
2025重磅研究:首个基于200万真实病例的 AI 安全评估


目录

前言
就在2025年圣诞节前夕(12月24日),arXiv上出现了一篇非常有分量的论文。这可不是那种在公开数据集上跑分的研究,而是**首个基于英国NHS初级保健数据**的LLM药物安全性审查评估。
研究团队直接把包含212.5万名患者的电子健康记录(EHR)数据库搬了出来,从中抽丝剥茧,让AI去处理那些真实的临床病例。
结果如何?
既让人惊喜,又让人背脊发凉。
惊喜的是,AI在发现问题上,灵敏度高达100%。
惊悚的是,当需要给出具体的、完全正确的干预建议时,它的通过率只有**46.9%**。
而且AI犯的错,不是因为它不懂医学,而是因为它不懂病人。 研究显示,86%的失败案例都源于AI无法像人类医生那样理解临床场景。
今天,我们就来深度拆解这份报告,看看到了真实医疗场景,大模型到底卡在了哪里?
一、200万数据的真相
做医疗AI研究,最难的不是模型,是数据。
这篇论文的研究团队来自英国科学、创新和技术部,利物浦大学,牛津大学等多家顶级机构。他们依托的是NHS切希尔和默西塞德地区的庞大数据库,覆盖了超过212万成年人。
为了测试AI的极限,研究者并没有随机抽取几个感冒发烧的简单病例,而是设计了一套精密的分层抽样策略,从20万名患者的测试集中,最终锁定了277名具有代表性的患者进行了人工评估:
- 高风险组(100人): 这些人至少符合一项预设的处方安全指标,比如“患有哮喘却开了β受体阻滞剂”或“服用抗精神病药的老年痴呆患者”。这是给AI出的陷阱题。
- 复杂对照组(100人): 这些人虽然没有触发特定的危险指标,但在年龄、用药数量、共病负担上与高风险组完全匹配。这是给AI出的干扰题。
- 普通随机组(100人): 随机抽取的普通患者,用于模拟日常门诊的真实分布。
评估的AI系统采用的是gpt-oss-120b(OpenAI于2025年8月发布的1200亿参数开源模型),并没有挂载外挂知识库,就是为了测试模型本身的能力。
为了不冤枉AI,研究引入了资深临床医生进行三级分层评估:
- Level 1: AI是否发现了存在的药物安全问题?
- Level 2: AI指出的问题是对的吗?
- Level 3: AI给出的解决建议或干预措施是否完全正确?
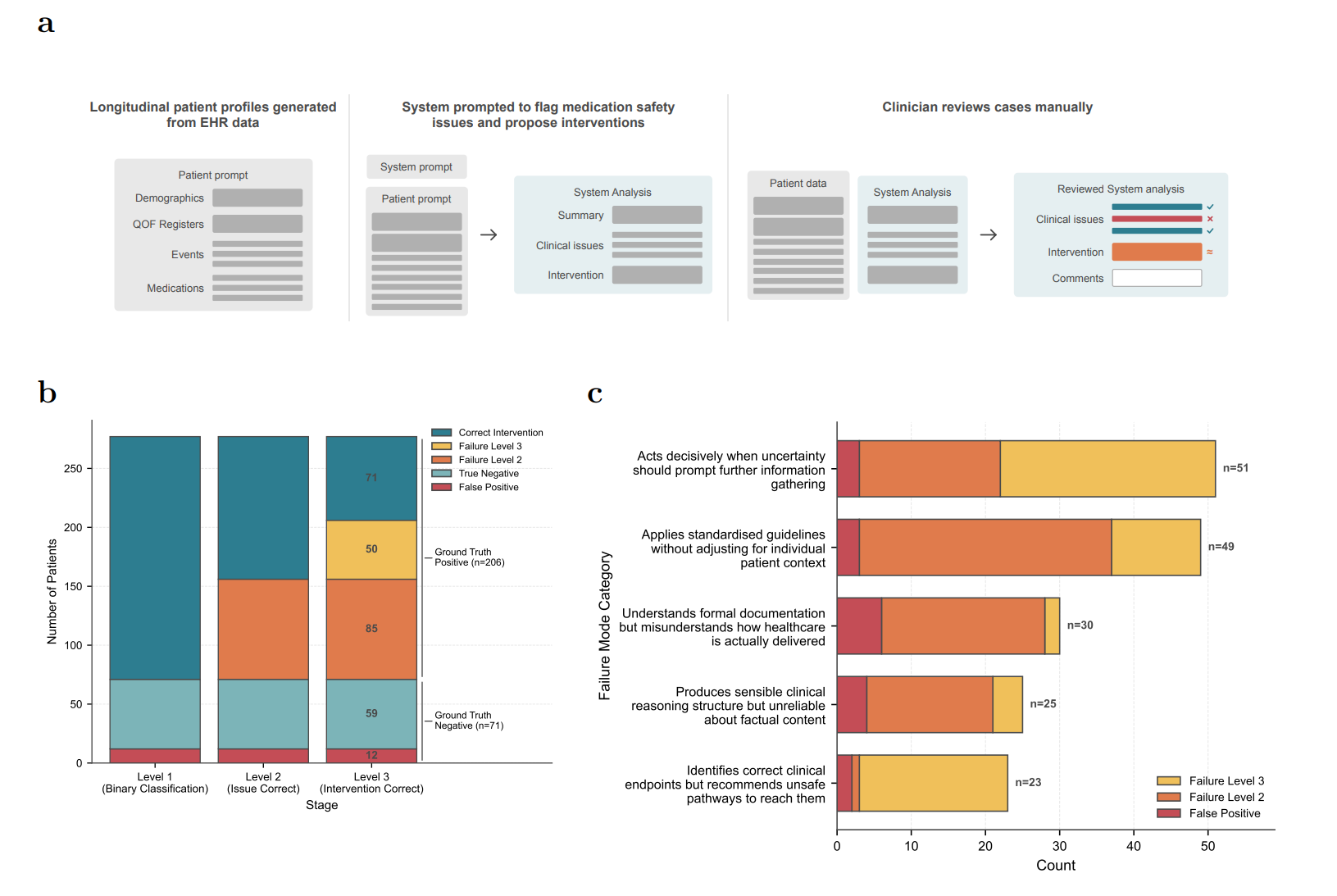
图1:三级分层评估标准示意图
二、实验结论:灵敏度与正确率的反差
测试结果出来后,出现了一个极具戏剧性的反差。
1. 灵敏度100%
在Level 1的测试中,对于所有206名经医生确认存在药物安全问题的患者,AI系统全部识别了出来。没有任何一个高风险病人被漏掉。这意味着,作为一道安全防线,LLM是极其可靠的。
2. 完全正确率仅46.9%
一旦进入解决问题的环节,AI就开始掉链子了。在所有277个案例中,只有不到一半(46.9%)的案例,AI不仅发现了问题,而且找准了病因,并给出了完全恰当的干预建议。
3. 复杂性的难题
研究还发现了一个明显的趋势:病人越复杂,AI越糊涂。
患者的复杂性通常由三个维度衡量:年龄、正在服用的药物数量、共病登记数量。数据显示:
- 对于只吃0-4种药的普通病人,AI的平均得分是0.83(满分1.0)。
- 对于吃药超过15种的复杂病人,AI的得分直接掉到了0.65,性能下降了22%。
图2:随着患者复杂性(用药数量)上升,LLM性能呈现明显下降趋势
这说明目前的大模型在处理多重用药、多重疾病交织的临床问题时,缺乏人类医生的抽丝剥茧能力。
三、结论:86%的错误源于“不懂病人”
这是本研究最核心、最独家、也是最颠覆的洞察。
过去我们总担心AI会一本正经地胡说八道,或者因为没背过最新的医学指南而开错药。但这项研究统计了148名患者身上的178个失败实例,结果令人大跌眼镜:
- 事实性错误:仅占14%(25例)。 比如不知道某种药的成分,或者背错了指南数值。
- 上下文推理错误:高达86%(153例)。 AI不仅知道药理,也背熟了指南,但它就是不懂得如何结合具体病人的情况来灵活运用。
研究团队将这些翻车场景归纳为五大类,每一类都值得所有医疗AI从业者反复研读:
1. 不确定时的过度自信——51例
AI在信息不足的时候喜欢强行加戏。
- 案例: 一位风湿病患者正在服用甲氨蝶呤(一种强效免疫抑制剂,需专科医生开具),同时用了非甾体抗炎药。AI敏锐地发现了两者有相互作用风险,于是:建议暂停甲氨蝶呤。
- 点评: 甲氨蝶呤是专科用药,贸然停药可能导致病情严重复发。正确的做法是咨询专科医生,而不是自己动手砍药。AI在这里表现得像鲁莽的实习生。
2. 忽略患者个体差异——49例
AI是死板的,不懂得具体情况具体分析。
- 案例: 一位90岁高龄、患有严重心脏病和肾病、住在养老院且正在接受临终关怀的老奶奶。她在9个月前停用了阿司匹林、他汀和降压药。AI看到后立刻报警:这不符合指南!必须马上把这些药全部加回去!
- 点评: AI完全不懂什么是临终关怀。对于这样一位生命即将走到尽头的老人,治疗目标是舒适,而不是为了多活几年去强行达标各项指标。
3. 缺少临床实践的灵活性——30例
AI不懂医疗系统的潜规则和实际操作习惯。
- 案例: 医生为了让患者达到3.75mg的雷米普利剂量,同时开了2.5mg和1.25mg两种规格的药片。AI一看:重复用药!同一成分开了两次!建议停掉一个!
- 点评: 这在英国医疗实践中是常规操作(为了凑剂量),AI却将其误判为医疗事故。
4. 事实错误——25例
这是少数的知识性错误。
- 案例(Vignette 27): AI信誓旦旦地分析:“Monomil XL这种药含有氯吡格雷……”
- 点评: Monomil XL其实是单硝酸异山梨酯(治心绞痛的),跟氯吡格雷(抗血小板的)八竿子打不着。这种一本正经的指鹿为马,极具迷惑性。
5. 过程盲点(Process Blindness)——23例
目标是对的,但手段极其粗暴,甚至危险。
- 案例: 一位76岁老太太在服用阿米替林(抗抑郁药)。AI指出这药有抗胆碱能副作用,建议停药。这没问题,但AI的建议是:立即停止。
- 点评: 阿米替林必须逐渐减量,突然停药会引发严重的戒断反应。AI只看到了终点,却忽略了路有多险。
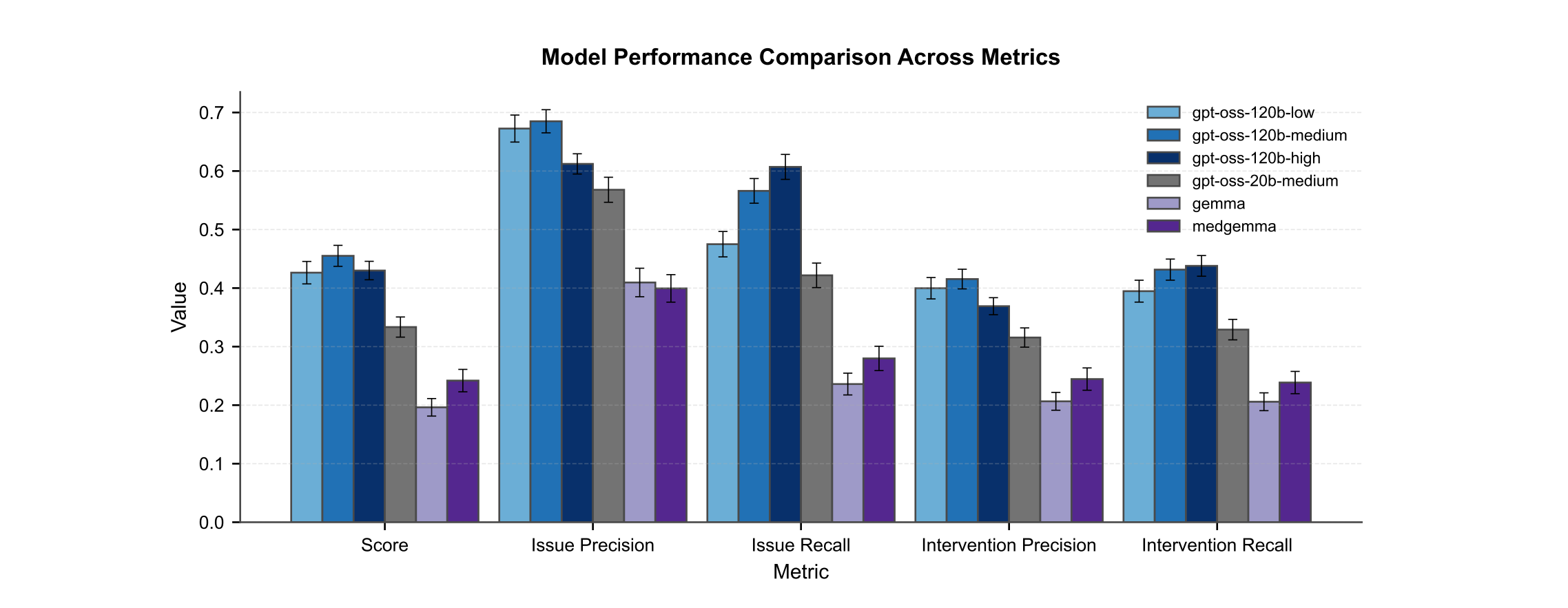
图3:AI失败案例的五大分类统计
四、 大模型碾压微调模型
为了看看这是不是OpenAI一家的毛病,研究团队还拉来了Gemma系列模型陪跑,包括经过医学微调的MedGemma-27B。
结果在复杂的临床推理任务上,通用大模型完胜专用小模型。
- GPT-OSS-120B 的得分是 0.459。
- MedGemma-27B 的得分只有 0.239。
这一结果有力地反驳了“医疗AI只需要小模型+医学微调”的观点。在面对复杂的临床问题时,模型的基础推理能力(往往与参数规模相关)比单纯灌输医学知识更重要。你得先是一个聪明的AI,然后才是一个合格的医生。
此外,研究还发现AI的输出存在随机性。同一个病人的数据跑10次,AI给出的安全评估可能会有显著波动。这对于严肃的医疗场景来说,是一个必须解决的稳定性难题。
五、 独家洞察
1. 警惕AI的呆板属性
AI目前非常缺乏隐性知识。它不懂什么是“凑剂量”,不懂什么是“临终关怀”,不懂“突然停药的痛苦”。这些知识写不在教科书里,而是存在于医生的经验和医疗体系的惯例中。如何将这些隐性知识形式化并教给AI,是下一个巨大的机会点。
2. 人机协作的最佳模式
鉴于AI拥有100%的灵敏度但只有46%的决策正确率,现阶段最安全的落地方式是:让AI做大规模的初筛和风险预警,把所有可疑点都列出来;然后由人类医生介入,进行去伪存真和决策制定。试图直接让AI全自动开方或改方,在目前阶段是极度危险的。
结语:
这篇发表于2025年底的重磅研究,虽然泼了一盆冷水,但也洗清了部分AI泡沫。它告诉我们,医疗AI并没有失败,只是它比我们想象的要更难、更复杂。要让AI从做题家迈入三甲医院专家,中间隔着的一条鸿沟。
