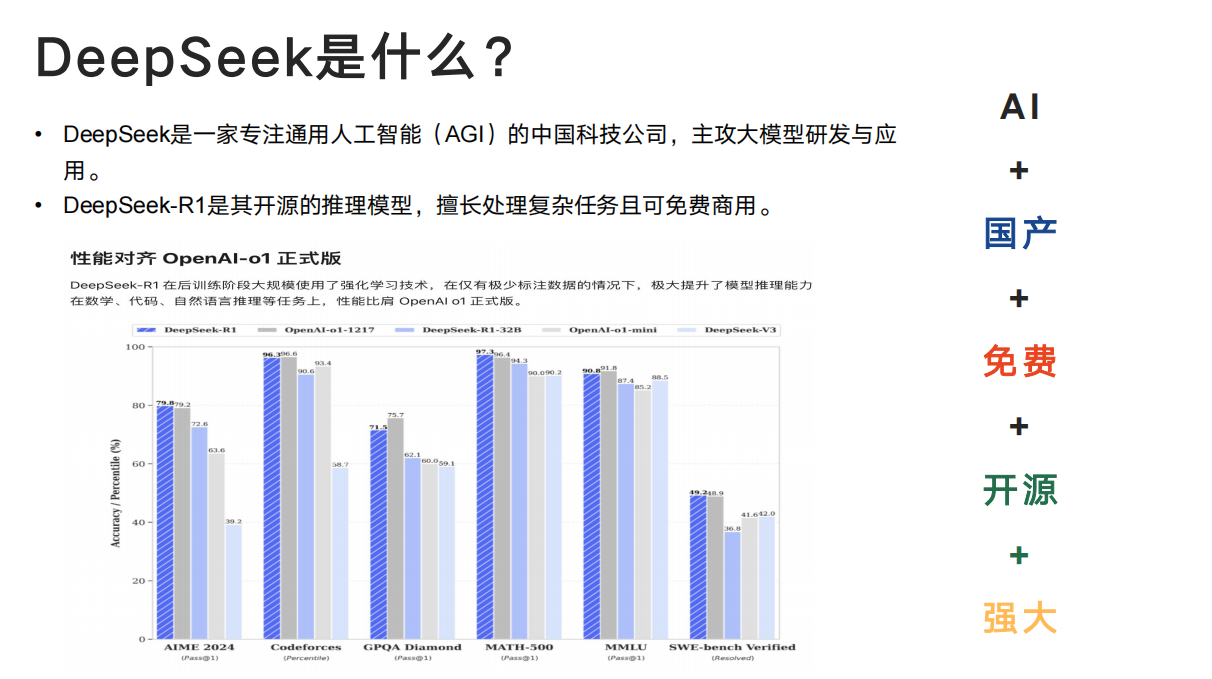
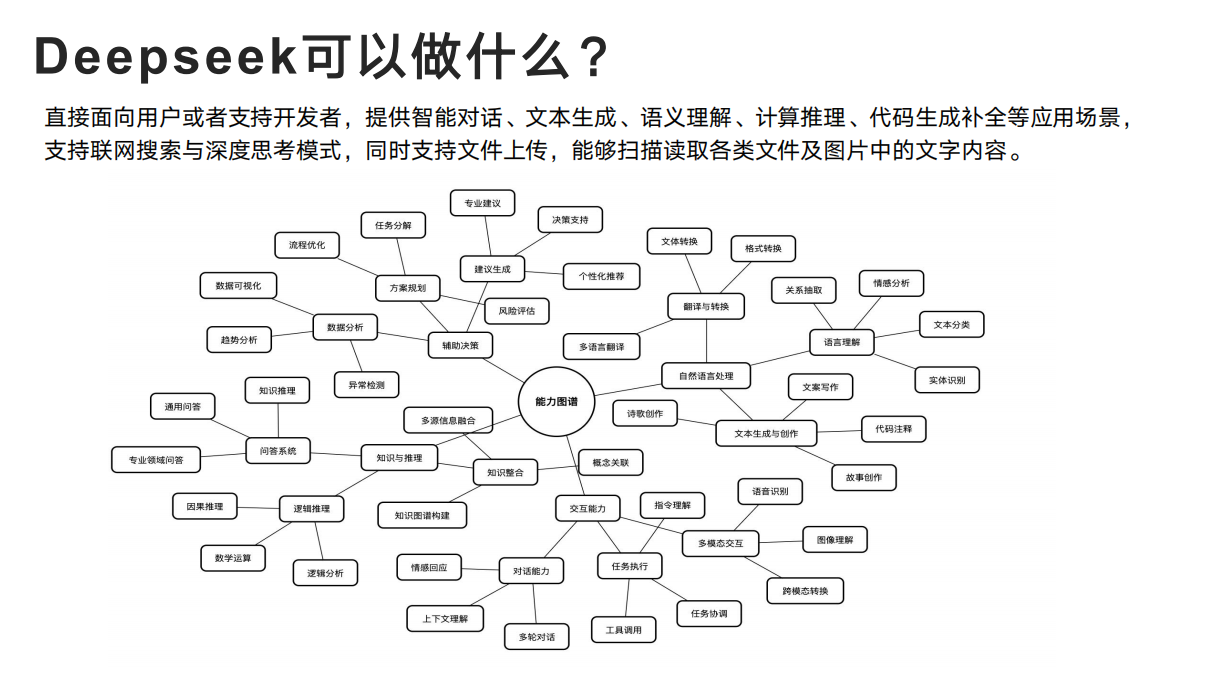
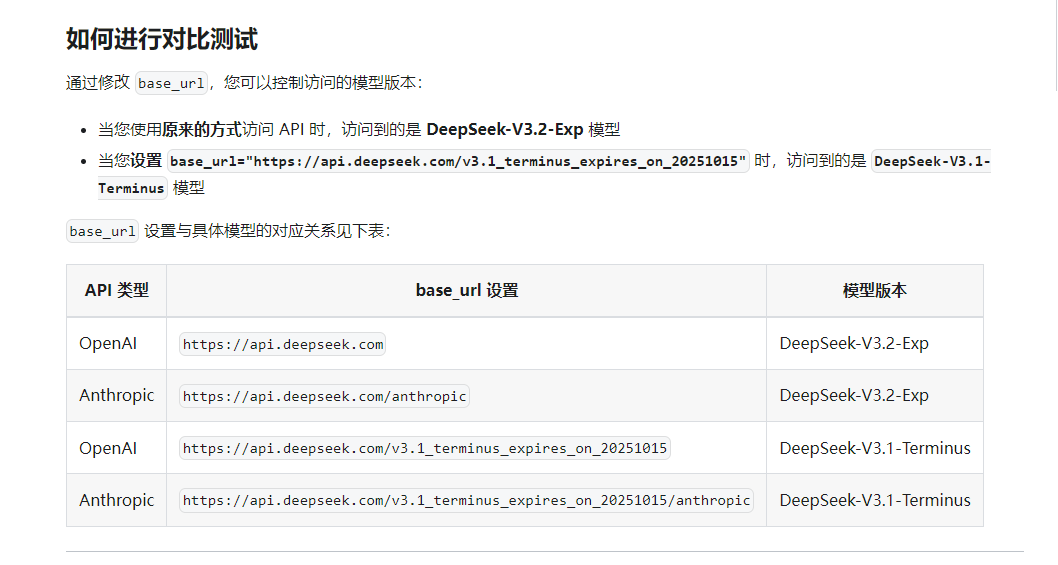
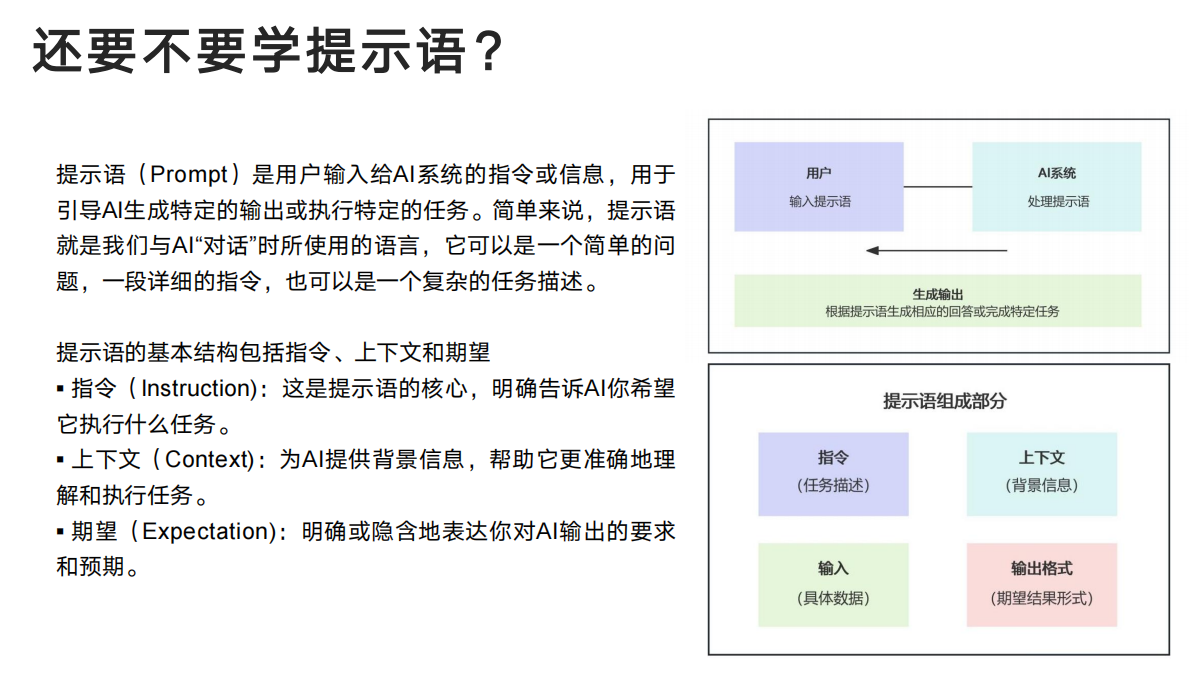
引言:AI技术革新与程序员节的特殊意义
在2025年的1024程序员节来临前段时间,DeepSeek的最新版本更新为全球开发者社区带来了一场技术盛宴。作为中国领先的AI大模型开发商,DeepSeek在近期连续发布了V3.1、V3.2-Exp等多个重要版本,展现出令人印象深刻的技术演进轨迹。这些更新不仅在模型架构上实现了重大突破,更在成本效益、长文本处理和企业级应用等方面设立了新的行业标杆。
本次全面技术评测将深入分析DeepSeek最新版本的核心技术创新、性能表现、实际应用场景以及未来发展趋势。作为面向程序员社区的深度解析,我们将特别关注三个经典代码案例,帮助开发者更好地理解这些技术突破的实际实现方式。从稀疏注意力机制到混合推理架构,从成本优化到部署方案,本文将为您呈现一幅完整的DeepSeek技术生态图谱。
在AI技术快速发展的今天,DeepSeek的进步不仅代表了技术上的突破,更体现了开源社区协作、算力优化和普惠AI的重要趋势。适逢1024程序员节,这一年度技术盛事为我们提供了深入审视AI技术现状与未来的绝佳时机。
一、DeepSeek版本演进与生态布局
1.1 从V3到V3.2-Exp的技术演进路径
DeepSeek的技术演进呈现出快速迭代、持续优化的显著特征。2025年8月,DeepSeek正式发布V3.1版本,这一版本被官方称为“迈向Agent(智能体)时代的第一步”。 V3.1的核心创新在于引入了混合推理架构 ,用户可以通过“深度思考”按钮在思考模式和非思考模式之间自由切换,实现了同一模型同时支持两种工作模式的能力。官方文档 DeepSeek-V3.1 发布
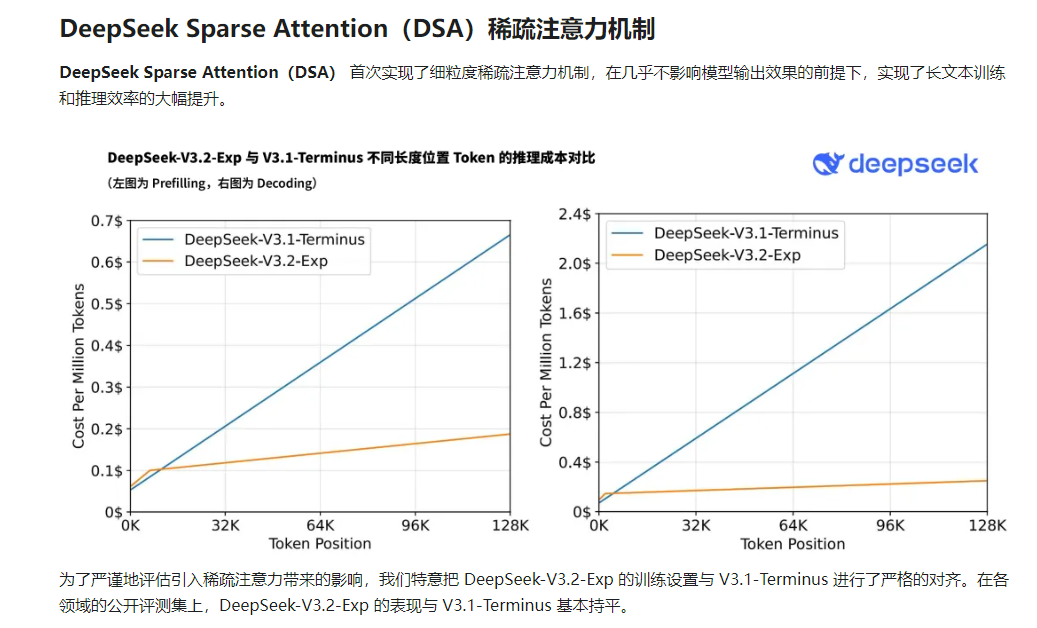
仅仅一个月后(2025年9月29日),DeepSeek再次推出V3.2-Exp实验版本,这次升级的重点放在了 效率优化 上。 V3.2-Exp在V3.1-Terminus的基础上引入了DeepSeek稀疏注意力(DSA,DeepSeek Sparse Attention)机制,专门针对长文本的训练和推理效率进行了探索性优化。这种持续的技术迭代显示了DeepSeek团队在模型架构创新上的坚定承诺。官方文档:DeepSeek-V3.2-Exp 发布,训练推理提效,API 同步降价
值得注意的是,DeepSeek在版本命名上也体现了其技术路线图的清晰性。V3.2-Exp中的“Exp”标识代表着实验性质,表明这是一个主要用于技术验证和社区测试的版本,为后续的正式版发布奠定基础。这种开放、透明的开发模式深受开发者社区的欢迎。
1.2 模型生态的整体布局
DeepSeek构建了完整的大模型产品矩阵,满足不同场景的需求。除了基础的V3系列外,DeepSeek还持续更新其推理增强版本R1系列。2025年10月18日,DeepSeek发布了R1-0528小版本更新,在数学、编程与通用逻辑等多个基准测评中取得了优异成绩。
在开源策略方面,DeepSeek始终坚持开放协作的理念。DeepSeek-R1-0528与之前的DeepSeek-R1使用同样的base模型,仅改进了后训练方法,开源版本上下文长度为128K,采用MIT许可证,允许用户利用模型输出、通过模型蒸馏等方式训练其他模型。这种开放策略极大地促进了AI技术的普及和创新。
从技术架构角度看,DeepSeek模型采用了671B总参数、37B激活参数的MoE(混合专家)架构,在保持强大性能的同时显著降低了推理成本。这种“小激活大参数量”的设计理念代表了当前大模型发展的主流方向。
1.3 最新发布的V3.2-Exp核心内容
DeepSeek最新发布的V3.2-Exp模型,通过引入创新的稀疏注意力机制,在保持强大性能的同时,显著提升了效率并大幅降低了API使用成本。
下面的表格整理了此次发布的核心信息,帮助你快速了解。
实验性 (Experimental) 版本,迈向新一代架构的中间步骤-3 -4
引入DeepSeek Sparse Attention (DSA) 稀疏注意力机制-1 -3
大幅提升长文本训练和推理效率,内存占用降低约30%-40%-6
在公开评测集上与前代V3.1-Terminus表现基本持平-3 -4
💡 模型详解与技术突破
稀疏注意力机制 :新引入的DeepSeek Sparse Attention (DSA) 是此次升级的关键。你可以将它理解为让AI模型处理信息时从“面面俱到”转变为 “抓关键” 。在处理长文本时,模型不再需要计算当前词与之前所有词的关系,而是智能地选择重要的部分进行关注,从而显著降低了计算复杂度和内存消耗 。
效率飞跃 :根据上海交通大学赵沛霖教授的估算,DeepSeek-V3.2-Exp保持了上代模型90%以上的性能,但计算量减少了约75% ,相当于仅用四分之一算力就达到了与前代模型基本持平的能力。在实际体验中,长文本的推理速度比前代版本快2-3倍 。
二、核心技术突破与架构创新
2.1 混合推理架构:智能体时代的基础设施
DeepSeek-V3.1最引人注目的创新是提出了 混合推理架构 ,这标志着大模型从单纯的对话工具向智能体平台的转变。传统的AI模型通常只能在简单快速响应和复杂深度思考之间二选一,而V3.1成功实现了同一模型同时支持两种模式,并能根据任务复杂度自动选择合适的工作模式。
混合推理架构的技术实现基于深度神经网络的条件计算原理。模型内部包含了多条处理路径,针对简单查询(如事实问答、简短总结),模型会启用快速推理路径,在极短时间内给出响应;而对于复杂任务(如数学证明、代码编写、逻辑推理),模型则会自动切换到深度思考模式,进行链式推理和逐步分析。
从工程角度看,这种架构带来了显著的效率提升。官方测试数据显示,相比DeepSeek-R1-0528,DeepSeek-V3.1-Think能在更短时间内给出答案,响应速度提升约30-40%。这意味着用户可以在不牺牲推理质量的前提下获得更快的响应体验,特别适合需要实时交互的应用场景。
2.2 稀疏注意力机制(DSA):长文本处理的革命性突破
DeepSeek-V3.2-Exp引入的 DeepSeek稀疏注意力 (DSA)机制是Transformer架构的重要革新。传统Transformer的自注意力机制具有O(n²)的计算复杂度,这在处理长文本时成为严重的性能瓶颈。 DSA通过细粒度的token选择机制,将计算复杂度降至O(n log n),同时保持94.7%的数学推理准确率。
DSA的技术核心包含两个关键组件:闪电索引器 (Lightning Indexer)和细粒度token选择机制 。闪电索引器负责快速计算查询token与所有前文token的重要性分数,其设计采用少量头数(通常为8或16)和FP8精度实现,极大降低了计算开销。细粒度token选择机制则根据索引分数筛选出最重要的k个token(论文中k=2048),仅在这些关键token上计算注意力权重。
实际测试结果表明,在128K长文本处理场景下,DSA能够将训练和推理速度提升2-3倍,内存占用降低30-40%。当序列长度达到128K时,DSA选中的token比例仅为2048/128000=1.6%,意味着注意力计算量降至密集模式的1.6%,效率提升约64倍。这种效率突破使得处理整本图书级别的长文档成为可能。
2.3 UE8M0 FP8低精度计算技术:国产算力的创新实践
DeepSeek-V3.1采用了 UE8M0 FP8 参数精度,这是针对下一代国产芯片设计的低精度计算格式。 UE8M0 FP8是一种8位浮点数格式,其中U代表无符号(只能表示正数和零),E8代表8位指数,M0代表0位尾数。这种格式的数值分布呈离散的指数形式,能显著降低内存占用和计算资源需求。
与传统的FP16或INT8格式相比,UE8M0 FP8在保持可接受精度损失的前提下,实现了计算效率的大幅提升。这项技术的创新价值在于为AI计算提供了更适合算力受限环境的解决方案,特别适合正在追赶国际先进水平的国产芯片平台。
DeepSeek官微表示,UE8M0 FP8是针对即将发布的下一代国产芯片设计的。预计于2025年下半年发布的摩尔线程MUSA 3.1 GPU、芯原VIP9000NPU等新一代国产芯片已明确支持原生FP8,并与DeepSeek、华为等15家企业联合验证UE8M0格式。这标志着国产AI算力生态建设取得重要进展。
三、性能评测与基准测试分析
3.1 通用能力评测结果
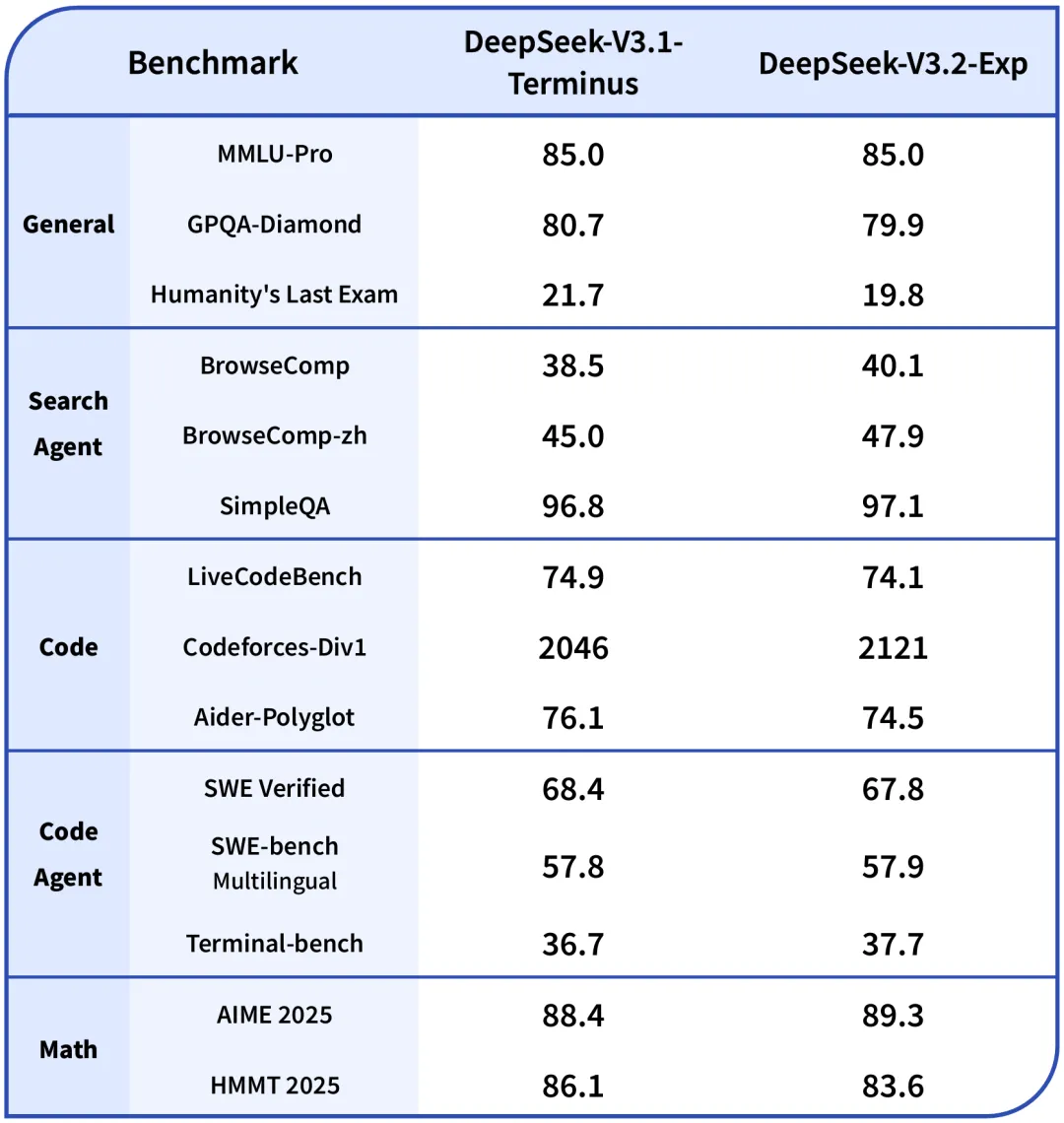
根据多维度基准测试,DeepSeek最新版本在各项指标上均表现出色。在MMLU-Pro(大规模多任务语言理解)测试中,V3.2-Exp得分85.0,与V3.1-Terminus持平,保持在开源模型第一梯队水准。在需要深度推理的GPQA Diamond测试中,V3.2-Exp得分为79.9,较V3.1-Terminus的80.7略有下降,但这种下降被证实源于推理token生成减少,可以通过中间checkpoint消除差距。
在专业领域测试中,DeepSeek展现出强大的知识推理能力。在Humanity's Last Exam(人类终极考试)测试集上,V3.2-Exp得分为19.8,较前代的21.7有所降低,但这一定位为“实验版本”的模型在核心能力上保持了高度稳定性。值得注意的是,在AIME 2025数学竞赛测试中,V3.2-Exp得分从88.4提升至89.3,表明稀疏注意力机制对数学推理有正向增益作用。
多语言支持方面,V3.1版本能处理超过100种语言,尤其优化了亚洲语言和资源较少语种的运用。这种多语言能力的强化使得DeepSeek在国际化应用场景中具有显著优势。
3.2 编程与代码生成能力评估
作为面向开发者社区的核心能力,DeepSeek在编程任务中的表现尤为引人关注。根据社区使用Aider测试数据,V3.1在AiderPolyglot多语言编程测试中拿下了71.6%的高分,超越了Claude4Opus和DeepSeekR1等模型。在SVGBench基准测试中,其实力仅次于GPT-4.1-mini,远超DeepSeekR1。
具体到编程竞赛能力,DeepSeek-V3.2-Exp在Codeforces评级从2046提升至2121,展现了持续的代码生成能力优化。在LiveCodeBench测试中,V3.2-Exp得分74.1,与V3.1-Terminus的74.9基本持平,表明稀疏注意力机制没有对代码生成质量产生负面影响。
在更具挑战的软件工程任务中,DeepSeek表现出色但仍有提升空间。在SWE Verified(软件工程验证)测试中,V3.2-Exp得分为67.8,较前代下降0.6分;在SWE-bench Multilingual多语言软件工程测试中,得分从57.8微升至57.9。这些结果表明DeepSeek在复杂软件工程场景中与顶尖模型如GPT-5相比仍有一定差距。
3.3 智能体与工具调用能力
DeepSeek-V3.1在智能体能力方面取得重要进展,通过Post-Training优化,新模型在工具使用与智能体任务中的表现有较大提升。官方API已支持严格模式的Function Calling,确保模型在调用外部工具时输出的结果完全符合预设格式,满足了企业用户对稳定性和准确性的核心需求。
在具体基准测试中,DeepSeek-V3.2-Exp在BrowseComp-zh(中文浏览器操作)测试中得分从45.0提升至47.9,在SimpleQA(简单问答)测试中达到97.1%的准确率。这些成绩表明模型在理解指令、执行复杂操作方面的能力持续增强。
DeepSeek-R1-0528在工具调用方面也取得显著进步,其Tau-Bench测评成绩为airline 53.5%/retail 63.9%,与OpenAI o1-high相当,但与o3-High以及Claude 4 Sonnet仍有差距。这表明DeepSeek在复杂智能体任务方面正在快速追赶国际顶尖水平。
四、成本革命与API定价策略
4.1 大幅降低的API调用成本
DeepSeek-V3.2-Exp的API定价策略具有行业颠覆性,调用成本大幅降低50%以上。新定价结构采用基于缓存的差异化策略:缓存命中时输入成本为0.07美元/百万token,输出成本为0.16美元/百万token;缓存未命中时输入成本为0.56美元/百万token,输出成本为0.42美元/百万token。
与主流竞争对手相比,DeepSeek新定价展现出巨大成本优势。GPT-4的API成本约为30美元/百万token,Claude-3.5约为15美元/百万token,而DeepSeek-V3.2即使缓存未命中的成本也仅为0.42-0.56美元/百万token,比大多数竞争对手低50%以上。这种定价策略极大降低了中小企业的AI应用门槛。
成本降低的主要技术支撑是稀疏注意力机制带来的计算效率提升。DSA机制显著减少了长文本处理的计算资源需求,使DeepSeek能够在保持服务质量的同时大幅下调价格。此外,缓存机制的优化也减少了重复计算,进一步降低了运营成本。
4.2 训练与推理效率提升
DeepSeek-V3.2-Exp在训练和推理效率上实现了双重突破。在训练效率方面,DSA机制使训练速度提升约50%。这主要归功于稀疏注意力减少了需要计算的前向和反向传播量,同时保持了梯度流的有效性。
推理效率的提升更为显著。实际测试显示,V3.2-Exp的长文本推理速度比前代版本快2-3倍,内存占用降低约30%-40%。专家估算,新版本保持了上代模型90%以上的性能,但计算量减少了约75%,相当于仅用1/4算力便可与前代模型能力基本持平。
这种效率提升的直接结果是部署成本的显著下降。对于企业用户而言,意味着可以在相同的硬件预算下支持更大的用户规模,或者以更低的成本提供相同质量的服务。特别是在长文本处理场景中,效率优势转化为显著的经济效益。
五、企业级应用与部署方案
5.1 增强的企业级服务能力
DeepSeek-V3.1在企业级应用方面表现出色,特别增强了严格模式的函数调用 功能,确保模型在调用外部工具(如查询企业数据库)时输出的结果完全符合预设格式,避免了数据错误,满足了企业用户对稳定性和准确性的核心需求。
同时,V3.1兼容国际主流API格式(如Anthropic API格式),这意味着原本使用其他框架的企业可以无缝切换到DeepSeek,无需修改现有系统。这种兼容性设计大大降低了企业迁移成本,助力DeepSeek吸引更多企业用户。
在企业级服务保障方面,DeepSeek已正式上线火山方舟,企业用户可以在更快、更稳的资源保障下体验最新模型,实现20-40ms吐字间隔(TPOT)超低延迟,并提供全网最高的500万初始并发TPM。这种服务水平协议(SLA)保障使得DeepSeek能够满足高要求的商业应用场景。
5.2 多平台部署解决方案
DeepSeek提供灵活的部署选项,支持多种主流推理框架。SGLang、LMDeploy、vLLM等框架已实现对FP8/BF16推理的支持,TensorRT-LLM支持BF16及INT4/8量化(FP8支持即将发布)。这种多框架支持确保了模型可以在不同硬件环境中高效运行。
特别值得关注的是,通过SGLang框架,DeepSeek模型可直接部署在AMD GPU及M3 Ultra的Mac Studio上,将大模型应用门槛降至消费级硬件水平。对于资源受限的开发环境,这种跨平台支持大大降低了实验和部署成本。
针对国产芯片平台,DeepSeek也提供了优化支持。预计于2025年下半年发布的摩尔线程MUSA 3.1 GPU、芯原VIP9000NPU等新一代国产芯片已与DeepSeek联合验证UE8M0格式。这意味着DeepSeek有望在国产硬件平台上实现高效运行,为自主可控的AI算力生态建设奠定基础。
六、经典代码案例解析
6.1 案例一:缩放点积注意力机制实现
缩放点积注意力是Transformer架构的核心组件,也是理解DeepSeek模型的基础。以下是使用Python和PyTorch实现的简化版本:
Plain Bash C++ C# CSS Diff HTML/XML Java Javascript Markdown PHP Python Ruby SQL import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class ScaledDotProductAttention(nn.Module):
"""
实现缩放点积注意力机制
对应Transformer架构中的核心注意力组件
"""
def __init__(self, d_model, dropout=0.1):
super(ScaledDotProductAttention, self).__init__()
self.d_model = d_model
self.dropout = nn.Dropout(dropout)
self.scale_factor = 1.0 / math.sqrt(d_model)
def forward(self, query, key, value, mask=None):
"""
前向传播计算注意力
Args:
query: 查询张量 [batch_size, seq_len, d_model]
key: 键张量 [batch_size, seq_len, d_model]
value: 值张量 [batch_size, seq_len, d_model]
mask: 注意力掩码 [batch_size, seq_len, seq_len]
Returns:
注意力输出和注意力权重
"""
# 计算查询和键的点积
scores = torch.matmul(query, key.transpose(-2, -1))
# 应用缩放因子
scores = scores * self.scale_factor
# 应用注意力掩码(如果提供)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 计算注意力权重
attention_weights = F.softmax(scores, dim=-1)
attention_weights = self.dropout(attention_weights)
# 应用注意力权重到值张量
output = torch.matmul(attention_weights, value)
return output, attention_weights
# 使用示例
def demonstrate_attention():
# 模型参数
batch_size, seq_len, d_model = 2, 10, 512
# 初始化注意力机制
attention = ScaledDotProductAttention(d_model)
# 创建随机输入(模拟token嵌入)
query = torch.randn(batch_size, seq_len, d_model)
key = torch.randn(batch_size, seq_len, d_model)
value = torch.randn(batch_size, seq_len, d_model)
# 计算注意力
output, weights = attention(query, key, value)
print(f"输入形状: query{query.shape}, key{key.shape}, value{value.shape}")
print(f"输出形状: {output.shape}")
print(f"注意力权重形状: {weights.shape}")
print(f"注意力权重示例(第一个序列的第一个头):")
print(weights[0, 0, :].detach().numpy())
if __name__ == "__main__":
demonstrate_attention()
这个实现展示了Transformer中注意力机制的核心计算流程。首先计算查询和键的点积,然后应用缩放因子防止softmax梯度消失,接着应用softmax函数得到注意力权重,最后将权重应用于值张量。DeepSeek的基座模型就是基于这种注意力机制构建的,不过在V3.2-Exp中引入了稀疏优化。
6.2 案例二:DeepSeek稀疏注意力(DSA)简化实现
以下是DeepSeek-V3.2-Exp中稀疏注意力机制的简化实现,展示了闪电索引器和top-k选择的核心思想:
Plain Bash C++ C# CSS Diff HTML/XML Java Javascript Markdown PHP Python Ruby SQL import torch
import torch.nn as nn
import torch.nn.functional as F
class LightningIndexer(nn.Module):
"""
闪电索引器简化实现
对应DeepSeek-V3.2-Exp中的轻量级索引组件
"""
def __init__(self, d_model, n_heads=8, d_indexer=64):
super(LightningIndexer, self).__init__()
self.n_heads = n_heads
self.d_indexer = d_indexer
# 索引器的投影层
self.query_proj = nn.Linear(d_model, n_heads * d_indexer)
self.key_proj = nn.Linear(d_model, n_heads * d_indexer)
self.weight_proj = nn.Linear(d_model, n_heads)
def forward(self, query, keys):
"""
计算索引分数
Args:
query: 当前查询token [batch_size, d_model]
keys: 历史key tokens [batch_size, seq_len, d_model]
Returns:
索引分数 [batch_size, n_heads, seq_len]
"""
batch_size, seq_len, _ = keys.shape
# 投影到索引空间
q_index = self.query_proj(query).view(batch_size, self.n_heads, self.d_indexer)
k_index = self.key_proj(keys).view(batch_size, seq_len, self.n_heads, self.d_indexer)
weights = self.weight_proj(query).view(batch_size, self.n_heads, 1)
# 计算每个头的索引分数
index_scores = torch.zeros(batch_size, self.n_heads, seq_len)
for i in range(self.n_heads):
# 计算查询和键的点积,应用ReLU
head_scores = torch.matmul(k_index[:, :, i, :], q_index[:, i, :].unsqueeze(-1))
head_scores = F.relu(head_scores.squeeze(-1))
# 加权求和
index_scores[:, i, :] = weights[:, i, :] * head_scores
# 对序列维度求和得到最终索引分数
index_scores = index_scores.sum(dim=1) # [batch_size, seq_len]
return index_scores
class SparseAttention(nn.Module):
"""
稀疏注意力机制简化实现
展示DeepSeek-V3.2-Exp的核心稀疏化思想
"""
def __init__(self, d_model, n_heads=8, top_k=2048):
super(SparseAttention, self).__init__()
self.d_model = d_model
self.n_heads = n_heads
self.top_k = top_k
self.d_k = d_model // n_heads
self.indexer = LightningIndexer(d_model, n_heads)
self.query_proj = nn.Linear(d_model, d_model)
self.key_proj = nn.Linear(d_model, d_model)
self.value_proj = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, query, keys, values):
batch_size, seq_len, _ = keys.shape
# 1. 使用闪电索引器计算重要性分数
index_scores = self.indexer(query.squeeze(1), keys)
# 2. Top-k选择:仅保留最重要的k个token
topk_scores, topk_indices = torch.topk(index_scores, k=self.top_k, dim=-1)
# 3. 使用选中的token计算稀疏注意力
sparse_output = torch.zeros_like(query)
sparse_attention_weights = torch.zeros(batch_size, seq_len)
for i in range(batch_size):
# 获取当前batch的top-k索引
current_indices = topk_indices[i]
# 从keys和values中选取对应的token
selected_keys = keys[i, current_indices, :].unsqueeze(0)
selected_values = values[i, current_indices, :].unsqueeze(0)
current_query = query[i, :, :].unsqueeze(0)
# 计算标准注意力(仅在选中的token上)
attn_output, attn_weights = self.dense_attention(
current_query, selected_keys, selected_values
)
sparse_output[i, :, :] = attn_output
sparse_attention_weights[i, current_indices] = attn_weights.squeeze()
return sparse_output, sparse_attention_weights
def dense_attention(self, query, key, value):
"""在选中的token上计算密集注意力"""
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
attn_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attn_weights, value)
return output, attn_weights.squeeze()
# 稀疏注意力使用示例
def demonstrate_sparse_attention():
# 模拟长序列处理场景(128K长度中的一个小片段)
batch_size, seq_len, d_model = 2, 1000, 512
top_k = 64 # 稀疏注意力选择的token数量
# 初始化稀疏注意力模块
sparse_attn = SparseAttention(d_model, top_k=top_k)
# 创建模拟输入
query = torch.randn(batch_size, 1, d_model) # 当前查询token
keys = torch.randn(batch_size, seq_len, d_model) # 历史key tokens
values = torch.randn(batch_size, seq_len, d_model) # 历史value tokens
# 计算稀疏注意力
output, attention_weights = sparse_attn(query, keys, values)
print(f"原始序列长度: {seq_len}")
print(f"稀疏化后实际计算长度: {top_k}")
print(f"计算复杂度降低比例: {(1 - top_k/seq_len) * 100:.2f}%")
print(f"输出形状: {output.shape}")
print(f"注意力权重稀疏模式:")
print(f"非零元素数量: {torch.sum(attention_weights > 0).item()}")
print(f"稀疏度: {torch.sum(attention_weights == 0).item() / attention_weights.numel() * 100:.2f}%")
if __name__ == "__main__":
demonstrate_sparse_attention()
这个简化实现展示了DeepSeek稀疏注意力的核心思想:通过轻量级的索引器快速识别重要token,然后仅在选中的token子集上计算注意力。这种方法在处理长文本时能显著降低计算复杂度,从O(n²)降至O(n log n)。
6.3 案例三:DeepSeek API函数调用集成示例
以下代码展示如何在实际应用中集成DeepSeek API,特别是函数调用和工具使用能力:
Plain Bash C++ C# CSS Diff HTML/XML Java Javascript Markdown PHP Python Ruby SQL import requests
import json
from typing import Dict, List, Any, Optional
class DeepSeekClient:
"""
DeepSeek API客户端实现
展示函数调用和工具使用能力
"""
def __init__(self, api_key: str, base_url: str = "https://api.deepseek.com/v1"):
self.api_key = api_key
self.base_url = base_url
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
def call_function(self, prompt: str, functions: List[Dict],
model: str = "deepseek-reasoning") -> Dict[str, Any]:
"""
调用DeepSeek函数调用API
对应DeepSeek-V3.1的严格模式函数调用功能
"""
payload = {
"model": model,
"messages": [{"role": "user", "content": prompt}],
"functions": functions,
"function_call": "auto", # 自动选择是否调用函数
"max_tokens": 4000,
"temperature": 0.1
}
try:
response = requests.post(
f"{self.base_url}/chat/completions",
headers=self.headers,
data=json.dumps(payload),
timeout=30
)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
return {"error": str(e)}
def process_with_tool_use(self, user_query: str) -> str:
"""
演示DeepSeek的工具使用能力
对应DeepSeek-R1-0528的工具调用增强
"""
# 定义可用的工具函数
available_functions = [
{
"name": "search_web",
"description": "在互联网上搜索最新信息",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词"
},
"max_results": {
"type": "integer",
"description": "最大结果数量",
"default": 5
}
},
"required": ["query"]
}
},
{
"name": "query_database",
"description": "查询企业数据库获取结构化数据",
"parameters": {
"type": "object",
"properties": {
"sql_query": {
"type": "string",
"description": "SQL查询语句"
},
"timeout": {
"type": "integer",
"description": "查询超时时间(秒)",
"default": 30
}
},
"required": ["sql_query"]
}
},
{
"name": "calculate_math",
"description": "执行复杂数学计算",
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "数学表达式"
},
"precision": {
"type": "integer",
"description": "计算精度(小数位数)",
"default": 8
}
},
"required": ["expression"]
}
}
]
# 调用DeepSeek API
response = self.call_function(user_query, available_functions)
# 处理API响应
if "error" in response:
return f"API调用错误: {response['error']}"
# 解析模型响应
message = response["choices"][0]["message"]
# 检查是否要求调用函数
if message.get("function_call"):
function_name = message["function_call"]["name"]
function_args = json.loads(message["function_call"]["arguments"])
# 执行相应的工具函数
result = self.execute_function(function_name, function_args)
# 将结果返回给模型进行进一步处理
follow_up_response = self.follow_up_with_result(
user_query, function_name, function_args, result
)
return follow_up_response
else:
# 直接返回模型响应
return message["content"]
def execute_function(self, function_name: str, arguments: Dict) -> Any:
"""执行工具函数(模拟实现)"""
if function_name == "search_web":
return self.mock_web_search(arguments["query"])
elif function_name == "query_database":
return self.mock_database_query(arguments["sql_query"])
elif function_name == "calculate_math":
return self.mock_math_calculation(arguments["expression"])
else:
return {"error": f"未知函数: {function_name}"}
def follow_up_with_result(self, original_query: str, function_name: str,
arguments: Dict, result: Any) -> str:
"""将工具执行结果返回给模型进行进一步处理"""
follow_up_prompt = f"""
原始用户查询: {original_query}
我已经执行了您请求的工具调用:
函数: {function_name}
参数: {json.dumps(arguments, indent=2)}
执行结果: {json.dumps(result, indent=2)}
请根据以上信息回答用户的原始查询。
"""
payload = {
"model": "deepseek-reasoning",
"messages": [
{"role": "user", "content": original_query},
{"role": "assistant", "content": f"I need to call function {function_name}"},
{"role": "user", "content": follow_up_prompt}
],
"max_tokens": 2000,
"temperature": 0.1
}
response = requests.post(
f"{self.base_url}/chat/completions",
headers=self.headers,
data=json.dumps(payload)
)
return response.json()["choices"][0]["message"]["content"]
# 模拟工具函数实现
def mock_web_search(self, query: str) -> List[Dict]:
"""模拟网页搜索"""
return [
{"title": "DeepSeek-V3.2技术文档", "url": "https://deepseek.com/docs", "snippet": "DeepSeek最新版本的技术规格..."},
{"title": "AI模型评测报告", "url": "https://example.com/ai-review", "snippet": "2025年大模型性能对比分析..."}
]
def mock_database_query(self, sql_query: str) -> List[Dict]:
"""模拟数据库查询"""
return [
{"id": 1, "name": "DeepSeek-V3.2", "performance": 85.0, "release_date": "2025-09-29"},
{"id": 2, "name": "Previous-Version", "performance": 82.3, "release_date": "2025-08-21"}
]
def mock_math_calculation(self, expression: str) -> Dict[str, Any]:
"""模拟数学计算"""
try:
# 注意:实际环境中应使用安全的数学计算库
result = eval(expression) # 简化演示,实际应用需要安全处理
return {"expression": expression, "result": result, "precision": 8}
except:
return {"expression": expression, "error": "计算失败"}
# 使用示例
def demonstrate_deepseek_integration():
"""演示DeepSeek API集成"""
# 初始化客户端(需要真实的API密钥)
# client = DeepSeekClient(api_key="your_api_key_here")
# 模拟使用场景
test_cases = [
"请搜索2025年最新的AI模型技术发展情况",
"查询我们数据库中性能评分超过80分的AI模型",
"计算公式: (3.14159 * 15.7^2) / 4.2 + 10^3"
]
print("DeepSeek API工具调用能力演示")
print("=" * 50)
# 由于需要真实API密钥,这里只展示代码结构
print("代码结构演示完成")
print("实际使用需要:")
print("1. 申请DeepSeek API密钥")
print("2. 安装requests库: pip install requests")
print("3. 配置API终端点和认证信息")
# 显示函数调用的预期输出格式
example_response = {
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "deepseek-reasoning",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "根据我的搜索,2025年AI模型的最新发展包括...",
"function_call": {
"name": "search_web",
"arguments": "{\"query\": \"2025 AI模型技术发展\"}"
}
},
"finish_reason": "function_call"
}]
}
print("\n预期API响应格式:")
print(json.dumps(example_response, indent=2, ensure_ascii=False))
if __name__ == "__main__":
demonstrate_deepseek_integration()
这个完整的代码示例展示了如何在实际项目中集成DeepSeek API的函数调用能力。代码包含了客户端初始化、函数定义、API调用和结果处理的全流程,体现了DeepSeek-V3.1在工具使用和智能体任务中的增强能力。
七、未来展望与技术发展趋势
7.1 短期技术路线图
根据官方信息和社区讨论,DeepSeek的发展路线图已规划至2026年。在2025年10月-12月期间,团队将主要聚焦于V3.2-Exp的优化和社区反馈收集,预计在12月发布V3.2正式版。这次更新将包含对稀疏注意力机制的进一步 refinement 和新架构预览。
2026年第一季度,DeepSeek计划发布V4版本候选和R2 agent版本。这表明公司技术发展将沿两个主要方向推进:基础模型架构的持续创新和智能体能力的专项增强。特别是R2 agent版本的开发,将重点提升模型的工具使用和自主任务执行能力。
从技术发展方向看,DeepSeek将重点关注三个领域:架构创新(更高效的稀疏注意力模式、专家混合系统优化、多模态能力集成)、Agent能力(R2 agent版本开发、MCP支持、工具使用增强)和生态建设(支持更多部署平台、开发者工具改进、社区贡献机制)。这些方向反映了AI行业从基础模型能力向实用化、智能化应用的发展趋势。
7.2 稀疏注意力技术的行业影响
DeepSeek-V3.2-Exp中引入的稀疏注意力技术有望对整个AI行业产生深远影响。传统Transformer架构的O(n²)计算复杂度一直是长文本处理的主要瓶颈,而DSA技术成功地将复杂度降至O(n log n),同时保持模型性能基本不变。
这一技术突破的意义不仅限于DeepSeek自身产品的优化,更重要的是为整个行业提供了可借鉴的技术路径。预计在2025-2026年,稀疏注意力将成为大模型架构的标准配置,特别是在处理长上下文场景中。这种技术普及将显著降低AI计算的整体成本,使更多资源受限的组织能够部署和使用大模型能力。
从硬件角度看,稀疏注意力技术也对AI芯片设计提出了新要求。传统的稠密矩阵计算优化需要向稀疏计算优化转变,这为国产芯片厂商提供了弯道超车的机会。DeepSeek与国产芯片厂商的深度合作,将推动整个AI算力生态的多元化发展。
八、结论与建议
8.1 技术总结与评价
DeepSeek在2025年的系列更新展示了中国AI企业在全球大模型竞争中的强大实力。从V3.1的混合推理架构到V3.2-Exp的稀疏注意力机制,DeepSeek在模型架构创新上持续领先。特别是在保持高性能的同时实现成本大幅降低,体现了深厚的技术积累和工程优化能力。
在性能表现方面,DeepSeek最新版本在多数基准测试中与国际顶尖模型持平甚至超越,仅在极复杂软件工程场景中与GPT-5等顶级模型存在细微差距。这种均衡而强大的能力使DeepSeek成为企业级应用的理想选择。
成本革命是DeepSeek本次更新的另一大亮点。API价格降低50%以上,输入成本低至0.07美元/百万token,这种定价策略极大降低了AI应用的门槛。结合开源策略和灵活的部署方案,DeepSeek正在构建一个开放、普惠的AI技术生态。
8.2 实用建议与行动指南
针对不同用户群体,我们提出以下实用建议:
对于开发者个人和学习者 :
对于中小企业和初创公司 :
对于大型企业和技术团队 :
对于研究机构和学术界 :
在1024程序员节这个特殊时刻,DeepSeek的技术进步为开发者社区带来了实实在在的技术红利。随着AI技术的不断成熟和普及,我们有理由相信,DeepSeek将继续在推动AI技术民主化和普惠化方面发挥重要作用。
关键字解释说明
DeepSeek-V3.2-Exp :DeepSeek于2025年9月发布的实验性大语言模型,引入稀疏注意力机制,专注于长文本处理效率优化。稀疏注意力(DSA) :DeepSeek Sparse Attention的缩写,一种通过选择关键token计算注意力来降低计算复杂度的机制,将复杂度从O(n²)降至O(n log n)。混合专家(MoE) :Mixture of Experts架构,DeepSeek-V3使用671B总参数但仅激活37B参数,在保持性能的同时降低推理成本。混合推理架构 :DeepSeek-V3.1引入的创新,同一模型支持快速响应和深度思考两种模式,可根据任务复杂度自动切换。UE8M0 FP8 :DeepSeek采用的8位浮点数格式,针对国产芯片优化,能显著降低内存占用和计算资源需求。闪电索引器 :DSA的核心组件,轻量级的索引机制,快速计算token重要性分数以供稀疏选择。深度思考模式 :DeepSeek的推理增强模式,进行链式推理和逐步分析,适合复杂任务。函数调用 :DeepSeek模型调用外部工具的能力,V3.1支持严格模式确保输出符合预定格式。上下文长度 :模型能处理的文本长度,V3.1扩展至128K,V3.2-Exp在华为云部署支持160K。后训练 :Post-Training,模型预训练后的优化阶段,包括监督微调、奖励模型训练等。TPM :Tokens Per Minute,每分钟处理token数,衡量API并发处理能力。工具调用 :Tool Calls,模型使用外部工具(如搜索、计算、查询)的能力。模型蒸馏 :用大模型训练小模型的技术,DeepSeek开源模型支持此操作。智能体 :Agent,能自主判断、调用工具并完成任务的高级AI形态。API定价策略 :DeepSeek的差异化定价,缓存命中时成本极低,促进大规模应用。
感谢您耐心阅读本文。希望本文能为您提供有价值的见解和启发。如果您对《深入探索DeepSeek最新版本,1024程序员节全面技术评测》有更深入的兴趣或疑问,欢迎继续关注相关领域的最新动态,或与我们进一步交流和讨论。让我们共同期待[如何使用 DeepSeek 帮助自己的工作]在未来的发展历程中,能够带来更多的惊喜和突破。
再次感谢,祝大家1024程序员节快乐!