
DeepSeek发文:纯强化学习如何激发大模型推理能力


Nature最新论文深度剖析:从15.6%到86.7%,这是如何实现的?
DeepSeek-R1 论文首登《自然》封面,梁文锋团队正面回应蒸馏质疑、发布详尽安全报告
9月17日,在Nature上发表的DeepSeek-R1论文《DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning》[1]引起了业界广泛关注。这不仅仅是因为它在AIME 2024数学竞赛上取得了86.7%的惊人成绩,更重要的是它展示了一条完全不同的技术路径:不依赖人工标注的推理轨迹,纯粹通过强化学习让大模型自发学会推理。
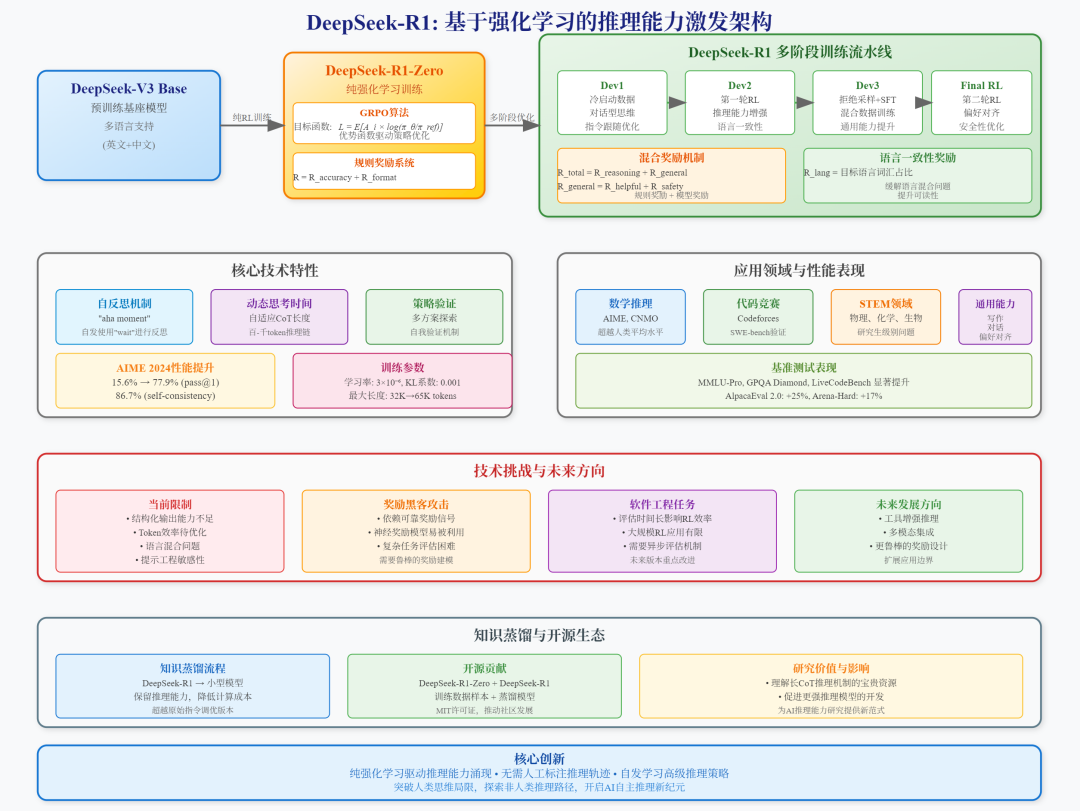
DeepSeek-R1 基于强化学习的推理能力激发架构
传统方法的瓶颈:人类标注的天花板
在讨论DeepSeek-R1的技术突破之前,我们需要先理解目前大模型推理能力提升面临的核心问题。
当前主流的推理能力增强方法主要依赖两种路径:
- • Chain-of-Thought (CoT)提示:通过精心设计的few-shot示例或"Let's think step by step"这样的提示词
- • 监督微调:使用人工标注的高质量推理轨迹进行训练
这些方法确实有效,但存在根本性限制:
- 1. 扩展性差:人工标注推理过程既昂贵又耗时
- 2. 认知偏见:人类标注者的思维模式会传递给模型
- 3. 性能上限:模型被限制在复制人类思维模式上,无法探索更优的推理路径
DeepSeek-R1的研究团队提出了一个大胆的假设:如果我们只提供最终答案的正确性反馈,让模型自由探索推理过程,会发生什么?
纯强化学习的探索:DeepSeek-R1-Zero
训练框架设计
DeepSeek-R1-Zero基于DeepSeek-V3 Base模型,采用Group Relative Policy Optimization (GRPO)算法进行训练。整个训练过程的核心思想极其简洁:
只告诉模型答案对不对,不告诉它应该怎么想。
训练使用的提示模板设计得极其简单:
奖励机制包含两个部分:
- • 准确性奖励:答案是否正确
- • 格式奖励:是否按照指定格式输出
就是这么简单。没有复杂的奖励工程,没有人工标注的推理步骤,甚至跳过了传统的监督微调阶段。
令人惊讶的自发行为
训练过程中观察到的现象让研究团队都感到意外:
自主延长思考时间:模型的推理链长度从几十个token自然增长到数百甚至数千个token。这不是外部强加的,而是模型自发学习的行为。
"顿悟时刻"的出现:训练过程中出现了一个明显的转折点,模型开始大量使用"wait"这个词进行自我反思。论文中展示的例子很有趣:
"Wait, let me recalculate this..."
"Actually, wait. I think I made an error..."
这种自我纠错行为是完全自发涌现的,没有任何外部指导。
复杂推理策略的发展:
- • 自我验证:模型学会检查自己的答案
- • 多角度探索:尝试不同的解题方法
- • 反思机制:发现错误后主动重新思考
技术深度解析
GRPO算法的优势
相比传统的PPO算法,GRPO在大模型训练中展现出明显优势:
目标函数设计:
其中优势函数A_i通过组内奖励对比计算:
这种设计的好处是:
- 1. 资源效率更高:不需要单独的价值网络
- 2. 训练更稳定:组内对比减少了奖励方差
- 3. 实现更简单:相比PPO减少了复杂的约束机制
性能提升数据
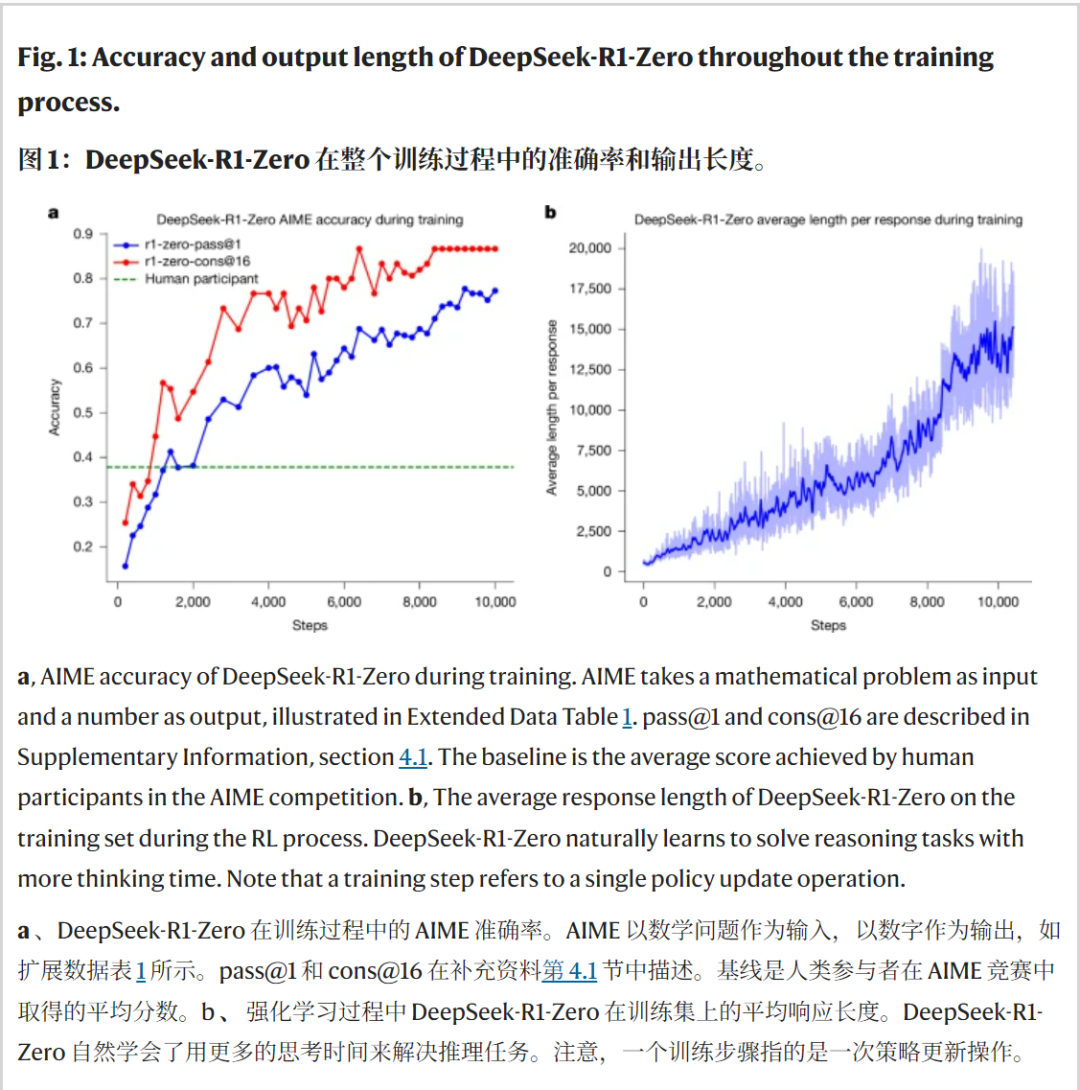
DeepSeek-R1-Zero 在整个训练过程中的准确率和输出长度。
AIME 2024测试结果最能说明问题:
- • 基础模型:15.6% (pass@1)
- • DeepSeek-R1-Zero训练后:77.9% (pass@1)
- • 结合self-consistency:86.7%
这个提升幅度已经超越了人类竞赛者的平均水平。而且这种能力不仅限于数学推理,在代码竞赛和STEM领域问题上同样表现出色。
从R1-Zero到R1:工程化的多阶段优化
虽然R1-Zero展现了强大的推理能力,但也暴露出一些问题:
- • 可读性差
- • 语言混合(中英文混杂)
- • 在非推理任务上表现一般
因此研究团队设计了多阶段的优化流水线来打造最终的DeepSeek-R1:
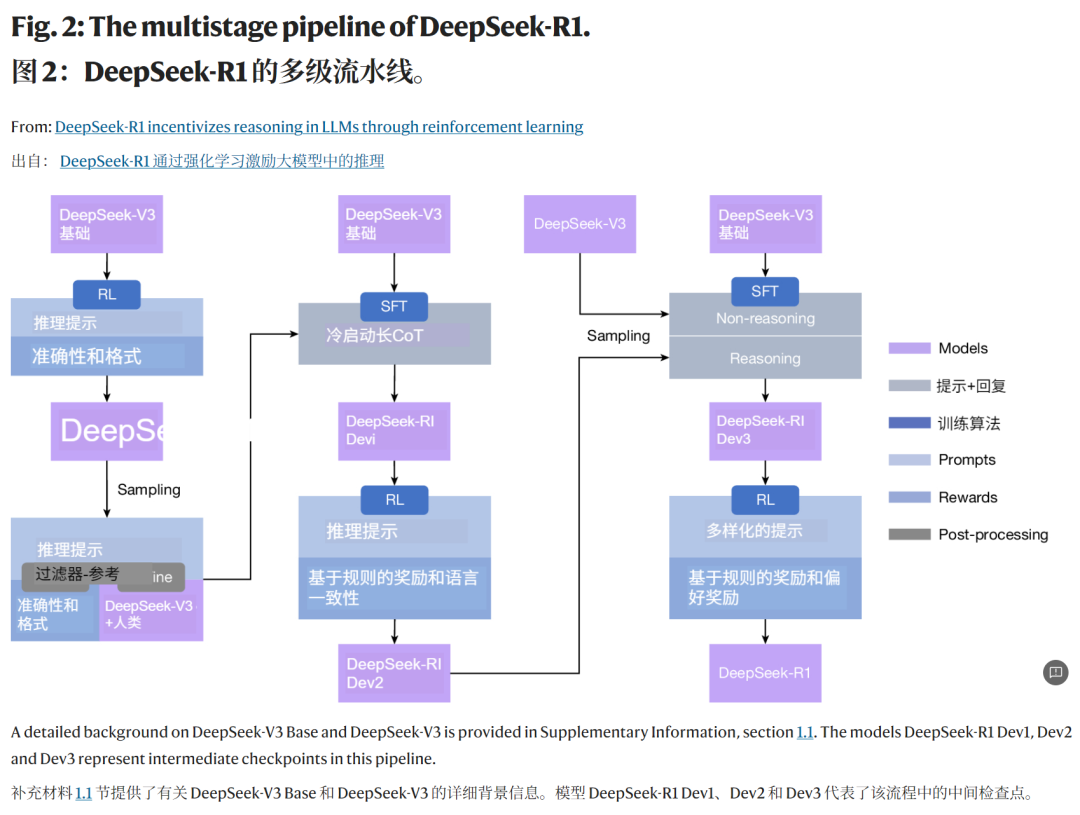
DeepSeek-R1 的多级流水线
第一阶段:冷启动数据训练 (Dev1)
引入少量人工设计的对话化思维过程数据,改善指令跟随能力。
第二阶段:推理专项强化学习 (Dev2)
专门针对推理任务进行RL训练,引入语言一致性奖励:
第三阶段:混合数据训练 (Dev3)
结合推理和非推理数据进行监督微调,提升通用能力。
第四阶段:综合强化学习 (Final)
使用混合奖励信号进行最终优化:
这个多阶段设计的巧妙之处在于:既保留了纯RL带来的推理突破,又通过工程化手段解决了实用性问题。
对GPU用户的实际意义
计算资源需求
从论文披露的训练细节来看:
- • 批大小:每步512样本
- • 序列长度:32K tokens (后期扩展到65K)
- • 采样数量:每个问题采样16个输出
- • 训练步数:总计约12,000步
这意味着如果要复现类似规模的训练,需要:
- • 高端GPU集群(至少数百张H100级别)
- • 大容量显存支持长序列训练
- • 高效的分布式训练框架
推理成本考量
DeepSeek-R1的推理特点是动态分配计算资源:
- • 简单问题:较短的推理链
- • 复杂问题:可能生成数千token的思考过程
这对GPU推理部署提出了新的挑战:
- 1. 显存管理:需要支持变长的KV Cache
- 2. 批处理策略:不同复杂度的请求处理时间差异巨大
- 3. 成本控制:长推理链会显著增加推理成本
技术局限与思考
当前限制
论文作者很坦诚地指出了当前的一些限制:
- • 结构化输出能力不足:对于需要特定格式输出的任务表现一般。
- • Token效率待优化:存在"过度思考"现象,简单问题也可能生成很长的推理链。
- • 工具使用缺失:无法调用外部工具(搜索引擎、计算器等)辅助推理。
- • 奖励设计挑战:对于难以客观评估的任务(如创意写作),纯RL方法仍然困难。
深层思考
- • 奖励黑客攻击是一个需要重视的问题。当模型过度优化奖励信号时,可能会找到绕过真正能力提升的"捷径"。DeepSeek-R1通过规则奖励在一定程度上缓解了这个问题,但对于更复杂的任务,这仍然是一个开放性挑战。
- • 推理路径的可解释性也值得关注。虽然我们能看到模型的思考过程,但这种自发涌现的推理模式是否真的反映了"理解",还是仅仅是统计模式的复杂组合?
开源生态与未来影响
社区贡献
DeepSeek团队将R1-Zero、R1以及训练数据样本都开源了,这对研究社区是巨大的贡献。特别值得关注的是:
- 1. 蒸馏模型:提供了多个小规模版本,降低了使用门槛
- 2. 训练数据:包含推理过程的高质量数据集
- 3. 技术细节:详细的超参数和训练配置
技术趋势预判
DeepSeek-R1代表的纯RL路径可能会成为未来大模型能力提升的重要方向:
- • 短期内:预计会有更多团队尝试类似的纯RL训练方法,特别是在数学、编程等有明确验证机制的领域。
- • 中期看:结合工具使用的增强推理系统可能成为主流,模型不仅会思考,还能调用外部资源验证和增强自己的推理过程。
- • 长期而言:当奖励建模技术进一步成熟后,纯RL方法可能扩展到更广泛的认知任务上。
结语
DeepSeek-R1的技术突破不仅仅在于性能数字的提升,更在于它展示了一种新的可能性:机器可以通过试错学习到超越人类设计的推理模式。
这项工作提醒我们,在AI能力的快速发展中,保持开放的心态去探索非传统路径的重要性。有时候,最好的老师不是人类的示范,而是正确的激励机制和足够的探索空间。
对于技术从业者而言,DeepSeek-R1的成功也提示我们需要重新思考:在GPU算力日益强大的今天,我们是否还在用昨天的思维模式设计明天的系统?
本文基于Nature发表的DeepSeek-R1论文内容整理,完整论文可在DeepSeek官方GitHub[2]获取。
引用链接
[1] DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning》: https://www.nature.com/articles/s41586-025-09422-z
[2] DeepSeek官方GitHub: https://github.com/deepseek-ai/DeepSeek-R1
