
人工智能(AI)基础:怎么构建企业级机器学习系统?

我的这篇文章涵盖了构建生产级人工智能基础设施系统所涉及的高级架构模式、性能优化策略以及关键的运维考量!
引言
在企业环境中扩展人工智能工作负载,仅靠强大的算法远远不够——它需要稳健、企业级的人工智能基础设施。随着数据量和模型复杂度的不断增长,高效管理计算、存储和网络资源的能力已成为关键任务。
人工智能基础设施在确保机器学习运维(MLOps)成功方面发挥着核心作用。从调配GPU等专用硬件,到构建分布式系统以实现无缝的数据流转,底层架构直接决定了AI应用的效率、可靠性和可扩展性。一些战略性架构决策,例如采用容器化技术以提升灵活性,或设计可扩展的存储解决方案,都会对整体性能产生重大影响。
本文将深入探讨构建企业级AI基础设施系统所必需的关键架构组件与运维策略。文章面向基础设施工程师和机器学习平台架构师,提供关于资源编排、容错能力和可扩展性等方面的实用指导——这些正是打造面向未来的AI基础设施的基石。
核心架构组件
计算资源管理
现代GPU是AI工作负载的基石,为机器学习和深度学习模型的训练与推理提供了所需的强大并行处理能力和卓越吞吐量。这些处理单元专为应对AI基础设施中的计算密集型操作而设计,例如矩阵乘法和卷积运算。
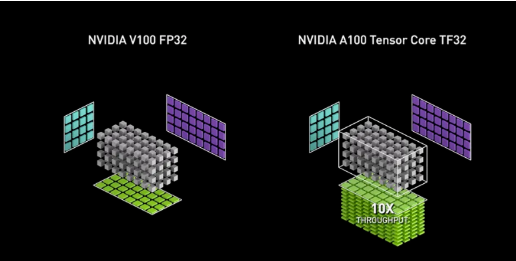
现代GPU的关键架构进步包括用于加速矩阵乘法的Tensor Core、用于高速数据传输的高带宽内存(HBM),以及支持多GPU扩展的技术,如NVLink和PCIe Gen5。这些特性使得大规模机器学习模型能够在分布式数据中心中高效运行,从而满足实时推理系统和AI开发流水线日益增长的计算需求。
对HBM感兴趣可以看这篇文章:高带宽内存(HBM)的概念、架构与应用
硬件加速需求:
人工智能系统在大规模模型训练任务中极大地受益于硬件加速。现代GPU(如NVIDIA A100、V100和AMD MI250)针对机器学习操作进行了优化,具备Tensor Core加速、共享内存以及NVLink等高速互连能力。这些特性显著缩短了训练时间,并提升了整体吞吐量。
下表为不同GPU架构的对比:
GPU型号 | Tensor Core | 内存带宽 (GB/s) | 计算性能 (TFLOPS) |
|---|---|---|---|
NVIDIA A100 | 是 | 1555 | 19.5 |
NVIDIA V100 | 是 | 900 | 15.7 |
AMD MI250 | 否 | 1638 | 22.0 |
Google TPU v4 | 不适用 | 不适用 | 27.0 |
处理单元的选择对训练时间、推理速度和成本优化策略具有重大影响。TPU通常更适用于基于云的环境以及TensorFlow等深度学习框架,而GPU则因其在PyTorch等平台上的广泛兼容性而更受青睐。
内存规格建议:
- 每块GPU最低显存(VRAM)要求:中等复杂度工作负载需16 GB;大语言模型(LLM)和生成式AI则需40–80 GB
- 多GPU节点的共享内存池:每节点至少配备512 GB系统内存,以实现高效的通信与内存共享
- 带宽要求:视觉和语言模型的训练建议内存带宽超过800 GB/s
通过采用专用GPU、内存优化配置以及智能编排工具,企业能够加速模型开发、缩短训练周期,并大规模部署高性能AI应用。在构建稳固的计算架构之后,下一步便是确保数据能像被处理一样高效地输入系统——这正是分布式存储系统的用武之地!
分布式存储系统
当AI系统规模扩大后,底层数据存储架构的重要性日益凸显。分布式文件系统是支撑大规模AI工作负载的基础,可确保高效的数据访问和高吞吐量。HDFS、Ceph和Lustre等架构提供了强大的数据分发、复制和容错机制。这些系统利用元数据服务器来管理跨存储节点的文件分配,同时保持良好的可扩展性。
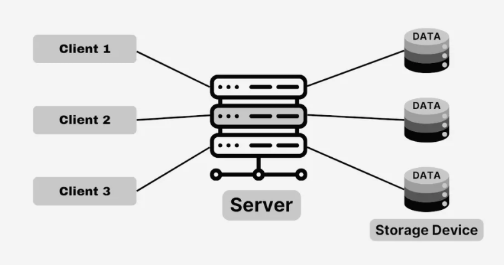
这些存储架构包含用于处理命名空间操作的元数据服务器,以及多个负责存储数据块的数据节点。通过数据复制实现冗余,而数据分片(sharding)与负载均衡则确保系统在大规模场景下仍能维持高性能。
数据局部性优化技术:
AI工作负载的性能与通过优化数据局部性来降低延迟的能力密切相关。常用技术包括:
- 将计算节点部署在靠近存储集群的位置
- 采用智能分片算法,将数据与相关计算任务协同放置(co-locate)
- 利用SSD或NVMe等高速存储介质构建缓存层,将热点数据更靠近处理单元
这些技术可有效减轻网络负载,并提升训练流水线的效率,尤其适用于自动驾驶和欺诈检测等实时应用场景。
性能基准测试指标:
评估分布式存储系统的关键指标包括:
- 吞吐量(Throughput):以MB/s或GB/s衡量,对大规模数据摄入和模型训练至关重要
- 延迟(Latency):访问关键训练或推理文件时应低于10毫秒
- IOPS(每秒输入/输出操作数):AI应用部署和MLOps流水线中的随机访问通常需要数千至数百万IOPS
不同机器学习工作负载的特定存储需求:
- 大模型训练:高吞吐量的NAS/SAN系统、RAID 10配置、冗余SSD集群
- 推理系统:低延迟SSD、内存分层缓存、预热(pre-warmed)的模型存储
- 数据预处理流水线:支持对原始文件的批量访问、压缩格式(如gzip、Parquet)支持,以及高速解压引擎
分布式存储的核心在于性能、可靠性以及与AI工作流的深度契合。一个合适的存储系统能够实现向GPU的无缝数据流传输,支持大规模模型检查点保存,并在AI生命周期的各个阶段为AI工具提供强大支撑。在存储优化完成后,构建稳健AI基础设施的最后一根支柱便是具备高可靠性和低延迟特性的网络系统。
网络基础设施
在企业级AI系统中,网络充当通信骨干——连接计算节点、存储系统以及负责管理从模型训练到实时推理全过程的编排层。糟糕的网络设计会引入瓶颈,严重制约系统的可扩展性并降低整体性能,尤其是在运行大规模机器学习流水线的数据中心环境中。
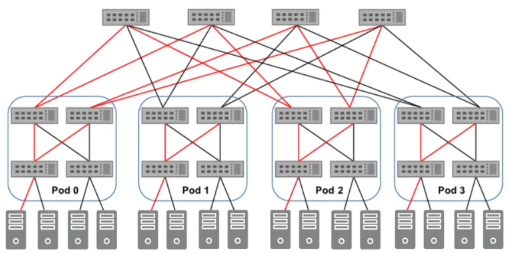
现代网络拓扑结构,如胖树(fat-tree)、网状(mesh)和叶脊(leaf-spine)架构,常被用于满足这些需求。其中,胖树架构因其可预测的性能和容错能力而备受青睐,非常适合需要在应用、服务和用户之间每秒处理数百万次操作的可扩展AI基础设施。
带宽优化技术:
在高速分布式计算环境中,带宽不仅需要充足,还必须被智能分配。常见的优化策略包括:
- QoS(服务质量)策略:优先保障关键流量,例如模型参数更新和检查点同步
- 自适应负载均衡:确保数据在高容量网络路径上均匀分布
- 压缩与解压算法:减小大规模数据集传输时的数据体积
延迟考量:
低延迟网络对于实时模型同步以及最小化AI应用中的响应延迟至关重要,这要求:
- 通过机架顶部(Top-of-Rack)和叶脊(leaf-spine)设计减少节点间互连延迟
- 集成支持RDMA(远程直接内存访问)的智能网卡(Smart NIC),实现零拷贝数据传输
- 在高性能计算(HPC)集群中部署低延迟交换机,如InfiniBand
网络协议及其应用场景对照表:
协议 | 应用场景 |
|---|---|
TCP | 训练任务中的可靠数据传输 |
UDP | 高速、低延迟的数据流 |
RDMA | 高性能计算(HPC)中的直接内存访问 |
gRPC | 微服务之间的通信 |
HTTP/HTTPS | 基于Web的AI服务 |
网络技术规格要求:
- 带宽:节点间通信最低需10 Gbps,高性能系统可扩展至100 Gbps
- 延迟:集群内部通信延迟需低于1毫秒
- 丢包率:低于0.01%,以避免在分布式训练任务中造成显著性能下降
- 抖动(Jitter):实时推理系统中需控制在1毫秒以下,以确保性能一致性
此外,对于基于云的AI平台,云服务商通常提供软件定义网络(SDN)解决方案,支持动态扩缩容和租户间隔离——这对于承载从医疗健康到自动驾驶等多样化应用场景的共享数据中心环境至关重要。
实施与部署
容器化策略
现代AI基础设施高度依赖容器化技术,以屏蔽底层系统依赖、隔离资源,并在不同环境中实现标准化部署。容器为运行机器学习模型、数据预处理任务和AI应用提供了轻量级、可移植的运行环境。目前,容器化系统的事实标准编排工具是Kubernetes,它支持自动扩缩容、容错机制和基于资源感知的调度策略——这些功能对于管理动态变化的AI工作负载至关重要。
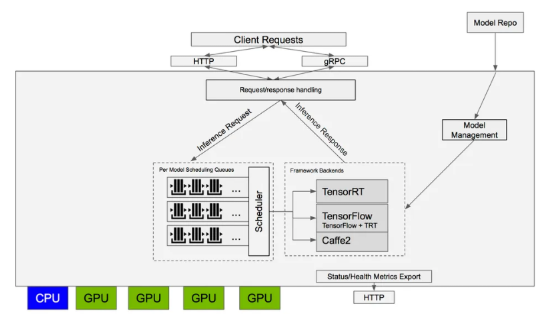
Kubernetes 还能与 CI/CD 流水线、MLOps 平台以及 TensorFlow Serving、TorchServe 和 NVIDIA Triton Inference Server 等主流框架无缝集成。
Kubernetes 配置示例:
以下是一个使用容器编排运行 AI 工作负载的基础部署清单(Deployment manifest):
该配置确保 AI 应用拥有足够的内存和 CPU 资源以稳定运行,同时允许 Kubernetes 在多个节点上自动管理扩缩容和故障恢复。
资源配额管理:
Kubernetes 通过在命名空间(namespace)级别定义配额来保障资源使用效率,使管理员能够为特定应用分配计算和内存资源。以下是在命名空间中设置资源限制的示例:
配额机制有助于系统管理员在共享的 AI 系统中维持公平性和可预测性,尤其在同时运行多个 AI 工作负载时尤为重要。
容器镜像优化:
容器优化的最佳实践之一是减小镜像体积并降低运行时开销。以下是一个使用 Docker 多阶段构建(multi-stage build)的示例:
通过使用精简的基础镜像(如 Alpine 或 Slim),并在最终镜像中排除构建工具,可显著缩小攻击面并缩短启动时间——这对在生产环境中部署实时 AI 应用至关重要。
容器化简化了部署流程,提升了可复现性,并增强了现代 AI 系统的可扩展性!以 Kubernetes 为核心,企业能够对容器化的 AI 解决方案实现细粒度的资源控制和弹性伸缩策略。而迈向更高阶运维成熟度的下一步,则是借助结构化的编排工具,对 AI 工作负载进行端到端的监控与自动化管理!
流水线编排(Pipeline Orchestration)
在真实的 AI 基础设施中,单次训练或推理任务很少孤立运行。相反,这些任务通常是更复杂工作流的一部分,涵盖数据摄入、清洗、转换、模型训练、验证、部署和监控等环节。Apache Airflow、Prefect 和 Kubeflow Pipelines 等编排工具为自动化这些流水线提供了框架。它们确保每个阶段按正确顺序执行,并内置容错机制与实时监控能力。
数据流水线优化技术:
为提升机器学习流水线的效率与容错能力,可采用以下技术:
- 并行化(Parallelization):并发执行多个任务(例如数据切片、超参数调优)
- 检查点(Checkpointing):保存中间状态,避免故障后重复已完成的步骤
- 数据分区(Data Partitioning):将大型数据集分布到多个节点,加速处理
这些优化策略可显著缩短运行时间并增强系统韧性,尤其适用于大规模 AI 工作负载。
AI 流水线的可观测性与监控:
强大的监控工具对于保障 AI 流水线的可靠性与可追溯性至关重要。关键策略包括:
- 使用 ELK Stack、Fluentd 或 CloudWatch 等工具实现实时日志记录
- 在任务失败或指标越限时触发告警与通知
- 通过可视化仪表盘(如 Grafana、Airflow UI)追踪执行流程、耗时及性能瓶颈
这些能力确保从开发到部署的整个 AI 工作负载生命周期都具备充分的可见性。
Airflow DAG 配置代码示例:
这个简单的 DAG(有向无环图)体现了工作流组件的模块化与可复用性,而这正是持续训练、部署与监控等 AI 实践中的关键要素。
性能优化
资源利用率
AI 系统中的高效资源利用依赖于持续监控、优化以及对关键性能指标的严格遵循。通过实施高级优化技术,可在不牺牲性能或可扩展性的前提下,最大化资源使用效率。
一个经过良好优化的系统能够在单位资源下最大化产出,同时在负载波动时仍保持韧性与适应性。这对于支撑大规模 AI 工作负载至关重要——在这些场景中,实时处理、框架兼容性与 GPU 加速必须协同运作。
资源监控技术:
- 基于代理的监控(Agent-Based Monitoring):在每个节点上部署 NVIDIA DCGM、Node Exporter 或 Kube-state-metrics 等代理,实时追踪 GPU、CPU、内存、磁盘 I/O 和网络带宽的使用情况。
- 日志与可视化工具:使用 Prometheus、Grafana 和 Loki 收集、存储并展示遥测数据。将其与 Kubernetes 集群集成,可提供跨服务资源消耗的全局视图。
- 基于阈值的告警(Threshold-Based Alerts):通过 Alertmanager 或 Datadog 等工具配置告警规则,当计算、内存或 IOPS 超出预设阈值时及时通知运维团队,从而在性能下降影响用户前主动干预。
优化算法:
- 负载均衡(Load Balancing)
- 轮询(Round-Robin):按顺序分发工作负载,适用于无状态的 AI 应用。
- 最少连接(Least Connections):将任务分配给当前连接数最少的服务器,非常适合实时推理引擎。
- 任务调度(Task Scheduling)
- 最早截止时间优先(Earliest Deadline First, EDF):按任务截止时间排序,最大限度降低实时数据处理中的延迟。
- 最短作业优先(Shortest Job First, SJF):适用于可并行化的批量机器学习训练任务。
- 基于强化学习的优化(Reinforcement Learning-Based Optimization)
- 利用经过训练的强化学习(RL)智能体,根据观测到的性能动态分配 GPU、调整资源限制或重新调度工作负载——尤其适用于云环境与本地混合部署场景。
性能指标:
指标(Metric) | 说明(Description) |
|---|---|
计算利用率(Compute Utilization) | CPU/GPU 周期被实际使用的百分比 |
内存使用(Memory Usage) | 已使用内存与可用内存的占比 |
吞吐量(Throughput) | 每秒成功执行的任务数量 |
I/O 等待时间(I/O Wait Time) | 因等待 I/O 操作完成而产生的延迟 |
延迟(Latency) | 从输入到模型输出预测结果所需的时间 |
资源分配技术规范:
- CPU 分配:每项任务至少 4 核,高强度计算任务可扩展至 32 核
- GPU 分配:标准工作负载每任务 1 块 GPU;高性能训练采用多 GPU 配置
- 内存需求:每任务至少 8 GB,数据密集型操作可扩展至 64 GB
- 网络带宽:节点间通信最低需 10 Gbps,以避免成为性能瓶颈
扩缩容机制(Scaling Mechanisms)
扩缩容机制确保计算资源能根据工作负载需求动态增减,从而在最小化成本的同时最大化可用性。这一能力在云环境和智能边缘系统中尤为关键——这些场景中的使用模式可能剧烈波动。
主要存在两种扩缩容形式:
- 水平扩缩容(Horizontal Scaling):向集群中添加更多实例或节点
- 垂直扩缩容(Vertical Scaling):提升现有节点的容量(如 CPU/GPU/内存)
这两种方式通常通过 Kubernetes、AWS Auto Scaling 或 GCP Autoscaler 等平台原生的自动扩缩容框架实现。
负载均衡策略:
为确保资源均衡使用与容错能力:
- 轮询(Round-Robin):简单高效,能均匀分发请求
- 最短响应时间(Least-Response-Time):将新请求路由至响应最快的节点,降低实时 AI 应用的延迟
- 应用感知型负载均衡器(Application-Aware Load Balancers):利用应用元数据(如模型版本、资源需求)优先处理关键任务,非常适合多模型 AI 平台
容量规划方法:
- 工作负载画像(Workload Profiling):在不同条件下分析工作负载,识别资源峰值与瓶颈
- 历史使用趋势(Historical Usage Trends):利用机器学习预测未来需求,避免过度配置
- 预留资源池(Reserve Pooling):为关键业务预留未使用的资源缓冲区,防止流量激增时发生服务中断
技术基准指标:
- 扩缩容响应时间:云环境中水平扩缩容应在 30 秒内完成
- 负载分布效率:节点间工作负载分布均匀度不低于 90%
- 资源利用率:CPU 与内存利用率应维持在 60%–80%,为突发流量保留余量
- 吞吐量:大规模 AI 推理系统每秒至少处理 10,000 个请求
将上述扩缩容机制融入 AI 基础设施,有助于支撑持续交付流水线、自动故障转移以及生产级 AI 应用中的突发流量处理。
卓越运营(Operational Excellence)
监控与可观测性(Monitoring and Observability)
监控与可观测性是可持续 AI 运营的基石,它们提供对系统行为的深度洞察,实现实时异常检测,并支持对新兴问题的快速响应。这些实践对于可扩展的生产级部署至关重要——在这些环境中,数千块 GPU、容器和应用程序在分布式数据中心中协同运行。
监控栈组件(Monitoring Stack Components):
- 基于 ELK 栈的集中式日志(Centralized Logging with ELK Stack)
- Elasticsearch:对微服务产生的日志进行索引和全文搜索。
- Logstash:从 Kubernetes、容器和应用运行时等来源采集日志。
- Kibana:提供丰富的可视化功能,用于分析趋势和关联错误。
- Prometheus 用于指标采集(Prometheus for Metrics Collection)
- 按自定义间隔从服务暴露的端点(如
/metrics)拉取指标 - 监控 CPU、GPU、内存、磁盘 I/O 以及 AI 工作负载的实时吞吐量
- Grafana 用于可视化(Grafana for Visualization)
- 提供自定义仪表盘,展示基础设施健康状况、训练任务性能、延迟图表及异常趋势
- 支持告警、注释和模板功能,用于机器学习流水线的实时监控
指标采集方法(Metrics Collection Methods):
- 基于代理的采集(Agent-Based Collection)
- 工具如 Node Exporter、DCGM Exporter 和 Telegraf 以 Kubernetes DaemonSet 形式运行,采集节点级和 GPU 特定的指标。
- 推送式监控(Push-Based Monitoring)
- 适用于自定义应用和自动化脚本,通过 API 将指标推送到中心化的时间序列数据库。
- 采样技术(Sampling Techniques)
- 自适应采样:用于高频指标(如 GPU 温度、推理延迟)
- 固定速率采样:用于稳定指标(如磁盘使用率、网络吞吐量)
告警策略(Alerting Strategies):
- 基于阈值的告警(Threshold-Based Alerts)
- 当指标超出预设阈值时触发告警,例如:GPU 内存使用率 > 90%,或推理延迟 > 200 毫秒。
- 升级策略(Escalation Policies)
- 分级通知机制:先通知 DevOps 团队,再通知值班工程师,最后升级至 SRE 负责人
- 支持与 PagerDuty、Slack、Opsgenie 或 Microsoft Teams 集成
- 自动响应(Automated Response)
- 根据告警严重程度触发修复脚本(如自动重启 Pod、横向扩容节点)
监控工具对照表(Table of Monitoring Tools):
工具(Tool) | 用途(Purpose) | 核心特性(Key Features) |
|---|---|---|
Prometheus | 指标采集 | 实时数据抓取与告警 |
Grafana | 可视化 | 自定义仪表盘与分析 |
ELK Stack | 集中式日志 | 全文搜索与过滤 |
PagerDuty | 事件管理 | 自动化告警升级 |
监控需求技术规范(Technical Specifications for Monitoring Requirements):
- 采样频率:高优先级指标至少每秒采样一次
- 告警延迟:确保在指标越限后 5 秒内发出告警
- 存储保留期:日志与指标至少保留 30 天,以支持历史分析
- 系统覆盖率:监控 100% 的计算节点,以及至少 95% 的网络流量
借助实时洞察与自动化告警,运维团队无论面对何种规模或复杂度的 AI 应用,都能保障其可用性与性能。
安全与访问控制(Security and Access Control)
鉴于敏感数据、关键模型和高价值知识产权面临的风险,安全与访问控制已成为现代 AI 基础设施不可妥协的支柱。随着组织采用云原生、混合及本地部署的 AI 解决方案,攻击面不断扩大——因此,必须一致地执行访问策略、加密标准和合规协议。
一套健全的安全策略应覆盖 AI 全生命周期(从开发到部署)中的安全认证、数据加密、基于角色的访问控制(RBAC)和流量管控。
安全架构(Security Architecture):
- 纵深防御(Defense-in-Depth)
- 应用层:Web 应用防火墙(WAF)、输入验证、安全编码
- 网络层:防火墙、VLAN 隔离、IP 白名单
- 基础设施层:操作系统加固、访问控制、补丁管理
- 零信任架构(Zero-Trust Architecture)
- 网络内部默认不信任任何实体——即使内部系统也需认证
- 持续验证身份、位置和设备健康状态
- 基于角色的访问控制(RBAC)
- 定义角色(如数据科学家、机器学习工程师、平台管理员)
- 为数据集访问、模型部署和集群配置分配细粒度权限
认证机制(Authentication Mechanisms):
- 多因素认证(MFA)
- 在密码登录基础上增加第二重验证,降低暴力破解和钓鱼攻击风险。
- OAuth 2.0 集成
- 为 AI 平台中的 REST API、CLI 工具和微服务提供基于令牌的访问控制。
- 单点登录(SSO)
- 在整个生态系统中统一用户访问入口,同时集中管理用户身份与审计日志。
加密协议(Encryption Protocols):
- 静态数据加密(At Rest)
- 所有存储数据使用 AES-256 加密
- 使用密钥管理服务(KMS)实现集中化的密钥轮换
- 传输中数据加密(In Transit)
- 所有节点间、外部 API 及云服务之间的数据传输强制使用 TLS 1.3
- 在容器化环境中使用双向 TLS(mTLS)实现服务间身份认证
- 端到端加密(E2EE)
- 保护边缘设备与中心推理服务器之间交换的敏感模型预测结果和实时推理数据
安全需求技术规范(Technical Specifications for Security Requirements):
- 访问日志:至少保留 90 天,并对未授权访问尝试自动告警
- 密钥管理:使用集中式 KMS 并支持自动轮换
- 合规标准:符合 GDPR、HIPAA 或 ISO 27001 等行业规范
- 防火墙规则:明确定义入站与出站流量规则,阻止未授权连接
通过实施分层安全策略、贯彻零信任原则,并在技术栈各层级集成加密机制,组织可在保障 AI 开发速度与敏捷性的同时有效降低安全风险。
结论
企业级 AI 系统的开发需要周密的架构规划,以确保强大的性能与可扩展性。关键决策包括:
- 利用分布式存储系统实现高吞吐数据访问
- 采用自动扩缩容机制动态管理工作负载
- 部署全面的监控栈以提升运维可见性
成功取决于战略性资源分配、安全的数据传输,以及网络与计算资源的无缝集成。下一步可操作建议包括:
- 开展全面的基础设施审计以识别瓶颈
- 部署容器化解决方案以提升部署效率
- 实施主动式告警机制以维持系统可靠性
常见问题解答
Q. 扩展 AI 系统的关键考虑因素有哪些?
A. 扩展 AI 系统需平衡计算、存储和网络资源。自动扩缩容与负载均衡策略对于处理动态工作负载至关重要。
Q. 高级 AI 与传统 AI 模型有何区别?
A. 高级 AI 包括深度神经网络、生成式模型等,能够执行复杂任务,如自动驾驶导航、自然语言理解,以及在实时环境中进行预测性决策。
Q. 如何优化 AI 基础设施中的资源利用率?
A. 优化手段包括:使用高级算法进行动态资源分配、设置资源配额,以及利用 Prometheus 等监控工具追踪实时性能指标。
Q. 企业部署 AI 基础设施的定价受哪些因素影响?
A. 定价取决于硬件规格(如 GPU、TPU)、可扩展性需求、数据管理要求以及软件许可成本——尤其是在将开源工具与专有编排或安全层结合使用时。
Q. AI 基础设施的核心组件有哪些?
A. 包括计算资源(CPU/GPU/TPU)、存储系统(如对象存储)、网络互连、编排平台、监控工具,以及用于高效管理 AI 全生命周期的安全 API。
