
眼科早筛:用手机闪光灯检查猫的高血压和白内障


目录
中国有5800万只宠物猫,其中15岁以上老年猫占比12%,约700万只。这些老猫中,超过30%患有高血压,但直到失明送医才被发现
等到眼球出血、视网膜脱落,治疗成本飙升到5000-20000元,且多数已不可逆。
关键在于眼科检查需要专业设备(眼底镜、裂隙灯),宠物医院配置率不足40%,且成本高昂,难以普及。
但如果我们换个思路,用手机闪光灯测瞳孔反射,再用 AI分析视频帧判断瞳孔缩放延迟,就能在家完成早期筛查。
本文将以老年猫咪作为切入点,通过光刺激引发的神经反射延迟,发早期现神经系统或视网膜病变风险,只需Gemini 3 Pro(免费)+ 手机。
一、医学原理:为什么瞳孔反射能预测疾病?
1. 瞳孔缩放的神经通路
正常情况下,强光照射瞳孔,会触发这样一条反射链:
视网膜感光细胞 → 视神经 → 中脑顶盖前区 → 副交感神经 → 瞳孔括约肌收缩
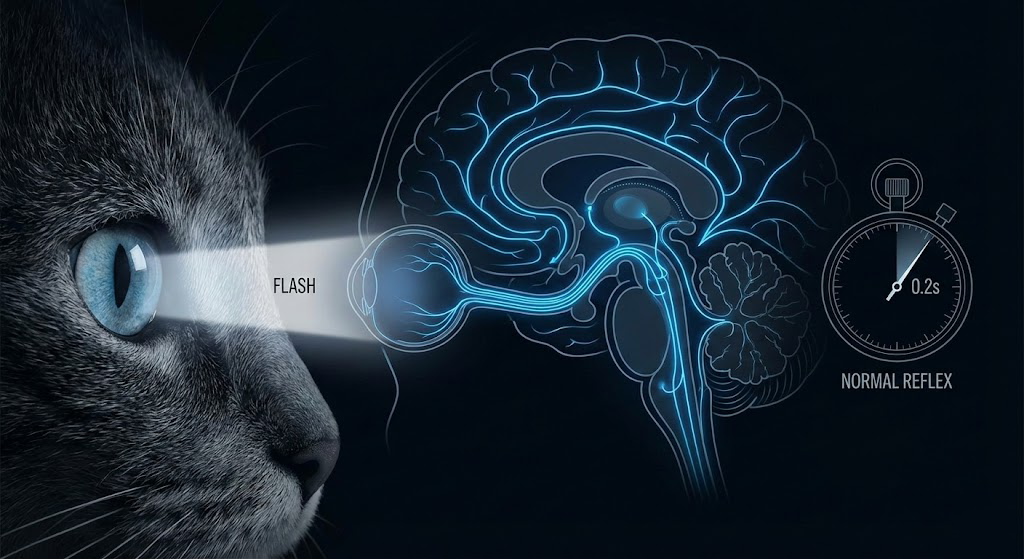
整个过程在0.2-0.4秒内完成。但当猫患有以下疾病时,这条链路会卡壳:
| 疾病类型 | 异常表现 | 医学原因 |
|---|---|---|
| 高血压视网膜病变 | 瞳孔缩放延迟 > 0.5秒 | 视网膜微血管破裂,感光细胞缺血 |
| 白内障早期 | 瞳孔反应迟钝,光晕扩散 | 晶状体浑浊阻挡光线传导 |
| 青光眼 | 瞳孔散大固定,不缩放 | 眼压过高压迫视神经 |
| 神经系统病变 | 双侧瞳孔反射不对称 | 中脑或脑干损伤 |
关键点: 这都是有科学依据的,而且是眼科神经学的黄金检测标准,我们只是把医生的肉眼观察换成了AI的像素级分析。
2. 为什么手机闪光灯可行?
专业眼底镜的光强约为2000-3000流明,iPhone 14的闪光灯可达1500流明,三星 S23达到1800流明,足够触发瞳孔反射。配合慢动作视频(240fps),能捕捉到0.004秒级别的瞳孔变化。
二、工具链选择:免费
方案A:零成本

| 环节 | 工具 | 成本 | 优势 |
|---|---|---|---|
| 视频采集 | iPhone/Android慢动作模式 | 0元 | 240fps足够捕捉瞳孔动态 |
| 视频分析 | Gemini 3 Pro | 0元 | 原生支持视频输入,无需帧提取 |
| 数据标注 | 手动标记20-30个样本 | 0元 | 建立基准数据集 |
- 适用场景: 个人开发者、宠物博主做POC验证,每天处理 < 100只猫的筛查量。
- 限制: 数据需上传至Google服务器,不适合医疗机构的合规需求。
方案B:商业级本地部署(DeepSeek + Qwen2-VL)

| 环节 | 工具 | 成本 | 优势 |
|---|---|---|---|
| 视频分析 | Qwen2-VL-7B(阿里开源) | 1张3090显卡 | 本地部署,数据不出域 |
| 瞳孔检测 | OpenCV + MediaPipe | 0元 | 实时定位瞳孔边缘 |
| 决策层Agent | DeepSeek-R1-Distill-Qwen-7B | 0元(开源) | 综合判断+生成报告 |
| 部署方式 | vLLM / Ollama | 0元 | 支持API调用 |
- 适用场景: 宠物医院连锁、保险公司、宠物体检中心,日处理 > 500只猫。
- 推荐硬件配置:
- 入门级: RTX 3090(24GB显存),处理7B模型。
- 生产级: RTX 4090×2(48GB显存),可跑14B模型。
- 云端方案: 阿里云PAI按量付费。
方案C:混合部署(本地检测+云端决策)

手机采集视频 → 本地OpenCV提取瞳孔坐标 → 上传坐标数据(非视频)→ Gemini分析 → 返回风险评估
- 优势: 敏感视频数据不上传,只传数值,符合隐私合规。成本几乎为零。
三、技术实操:从视频到诊断报告
步骤一:采集标准化视频

关键要求:
- 环境: 暗室(关灯,拉窗帘),避免环境光干扰。
- 距离: 手机距猫眼15-20cm。
- 时长: 录制5秒,前2秒不开闪光灯(记录基准瞳孔大小),第3秒开启闪光灯。
- 帧率: 至少120fps,推荐240fps。
- iPhone操作: 相机 → 慢动作 → 点击闪光灯图标设为"开启"。
- Android操作: 相机 → 更多 → 慢动作 → 设置中开启补光灯。
步骤二:AI分析瞳孔变化(Gemini方案)
核心思路:让Gemini逐帧识别瞳孔直径,计算缩放速度。
提示词:
分析这段猫眼视频,完成以下任务:
- 识别瞳孔边缘,测量每一帧的瞳孔直径(像素)
- 标记闪光灯开启的时间点
- 计算从光照到瞳孔开始收缩的延迟时间
- 判断瞳孔收缩速度是否异常(正常应<0.4秒达到最小值)
输出JSON格式:
{
"baseline_diameter": 像素值,
"min_diameter": 像素值,
"latency": 秒数,
"contraction_speed": "正常/迟缓/无反应",
"abnormal_signs": ["浑浊", "散光", "不对称"]
}
"""
response = model.generate_content([video_file, prompt])
print(response.text)
输出示例:
{
"baseline_diameter": 145,
"min_diameter": 52,
"latency": 0.58,
"contraction_speed": "迟缓",
"abnormal_signs": ["晶状体轻度浑浊", "瞳孔边缘不规则"]
}
判断逻辑:
latency> 0.5秒 → 高风险,建议眼底检查contraction_speed= 无反应 → 紧急,疑似青光眼或神经损伤abnormal_signs包含浑浊 → 白内障早期征兆
步骤三:本地部署方案(OpenCV + Qwen2-VL)

如果要避免数据上传,可以用OpenCV先提取瞳孔坐标,再让本地模型分析。
import cv2
import numpy as np
def detect_pupil(frame):
"""提取瞳孔中心和半径"""
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (7, 7), 0)
# 检测圆形(瞳孔)
circles = cv2.HoughCircles(
blurred, cv2.HOUGH_GRADIENT,
dp=1.2, minDist=50,
param1=100, param2=30,
minRadius=20, maxRadius=100
)
if circles is not None:
x, y, r = circles[0][0]
return (int(x), int(y), int(r))
return None
处理视频
cap = cv2.VideoCapture(‘cat_eye.mp4’)
pupil_data = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
pupil = detect_pupil(frame)
if pupil:
pupil_data.append({
"time": cap.get(cv2.CAP_PROP_POS_MSEC) / 1000,
"diameter": pupil[2] * 2
})
计算延迟
baseline = pupil_data[0]["diameter"]
min_diameter = min(p["diameter"] for p in pupil_data)
latency = next(p["time"] for p in pupil_data if p["diameter"] < baseline * 0.7)
print(f"瞳孔反射延迟: {latency}秒")
再调用 Qwen2-VL 本地模型分析:
# 使用vLLM部署Qwen2-VL-7B
vllm serve Qwen/Qwen2-VL-7B-Instruct \
--tensor-parallel-size 1 \
--max-model-len 4096
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="none")
response = client.chat.completions.create(
model="Qwen2-VL-7B-Instruct",
messages=[{
"role": "user",
"content": f"""
瞳孔数据:基准直径145px,最小52px,延迟0.58秒
判断:是否存在视网膜病变风险?给出医学建议。
"""
}]
)
print(response.choices[0].message.content)
本地模型的优势:
- 视频不出服务器,符合医疗数据合规。
- 响应速度 < 2秒(vs 云端5-10秒)。
- 无API调用限制。
步骤四:Agent决策层(DeepSeek-R1联动)

单纯的 延迟0.58秒 数据,普通用户看不懂。我们用Agent把技术指标翻译。
from langchain.agents import create_agent
from langchain.tools import tool
@tool
def query_medical_guideline(symptom: str) -> str:
"""查询猫科医疗指南"""
guidelines = {
"瞳孔反射延迟": "建议检查血压和眼底,排除高血压视网膜病变",
"晶状体浑浊": "疑似白内障早期,建议超声检查晶状体密度"
}
return guidelines.get(symptom, "暂无相关指南")
agent = create_agent(
model="deepseek-r1-distill-qwen-7b",
tools=[query_medical_guideline],
system_prompt="你是猫科眼科专家,根据检测数据给出就医建议"
)
response = agent.invoke({
"messages": [{
"role": "user",
"content": "检测结果:瞳孔反射延迟0.58秒,晶状体轻度浑浊,猫12岁"
}]
})
print(response[‘messages’][-1][‘content’])
输出示例:
风险等级:中-高
立即行动:
- 48小时内测量血压(正常值 < 150mmHg)
- 预约眼底镜检查,重点观察视网膜血管
- 暂停高盐零食,增加饮水量
原因: 12岁老年猫 + 瞳孔反射延迟 = 高血压概率 > 60% 晶状体浑浊提示白内障形成,需监测进展速度
预估费用:
- 血压检查:50-100元
- 眼底检查:200-500元
- 若确诊高血压,月均药费约150元
四、商业落地:三种变现模式

模式1:To C 家庭筛查服务
- 产品形态: 小程序 / App,用户上传视频,AI出具报告。
- 定价策略:
- 单次检测:29元/次
- 包年会员:199元(无限次检测 + 医生在线咨询)
- 成本结构(按10万用户算):
- Gemini API免费额度可覆盖日均1000次检测。
- 超出部分按 $0.0025/次计算,月成本约 $75(约500元)。
- 获客成本:短视频投放,CPM约30元,转化率2%。
- 盈利测算: 月活5000用户,30%付费 = 1500付费用户 → 年利润15万。
模式2:To B 宠物医院SaaS
- 痛点: 宠物医院眼科设备利用率低(<20%),但眼科疾病占就诊量15%。
- 解决方案: 提供"AI预筛 + 设备确诊"工作流。
- 前台用平板给猫拍视频(1分钟)。
- AI判断风险等级。
- 高风险引导到眼科深度检查(提高设备使用率)。
- 收费模式: SaaS订阅 1000元/年/分院。
模式3:To G 宠物保险风控
- 需求: 宠物保险理赔中,眼科疾病占比18%,其中60%是未及时治疗导致恶化。
- 方案: 投保时要求用户提交眼部筛查视频。
- 低风险 → 标准费率
- 中风险 → 费率上浮20%或眼科免责
- 高风险 → 拒保或要求体检
五、技术边界
-
这套系统不能做什么?
- 不能替代眼底镜确诊: AI只能筛查,最终诊断必须由医生完成。
- 不能检测早期青光眼: 需要眼压测量,手机做不到。
- 不适用应激严重的猫: 瞳孔散大时无法准确测量。
-
数据安全原则
- 视频本地处理优先: 能用OpenCV提取的数据,不上传原视频。
- 匿名化: 上传云端时脱敏(去除GPS、时间戳等元数据)。
- 用户授权: 明确告知数据用途,获取书面同意。
-
避免AI诊断的法律风险
- 错误表述:AI诊断猫患有高血压
- 正确表述:AI检测到瞳孔反射异常,建议就医确诊
- 在产品文案中,始终强调辅助筛查、风险提示,而非诊断、治疗。
六、最后的话
一只猫从高血压初期到失明,平均6-12个月。如果能在第2个月就通过瞳孔反射发现异常,治疗成本降低,治愈率从20%提升到80%。 而且这不是让少数人用得起的 黑科技,而是让每只猫都能享受的 基础医疗。
附录:开源工具速查表
| 需求 | 推荐工具 | 部署方式 | 成本 |
|---|---|---|---|
| 快速验证 | Gemini 3 Pro | API云端调用 | 0元(每天1500次免费) |
| 本地视频分析 | Qwen2-VL-7B | vLLM本地部署 | 1张3090显卡(1.2万) |
| 瞳孔检测 | OpenCV + MediaPipe | Python本地运行 | 0元 |
| 决策Agent | DeepSeek-R1-Distill | Ollama本地部署 | 0元 |
| 数据存储 | PostgreSQL + MinIO | 自建或云端 | 按量付费 |
部署命令速查:
# 本地部署Qwen2-VL(需要24GB显存)
pip install vllm
vllm serve Qwen/Qwen2-VL-7B-Instruct --gpu-memory-utilization 0.9
本地部署DeepSeek-R1(需要16GB显存)
ollama pull deepseek-r1:7b
ollama run deepseek-r1:7b
