前言
关联规则可以挖掘出物品间的关联关系,物品间的关联性越强推荐给用户时越可能受用户喜欢,提取关联规则的最大困难在于当存在很多商品时,可能的商品的组合(规则的前项与后项)的数目会达到一种令人望而却步的程度。
因此,各种关联规则分析的算法会从不同方面入手减小可能的搜索空间的大小以及减小扫描数据的次数。目前常见的关联规则算法有:Apriori和FP-Growth。
一、关联规则和频繁项集
2. 最小支持度和最小置信度
最小支持度是用户或专家定义的衡量支持度的一个阈值,表示项目集在统计意义上的最低重要性。 最小置信度是用户或专家定义的衡量置信度的一个阈值,表示关联规则的最低可靠性。 同时满足最小支持度阈值和最小置信度阈值的规则被称作强规则。
3. 项集
项集是项的集合。包含k个项的项集称为k项集,如集合{牛奶,麦片,糖}是一个3项集。 项集的出现频数是所有包含项集的事务计数,又被称作绝对支持度或支持度计数。 如果项集$I$的相对支持度满足预定义的最小支持度阈值,则I是频繁项集。频繁k项集通常记作L_k。
二、Apriori算法
Apriori算法的主要思想是找出存在于事务数据集中的最大的频繁项集,再利用得到的最大频繁项集与预先设定的最小置信度阈值生成强关联规则。
2. 使用Apriori算法实现餐饮菜品关联分析
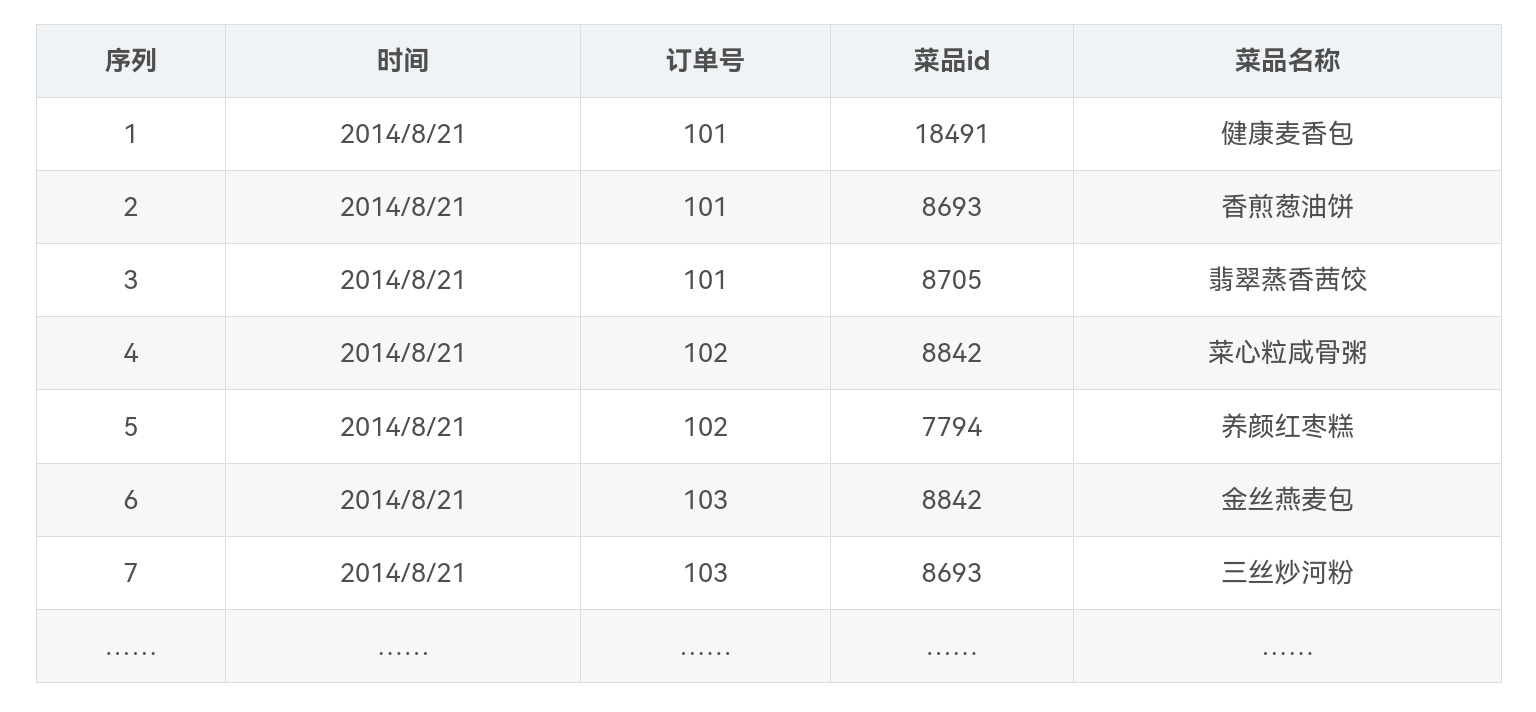
结合餐饮行业的实例讲解Apriori关联规则算法挖掘的实现过程。数据库中部分点餐数据如表所示。
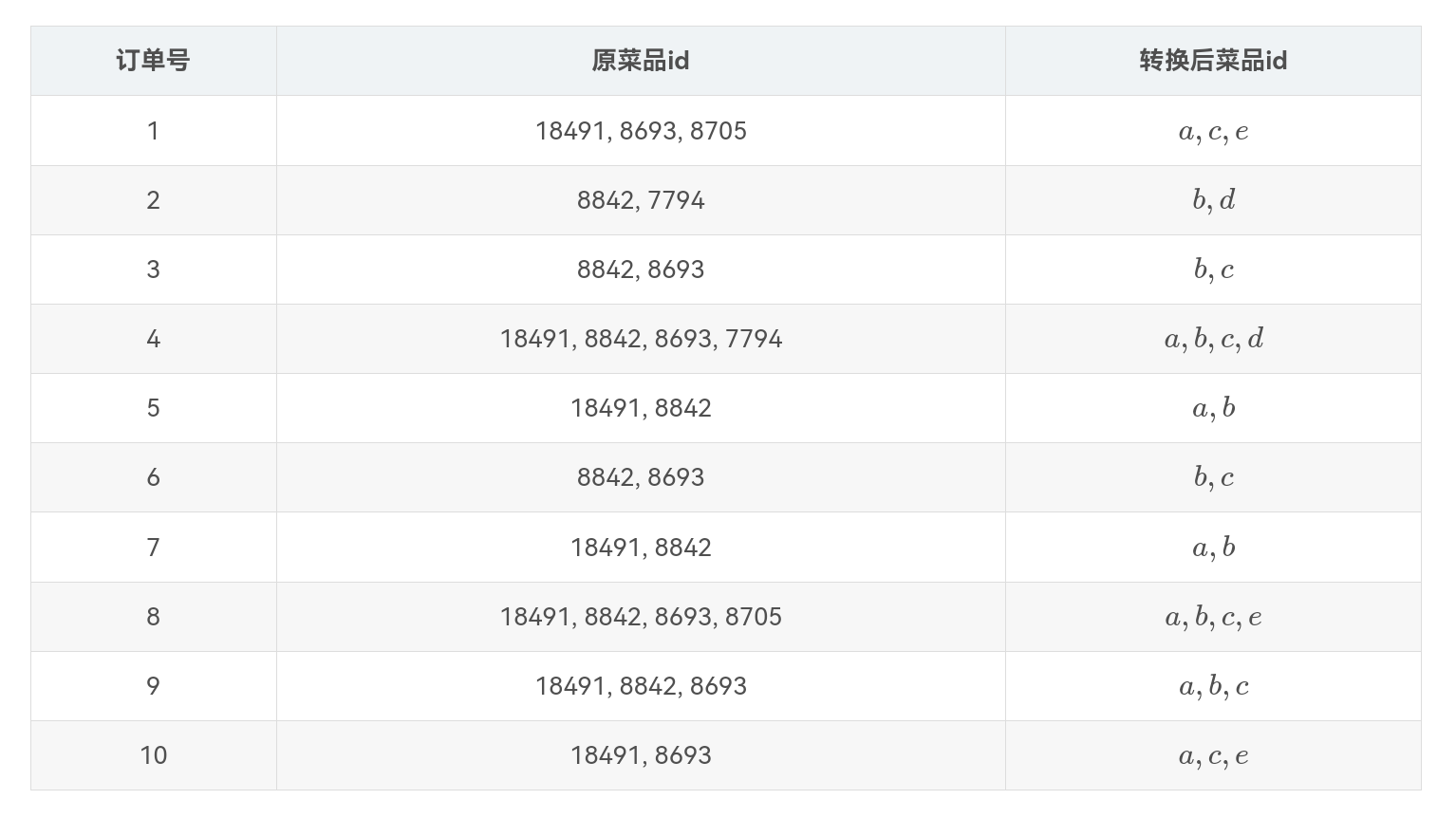
首先将上表中的事务数据(一种特殊类型的记录数据)整理成关联规则模型所需的数据结构,从中抽取10个点餐订单作为事务数据集,设支持度为0.2(支持度计数为2),为方便起见将菜品{18491,8842,8693,7794,8705}分别简记为{a,b,c,d,e},如表所示。
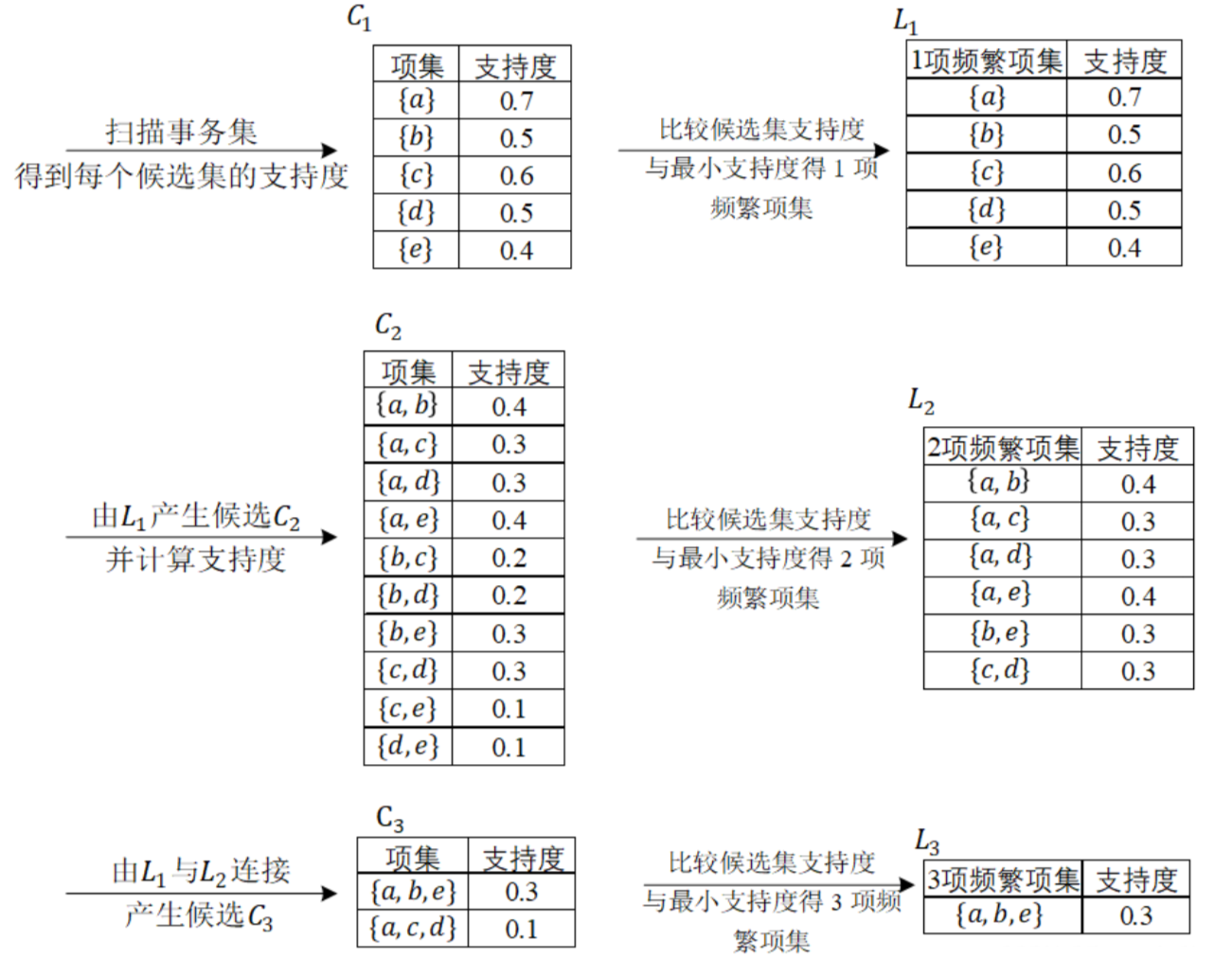
算法过程如图所示。
(2)过程二:由频繁集产生关联规则
自定义包apriori.py代码如下:
Plain Bash C++ C# CSS Diff HTML/XML Java Javascript Markdown PHP Python Ruby SQL
import numpy as np
import pandas as pd
def connect_string (x, ms ):
x = list (map (lambda i:sorted (i.split(ms)), x))
l = len (x[0 ])
r = []
for i in range (len (x)):
for j in range (i,len (x)):
if x[i][:l-1 ] == x[j][:l-1 ] and x[i][l-1 ] != x[j][l-1 ]:
r.append(x[i][:l-1 ]+sorted ([x[j][l-1 ],x[i][l-1 ]]))
return r
def find_rule (d, support, confidence, ms = u'--' ):
result = pd.DataFrame(index=['support' , 'confidence' ])
support_series = 1.0 *d.sum ()/len (d)
column = list (support_series[support_series > support].index)
k = 0
while len (column) > 1 :
k = k+1
print (u'\n正在进行第%s次搜索...' %k)
column = connect_string(column, ms)
print (u'数目:%s...' %len (column))
sf = lambda i: d[i].prod(axis=1 , numeric_only = True )
d_2 = pd.DataFrame(list (map (sf,column)), index = [ms.join(i) for i in column]).T
support_series_2 = 1.0 *d_2[[ms.join(i) for i in column]].sum ()/len (d)
column = list (support_series_2[support_series_2 > support].index)
support_series = support_series.append(support_series_2)
column2 = []
for i in column:
i = i.split(ms)
for j in range (len (i)):
column2.append(i[:j]+i[j+1 :]+i[j:j+1 ])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2])
for i in column2:
cofidence_series[ms.join(i)] = support_series[ms.join(sorted (i))]/support_series[ms.join(i[:len (i)-1 ])]
for i in cofidence_series[cofidence_series > confidence].index:
result[i] = 0.0
result[i]['confidence' ] = cofidence_series[i]
result[i]['support' ] = support_series[ms.join(sorted (i.split(ms)))]
result = result.T.sort_values(['confidence' ,'support' ], ascending = False )
print (u'\n结果为:' )
print (result)
return result
尝试基于该例产生关联规则,在Python中实现上述Apriori算法的代码, 结果如图所示。
Plain Bash C++ C# CSS Diff HTML/XML Java Javascript Markdown PHP Python Ruby SQL import pandas as pd
from apriori import *
data = pd.read_excel('../data/menu_orders.xls' , header=None )
data.head()
Plain Bash C++ C# CSS Diff HTML/XML Java Javascript Markdown PHP Python Ruby SQL print ('\n转换原始数据至0-1矩阵...' )
ct = lambda x: pd.Series(1 , index=x[pd.notnull(x)])
b = map (ct, data.to_numpy())
data = pd.DataFrame(list (b)).fillna(0 )
print ('\n转换完毕' )
Plain Bash C++ C# CSS Diff HTML/XML Java Javascript Markdown PHP Python Ruby SQL data.head()
Plain Bash C++ C# CSS Diff HTML/XML Java Javascript Markdown PHP Python Ruby SQL support = 0.2
confidence = 0.5
ms = '---'
find_rule(data, support, confidence, ms).to_excel('../tmp/outputfile.xls' , encoding='utf-8' )
针对图中第一条输出结果进行解释:客户同时点菜品e和a的概率是30%,点了菜品e,再点菜品a的概率是100%。知道了这些,就可以对顾客进行智能推荐,增加销量的同时满足客户需求。
三、FP-Growth算法
FP-Growth算法不同于Apriori算法生成候选项集再检查是否频繁的“产生-测试”方法,而是使用一种称为频繁模式树(FP-Tree,FP代表频繁模式,Frequent Pattern)的菜单紧凑数据结构组织数据,并直接从该结构中提取频繁项集。
1. FP-Growth算法的基本过程
相比于Apriori对每个潜在的频繁项集都需要扫描数据集判定是否满足支持度,FP-Growth算法只需要遍历两次数据集,因此它在大数据集上的速度显著优于Apriori。FP-Growth算法的基本运作步骤如下。 ① 扫描数据,得到所有1项频繁一项集的计数。然后删除支持度低于阈值的项,将1项频繁项集放入项头表,并按照支持度降序排列。 ② 读入排序后的数据集,插入FP树,插入时将项集按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表连接新节点。直到所有的数据都插入到FP树后,FP树的建立完成。 ③ 从项头表的底部项依次向上找到项头表项对应的条件模式基。从条件模式基递归挖掘得到项头表项的频繁项集。 ④ 如果不限制频繁项集的项数,则返回步骤3所有的频繁项集,否则只返回满足项数要求的频繁项集。
2. FP-Growth算法原理
FP-Growth算法主要包含3个部分:扫描数据集建立项头表、基于项头表建立FP-tree和基于FP-tree挖掘频繁项集。
(1)建立项头表
要建立FP-tree首先需要建立项头表,建立项头表需要先对数据集进行一次扫描,得到所有1项频繁一项集的计数,将低于设定的支持度阈值的项过滤掉后,将1项频繁集放入项头表并按照项集的支持度进行降序排序。之后对数据集进行第二次扫描,从原始数据中剔除1项非频繁项集,并按照项集的支持度降序排序。
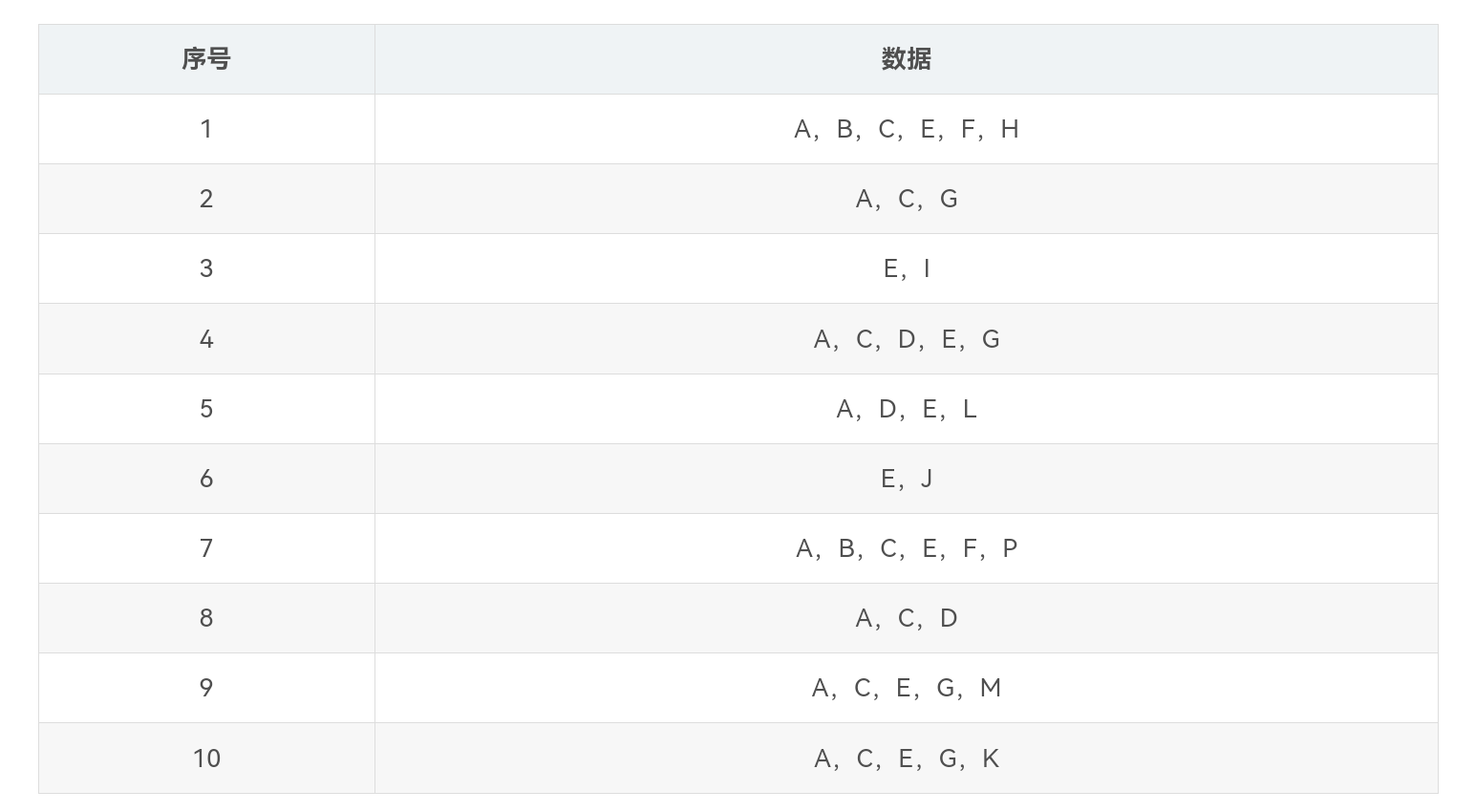
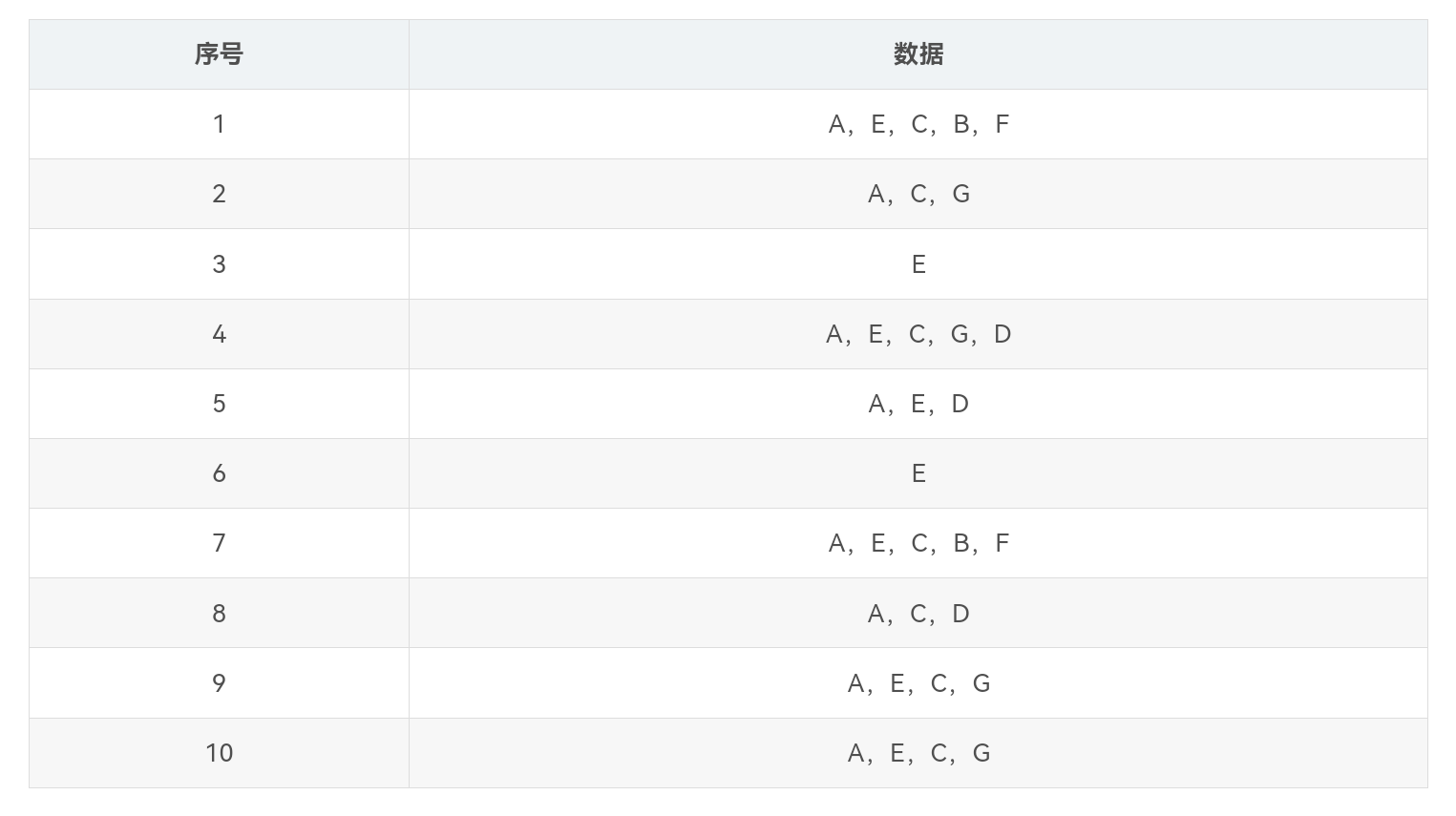
以一个含有10条数据的数据集为例,数据集中的数据如表所示。
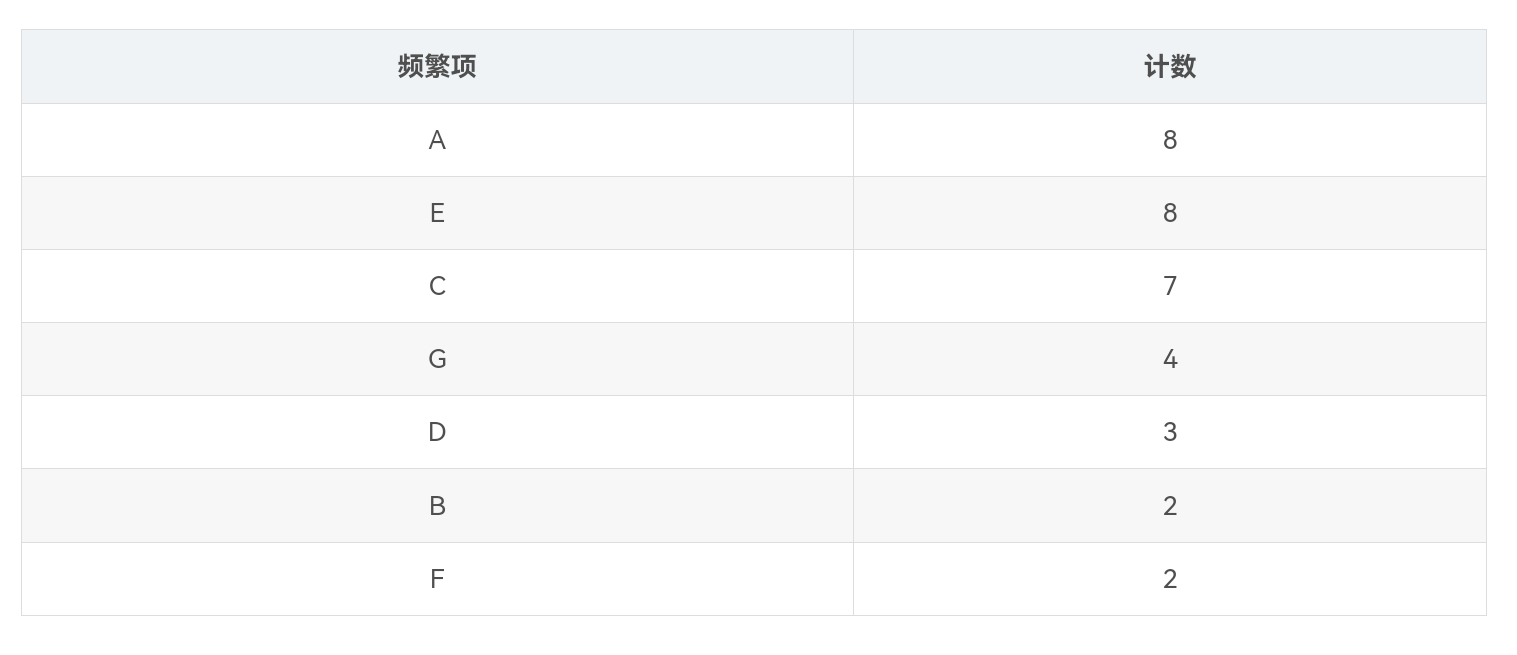
对数据集进行扫描,支持度阈值设为20%,由于H,I,L,J,K,P,M都仅出现一次,小于设定的20%的支持度阈值,因此将不进入项头表。将1项频繁项集按降序排序后构建的项头表如表所示。
第二次扫描数据,将每条数据中的1项非频繁项集删去,并按照项集的支持度降序排列。如数据项“A,B,C,E,F,H”,其中“H“为1项非频繁项集,剔除后按项集的支持度降序排列后的数据项为“A,E,C,B,F”,得到排序后的数据集如表所示。
(2)建立FP-tree
构建项头表并对数据集排序后,就可以开始建立FP-tree。建立FP-tree时按顺序读入排序后的数据集,插入FP-tree中时按照排序的顺序插入,排序最为靠前的是父节点,之后的是子孙节点。如果出现共同的父节点,则对应父节点的计数增加1次。插入时如果有新节点加入树中,则将项头表中对应的节点通过节点链表链接接上新节点。直至所有的数据项都插入FP-tree后,FP-tree完成建立过程。
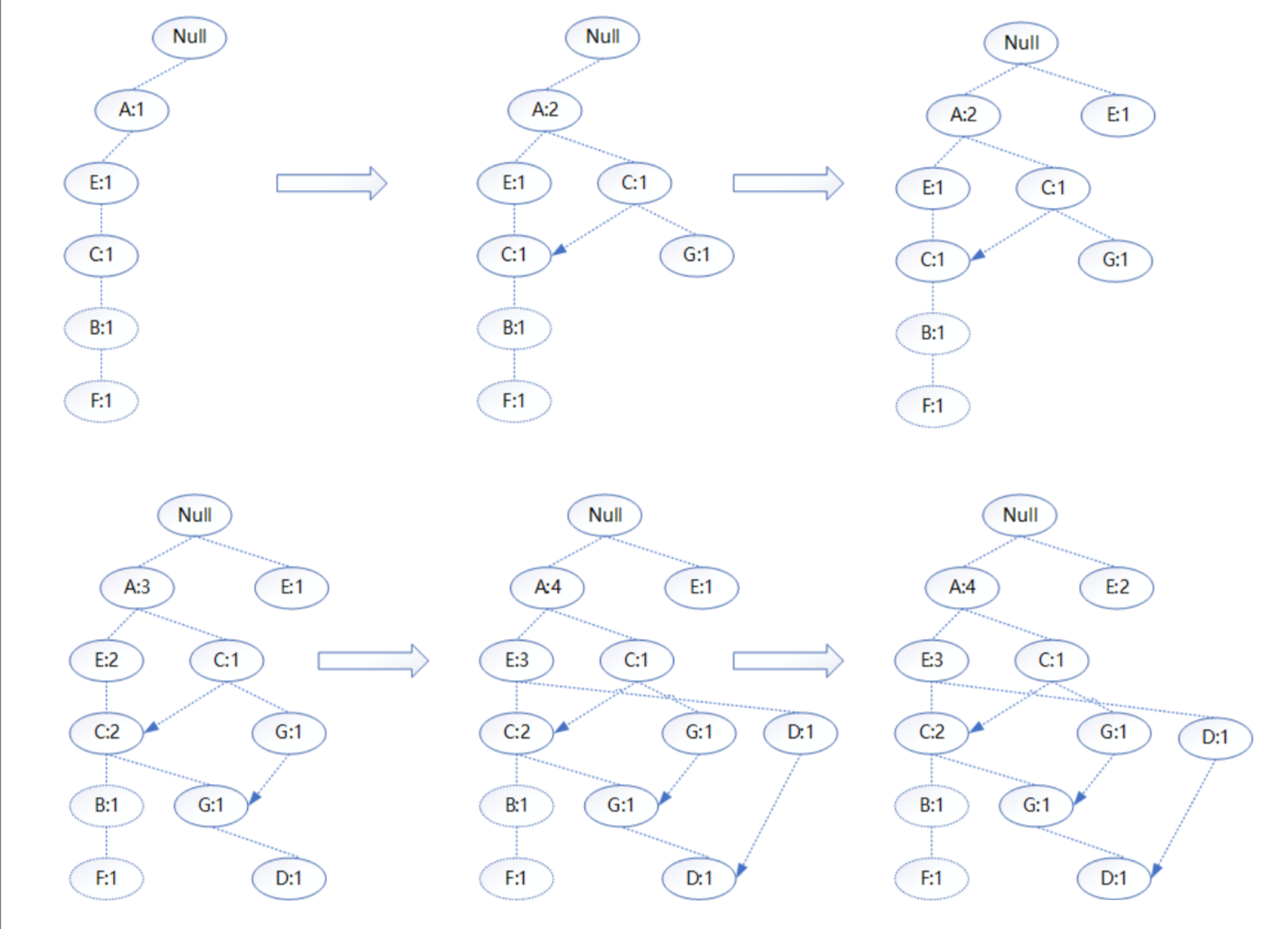
以建立项头表的数据集为例,构建FP-tree的过程如图所示。
构建FP-tree具体步骤如下。
读入第一条数据“A,E,C,B,F”,此时FP-tree中没有节点,按顺序构成一条完整路径,每个节点的计数为1。
读入第二条数据“A,C,G”,在A节点处延伸一条新路径,并且A节点计数加1,其余节点计数为1。
读入第三条数据“E”,从根节点位置延伸一条新路径,计数为1。
读入第四条数据“A,E,C,G,D”,在C节点处延伸一条新路径,共用的“A,E,C”计数加1,新建的节点计数为1。
重复以上步骤直至整个FP-tree构建完成。
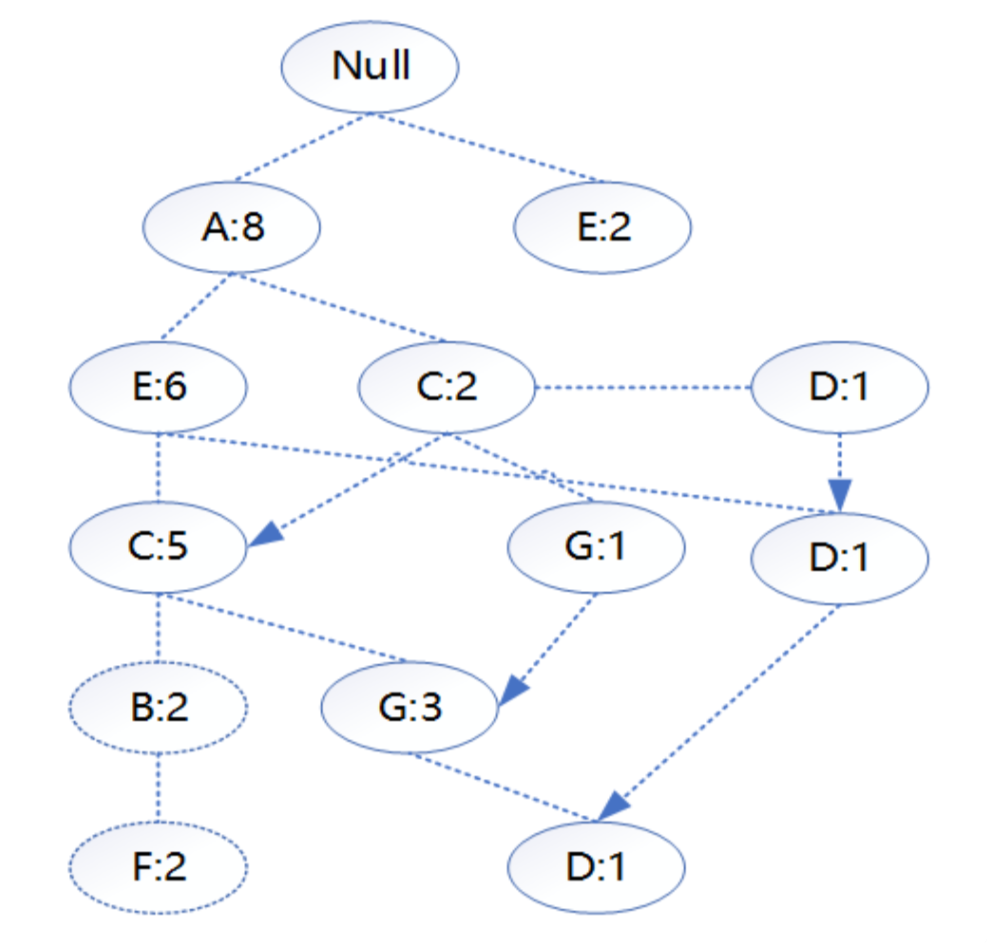
最终得到的FP-tree如图所示。
(3)挖掘频繁项集
在构建FP-tree、项头表和节点链表后,需要从项头表的底部项依次向上挖掘频繁项集。这需要找到项头表中对应于FP-tree的每一项的条件模式基。条件模式基是以要挖掘的节点作为叶子节点所对应的FP子树。
得到该FP子树后,将子树中每个节点的计数设置为叶子节点的计数,并删除计数低于最小支持度的节点。基于这个条件模式基就可以递归挖掘得到频繁项集了。
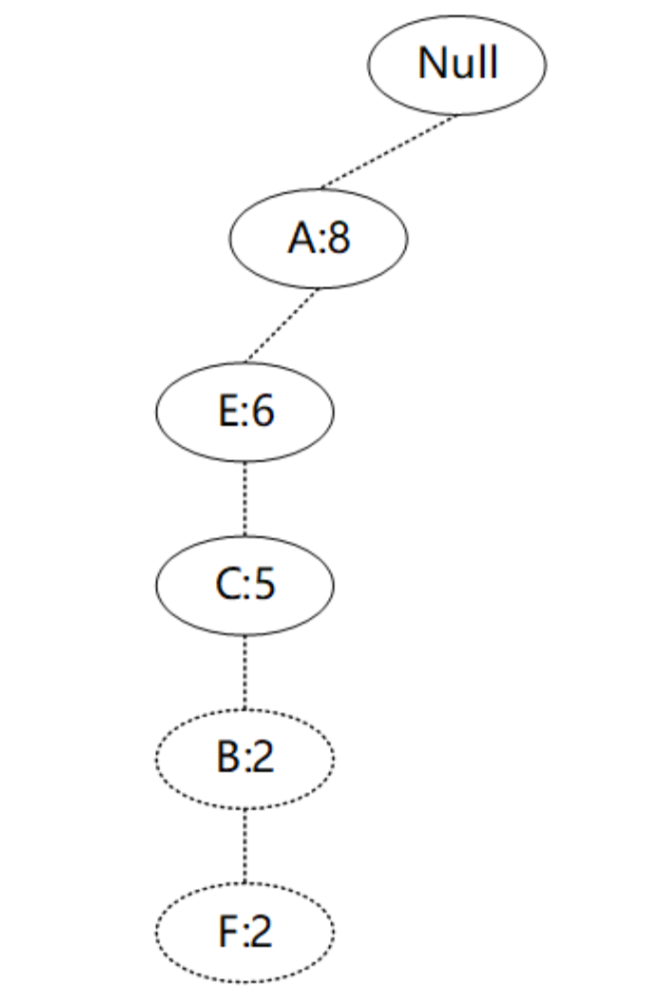
以构建F节点的条件模式基为例,F节点在FP-tree中只有一个子节点,因此只有一条路径{A:8,E:6,C:5,B:2,F:2},得到F节点的FP子树如图所示。
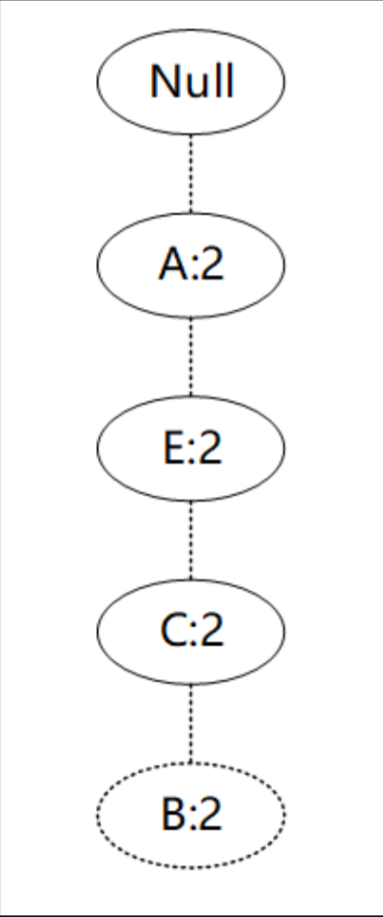
接着将所有的父节点的计数设置为子节点的计数,即FP子树变成{A:2,E:2,C:2,B:2,F:2}。通常条件模式基可以不写子节点,如图所示。
通过F节点的条件模式基可以得到F的频繁2项集为{A:2,F:2}、{E:2,F:2}、{C:2,F:2}、{B:2,F:2}。将2项集递归合并得到频繁3项集为{A:2,C:2,F:2}、{A:2,E:2,F:2}等等。最终递归得到最大的频繁项集为频繁5项集{A:2, E:2,C:2, B:2,F:2}。
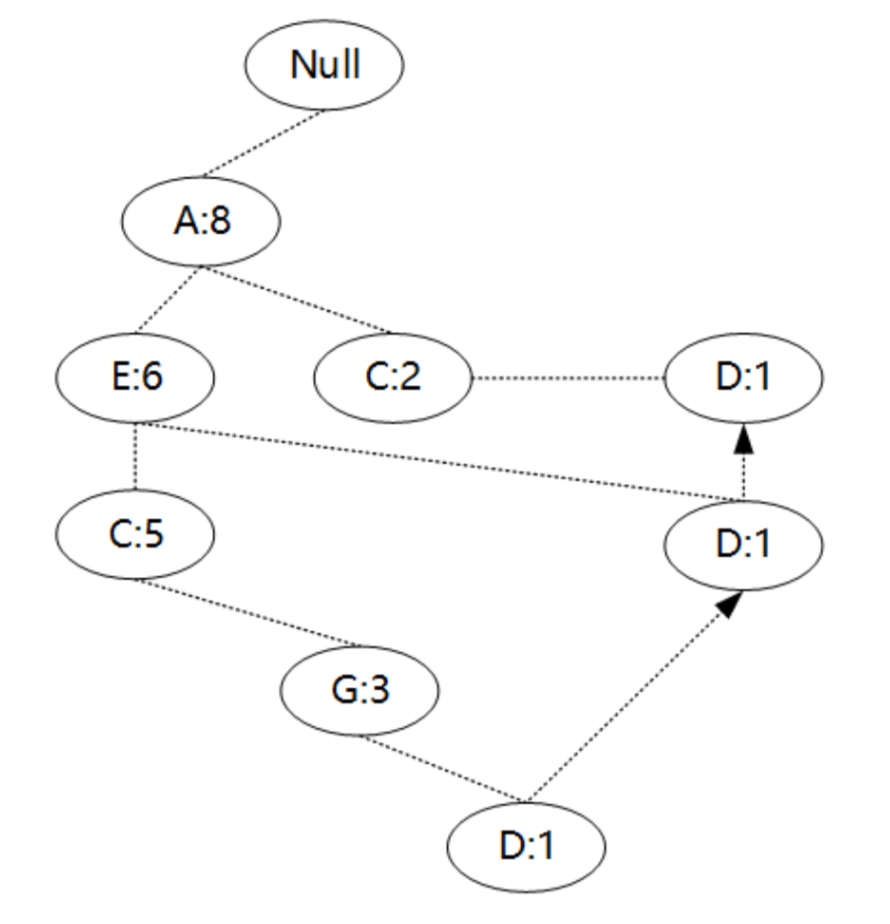
获取B节点的频繁项集的过程与F节点类似,此处不再列出,需要特别提一下D节点。D节点在树中有三个子节点,得到D节点的FP子树如图所示。
接着将所有的父节点计数设置为子节点的计数,即变成{A:3,E:2,C:2,G:1,D:1,D:1,D:1},由于G节点在子树中的支持度低于阈值,在去除低支持度节点并不包括子节点后D的条件模式基为{A:3,E:2,C:2}。通过D的条件模式基得到D的频繁2项集为{A:3,D:3},{E:2,D:2},{C:2,D:2}。
递归合并2项集,得到频繁3项集为{A:2,E:2,D:2},{A:2,C:2,D:2}。D节点对应的最大的频繁项集为频繁3项集。其余节点可以用类似的方法得出对应的频繁项集。
3. 使用FP-Growth算法实现新闻站点点击流频繁项集挖掘
使用FP-Growth算法挖掘匈牙利在线新闻门户的点击流数据kosarak.dat中的频繁项集,该数据有将近100万条记录,每一行包含某个用户浏览过的新闻报道。新闻报道被编码成整数,使用FP-growth算法挖掘其中的频繁项集,查看哪些新闻ID被用户大量浏览。
自定义包fpGrowth.py代码如下:
Plain Bash C++ C# CSS Diff HTML/XML Java Javascript Markdown PHP Python Ruby SQL
class treeNode :
"""
FP-tree树类
"""
def __init__ (self, nameValue, numOccur, parentNode ):
self .name = nameValue
self .count = numOccur
self .nodeLink = None
self .parent = parentNode
self .children = {}
def inc (self,numOccur ):
self .count += numOccur
def disp (self, ind=1 ):
print (' ' * ind, self .name, ' ' , self .count)
for child in self .children.values():
child.disp(ind + 1 )
def createTree (dataSet, minSup=1 ):
headerTable = {}
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0 ) + dataSet[trans]
for k in list (headerTable):
if headerTable[k] < minSup:
del (headerTable[k])
freqItemSet = set (headerTable.keys())
if len (freqItemSet) == 0 :
return None , None
for k in headerTable:
headerTable[k] = [headerTable[k], None ]
retTree = treeNode('Null Set' , 1 , None )
for tranSet, count in dataSet.items():
localD = {}
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0 ]
if len (localD) > 0 :
orderedItems = [v[0 ] for v in sorted (localD.items(), key=lambda p: p[1 ], reverse=True )]
updateTree(orderedItems, retTree, headerTable, count)
return retTree, headerTable
def updateTree (items, inTree, headerTable, count ):
if items[0 ] in inTree.children:
inTree.children[items[0 ]].inc(count)
else :
inTree.children[items[0 ]] = treeNode(items[0 ], count, inTree)
if headerTable[items[0 ]][1 ] == None :
headerTable[items[0 ]][1 ] = inTree.children[items[0 ]]
else :
updateHeader(headerTable[items[0 ]][1 ], inTree.children[items[0 ]])
if len (items) > 1 :
updateTree(items[1 ::], inTree.children[items[0 ]], headerTable, count)
def updateHeader (nodeToTest, targetNode ):
while (nodeToTest.nodeLink != None ):
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
def loadSimpDat ():
simpDat = [['r' , 'z' , 'h' , 'j' , 'p' ],
['z' , 'y' , 'x' , 'w' , 'v' , 'u' , 't' , 's' ],
['z' ],
['r' , 'x' , 'n' , 'o' , 's' ],
['y' , 'r' , 'x' , 'z' , 'q' , 't' , 'p' ],
['y' , 'z' , 'x' , 'e' , 'q' , 's' , 't' , 'm' ]]
return simpDat
def createInitSet (dataSet ):
retDict = {}
for trans in dataSet:
retDict[frozenset (trans)] = 1
return retDict
def ascendTree (leafNode, prefixPath ):
if leafNode.parent != None :
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath)
def findPrefixPath (basePat, treeNode ):
condPats = {}
while treeNode != None :
prefixPath = []
ascendTree(treeNode, prefixPath)
if len (prefixPath) > 1 :
condPats[frozenset (prefixPath[1 :])] = treeNode.count
treeNode = treeNode.nodeLink
return condPats
def mineTree (inTree, headerTable, minSup, preFix, freqItemList ):
bigL = [v[0 ] for v in sorted (headerTable.items(), key=lambda p: str (p[1 ]))]
for basePat in bigL:
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
print ('finalFrequent Item: ' ,newFreqSet)
freqItemList.append(newFreqSet)
condPattBases = findPrefixPath(basePat, headerTable[basePat][1 ])
print ('condPattBases :' ,basePat, condPattBases)
myCondTree, myHead = createTree(condPattBases, minSup)
print ('head from conditional tree: ' , myHead)
if myHead != None :
print ('conditional tree for: ' ,newFreqSet)
myCondTree.disp(1 )
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
def fpGrowth (dataSet, minSup=3 ):
initSet = createInitSet(dataSet)
myFPtree, myHeaderTab = createTree(initSet, minSup)
freqItems = []
mineTree(myFPtree, myHeaderTab, minSup, set ([]), freqItems)
return freqItems
在Python中实现FP-Growth算法挖掘新闻门户的点击流数据的代码,结果如下。
Plain Bash C++ C# CSS Diff HTML/XML Java Javascript Markdown PHP Python Ruby SQL import fpGrowth
newsdata = [line.split() for line in open ('../data/kosarak.dat' ).readlines()]
indataset = fpGrowth.createInitSet(newsdata)
news_fptree, news_headertab = fpGrowth.createTree(indataset, 50000 )
newslist = []
fpGrowth.mineTree(news_fptree, news_headertab, 50000 , set ([]), newslist)
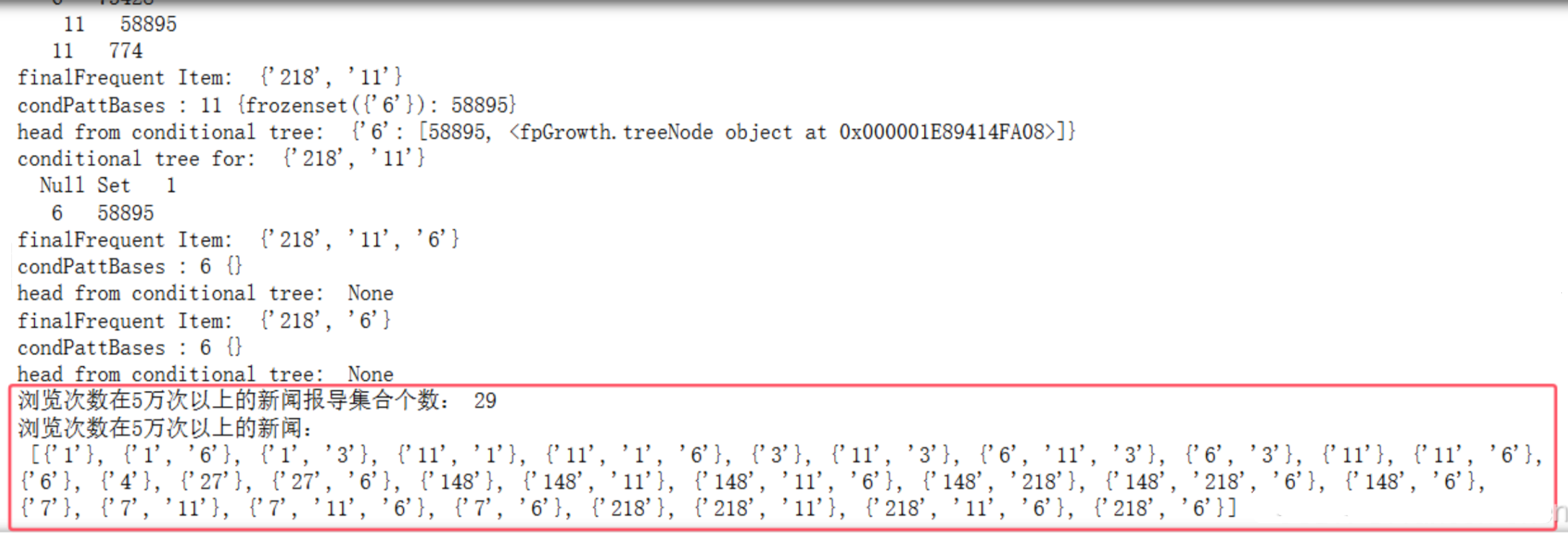
print ('浏览次数在5万次以上的新闻报导集合个数:' , len (newslist))
print ('浏览次数在5万次以上的新闻:\n' , newslist)
可以得到该网站上浏览次数超过5万次的新闻集合的个数为29个。