
【大数据分析 | 深度学习】Submarine(Hadoop生态系统)

前言
大数据和深度学习结合之路——在Hadoop上实现分布式深度学习(本质理解:搭好环境后可运行深度学习程序)
一、Submarine 介绍
Hadoop 是用于大型企业数据集的分布式处理的最流行的开源框架,它在本地和云端环境中都有很多重要用途。
深度学习对于语音识别,图像分类,AI 聊天机器人,机器翻译等领域的企业任务非常有用,仅举几例。为了训练深度学习/机器学习模型,可以利用 TensorFlow / MXNet / Pytorch / Caffe / XGBoost 等框架。有时需要将这些框架进行组合使用以用于解决不同的问题。
为了使分布式深度学习/机器学习应用程序易于启动,管理和监控,Hadoop 社区启动了 Submarine 项目以及其他改进,例如一流的 GPU 支持,Docker 容器支持,容器 DNS 支持,调度改进等。
这些改进使得在 Apache Hadoop YARN 上运行的分布式深度学习/机器学习应用程序就像在本地运行一样简单,这可以让机器学习工程师专注于算法,而不是担心底层基础架构。通过升级到最新的 Hadoop,用户现在可以在同一群集上运行其他 ETL / streaming 作业来运行深度学习工作负载。这样可以轻松访问同一群集上的数据,从而实现更好的资源利用率。
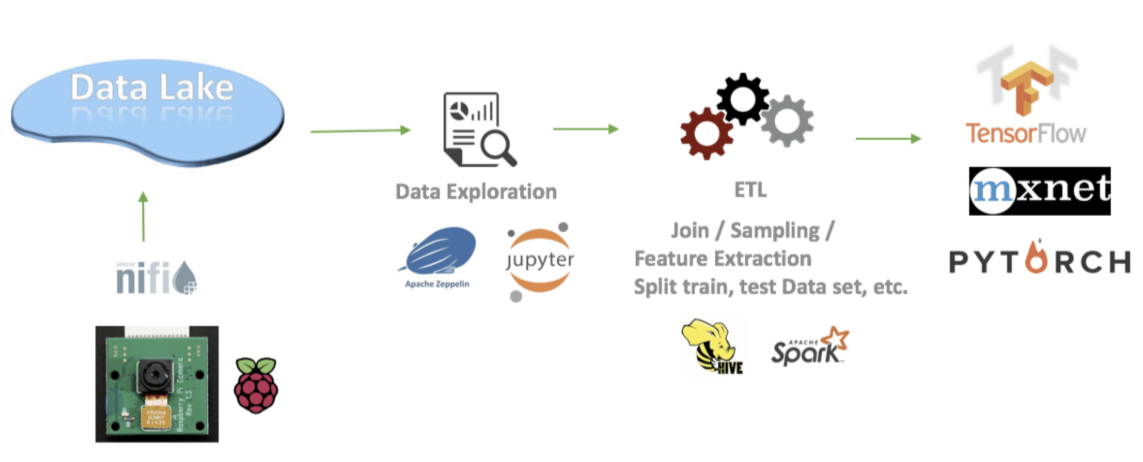 典型的深度学习工作流程:数据从各个终端(或其他来源)汇聚到数据湖中。数据科学家可以使用笔记本进行数据探索,创建 pipelines 来进行特征提取/分割训练/测试数据集。并开展深度学习和训练工作。这些过程可以重复进行。因此,在同一个集群上运行深度学习作业可以显著提高数据 / 计算资源共享的效率。
典型的深度学习工作流程:数据从各个终端(或其他来源)汇聚到数据湖中。数据科学家可以使用笔记本进行数据探索,创建 pipelines 来进行特征提取/分割训练/测试数据集。并开展深度学习和训练工作。这些过程可以重复进行。因此,在同一个集群上运行深度学习作业可以显著提高数据 / 计算资源共享的效率。
让我们仔细看看 Submarine 项目(它是 Apache Hadoop 项目的一部分),请看下如何在 Hadoop 上运行这些深度学习工作。
为什么叫 Submarine 这个名字? 因为潜艇是唯一可以将人类带到更深处的装置设备。
Submarine 项目包括两个部分:Submarine 计算引擎和一套 Submarine 生态系统集成插件/工具。
Submarine 计算引擎通过命令行向 YARN 提交定制的深度学习应用程序(如Tensorflow, Pytorch等)。这些应用程序与 YARN 上的其他应用程序并排运行,例如 Apache Spark,Hadoop Map/Reduce 等。
最重要的是,有一套海底生态系统集成,目前包括:
- Submarine-Zeppelin integration:允许数据科学家在 Zeppelin notebook 上编码,并直接从 notebook 上提交/管理培训工作。
- Submarine-Azkaban integration:允许数据科学家从 notebooks 直接向 Azkaban 提交一组具有依赖关系的任务。
- Submarine-installer:在您的环境中安装 Submarine 和 YARN,以便更容易地尝试强大的工具集。
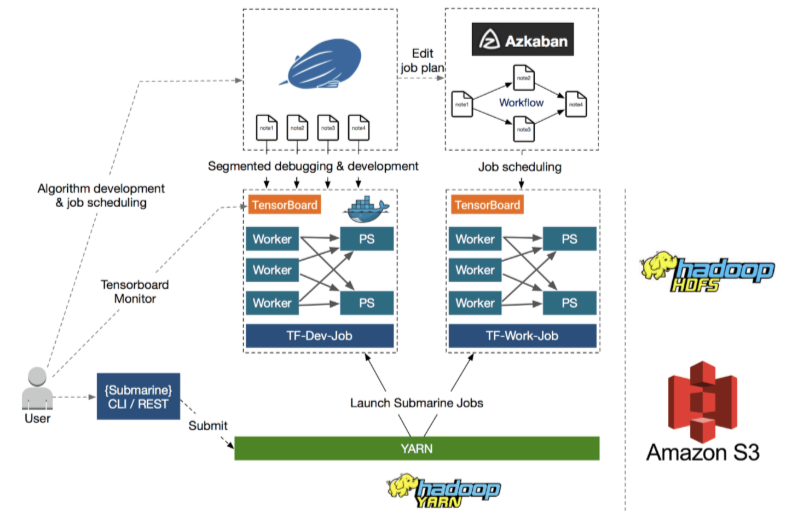 Submarine 示意图,底部显示 Submarine 计算引擎,它只是另一个 YARN 应用程序。在计算引擎之上,它集成了其他生态系统,如 notebook (Zeppelin/Jupyter) 和 Azkaban。
Submarine 示意图,底部显示 Submarine 计算引擎,它只是另一个 YARN 应用程序。在计算引擎之上,它集成了其他生态系统,如 notebook (Zeppelin/Jupyter) 和 Azkaban。
二、中文演讲介绍
APACHE SUBMARINE 云原生机器学习平台 刘勋 KEVIN SU 中文演讲 2022-07-29 14:00 GMT+8 #AI
Apache Submarine 是一个可以进行机器学习全流程处理的一站式工作平台,它以云原生的方式运行在 Kubernetes 和 Cloud 之上。Submarine 提供了完善的平台部署和 Tensorflow、Pytorch 等机器学习框架的 YAML 文件和 Docker 镜像,这让整个系统的部署和使用都变的非常简单,您只需运行一条 Heml 命令就可以将 Submarine 机器学习平台运行在 Kubernetes 或 Cloud 之上,Submarine 提供支持多用户操作的 Workbench,数据科学家和算法工程师通过浏览器就可以完成数据加工、算法开发、作业调度、模型训练以及模型 Serving 的所有工作。Submarine 提供了标准的 Tensorflow、Pytorch、Python 和 XGBoost 等机器学习框架 Docker 镜像,您还可以自己进行定制和扩展,通过 Docker 为机器学习作业提供了完全隔离的运行环境,借助 Kubernetes 和 Cloud 的资源管控能力,Submarine 支持大量机器学习作业的调度运行。
Speakers: 刘勋:滴滴,高级技术专家,Apache Member、Apache 孵化器导师、Apache Submarine PMC Chair、Apache Hadoop & Zeppelin Committer kevin Su:Union.ai 软件研发工程师,Apache Submarine Committer & PMC,LFAI 开源项目 Flyte Maintainer & Committer
三、Submarine 属于 Hadoop 生态系统
Apache Hadoop 官网地址:https://hadoop.apache.org/

 Submarine: A unified AI platform which allows engineers and data scientists to run Machine Learning and Deep Learning workload in distributed cluster.
Submarine: A unified AI platform which allows engineers and data scientists to run Machine Learning and Deep Learning workload in distributed cluster.
Submarine:一个统一的人工智能平台,允许工程师和数据科学家在分布式集群中运行机器学习和深度学习工作负载。
四、Submarine 官网版本演进
Submarine 官网地址:https://submarine.apache.org/versions/
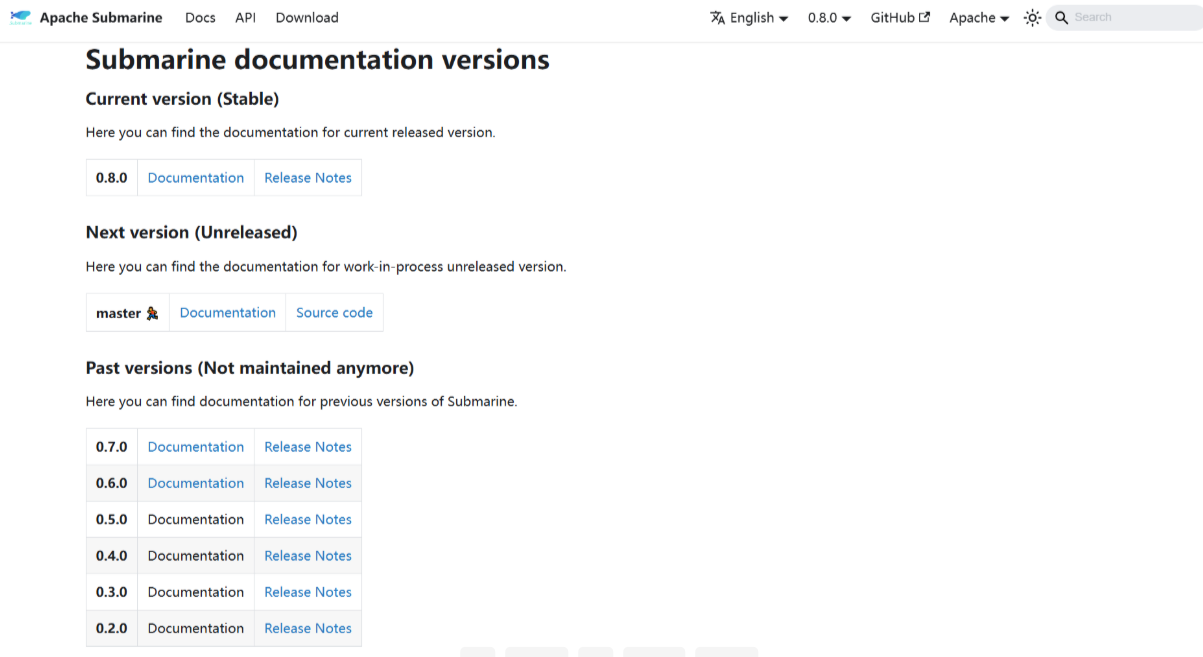 1. 最新版 0.8.0
1. 最新版 0.8.0
This document gives you a quick view on the basic usage of Submarine platform. You can finish each step of ML model lifecycle on the platform without messing up with the troublesome environment problems.
本文档让您快速了解 Submarine 平台的基本用法。您可以在平台上完成 ML 模型生命周期的每一步,而不会遇到麻烦的环境问题。
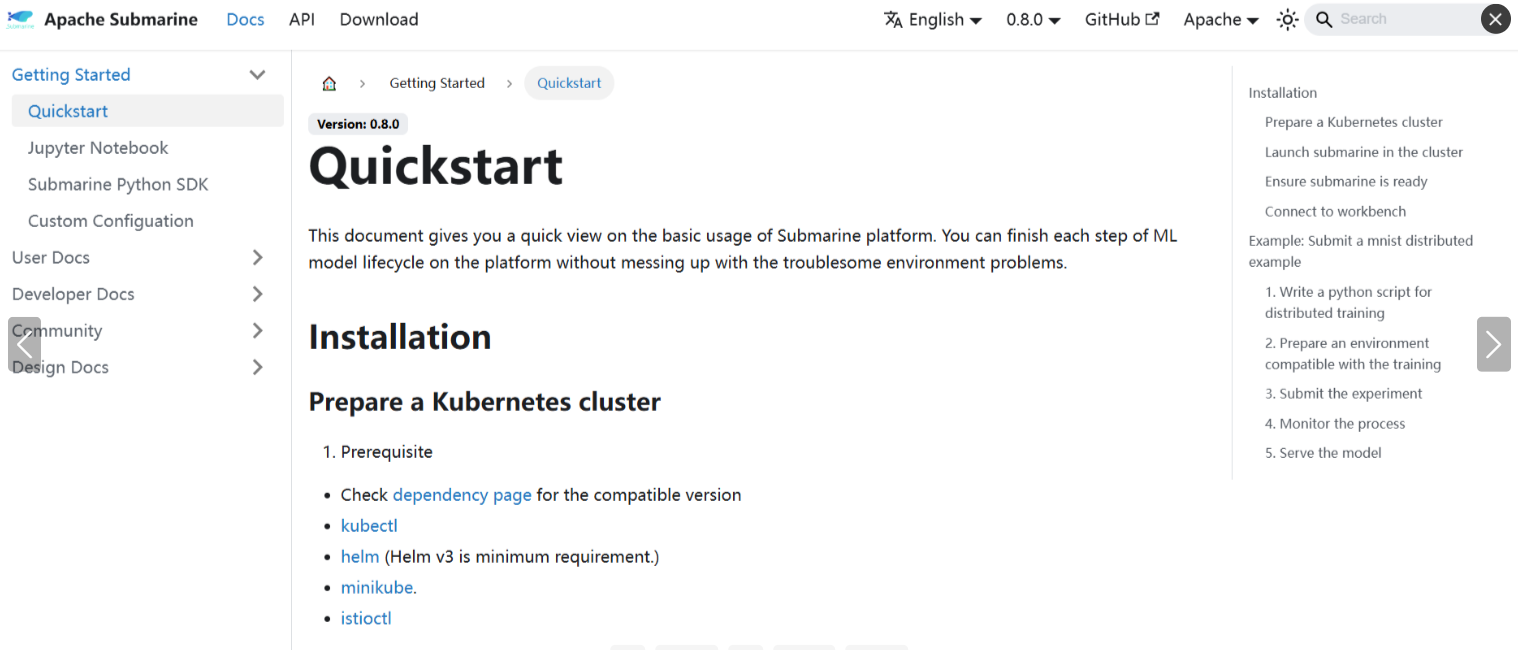 

2. 版本 0.6.0
https://submarine.apache.org/docs/0.6.0/userDocs/yarn/YARNRuntimeGuide/
不论是通过 Sumarine 还是通过单独的 Tony 本身,本质上都是支持两种模式来支持在 Yarn 上实现分布式深度学习: (1)无需 Docker 容器,需要带 TensorFlow 的 Python 虚拟环境等支持; (2)通过配置 Docker 容器(Docker 镜像)支持的 Hadoop 集群。
对于所需的基础镜像 Ubuntu 18.04, 可以直接从 Docker Hub 下载:https://hub.docker.com/_/ubuntu/tags
