常见的协同过滤推荐技术主要分为基于用户和基于物品两大类。
一、基于用户的协同过滤
基于用户的协同过滤的基本思想相当简单,基于用户对物品的偏好找到相邻用户,然后将邻居用户喜欢的推荐给当前用户。在计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到K邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。如右图给出了一个例子,对于用户A,根据用户的历史偏好,这里只计算得到一个邻居-用户C,可以将用户C喜欢的物品D推荐给用户A。

1. 算法原理
实现基于用户的协同过滤算法第一个重要的步骤就是计算用户之间的相似度。而计算相似度,建立相关系数矩阵目前主要分为以下几种方法。


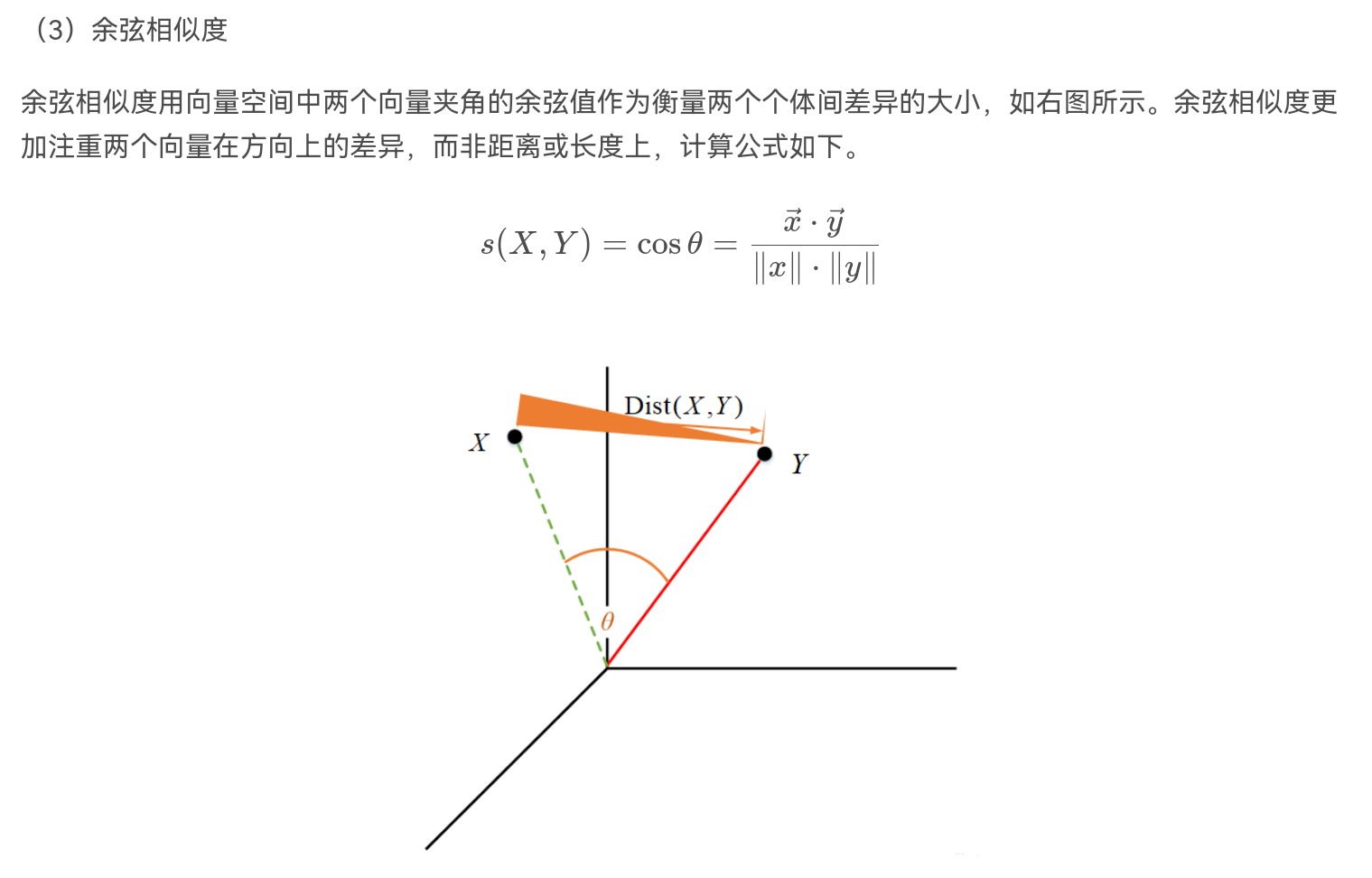


2. 基于用户的个性化的电影推荐
通过个性化的电影推荐的实例演示基于用户的协同过滤算法在Python中的实现。现今影视已经成为大众喜爱的休闲娱乐的方式之一,合理的个性化电影推荐一方面能够促进电影行业的发展,另一方面也可以让用户在数量众多的电影中迅速得到自己想要的电影,做到两全齐美。甚至更近一步,可以明确市场走向,对后续电影的类型导向等起到重要作用。
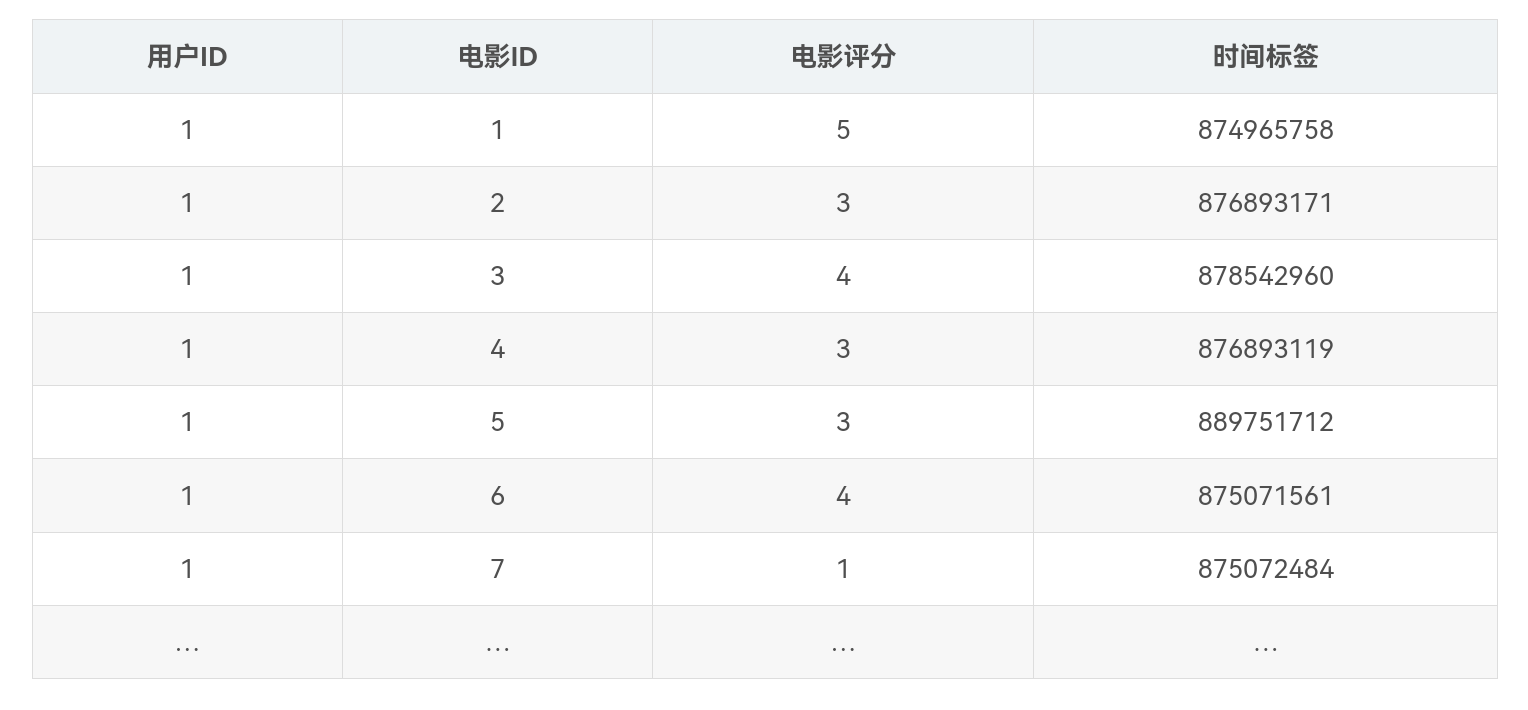
MovieLens数据集记录了943个用户对1682部电影的共100000个评分,每个用户至少对20部电影进行了评分。脱敏后的部分电影评分数据如下表所示。
自定义包recommender.py代码如下:
import numpy as np
import pandas as pd
import math
def prediction(df,userdf,Nn=15):
corr=df.corr();
rats=userdf.copy()
for itemid in userdf.columns:
dfnull=userdf.loc[:,itemid][userdf.loc[:,itemid].isnull()]
itemv=df.loc[:,itemid].mean()
for usrid in dfnull.index:
nft=(df.loc[usrid]).notnull()
nlist=df.loc[usrid][nft]
nlist=nlist[(corr.loc[itemid,nlist.index][corr.loc[itemid,nlist.index].notnull()].sort_values(ascending=False)).index]
if(Nn<=len(nlist)):
nlist=(df.loc[usrid][nft])[:Nn]
else:
nlist=df.loc[usrid][nft][:len(nlist)]
nratsum=0
corsum=0
if(0!=nlist.size):
nv=df.loc[:,nlist.index].mean()
for index in nlist.index:
ncor=corr.loc[itemid,index]
nratsum+=ncor*(df.loc[usrid][index]-nv[index])
corsum+=abs(ncor)
if(corsum!=0):
rats.at[usrid,itemid]= itemv + nratsum/corsum
else:
rats.at[usrid,itemid]= itemv
else:
rats.at[usrid,itemid]= None
return rats
def recomm(df,userdf,Nn=15,TopN=3):
ratings=prediction(df,userdf,Nn)
recomm=[]
for usrid in userdf.index:
ratft=userdf.loc[usrid].isnull()
ratnull=ratings.loc[usrid][ratft]
if(len(ratnull)>=TopN):
sortlist=(ratnull.sort_values(ascending=False)).index[:TopN]
else:
sortlist=ratnull.sort_values(ascending=False).index[:len(ratnull)]
recomm.append(sortlist)
return ratings,recomm
在Python中实现基于用户的协同过滤算法进行个性化电影推荐。将原始的事务性数据导入Python中,因为原始数据无字段名,所以首先需要对相应的字段进行重命名,再运行基于用户的协同过滤算法。得到用户预测评分数据和用户推荐列表数据,如下所示。
import pandas as pd
from recommender import recomm
traindata = pd.read_csv('../data/u1.base', sep='\t', header=None, index_col=None)
testdata = pd.read_csv('../data/u1.test', sep='\t', header=None, index_col=None)
traindata.drop(3, axis=1, inplace=True)
testdata.drop(3, axis=1, inplace=True)
traindata.rename(columns={0: 'userid', 1: 'movid', 2: 'rat'}, inplace=True)
testdata.rename(columns={0: 'userid', 1: 'movid', 2: 'rat'}, inplace=True)
traindf = traindata.pivot(index='userid', columns='movid', values='rat')
testdf = testdata.pivot(index='userid', columns='movid', values='rat')
traindf.rename(index={i: 'usr%d' % (i) for i in traindf.index}, inplace=True)
traindf.rename(columns={i: 'mov%d' % (i) for i in traindf.columns}, inplace=True)
testdf.rename(index={i: 'usr%d' % (i) for i in testdf.index}, inplace=True)
testdf.rename(columns={i: 'mov%d' % (i) for i in testdf.columns}, inplace=True)
userdf = traindf.loc[testdf.index]
trainrats, trainrecomm = recomm(traindf, userdf)
print('用户预测评分的前5行:\n', trainrats.head())
trainrats.to_csv('../tmp/movie_comm.csv', index=False, encoding='utf-8')
print('用户推荐列表的前5行:\n', trainrecomm[:5])
二、基于物品的协同过滤
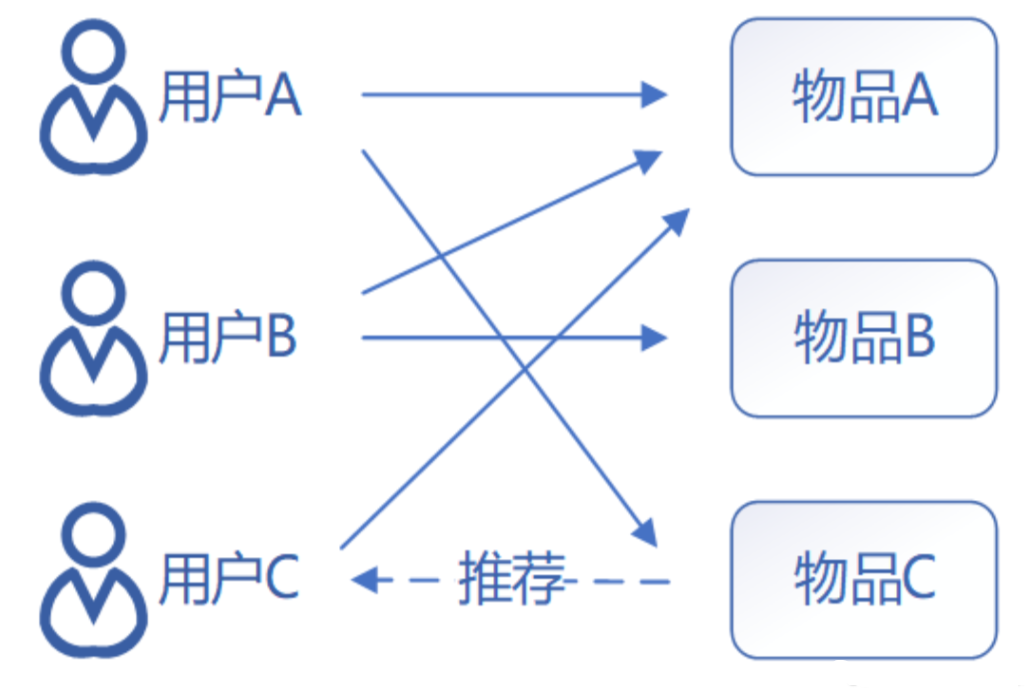
基于物品的协同过滤的原理和基于用户的协同过滤类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,再根据用户的历史偏好,推荐相似的物品给用户。从计算的角度看,是将所有用户对某个物品的偏好作为一个向量计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。对于物品A,根据所有用户的历史偏好,喜欢物品A的用户都喜欢物品C,得出物品A和物品C比较相似,而用户C喜欢物品A,可以推断出用户C可能也喜欢物品C,如图所示。
1. 算法过程
根据协同过滤的处理过程可知,基于物品的协同过滤算法(简称ItemCF算法)主要分为两个步骤。
- 计算物品之间的相似度。
- 根据物品的相似度和用户的历史行为为用户生成推荐列表。

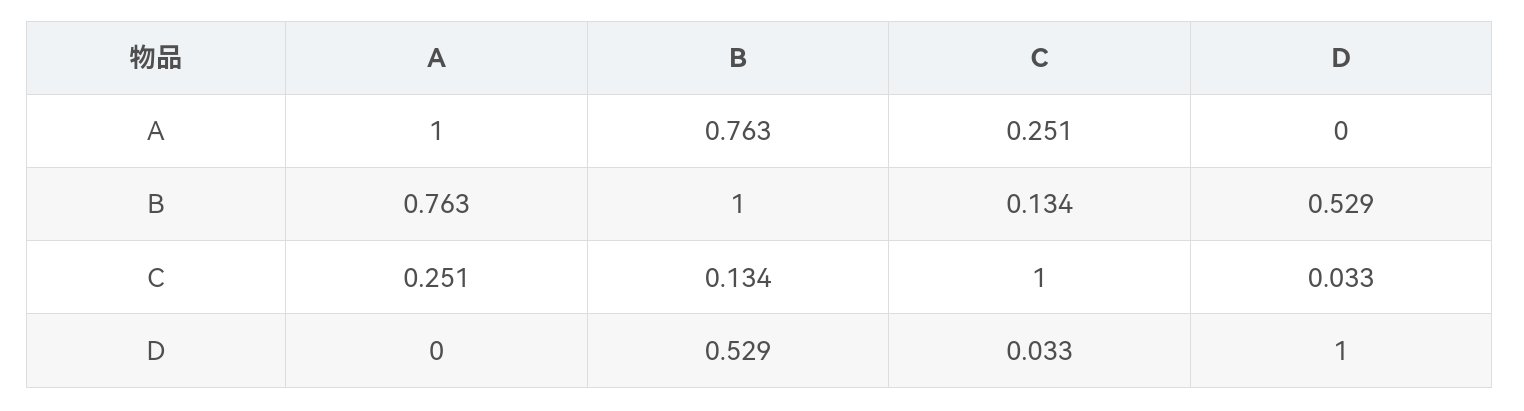
计算各个物品之间的相似度后,即可构成一个物品之间的相似度矩阵,如下表所示。通过相似度矩阵,推荐算法会为用户推荐与用户偏好的物品最相似的K个的物品。

推荐系统是根据物品的相似度以及用户的历史行为对用户的兴趣度进行预测并推荐,在评价模型的时候一般是将数据集划分成训练集和测试集两部分。模型通过在训练集的数据上进行训练学习得到推荐模型,然后在测试集数据上进行模型预测,最终统计出相应的评测指标评价模型预测效果的好与坏。
模型的评测采用的方法是交叉验证法。交叉验证法即将用户行为数据集按照均匀分布随机分成M份,挑选一份作为测试集,将剩下的M-1份作为训练集。在训练集上建立模型,并在测试集上对用户行为进行预测,统计出相应的评测指标。为了保证评测指标并不是过拟合的结果,需要进行M次实验,并且每次都使用不同的测试集。最后将M次实验测出的评测指标的平均值作为最终的评测指标。
构建基于物品的协同过滤推荐模型的流程如图所示。
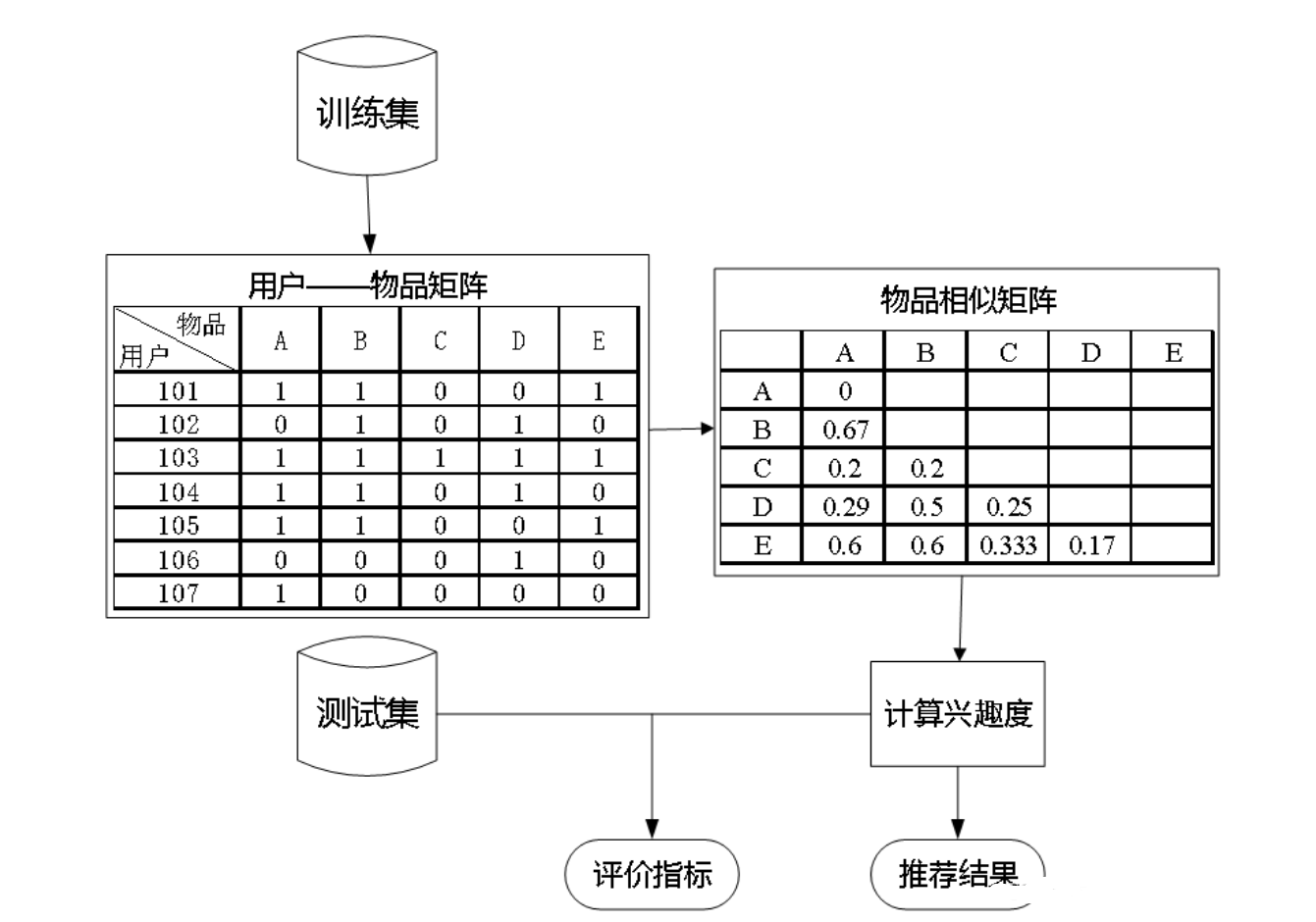
其中训练集与测试集是通过交叉验证的方法划分后的数据集。通过协同过滤算法的原理可知,在建立推荐系统时,建模的数据量越大,越能消除数据中的随机性,得到的推荐结果越好。算法的弊端在于数据量越大,模型建立和模型计算耗时越久。
2. 基于物品的个性化电影推荐
同样使用MovieLens数据集,将原始数据导入Python后使用基于物品的协同过滤算法进行个性化电影推荐,结果如图所示。
import pandas as pd
traindata = pd.read_csv('../data/u1.base', sep='\t', header=None, index_col=None)
testdata = pd.read_csv('../data/u1.test', sep='\t', header=None, index_col=None)
traindata.drop(3, axis=1, inplace=True)
testdata.drop(3, axis=1, inplace=True)
traindata.rename(columns={0: 'userid', 1: 'movid', 2: 'rat'}, inplace=True)
testdata.rename(columns={0: 'userid', 1: 'movid', 2: 'rat'}, inplace=True)
user_tr = traindata.iloc[:, 0]
mov_tr = traindata.iloc[:, 1]
user_tr = list(set(user_tr))
mov_tr = list(set(mov_tr))
print('训练集电影数:', len(mov_tr))
ui_matrix_tr = pd.DataFrame(0, index=user_tr, columns=mov_tr)
for i in traindata.index:
ui_matrix_tr.loc[traindata.loc[i, 'userid'], traindata.loc[i, 'movid']] = 1
print('训练集用户观影次数:', sum(ui_matrix_tr.sum(axis=1)))
item_matrix_tr = pd.DataFrame(0, index=mov_tr, columns=mov_tr)
for i in item_matrix_tr.index:
for j in item_matrix_tr.index:
a = sum(ui_matrix_tr.loc[:, [i, j]].sum(axis=1) == 2)
b = sum(ui_matrix_tr.loc[:, [i, j]].sum(axis=1) != 0)
item_matrix_tr.loc[i, j] = a / b
for i in item_matrix_tr.index:
item_matrix_tr.loc[i, i] = 0
user_te = testdata.iloc[:, 0]
mov_te = testdata.iloc[:, 1]
user_te = list(set(user_te))
mov_te = list(set(mov_te))
ui_matrix_te = pd.DataFrame(0, index=user_te, columns=mov_te)
for i in testdata.index:
ui_matrix_te.loc[testdata.loc[i, 'userid'], testdata.loc[i, 'movid']] = 1
res = pd.DataFrame('NaN', index=testdata.index, columns=['User', '已观看电影', '推荐电影', 'T/F'])
res.loc[:, 'User'] = list(testdata.iloc[:, 0])
res.loc[:, '已观看电影'] = list(testdata.iloc[:, 1])
for i in res.index:
if res.loc[i, '已观看电影'] in list(item_matrix_tr.index):
res.loc[i, '推荐电影'] = item_matrix_tr.loc[res.loc[i, '已观看电影'], :].argmax()
if res.loc[i, '推荐电影'] in mov_te:
res.loc[i, 'T/F'] = ui_matrix_te.loc[res.loc[i, 'User'], res.loc[i, '推荐电影']] == 1
else:
res.loc[i, 'T/F'] = False
res.to_csv('../tmp/res_mov.csv', index=False, encoding='utf8')
print('推荐结果前5行: \n', res.head())
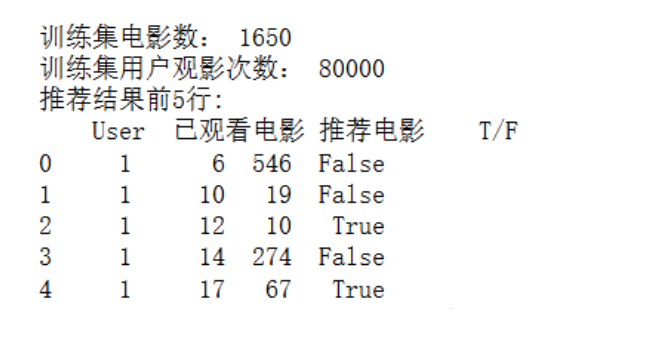
通过基于物品的协同过滤算法构建的推荐系统,得到针对用户每次观影记录的用户观影推荐,但是推荐结果可能存在NaN的情况。这种情况是由于在目前的数据集中,观看该电影的只有单独一个用户,使用协同过滤算法计算该电影与其他电影的相似度为0,所以出现了无法推荐的情况。


