
医疗AI新突破:利用“慢思考”变革放射外科


核心资料来源: 亨利·福特医疗系统 (Henry Ford Health System) 该研究论文《Automated stereotactic radiosurgery planning using a human-in-the-loop reasoning large language model agent》已发布于 arXiv 预印本平台 (2025/12/23)
目录
伽马刀、射波刀,这些技术听起来很酷,其实这些都被统称为 立体定向放射外科。简单说,就是用极高剂量的射线精准打击脑子里的肿瘤,同时还能避开紧挨着的视神经和脑干。
这活儿有多难?就像在米粒上雕花。全球只有30%的医院能做,一个完美的治疗计划,往往需要顶尖物理师耗费数小时反复打磨。
以前的AI也想帮忙,但医生们不敢用。因为传统AI扔给你一个结果,却说不清是怎么算出来的。在人命关天的医疗领域,这就是原罪。
最近,美国亨利·福特医疗系统的研究团队搞了个大新闻。他们开发了一个叫 SAGE 的AI代理,不仅做出的计划媲美人类专家,还在保护听力(耳蜗剂量)上意外地超越了人类。
最神的是,它靠的不是更强的算力,而是学会了人类的 慢思考 能力。
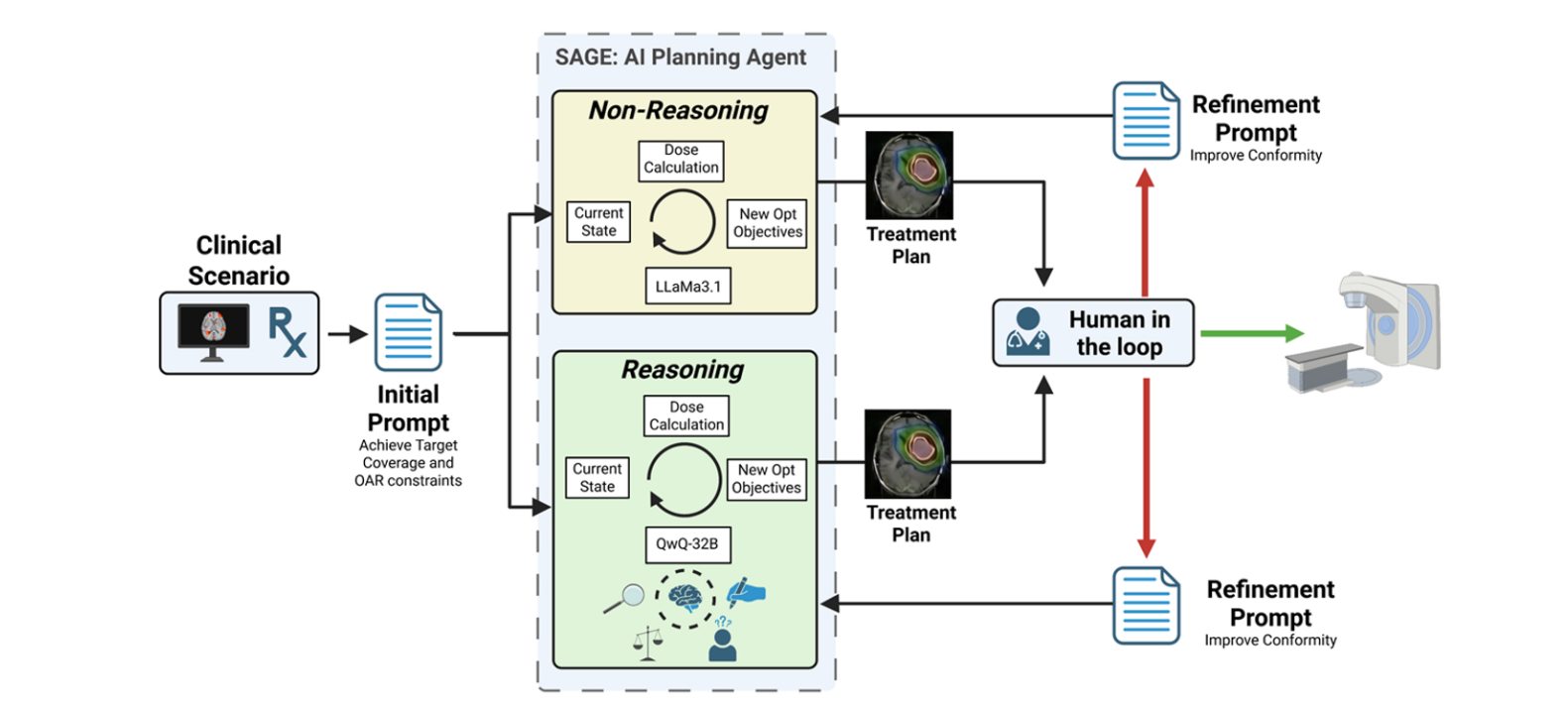
01 当AI学会了“三思而后行”
这次研究最吸睛的看点,是一场大模型内战。
研究人员找了两位选手:
- Llama 3.1-70B:像大多数聊天机器人一样,反应快,直接生成参数。
- Qwen QwQ-32B-Reasoning:这就是本次的主角,虽然参数量只有前者的一半,但它具备 链式推理 能力。
在处理41例脑转移瘤患者的病例时,两者的表现差异让人细思极恐。
Llama 3.1-70B 就像个莽撞的实习生,它完全不进行自我检查(0次约束验证),甚至在被指出错误时还会 嘴硬,虽然也能生成计划,但稳定性极差。
Qwen QwQ-32B-Reasoning 则展现出了惊人的 类人决策。它不会急着给答案,而是悄悄在后台进行了 457次主动检查。
- 它会自言自语:如果我现在提高这里的剂量,会不会烧坏旁边的脑干?
- 不行,梯度太陡了,我得调整一下射束角度。
- 再次验证一下视神经的受量……嗯,现在安全了。
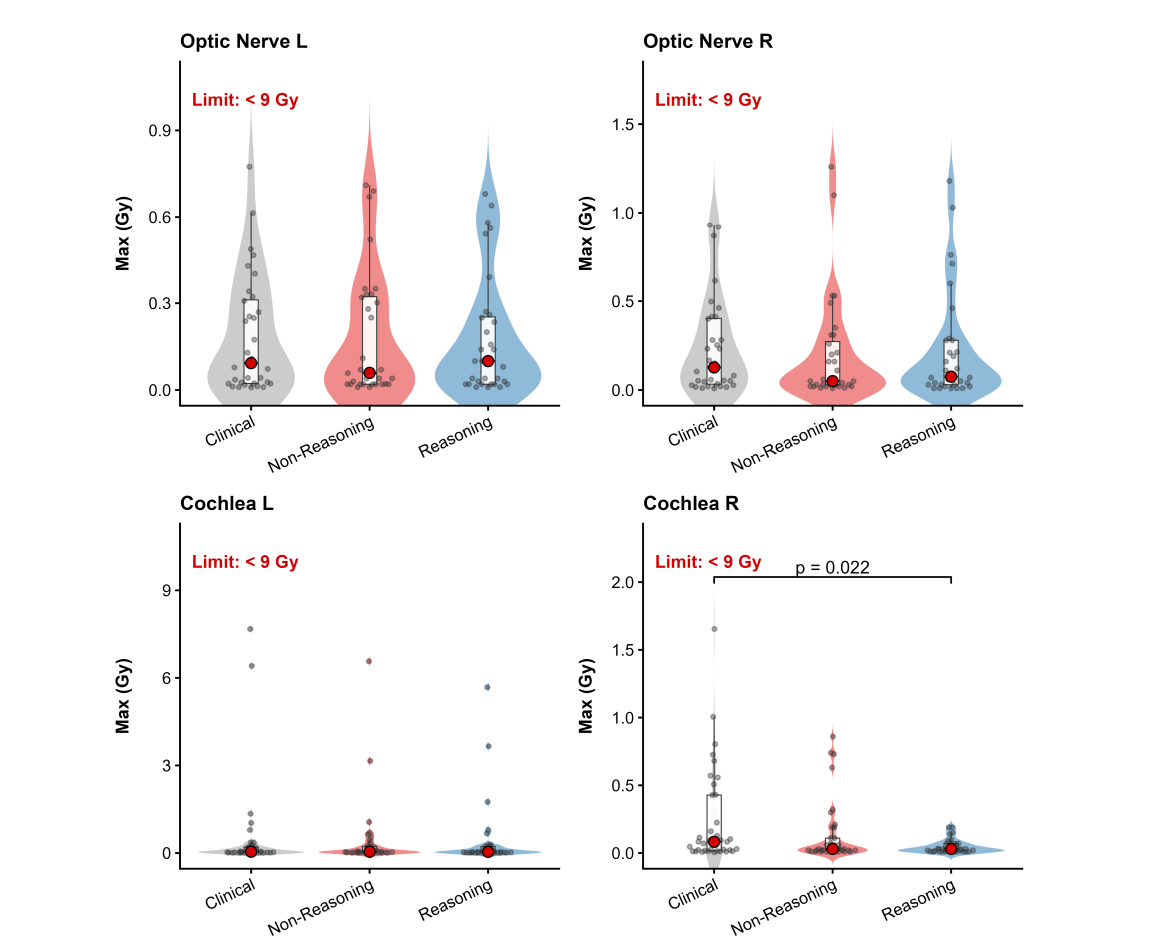
正是这种 假设-验证-修正 的系统2思维,让它在保护右侧耳蜗这项指标上,做到了显著优于人类物理师(p=0.022)。人类物理师可能因为疲劳或习惯忽略了极致的优化空间,但“慢思考”的AI不会。
02 人类一开口,AI就进化
SAGE系统最棒的设计,在于它的超级副手属性。
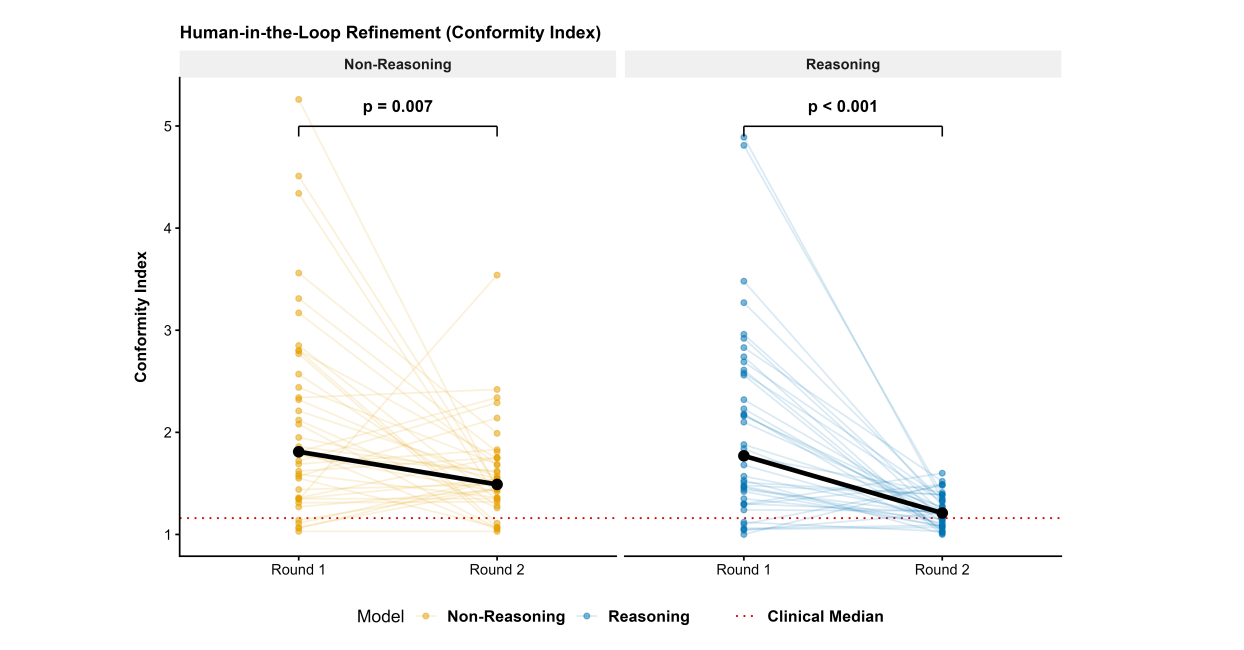
若初始计划未达到符合性指数要求,物理师可用自然语言指令(如“请提升剂量集中度”)触发二次优化。
结果显示,推理模型在接收反馈后,CI中位数接近临床基准(p<0.001),而非推理模型虽也有改进(p=0.007),但稳定性较差。
更有趣的是,这一切都被记录在案。AI会生成一份 审计日志,详细记录它是如何为了保护视神经而稍微牺牲了一点点靶区覆盖度的。这对于医生来说,这是可追溯的 诊疗逻辑。
03 效率换安全
必须承认,这种“慢思考”是有代价的。推理型模型的计算时间是普通模型的3倍。但在医疗领域,快从来不是第一指标,准和稳才是。
虽然算得慢,但推理型模型的输出错误率极低(中位数0次错误),而普通模型经常因为参数格式错误被系统驳回(中位数3次)。这就像一个是慢工出细活的大师,一个是手忙脚乱的学徒,你选谁?
独家洞察
-
小而美的推理模型更适合医疗垂直赛道 实验中32B参数的推理模型(Qwen QwQ)完胜70B的通用模型(Llama 3.1),这说明在专业领域,模型的逻辑推理能力远比单纯的知识储备重要。医疗AI企业不必盲目卷千亿参数大模型,专注于优化垂直场景下的推理链条,才是降本增效的王道。
-
医生角色的重构 SAGE展示的“人类-AI协同闭环”揭示了未来医生的定位。繁琐的参数调整、空间几何计算将完全交给AI;而医生的核心价值,将回归到 战略决策(System 2工作)。比如判断患者的身体状况是否适合牺牲局部功能来换取生存期。这才是人机共生的终极形态。
