
机器学习模型部署全流程实战:从训练完成到上线可用
一、部署前准备:打好地基
1.1 模型序列化:选对"快递盒"
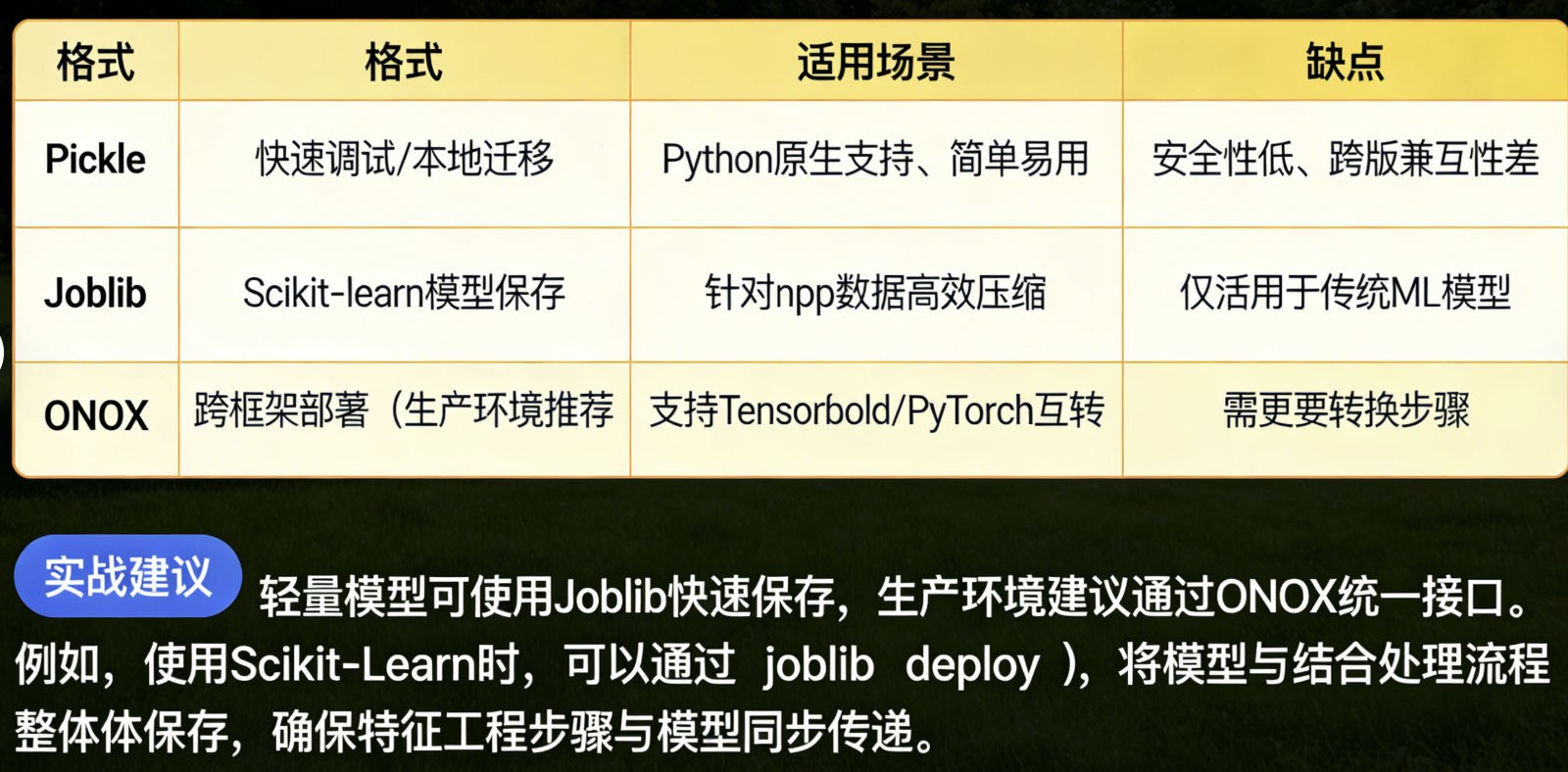
模型文件是部署的核心载体,选择合适的序列化格式能显著影响效率和兼容性。以下是三种常用方案对比:
格式 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
Pickle | 快速调试/本地迁移 | Python原生支持,简单易用 | 安全性低,跨版本兼容性差 |
Joblib | Scikit-learn模型保存 | 对numpy数组高效压缩 | 仅适用于传统ML模型 |
ONNX | 跨框架部署(生产环境推荐) | 支持TensorFlow/PyTorch互转 | 需额外转换步骤 |
实战建议:轻量模型可使用Joblib快速保存,生产环境建议通过ONNX统一接口。例如,使用Scikit-learn时,可以通过joblib.dump()将模型与预处理流程整体保存,确保特征工程步骤与模型同步传递。
1.2 环境管理:避免"版本地狱"
部署失败70%源于环境依赖冲突,推荐采用双重保险策略:
- 虚拟环境隔离:使用
conda或venv创建独立环境,确保依赖包版本固定。 - 依赖清单固化:通过
pip freeze > requirements.txt生成依赖清单,避免手动安装遗漏。
进阶方案:Docker容器化(后续章节详解),确保"一次构建,到处运行"。通过Docker镜像封装所有依赖,彻底消除环境差异问题。
二、模型优化:小身材大能量
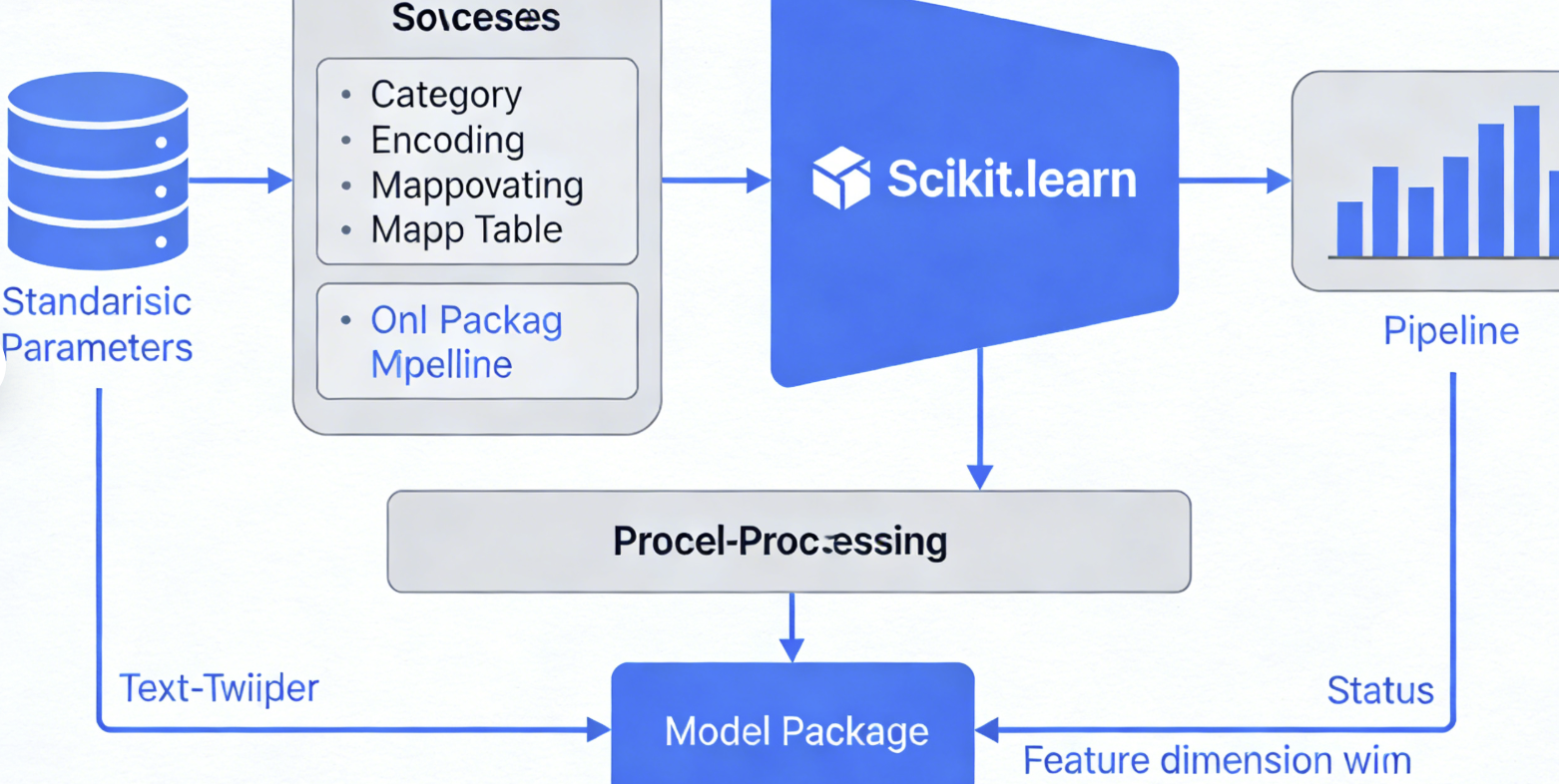
2.1 特征工程固化
部署时必须将训练阶段的特征处理流程同步保存。典型场景包括标准化参数、类别编码映射表、文本分词器状态等。例如,使用Scikit-learn的Pipeline将预处理步骤与模型打包,避免线上预测时出现特征维度不匹配的问题。
2.2 模型压缩技术
INT8量化:通过降低数值精度(32位浮点→8位整型)减少模型体积,提升推理速度。PyTorch提供动态量化工具,适用于LSTM/Linear层,但需验证量化后精度损失是否在可接受范围内。
轻量剪枝:移除模型中贡献度较低的权重参数,例如对全连接层进行50%剪枝。剪枝后需重新训练微调模型,确保性能不大幅下降。此方法更适合参数量大的深度学习模型。
三、部署方案实现:双轨并行
3.1 FastAPI快速搭建API服务
适用场景:本地调试/小规模应用。FastAPI提供高性能的异步接口,支持JSON数据交互。通过定义/predict端点,将模型预测逻辑封装为RESTful API。启动服务后,可通过curl或Postman发送测试请求。
关键步骤:
- 加载已保存的模型文件
- 定义接收数据的格式(如JSON)
- 将输入数据转换为模型可接受的格式
- 返回预测结果
3.2 Docker容器化部署
适用场景:生产环境/团队协作。Docker通过镜像打包应用及所有依赖,确保部署一致性。编写Dockerfile时需指定基础镜像、安装依赖、复制代码文件,并设置启动命令。
核心优势:
- 隔离性:避免服务器环境污染
- 可移植性:跨平台部署无差异
- 扩展性:配合Kubernetes实现弹性伸缩
方案对比:
方案 | 启动速度 | 扩展性 | 适用阶段 |
|---|---|---|---|
FastAPI | 快 | 一般 | 开发/测试 |
Docker+K8s | 稍慢 | 强 | 生产/高并发 |
四、测试与监控:让模型持续发光
4.1 接口性能测试
使用Apache Benchmark等工具模拟并发请求,测试服务的响应时间和吞吐量。关键指标包括:
- 响应时间:SaaS标准要求<200ms
- 错误率:生产环境需<0.1%
- 并发处理能力:目标>100 RPS
4.2 模型监控体系
基础监控项:
- 输入特征分布(定期比对训练数据)
- 预测置信度趋势
- 业务指标关联性(如点击率/转化率)
简易实现:通过日志记录每次预测的输入特征和输出结果,定期分析数据分布变化。例如,记录特征均值、方差等统计量,发现异常波动时触发预警。
4.3 漂移检测入门
使用Evidently等工具进行特征漂移分析,对比在线数据与训练数据的分布差异。重点关注类别特征的占比变化、数值特征的偏移程度。当漂移值超过阈值时,需重新训练模型或调整特征工程策略。
