
LangChain1.0速通指南(二)——LangChain1.0 create_agent api 基础知识


前言
上篇分享LangChain1.0速通指南(一)——LangChain1.0核心升级笔者分享了Langchain1.0三大核心升级:全新智能体构建 API create_agent、标准化内容块接口和精简的包结构。从笔者的分享中大家也能感受到在这些新特性中,create_agent 作为新一代智能体构建的标准 API,凭借其灵活的中间件机制和内置的结构化输出能力,不仅大幅提升了开发效率,也进一步拓展了智能体的功能边界。本期分享开始笔者将正式讲解create_agent, 本篇将聚焦于 create_agent 的基本使用方法,帮助大家快速掌握这一核心 API 的基础操作。
一、环境搭建
LangChain 1.0 的环境搭建过程较为简单。笔者推荐使用 anaconda 创建一个新的虚拟环境(这里命名为 langchainenvnew),并建议将 Python 版本设置为 3.12 。创建环境的命令如下:
环境创建完成后,安装本实验所需的依赖包。请执行以下命令:
完成上述步骤后环境准备就绪,接下来开始编写今天的代码。
二、create_agent三要素:提示词,大模型和工具函数
在笔者文章深入浅出LangGraph AI Agent智能体开发教程(二)—LangGraph预构建图API快速创建Agent中提到,要利用create_react_agent api 构建一个基础的智能体,提示词,大模型和工具函数三要素必不可少。作为升级版,create_agent 同样基于这三个要素构建。接下来笔者使用经典的天气助手案例为大家详细说明create_agent的基本使用方法。
1. 首先导入代码所需依赖,并通过自定义函数的方式编写一个模拟天气查询函数,注意工具函数必须包含清晰的函数说明,这是大模型判断是否调用自定义函数的重要依据。从依赖包的导入方式大家可以看出langchain的依赖包命名更加简洁明了。
2. 现在已经具备了工具函数,接下来需要准备提示词和大语言模型,然后使用这三要素创建智能体:
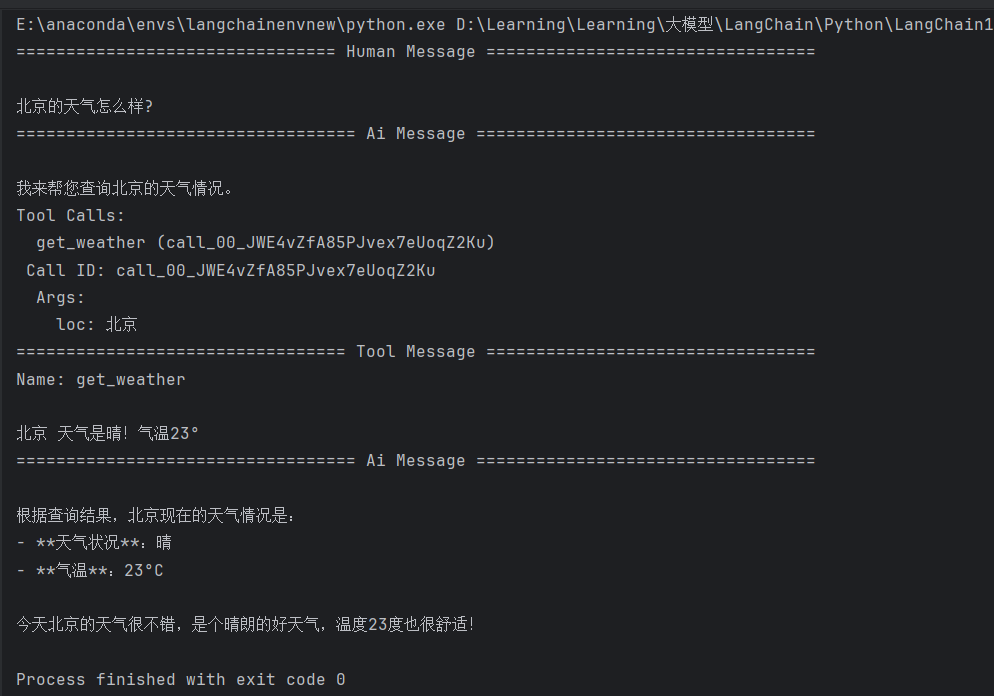
3. 编写问题"北京天气怎么样"来测试智能体,并使用 agent.stream 方法实现流式输出,通过 pretty_print() 方法格式化显示每次的输出结果:
4. 运行上述代码后,我们可以清晰地观察到 LangChain 1.0 智能体的完整执行流程:
- 用户提问
- 接收到问题"北京天气怎么样"
- 模型分析
- 大语言模型识别出自身无法直接回答,决定调用工具函数
get_weather,并自动生成调用参数{loc: 北京} - 工具执行
- 执行工具函数并获取返回结果
- 结果整合
- 大语言模型根据工具函数的执行结果,生成格式化的最终回答
三、模型与消息机制
3.1 LangChain模型支持
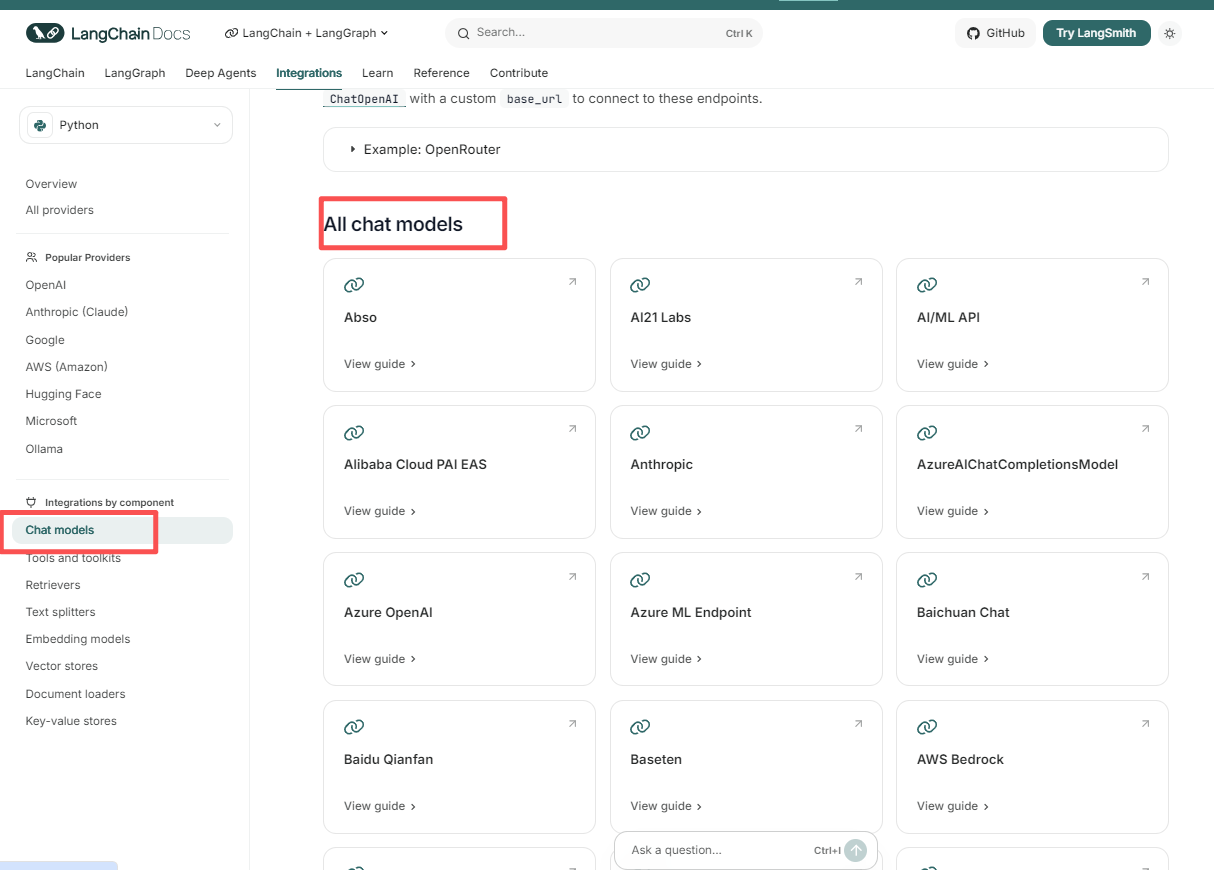
在上述代码中,笔者使用了 DeepSeek 模型。LangChain 1.0 已经集成了超过 100 个模型供应商,为开发者提供了极大的灵活性。不同模型的具体使用方法都可以在 LangChain 官网的 Chat 模型集成页面 找到详细的文档说明,包括我们上面使用的DeepSeek 模型配置方法:
现代大语言模型(LLMs)不仅能够生成文本,还支持多种高级功能,包括工具调用(调用外部工具如数据库查询或API)、结构化输出(使模型响应遵循预定义格式)、多模态处理(处理图像、音频等非文本数据)以及多步推理能力。
3.2 LangChain消息类型解析
观察前面程序的运行结果,可以看到 create_agent 执行过程中产生了多种类型的消息。LangChain 定义了一套完整的消息类型系统,主要包括以下几种
- SystemMessage
- 系统消息,用于设定智能体的角色定位与工具能力。精心设计的系统提示对智能体性能至关重要,它可以定义模型行为、回复风格,并对应答格式进行约束。
- HumanMessage
- 人类消息,通常是用户的初始提问,也可以是必要的反馈或人为干预(例如决定是否继续执行特定操作)。
- ToolMessage
- 工具消息,封装了函数调用结果的相关数据,显示工具调用的执行结果。
- AIMessage
- AI消息,包含大模型生成的所有响应内容。
create_agent 的消息管理机制与笔者在 深入浅出LangGraph AI Agent智能体开发教程(八)—LangGraph底层API实现ReACT智能体 中讲解的 messages 系统一脉相承。所有对话产生的历史消息都会被智能体完整保存下来,形成完整的对话上下文。智能体在决策时会综合分析所有历史消息,包括原始问题、工具调用记录和观察结果,并基于这些信息进行逐步推理。这种设计使得 create_agent 智能体天然具备多轮对话的能力,能够处理复杂的多步骤任务。
3.3 消息的多种表示方式
在实际编码中,LangChain 提供了灵活的消息表示方法。前面程序中的输出代码实际上是 HumanMessage(question) 的简写形式:
除了直接使用消息对象外,还可以使用字典来表示消息,这种情况下需要明确指定消息的角色类型:
其他类型的消息用字典表示的格式如下:
3.4 消息的元数据与详细信息
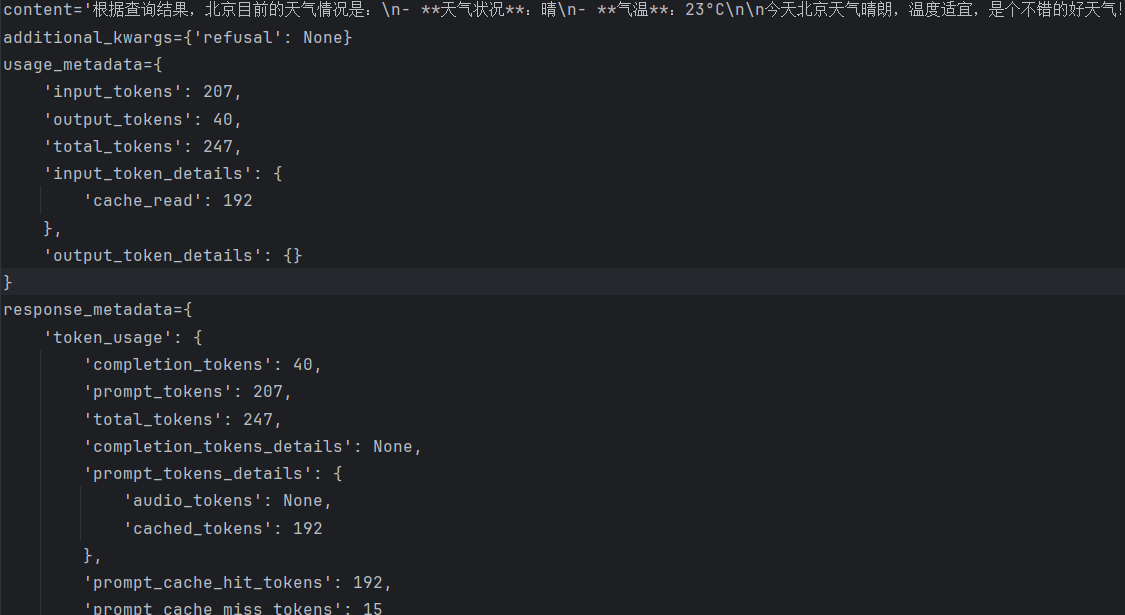
前面程序中使用的 pretty_print() 方法用一种美观的格式展示了不同消息的内容,但实际上每条消息都包含了丰富的元数据信息。如果改用以下代码:
查看输出的最后一条消息,可以看到 messages 消息列表中返回了详细的内容结构:其中content是模型的主要输出内容,usage_metadata包含了输入输出token的使用量统计,response_metadata包含了更详细的输入输出信息包括令牌使用,模型提供商,模型名称等。这些丰富的元数据为开发者监控智能体行为、优化性能和分析成本提供了宝贵的信息基础。
四、流式输出模式详解
在大语言模型或交互式智能体的应用中,由于计算复杂度较高,常常会遇到显著的响应延迟。为了提升用户体验,LangChain 提供了多种流式传输模式,让用户能够逐步获取生成内容,而不是等待完整响应。
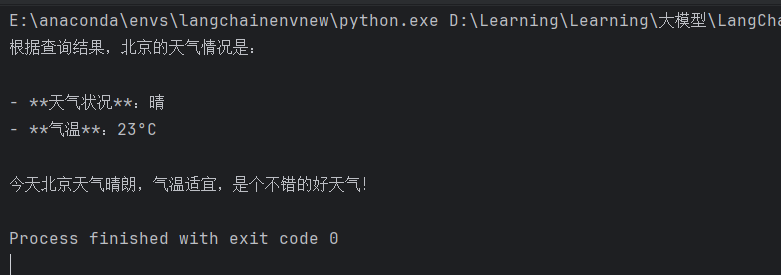
4.1 不使用流模式
不使用流模式采用invoke方法,在这种情况下会等到产生最终结果后一次性显示出来,而不是逐个token传输:
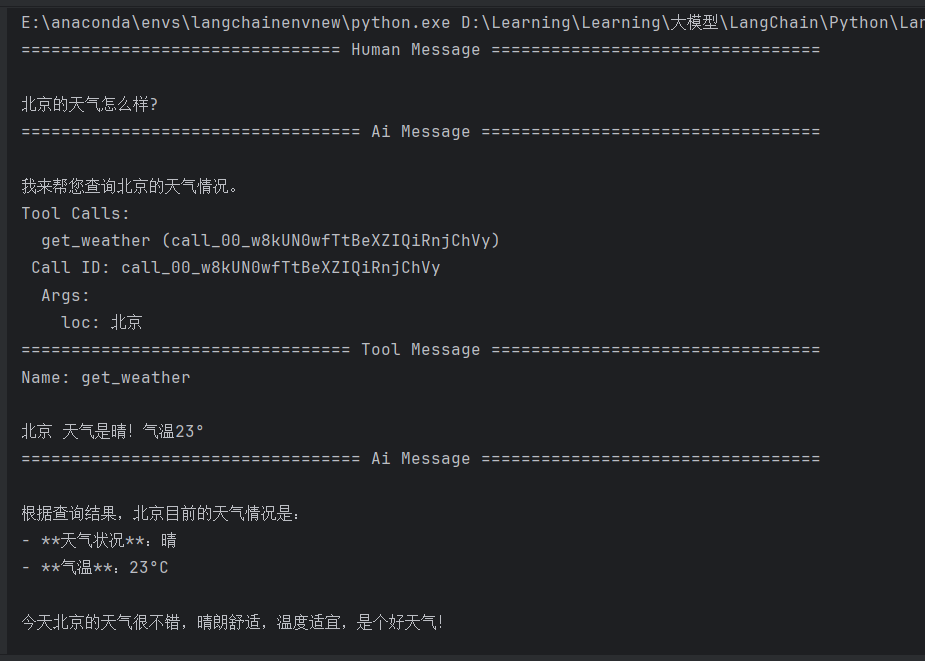
4.2 值流模式
上面的示例程序中使用的是值流模式,该模式会在智能体的每个执行步骤完成后传输中间数据,让开发者能够观察到完整的决策过程,如上例所示,值流模式会分四次更新数据:HumanMessage(用户输入)、AIMessage(模型初始响应)、ToolMessage(工具调用结果)和最终的AIMessage(总结回答)。
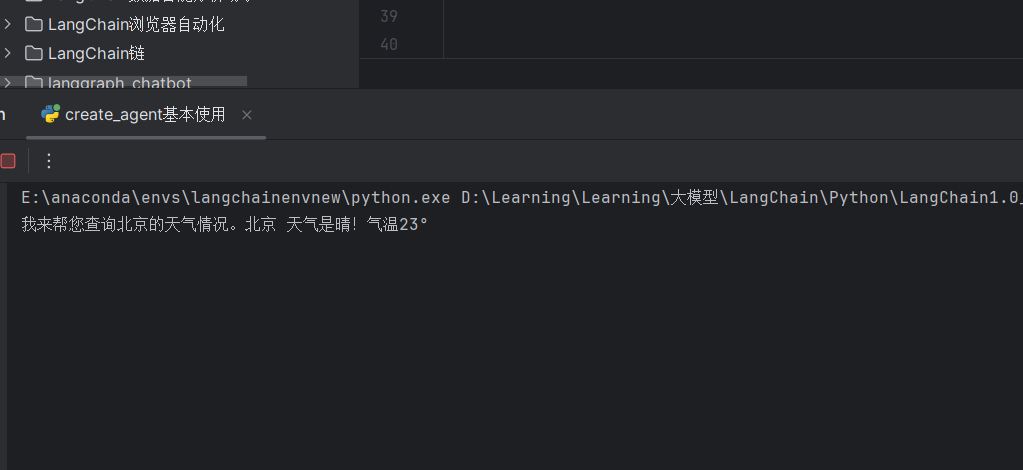
4.3 消息流模式
消息流模式会将模型的最终响应内容逐个token输出,而不是分步输出。
4.4 自定义模式
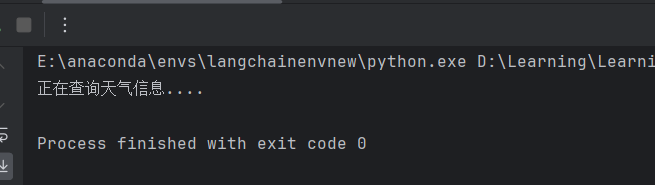
LangChain 还支持用户自定义流式传输,特别是在工具函数中插入自定义的输出内容。通过 get_stream_writer 可以获取图的流式传输对象,当流模式设置为 custom 时,输出将只包含在工具函数中自定义的内容:
流模式还支持以数组形式指定多个模式,实现同时输出多种类型的内容:
可以看到,除了 values 模式的四个标准输出外,在工具函数调用阶段还输出了我们自定义的内容。系统通过元组对象对 values 和 custom 输出进行区分:

自定义流式传输的核心优势在于:用户能够在数据逐步生成的过程中就进行自定义处理(例如在工具函数中感知执行阶段),而无需等待所有内容生成完毕。这显著提升了应用的响应速度和用户体验。
五、总结
本篇深入解析LangChain 1.0的create_agent API,涵盖环境搭建、智能体三要素(提示词、模型、工具函数)、消息类型及四种流模式。通过天气助手实例演示智能体完整执行流程,帮助大家快速掌握新一代智能体开发标准。当然本文讲述的仅仅是create_agent的基础使用,这次更新还有更多的核心特性尤其是中间件机制,下期内容我们接着分享,大家敬请期待!
