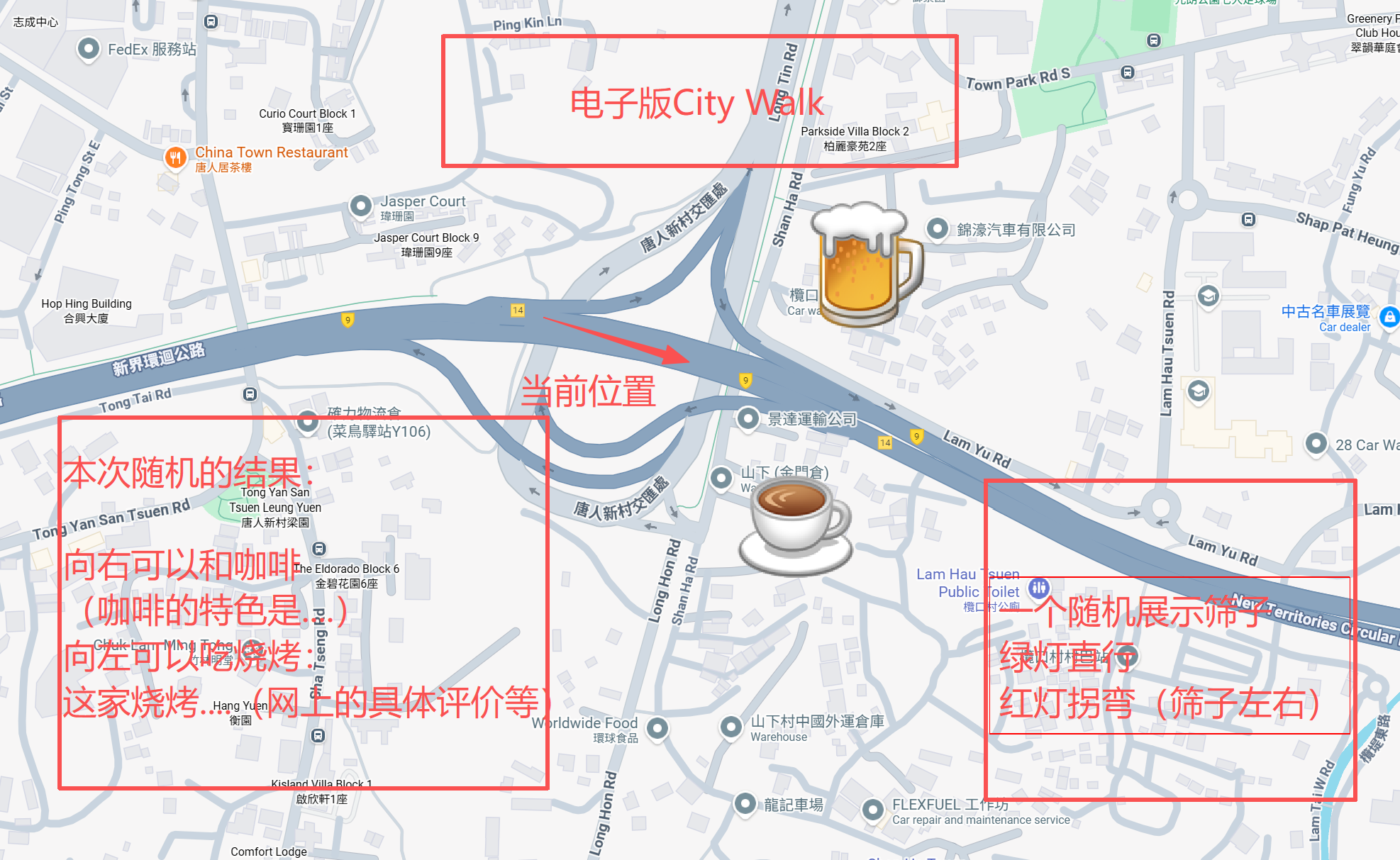
“City Walk”——城市漫步,曾是年轻人逃离内卷的诗意解药:绿灯直行、红灯拐弯、路口掷骰子、遇见小店就进去坐坐,拍一百张照片,只为记录一条无人知晓的小巷。它不为打卡,只为“瞎溜达”。
但对我这种能坐绝不站、能躺绝不坐的懒人来说:
“走1公里,拍100张照,找3家店,最后发现没带充电宝。”
于是,我灵机一动:为什么不做一个“电子版City Walk”?如果有合适的,我在出门。
不用出门,打开网页,点击“开始漫步”,AI就带着我在城市里“瞎溜达”——绿灯直行、红灯拐弯、路口掷骰子,还能推荐路边的宝藏咖啡馆和涂鸦墙。
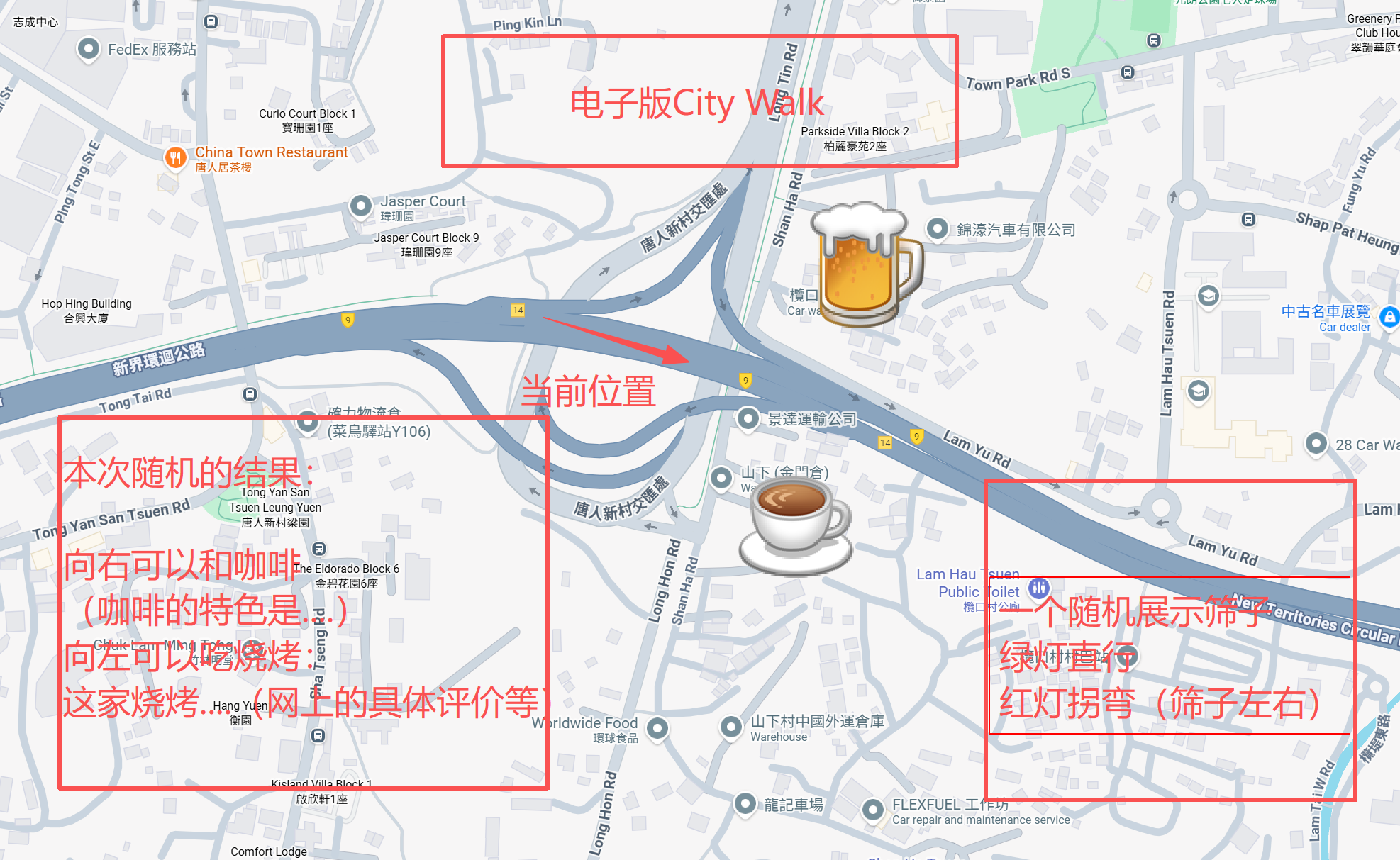
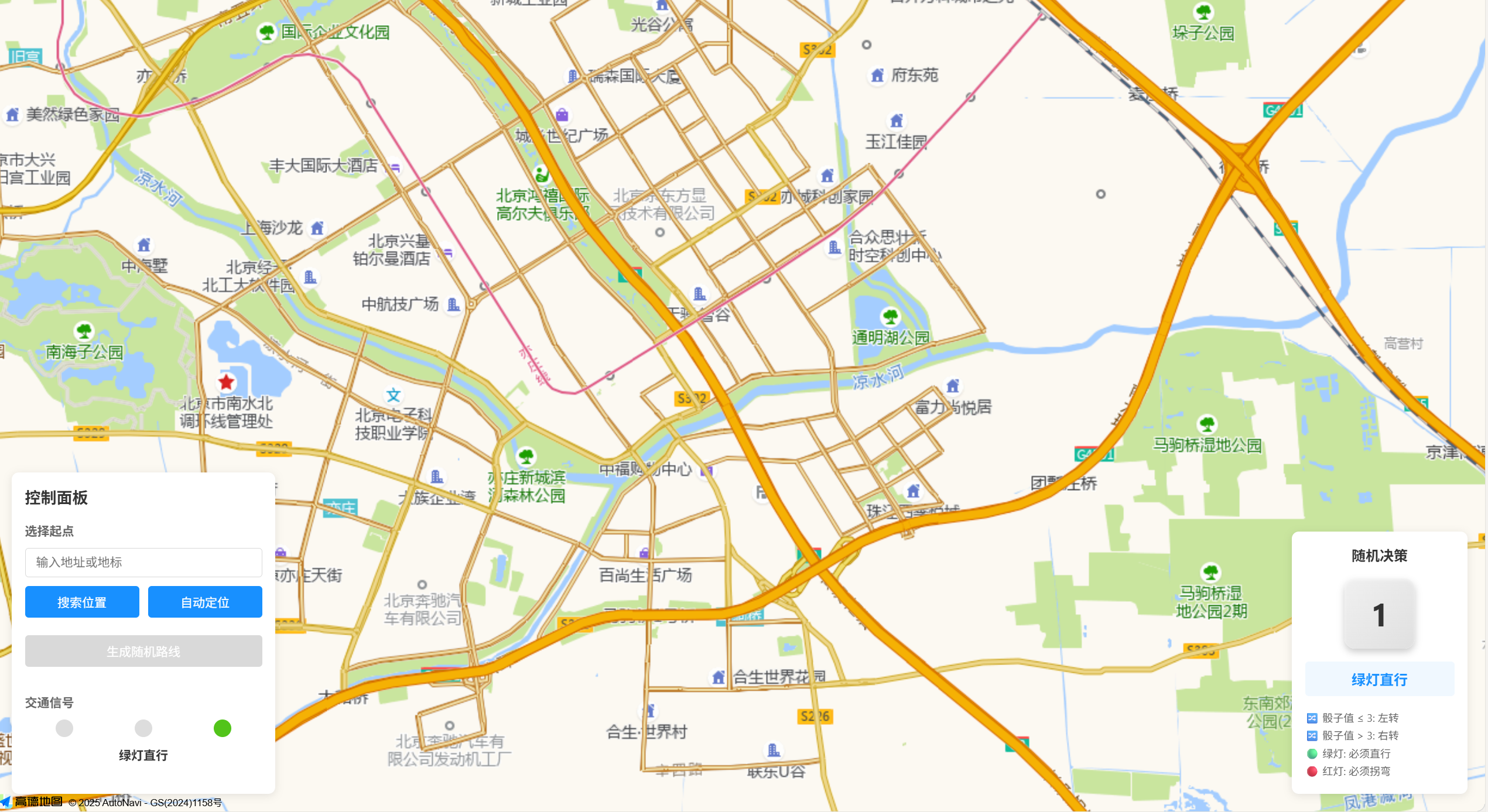
左侧为草稿图,右侧为使用 Doubao-Seed-Code 编程的效果。
二.相关介绍
工具选择:为什么是 Doubao-Seed-Code?
Doubao-Seed-Code 是一款专为 "Agentic Coding"任务深度优化的全新代码模型。它为真实的、复杂的编程任务而设计,在长上下文理解、任务规划、代码生成与调试方面均有卓越表现。
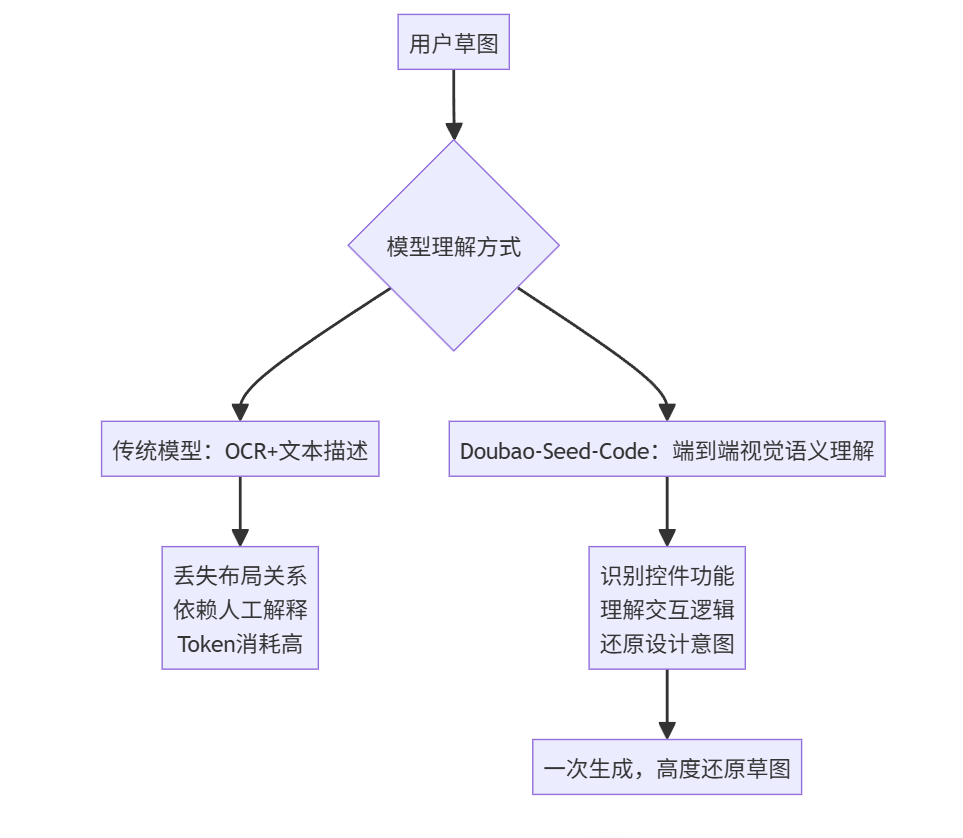
我试过多个主流AI编程模型(Claude 3.5、GPT-4o、GLM-4、DeepSeek-Coder),但它们要么:
- ❌ 无法理解图片(只能靠文字描述)
- ❌ 生成的界面五花八门,完全偏离草图
- ❌ 需要手动拆解“地图+随机路线+骰子+POI推荐”等复杂逻辑,效率极低
直到我发现了 火山引擎的 Doubao-Seed-Code。
✅ 它的三大杀手锏,直接击中我的痛点:
能力 | 普通模型 | Doubao-Seed-Code |
视觉理解 | ❌ 依赖OCR/文本转述(信息丢失) | ✅ 原生VLM,直接看图写代码,0损失 |
长上下文 | 通常≤32K | ✅ 256K,整项目代码+图片+需求全塞进去 |
成本 | 业内均价高 | ✅ 综合成本低62.7%,首月9.9元起 |
关键点: 它不是“能看图”,而是真正理解图中的布局、交互、语义关系——比如我草图里左下角的“骰子”和“向右喝咖啡”,它知道那是两个独立的交互模块,不是随便画的装饰。
三.全程“对话式开发”
前置准备
虽然使用的是Doubao-Seed-Code这个国内首个具备视觉理解能力的编程模型,但是这在他的人家官方公司,我们没办法直接用,所以可以通过 Claude Code去调用 Doubao-Seed-Code ,另外,在火山方舟平台也是提供API调用。
仅需 5s 在Claude Code 丝滑接入 Doubao-Seed-Code
在启动 Claude Code 前输入环境变量(以Windows为例):
📌注意:<ARK-API-KEY>换为你自己的,来这里获取 -> https://console.volcengine.com/ark/region:ark+cn-beijing/apikey
📚如果有不会的地方可以看官方教程来配置:https://www.volcengine.com/docs/82379/1928262
真消费才敢说真话。

使用指令导航到指定目录,并启动claude:
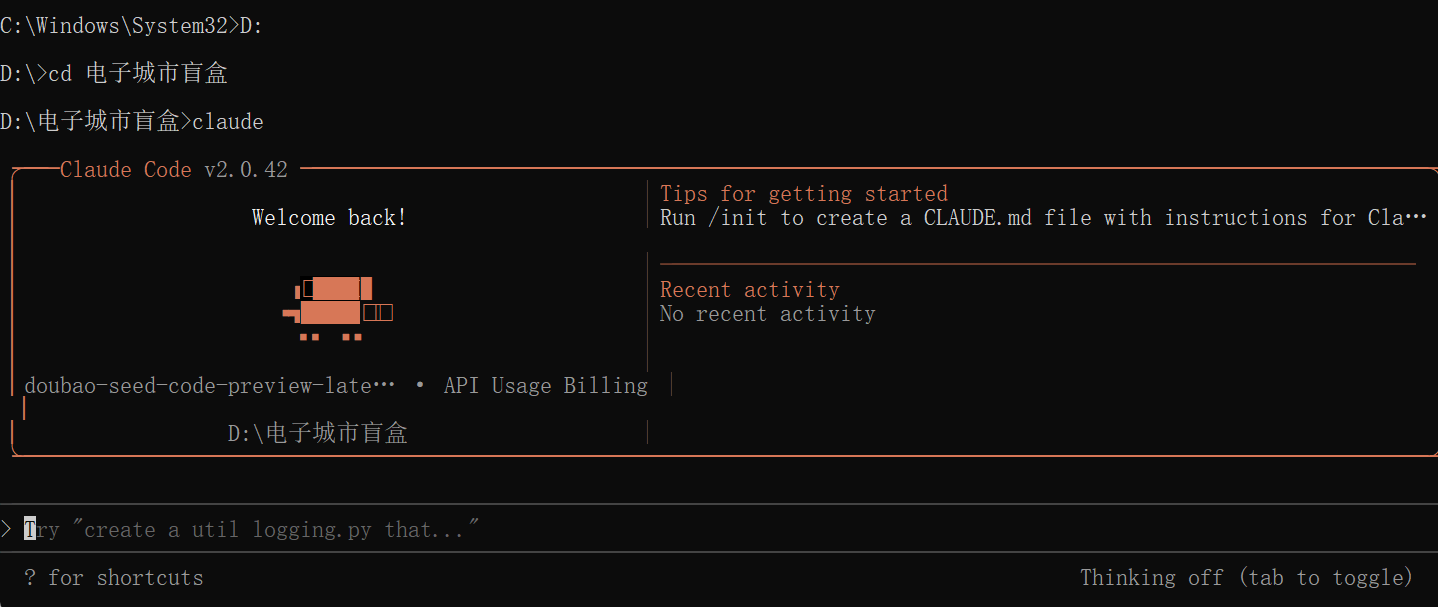
可以看到如图所示成功启动并使用Doubao-Seed-Code模型, 兼容了原本的 Anthropic API,对于使用Claude Code的开发者,几乎零成本 将 API 切换到 Doubao-Seed-Code,完全无缝,像换了“引擎”,但方向盘还是原来的。
🖼️ 图片理解测评
听说 Doubao-Seed-Code 是国内首个具备视觉理解能力的编程模型,我直接把我本次的草稿图直接给了他,看他理解的怎么样?
草稿图原图(其中有多个地名为干扰选项)
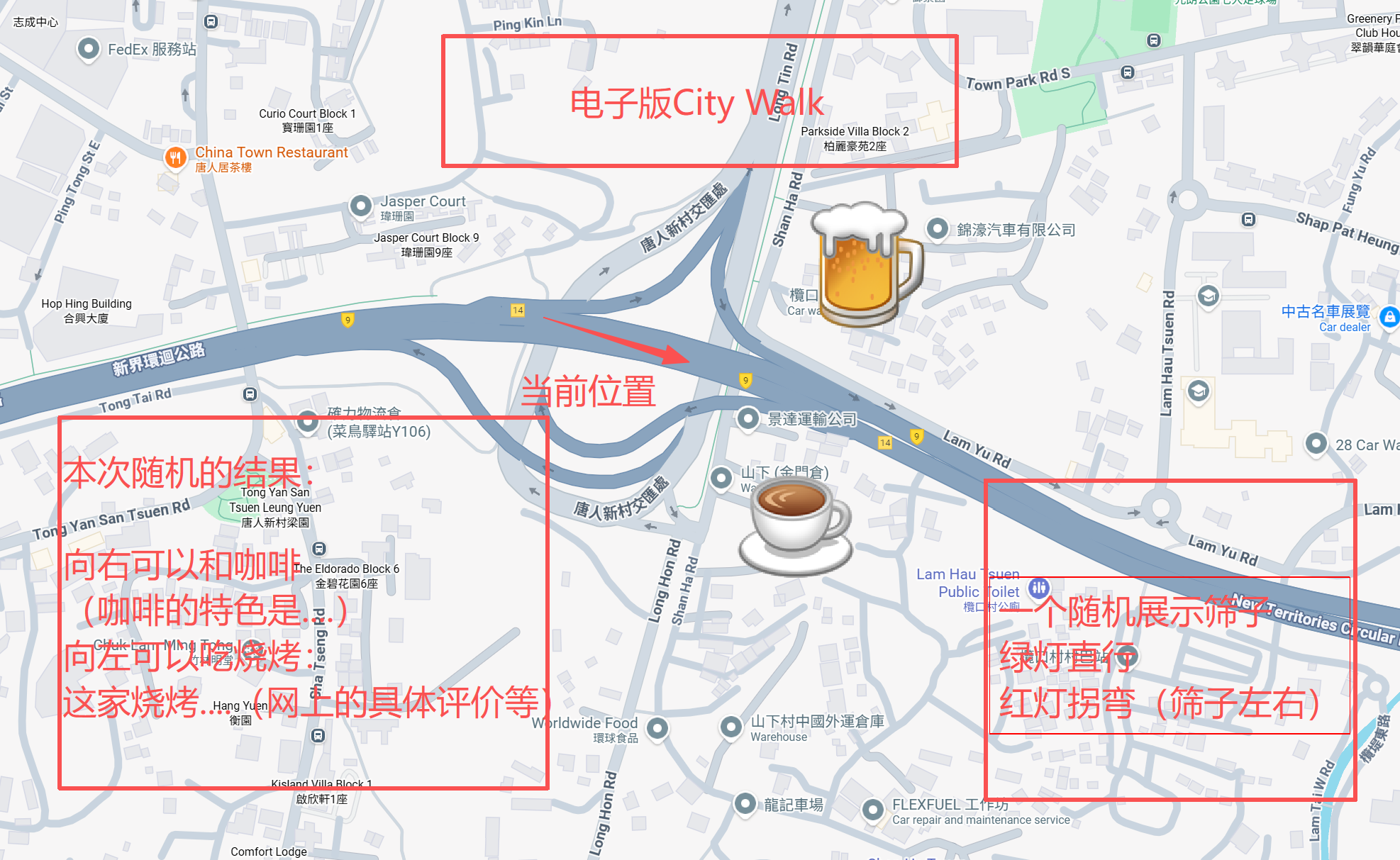
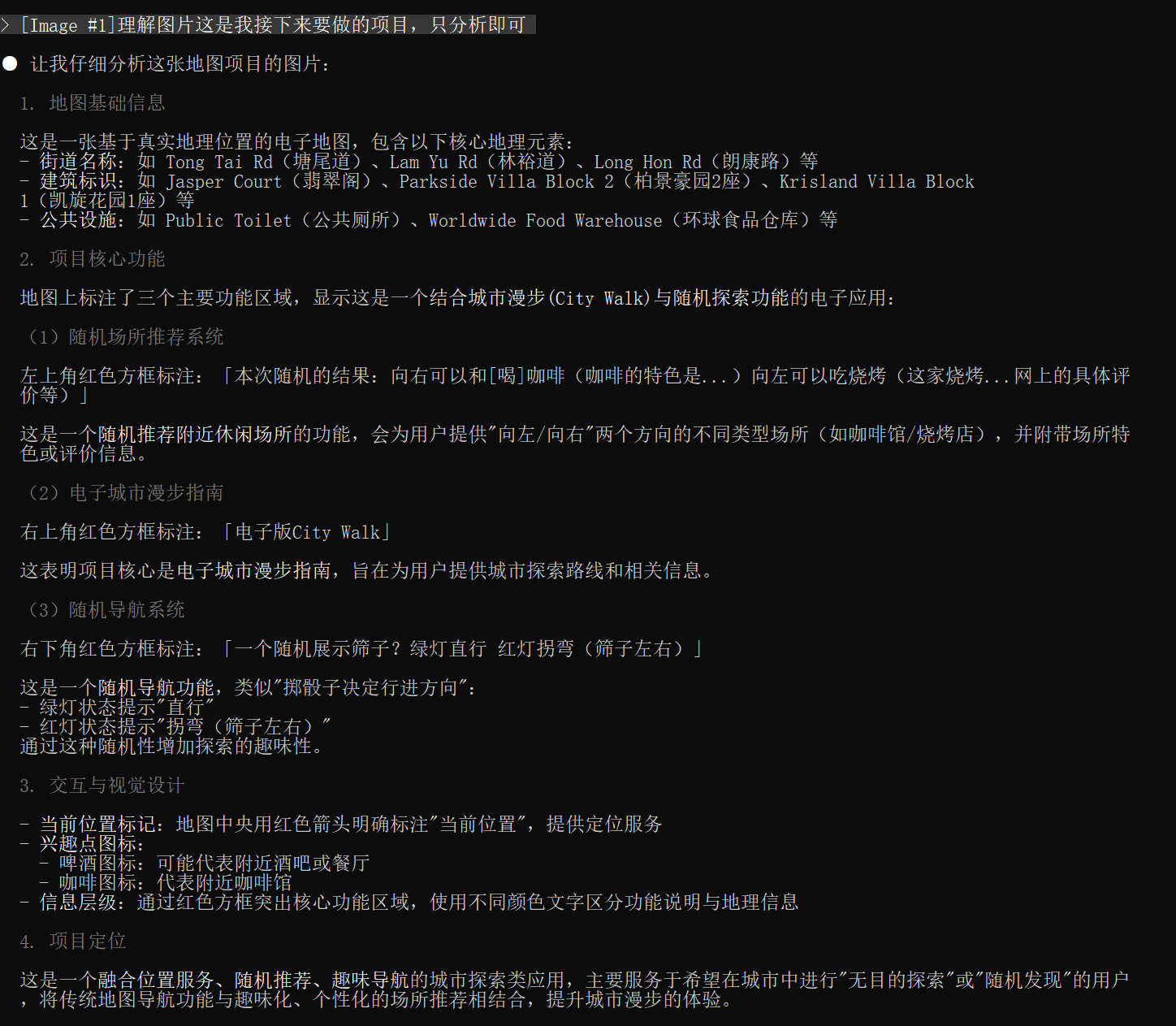
💡 不是“猜”出来的,是“看懂”了。
VLM训练需要专业团队和数据积累,有一定技术壁垒,doubao 系列模型一直以来视觉理解能力非常强,Seed-Code 模型保持了这个优势,在国内,要么模型不具备视觉理解能力,要么需要依赖MCP实现,将图片转化成语义描述供模型理解,过程中消耗token,效果远不及原生VLM能力,项目开发,只有真正的理解,才能大幅提升前端开发效率。
📌 实战 AI 开发
直接把下面的提示词扔给他
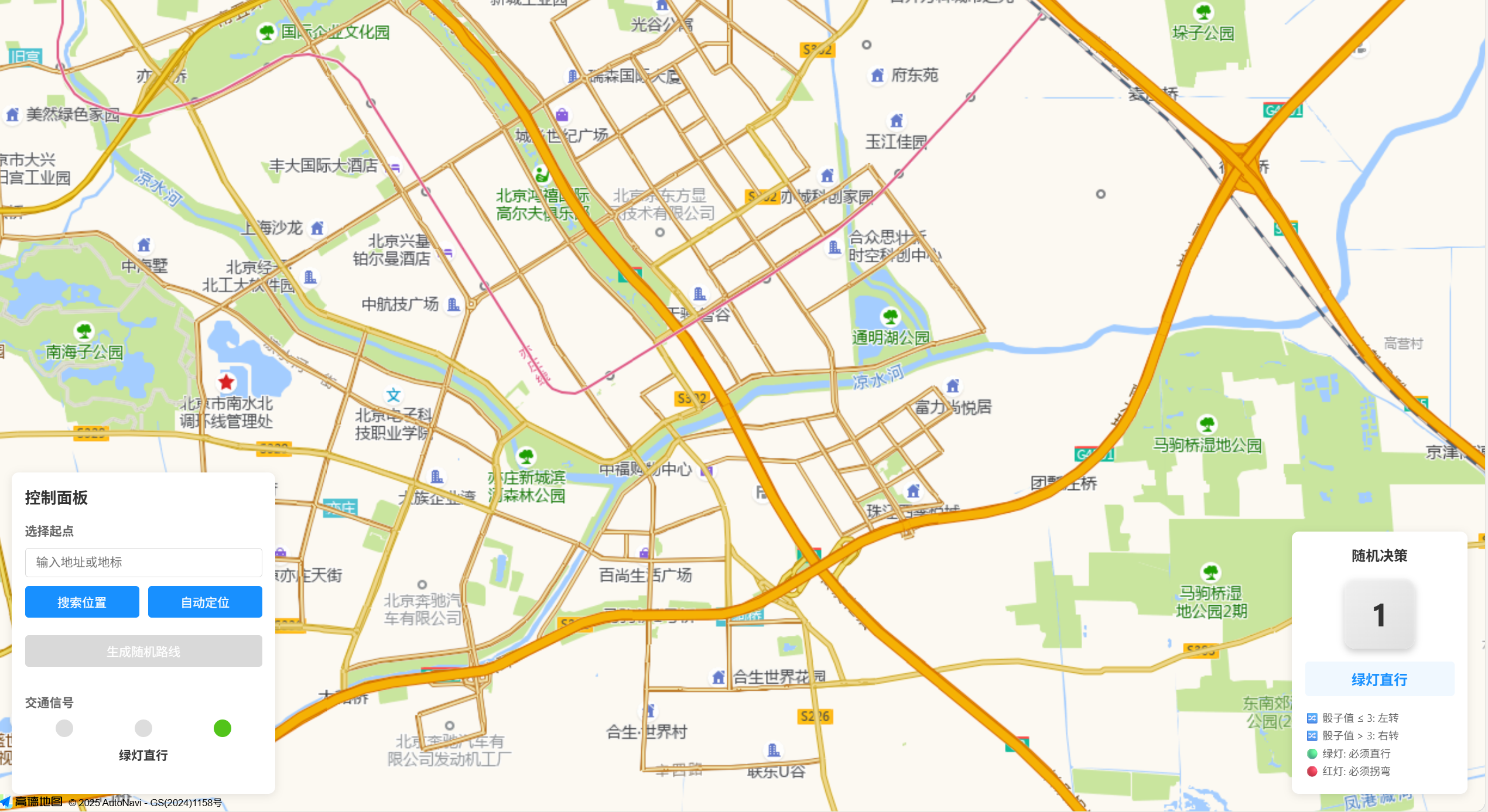
第一次生成的效果如下:
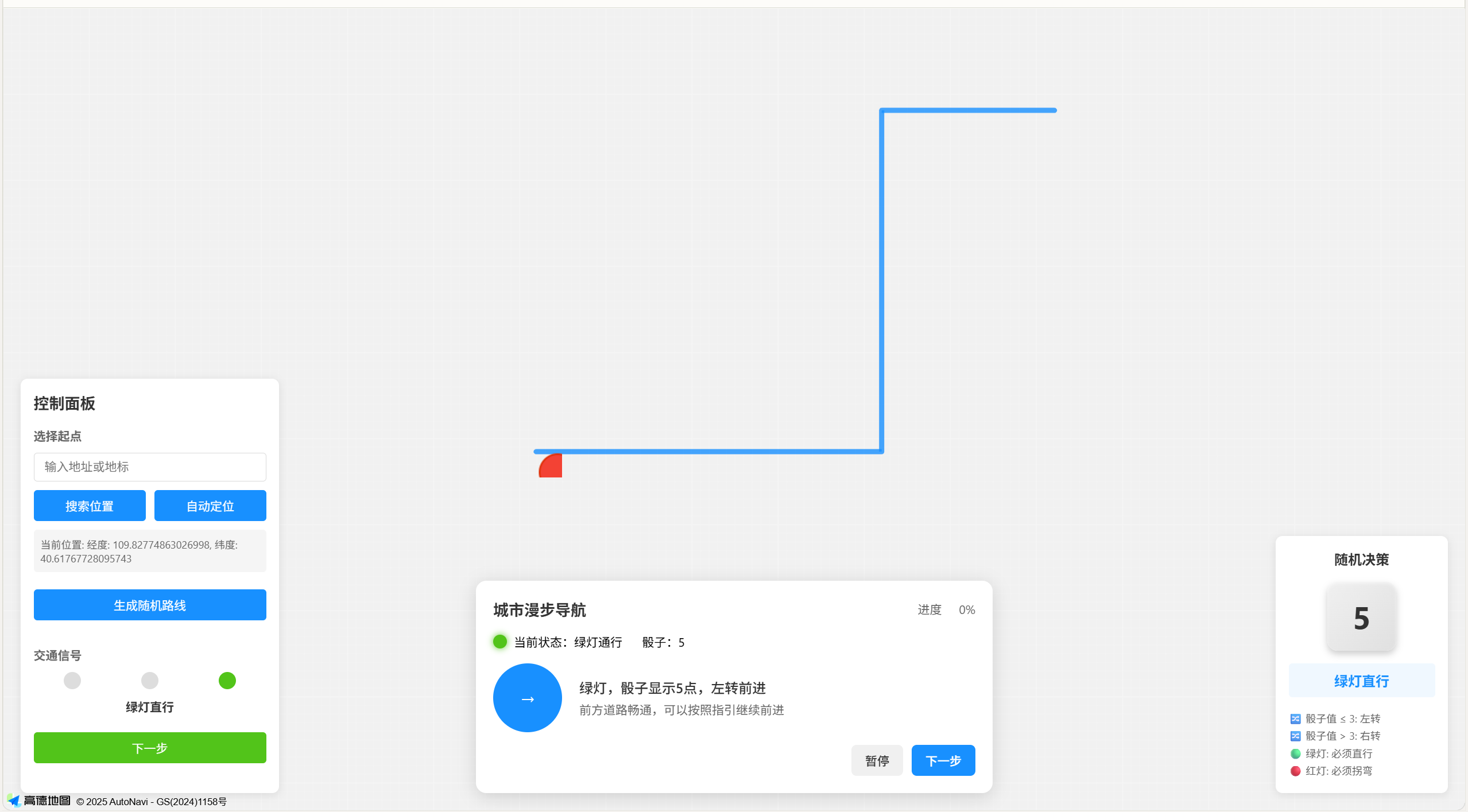
虽然没有具体使用高德,但是在这个的布局上和我的草稿没有什么区别。
迭代:多轮对话,越聊越准
为让效果更好,我们多尝试、跟模型多轮对话,效果好于一次性对话
接下来就是漫长的迭代~

第一次生成的版本,骰子是静态图片。我说:“让它能转起来,像真骰子一样。”
它立刻改成了CSS动画 + JS随机数控制。
我说:“咖啡馆的推荐文案太假了,要真实评价。”
它从网络抓取了真实用户对“北京胡同咖啡馆”的点评,自动生成了3条风格迥异的文案。
我说:“能不能加个‘暂停’按钮?”
它加了,还顺手做了个“进度条”和“已走距离”。
全程无代码干预,纯对话。
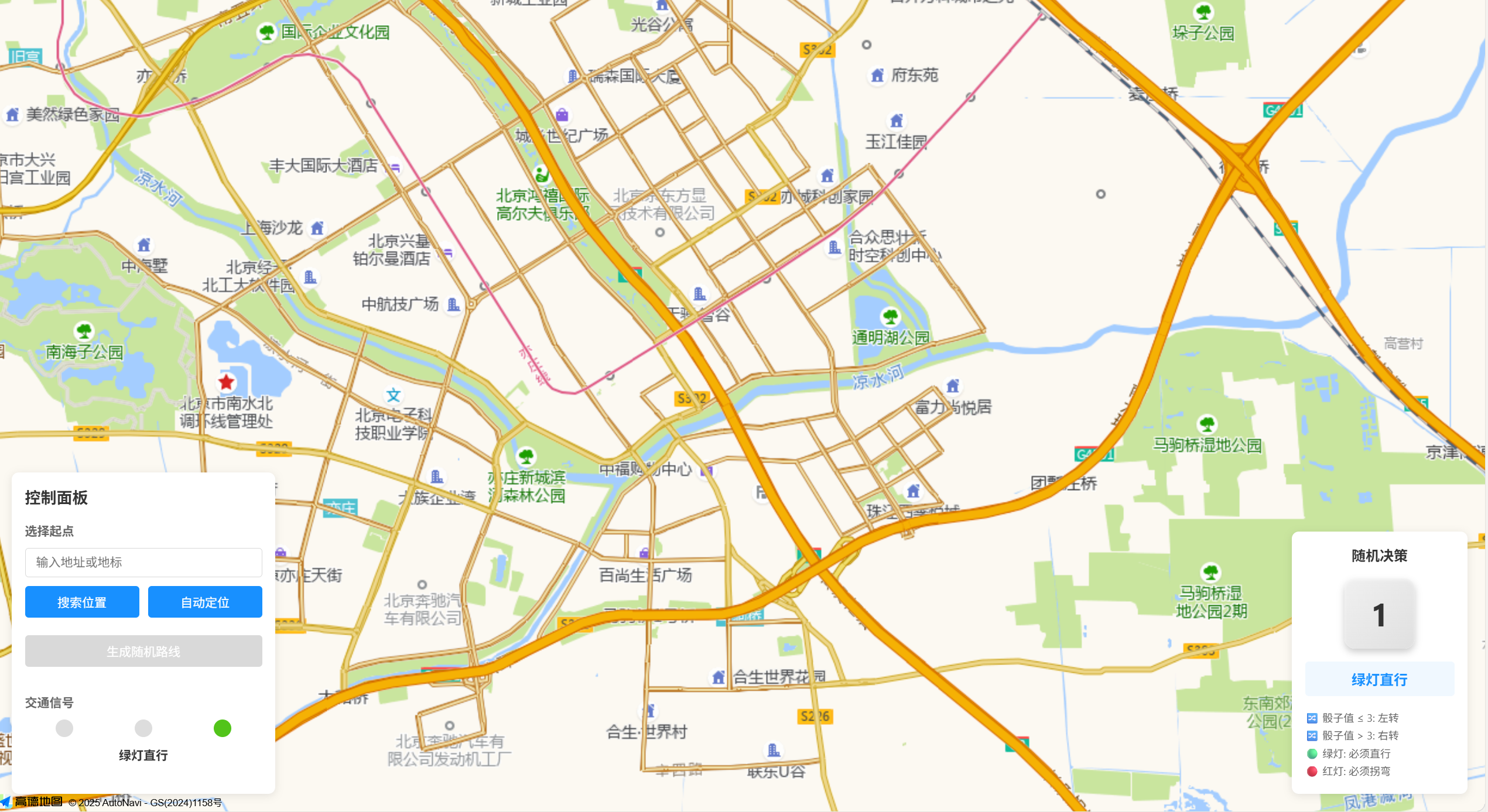
看看最终效果吧~
左侧为草稿图,右侧为使用 Doubao-Seed-Code 编程的效果。
下面是生成的README.md的文件,准确的识别了图片,以及分析图片所描述的功能等。
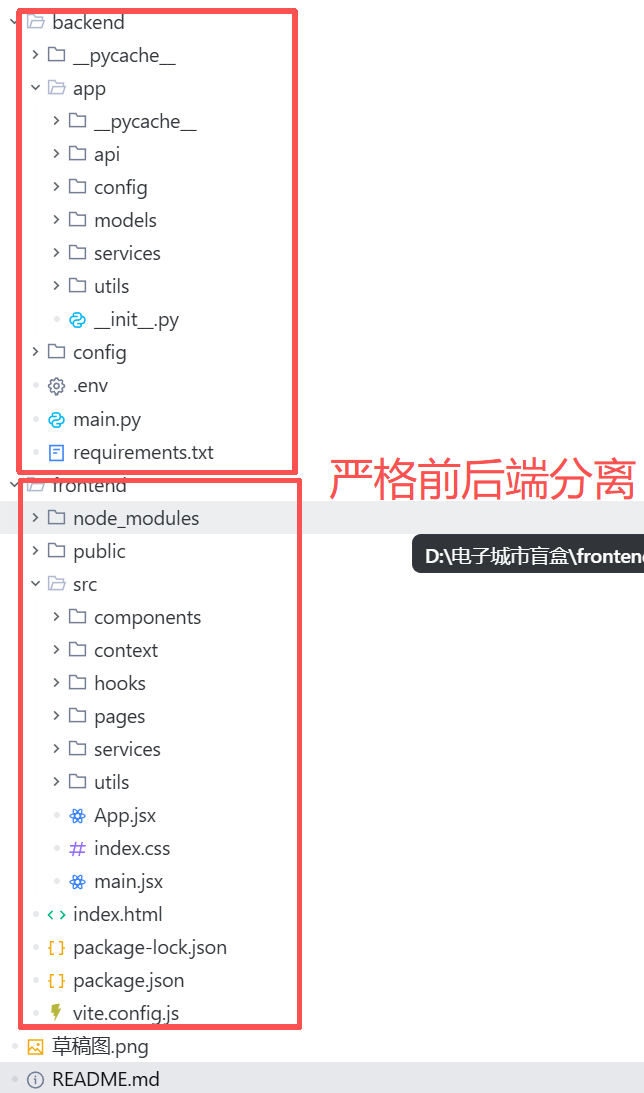
项目架构如下:
四.对比:为什么它赢了?
除了Doubao-Seed-Code,我用2个国外的模型进行了对比,做了相同任务:。
Doubao-Seed-Code生成的效果:
模型一:
仅简单的界面,其余功能都未实现。

模型二:
无法理解图片,仅生成了记得的前端,用的AI常用的紫色配色。
对比表如下:
模型 | 是否理解图片 | 是否生成完整项目 | 是否还原布局 | 成本(估算) |
Doubao-Seed-Code | ✅ 原生VLM,精准还原 | ✅ 前后端齐全,功能完整 | ✅ 100%还原草图 | ¥0.34(0-32K区间) |
模型一 | ❌ 仅靠文字描述 | ⚠️ 只生成前端UI,无后端逻辑 | ❌ 配色乱、布局错 | ¥4.05 |
模型二 | ❌ 无视图片 | ❌ 生成“标准模板”,紫色主题,无交互 | ❌ 完全跑偏 | ¥2.10 |
📌 Doubao-Seed-Code的输入价格:1.20元/百万Token,输出8.00元/百万Token
在相同任务下,成本不到Claude的1/10,且效果碾压。
五.总结:它不是工具,是“懂你”的伙伴
Doubao-Seed-Code 的革命性,不在于它“能写代码”,而在于它终于看懂了人类的意图。
过去,我们写需求文档,像给外星人写说明书:
“请在页面左上角放一个地图,右下角放一个按钮,点击后触发随机算法,返回3个兴趣点,用蓝色字体,字体大小16px,悬停有阴影……”
而今天,我们只需画一张草图,说一句:“帮我做出来。”
它知道:
- 哪里是按钮,哪里是地图;
- 哪里该有动画,哪里该有真实评价;
- 哪个“咖啡杯”不是装饰,而是故事的起点。
它不靠你“说清楚”,它靠你“画出来”。
这不是AI编程的进化,这是人机协作范式的跃迁。
“以前是人教AI怎么干活,现在是AI看懂人想干嘛。” —— 这才是真正的“原生智能”。
为什么这很重要?
- 降低技术门槛:设计师、产品经理、普通用户,都能直接“画出产品”。
- 提升创作效率:从“写5000字需求”到“画5分钟草图”,效率提升10倍。
- 释放创造力:不再被语法、框架、API文档束缚,专注“我想做什么”。
- 重塑开发流程:未来,产品经理画原型 → AI生成代码 → 测试上线,三步完成。
这不是未来,这是现在正在发生的现实。
我用9.9元,让AI替我走了一条从未走过的城市小巷。 我没有出门,但我“走”过了整座城。
当AI能读懂你的草图,它就不再是工具,而是你思维的延伸。
🌆 真正的City Walk,不是用脚走,而是用心看。 而现在,AI,替你看了。
