
多模态理解生成“大一统”!Meta&港大等重磅发布Tuna:统一视觉表征,性能碾压Show-o2


项目链接:https://tuna-ai.org/
文章链接:https://arxiv.org/pdf/2512.02014
Huggingface: https://huggingface.co/papers/2512.02014
亮点直击
- Tuna,一个采用统一视觉表示的原生统一多模态模型,在一个单一框架内实现了图像/视频理解、图像/视频生成和图像编辑。
- 广泛的实验表明,Tuna 的统一视觉表示非常有效,在多个多模态理解和生成任务中实现了SOTA性能。
- 全面的消融研究证明了本文的统一视觉表示设计优于现有方法,如Show-o2和其他采用解耦表示的模型。

 图1 展示了Tuna,这是一个基于统一视觉表示的原生统一多模态模型,支持多样的多模态理解与生成能力,如图像和视频理解、图像与视频生成以及图像编辑。
图1 展示了Tuna,这是一个基于统一视觉表示的原生统一多模态模型,支持多样的多模态理解与生成能力,如图像和视频理解、图像与视频生成以及图像编辑。
总结速览
解决的问题
- 现有统一多模态模型(UMMs)的性能不足: 当前的 UMMs 采用单一类型的视觉编码器(如 VQ-VAE、MAR 编码器)来处理理解和生成任务,这往往牺牲其中一个任务的性能,导致其表现不如解耦(decoupled)的模型。
- 视觉表示的统一与平衡挑战: 如何将视觉输入编码成一种单一、统一、且能兼顾理解(侧重语义)和生成(侧重细节)任务需求的视觉表示,是开发原生 UMMs 的核心挑战。
提出的方案
- 提出模型: Tuna,一个采用统一视觉表示的原生统一多模态模型(native UMM)。
- 核心设计: 通过直接连接一个 VAE 编码器(负责细节/生成)和一个表示编码器(Representation Encoder,负责语义/理解)。
- 目的: 获得足够富有表现力的统一表示,以同时适用于各种多模态任务。
- 处理流程: 将这些统一的视觉特征与文本 tokens 融合,然后由一个 LLM 解码器进行处理,通过自回归的下一词元预测和流匹配(flow matching)来生成新的文本 tokens 和去噪图像。
应用的技术
- 统一视觉表示: Tuna 的核心技术,通过将 VAE 编码器(如 VAE)与表示编码器(如 SigLIP)直接连接起来。
- LLM 解码器: 用于处理融合后的文本和视觉特征。
- 自回归下一词元预测: 用于生成新的文本 tokens。
- 流匹配: 用于生成去噪图像(denoised images)。
- 三阶段训练: 采用特定的三阶段训练流程来优化模型性能。
达到的效果
- 功能统一性: Tuna 在单一框架内实现了图像和视频的理解、图像和视频的生成以及图像编辑等多种任务。
- 性能提升: 在多模态理解和生成基准测试中达到了SOTA:
- 理解基准: 在 MMStar 上达到 61.2% 。
- 生成基准: 在 GenEval上达到 0.90 。
方法:Tuna
本节介绍 Tuna,这是一种原生的统一多模态模型,在所有多模态理解和生成任务中采用统一的视觉表示。首先概述模型设计的关键动机,随后详细描述 Tuna 的架构和训练流程。整体框架概览如下图 2 所示。
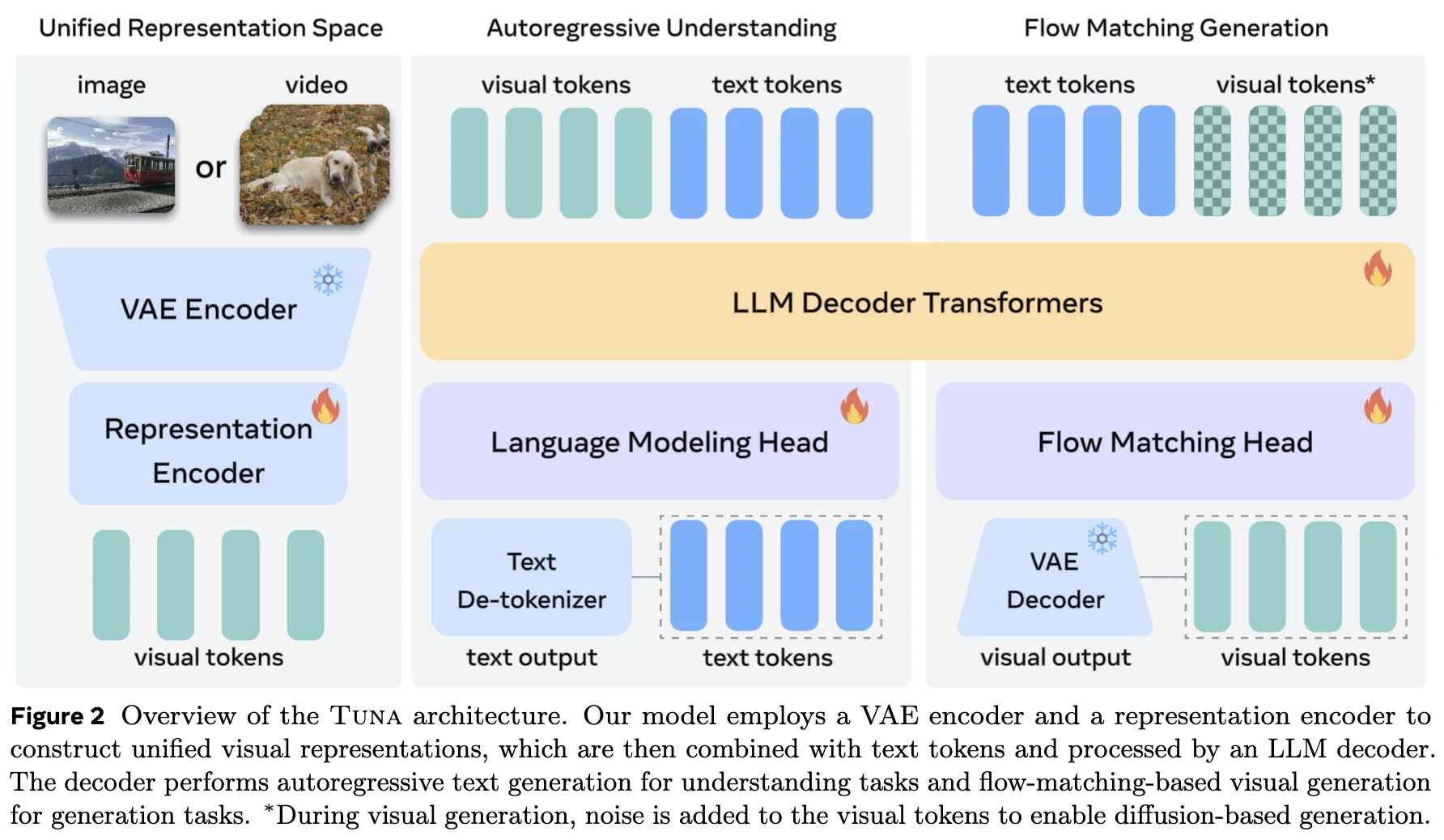
动机与设计原则
- 自回归 vs. 扩散: 文本生成和图像/视频生成既可以通过自回归模型实现,也可以通过扩散模型实现。在实践中,领先的纯理解模型通常采用自回归模型进行文本生成。另一方面,最先进的图像和视频生成器则采用带有流匹配(flow matching)的(隐空间)扩散模型。
- 连续 vs. 离散视觉表示: 观察发现,在连续(例如 KL 正则化)VAE 隐空间中运行的图像和视频生成模型,其表现优于使用离散表示的模型,因为离散化会导致信息丢失并降低保真度。同样,多模态理解模型通常依赖连续的语义特征(如 CLIP 特征),这表明连续视觉表示对于理解和生成任务本质上更为有效。
- 语义表示有益于视觉生成: 最近的研究表明语义特征可以增强视觉生成。例如,REPA 证明了扩散 Transformer 受益于中间特征与预训练表示编码器(如 DINOv2)的对齐。与本工作同期的 RAE 研究使用冻结的表示编码器将图像编码为隐空间表示,表明仅凭预训练的语义特征就能有效地重建输入图像。
- VAE 隐空间变量可以支持理解任务: 本工作观察到,最初为视觉重建设计的离散和连续 VAE 隐空间变量也能支持语义理解任务。最近的方法如 UniTok 和 TokLIP 通过对比学习增强了 VQ-VAE 隐空间变量的语义理解能力。其他工作探索了基于连续 VAE 隐空间变量的扩散模型用于语义理解和密集预测任务,包括语义分割、目标识别和图像检索。
基于这些观察,Tuna 的设计具有以下关键特征:
- Tuna 集成了用于文本生成的自回归模型和用于图像/视频生成的流匹配模型。
- Tuna 将其统一视觉表示建立在连续的 VAE 隐空间变量之上,因为这些隐空间变量有效地支持理解和生成任务。
- 为了进一步提升性能,Tuna 采用表示编码器从 VAE 隐空间变量中提取更高级别的特征,从而提高理解和生成的质量。
模型架构

LLM 解码器和流匹配头
在获得统一视觉表示 后,在其前面添加一个表示采样时间步 的时间步 Token,将此视觉 Token 序列与语言 Token 拼接,并将组合后的序列输入到 LLM 解码器(Qwen-2.5)中进行联合多模态处理。遵循标准 UMM 实践,如图 3 所示,在 LLM 解码器层内对语言 Token 应用因果注意力掩码(causal attention mask),对视觉 Token 应用双向注意力掩码(bidirectional attention mask)。
对于多模态理解任务,LLM 解码器的输出通过语言建模头(language modeling head)以生成文本 Token 预测。对于视觉生成和图像编辑,将完整的 Token 序列输入到一个随机初始化的流匹配头(flow matching head)以预测流匹配的速度(velocity)。该头共享 LLM 解码器架构,并通过 AdaLN-Zero 添加时间步条件,遵循 Show-o2 和 DiT 的做法。对于生成和编辑任务,在拼接的文本-视觉序列上采用多模态 3D-RoPE,以处理交错的指令和视觉内容。
训练流程
为了有效地训练该统一模型,本工作采用三阶段训练策略,逐步使每个模型组件适应理解和生成任务。
第一阶段:统一表示和流匹配头预训练
在第一个训练阶段,目标是调整语义表示编码器以生成统一视觉表示,并为流匹配头建立稳健的初始化。为此,在冻结 LLM 解码器的同时训练表示编码器和流匹配头,使用两个目标:图像描述(image captioning)和文本到图像生成。
图像描述目标与强语义编码器(如 SigLIP 2 和 Qwen2.5-VL 视觉编码器)的预训练目标一致。图像描述已被证明可以提供与对比学习相当的语义丰富性,从而增强统一表示的视觉理解能力。同时,文本到图像生成目标训练流匹配头从文本条件生成图像,为后续的图像编辑和文本到视频生成任务奠定基础。此外,该目标允许生成梯度反向传播到表示编码器,进一步使统一视觉表示与理解和生成任务对齐。
第二阶段:全模型持续预训练
在第二个训练阶段,解冻 LLM 解码器,并使用与第一阶段相同的图像描述和文本到图像生成目标对整个模型进行预训练。在第二阶段的后期训练步骤中,进一步引入图像指令跟随(image instruction-following)、图像编辑和视频描述数据集,以扩展模型的能力。这一阶段使 Tuna 能够执行更复杂的多模态推理和生成任务,弥合了基本视觉-文本对齐与更高级的指令驱动的多模态理解和生成之间的差距。
第三阶段:监督微调 (SFT) 最后,在第三阶段,使用图像编辑、图像/视频指令跟随和高质量图像/视频生成数据集的组合进行监督微调(SFT),并使用降低的学习率进行训练。这一阶段进一步细化了 Tuna 的能力,提高了其在不同多模态理解和生成任务中的性能和泛化能力。
实验
本部分对 Tuna 在各类多模态任务上的性能进行了全面评估。
实验设置
Tuna 基于两个不同规模的 LLM 构建:Qwen2.5-1.5B-Instruct 和 Qwen2.5-7B-Instruct。训练过程分为三个阶段,涉及从表示编码器、投影层到全模型的优化。使用了包括图像描述、文本生成图像、图像编辑及视频相关的数据集。
主要结果
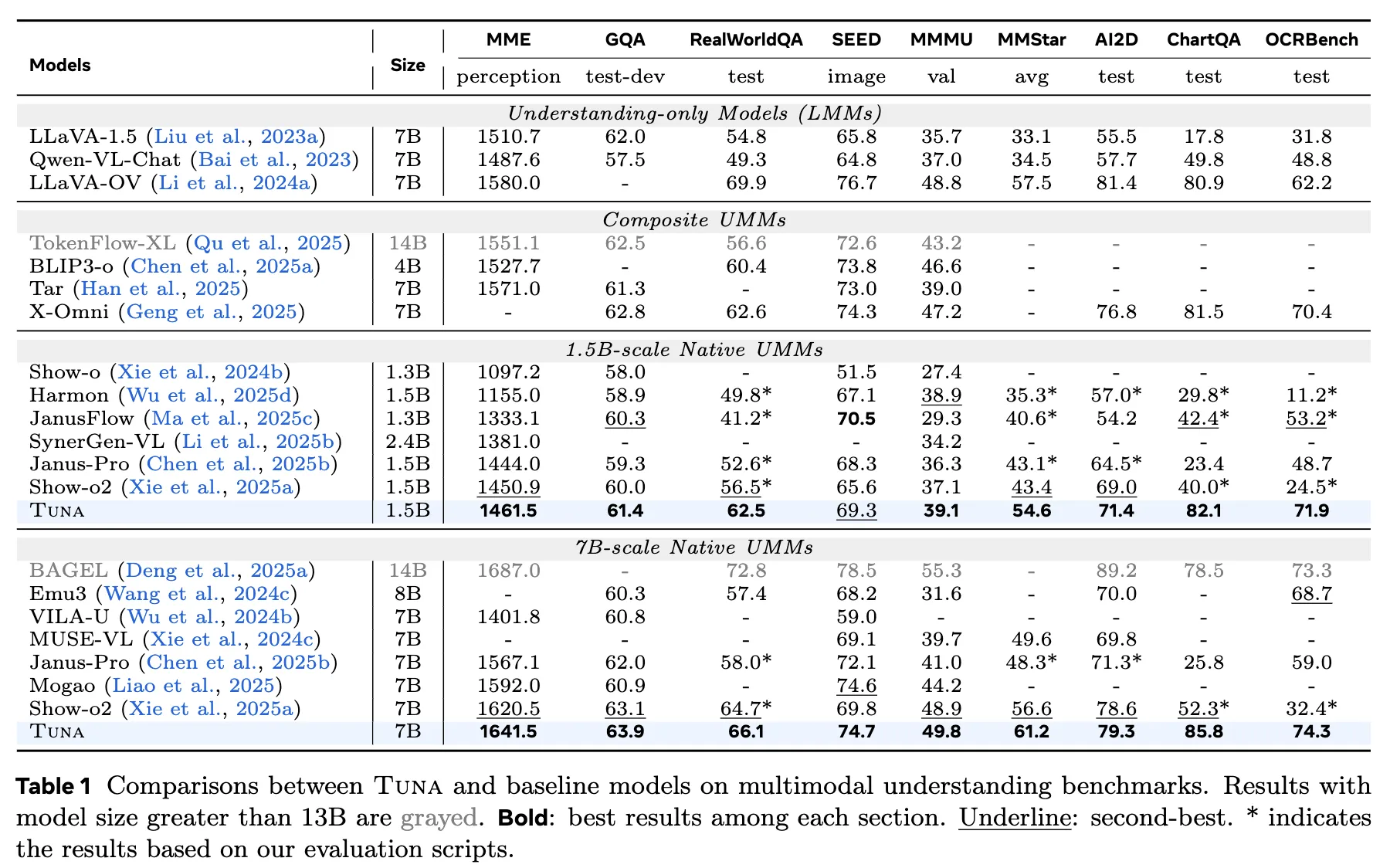
图像理解 本工作在 MME、GQA、MMMU 等 9 个基准上评估了 Tuna。如下表 1所示,无论是 1.5B 还是 7B 版本,Tuna 几乎在所有基准测试中都达到了最先进(SOTA)的结果。Tuna 不仅与纯理解模型相比具有竞争力,而且优于许多复合型 UMM 和更大规模的 UMM,证明了统一表示的有效性。
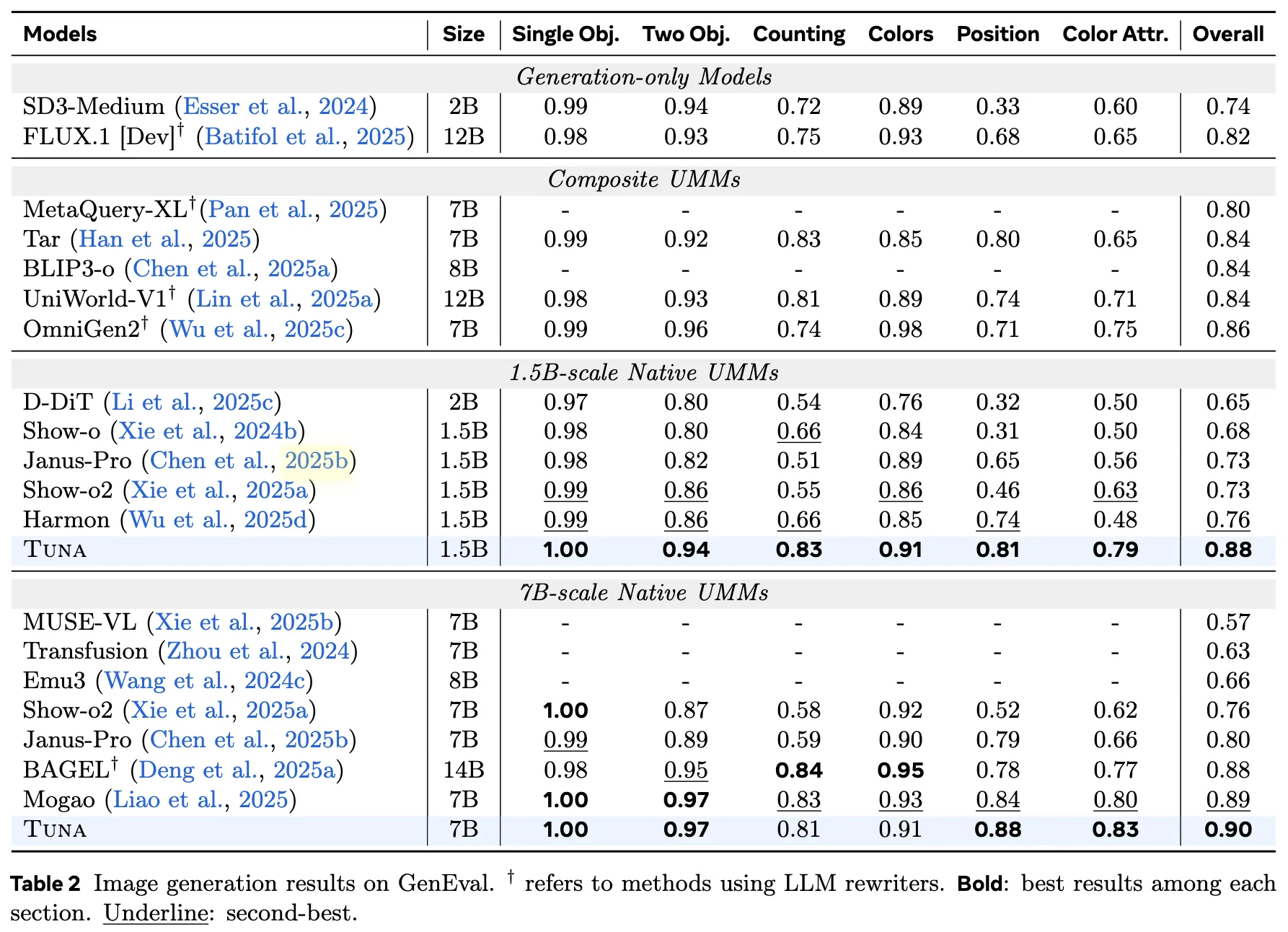
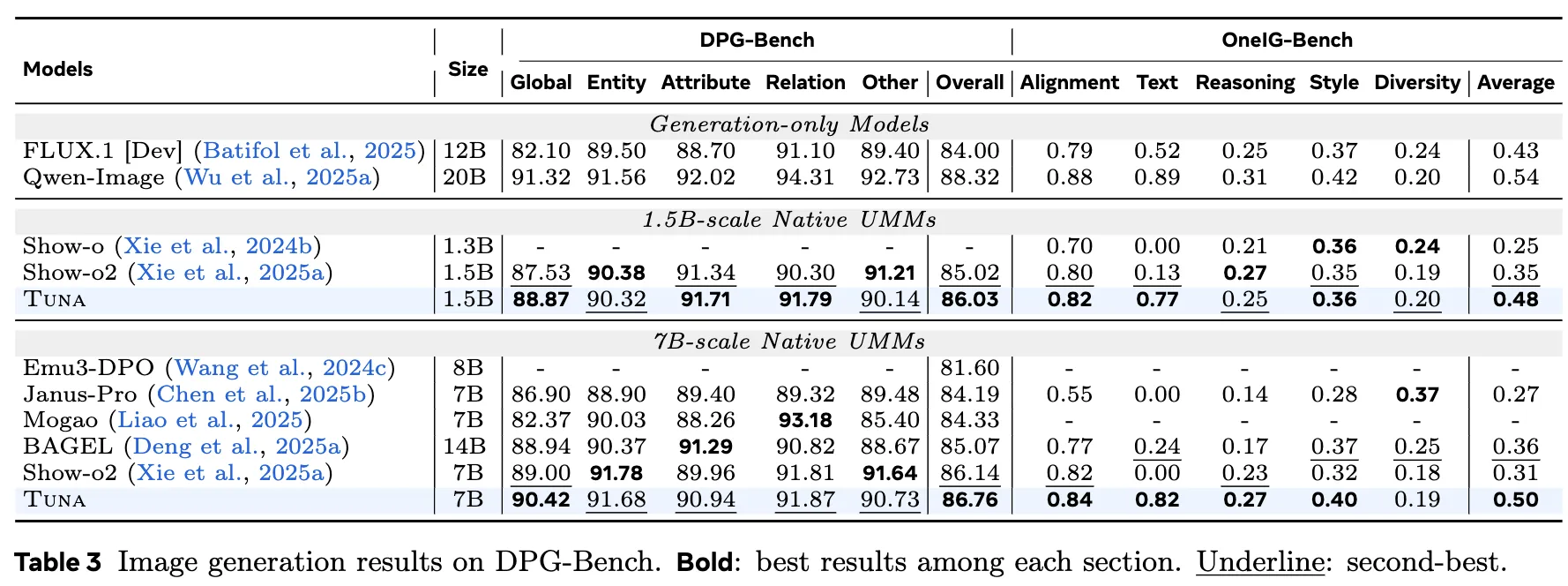
图像生成 在 GenEval、DPG-Bench 和 OneIG-Bench 三个基准上评估了 Tuna。结果如下表 2和下表 3所示。Tuna 始终优于包括 Janus-Pro、BAGEL 和 Mogao 在内的现有方法。特别是在 OneIG-Bench 中,Tuna 在文本渲染质量方面表现出显著优势,这表明其在处理包含视觉文本信息的复杂指令时具有强大的语义理解能力。
图像编辑 使用 ImgEdit-Bench 和 GEdit-Bench 进行评估。如下表 4所示,Tuna 在 ImgEdit-Bench 上取得了 4.31 的总分,在所有 UMM 中排名最高,且与 FLUX.1 等纯生成模型相当。在 GEdit-Bench 上,Tuna 在所有统一模型中得分最高。下图 7 展示了定性结果,Tuna 能够准确执行风格迁移、环境更改和对象替换等操作。
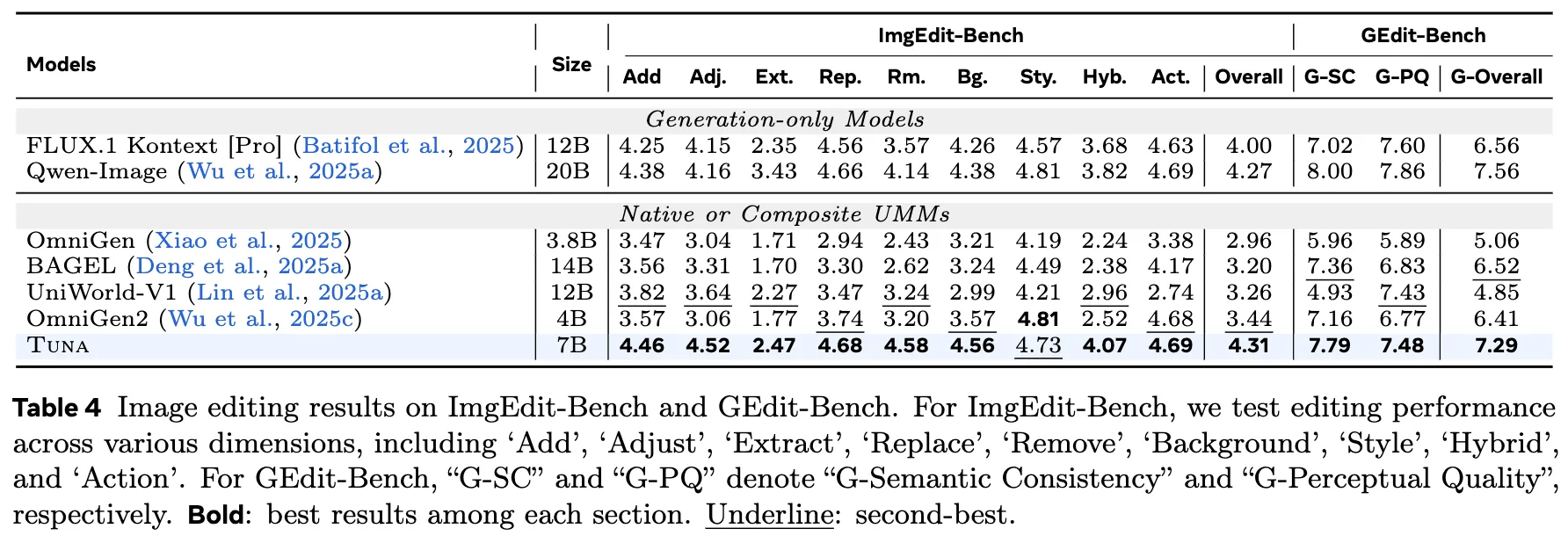

视频理解 在 MVBench、Video-MME 等四个视频基准上的评估结果如下表 5所示。Tuna 在 MVBench 和 Video-MME 上优于 Show-o2,并在其他基准上表现出竞争力。即使是 1.5B 参数的模型,其性能也能与更大的纯理解模型相媲美。
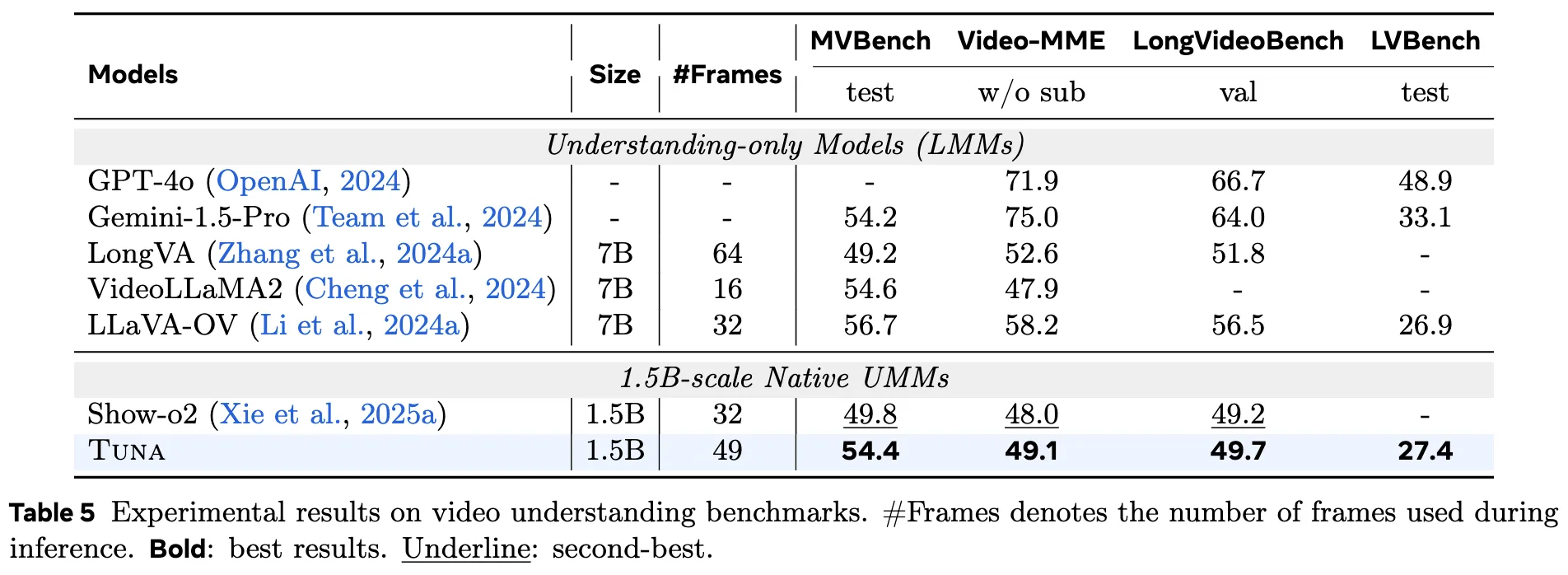
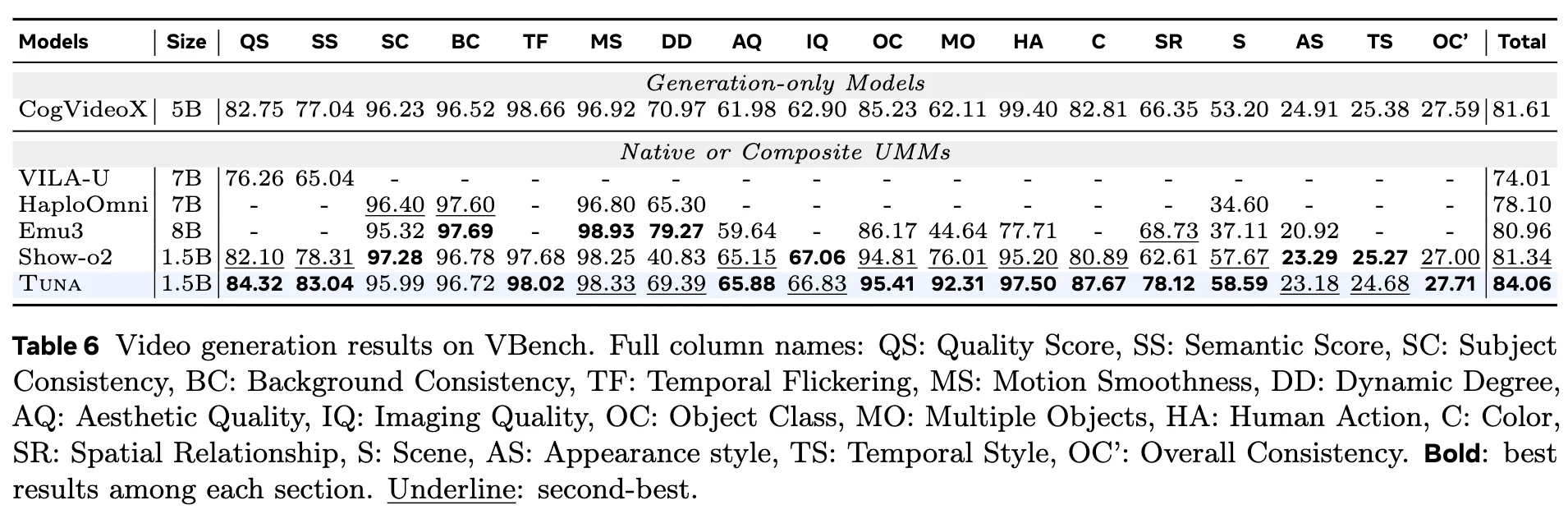
视频生成 在 VBench 上的评估结果如下表 6所示,Tuna 实现了 SOTA 性能,超越了所有现有的具备视频生成能力的 UMM,同时仅使用了 1.5B 参数的 LLM 解码器。定性结果如下图 8所示,展示了 Tuna 生成高保真视频的能力。

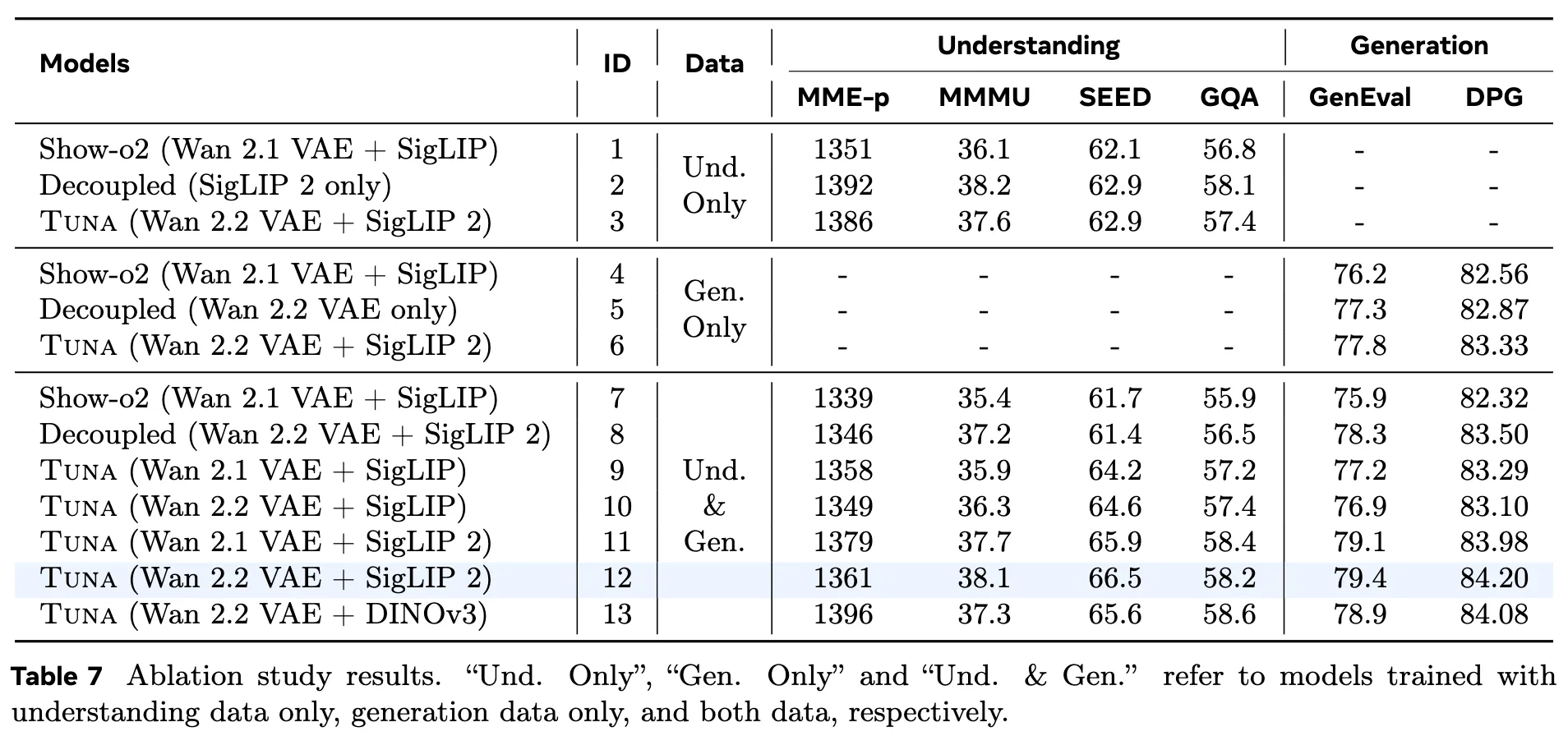
消融实验:视觉表示设计
本工作通过一系列消融实验(如下表7所示)验证了架构和训练策略的有效性:
- 统一表示 vs. 解耦表示: 结果表明,Tuna 的统一表示在理解和生成任务上均优于解耦设置(即理解和生成使用不同的编码器)。解耦设计在理解任务上会导致性能显著下降。
- 表示编码器的选择: 更强的表示编码器(如 SigLIP 2 vs. SigLIP)能带来更好的性能。SigLIP 2 在保持较小模型尺寸的同时,提供了优于 DINOv3 的生成质量。
- 理解-生成协同效应: 联合训练使得 Tuna 在理解任务上超过了仅使用理解数据训练的模型,在生成任务上也超过了仅使用生成数据训练的模型。这证明了统一视觉表示设计实现了任务间的相互增强。
- 与 Show-o2 的比较: Tuna 的统一表示(直接从 VAE 隐空间变量提取特征)在所有基准上均优于 Show-o2 采用的后期融合策略。
讨论:统一表示分析
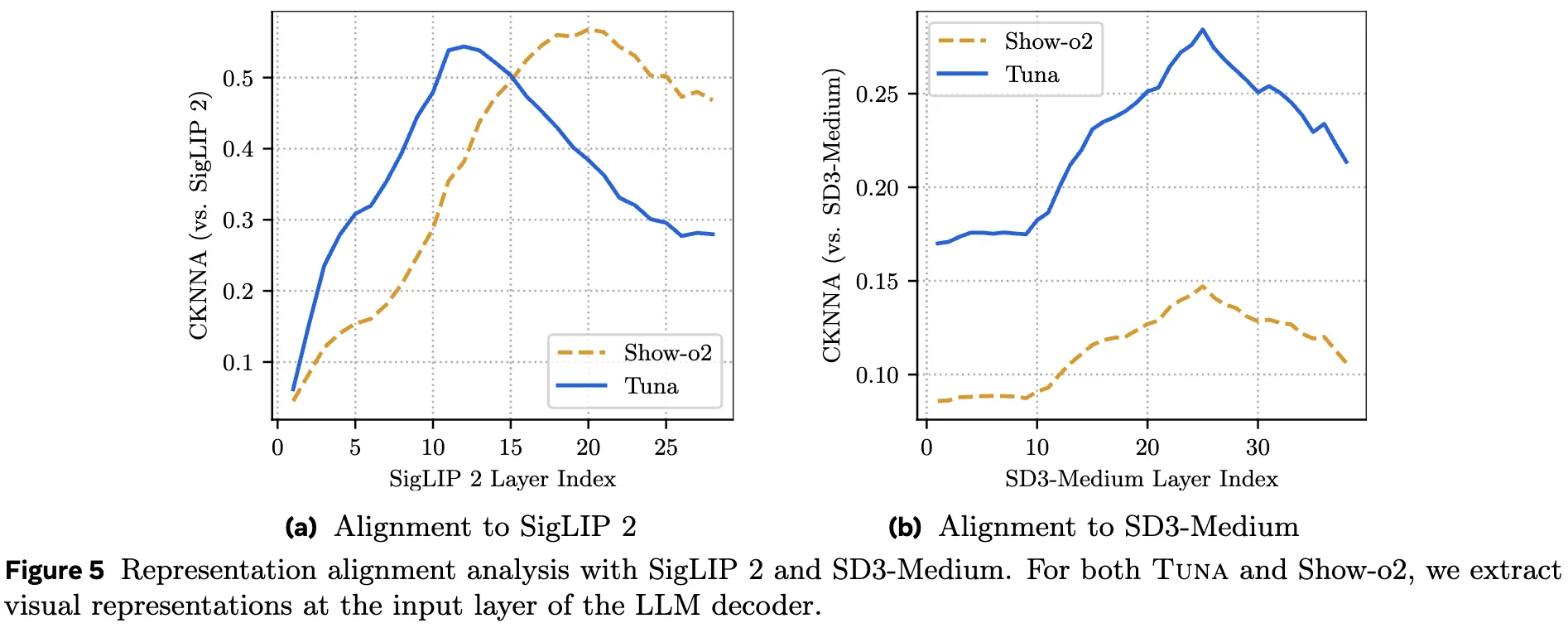
通过 CKNNA 分数分析(如下图 5所示),本工作发现 Show-o2 的特征严重偏向语义理解,而与生成模型的特征相关性较弱。相比之下,Tuna 的统一表示与 SD3-Medium(强生成模型)的中间特征具有更高的一致性,表明 Tuna 学习到了更平衡的、适用于理解和生成的统一表示。
定性结果
下图 6展示了 Tuna 在图像生成上的优势,特别是在组合性生成和文本渲染方面(例如正确拼写单词、按指示放置物体)。相比之下,其他模型经常出现拼写错误或物体遗漏。

结论
Tuna,一种原生的统一多模态模型,它通过级联 VAE 编码器和表示编码器构建了统一的视觉表示空间。本工作在此统一表示的基础上训练了一个 LLM 解码器和一个流匹配头,在图像和视频理解、图像和视频生成以及图像编辑方面均取得了强大的性能。
Tuna 不仅超越了之前的 UMM 基线模型,而且与领先的纯理解和纯生成模型相比也具有竞争力。消融研究进一步表明:(1) Tuna 的统一表示空间优于 Show-o2 风格的统一表示和解耦表示设计;(2) 在该框架内,更强的预训练表示编码器始终能带来更好的性能;(3) 这种统一视觉表示设计实现了理解和生成之间的相互增强。
参考文献
[1] Tuna: Taming Unified Visual Representations for Native Unified Multimodal Models
