
多任务多模态全统一!港科大&快手可灵等最新UnityVideo:生成、理解、控制多项SOTA


- 论文链接: https://arxiv.org/abs/2512.07831
- 项目链接: https://jackailab.github.io/Projects/UnityVideo
- 代码链接: https://github.com/dvlab-research/UnityVideo
- 模型链接: https://huggingface.co/JackAILab/UnityVideo
亮点直击
- 统一框架:UnityVideo,一个统一的多模态、多任务视频生成与理解框架。在基于 Diffusion Transformer (DiT) 的架构中,实现了文本到视频生成、可控视频生成以及视频模态估计(如深度、光流、骨骼等)的联合学习。
- 双向互促:通过联合训练,验证了多模态学习不仅能实现任务的大一统,还能加速模型收敛,并增强模型对物理世界的理解能力(如物体折射、碰撞动力学)。
- 零样本泛化:模型展现了强大的零样本(Zero-shot)泛化能力,能够处理训练数据中未见过的物体和风格。
- *贡献了大规模统一数据集 OpenUni(130万对多模态样本)和高质量评测基准 UniBench(包含Unreal Engine渲染的真值数据)。

解决的问题
- 单一模态的局限性:现有的视频生成模型大多局限于单一模态(主要是 RGB),缺乏全面的世界理解能力(World-Awareness)。
- 物理常识的缺失:仅靠 RGB 视频训练,模型倾向于拟合分布而非进行物理推理,难以捕捉复杂的物理动态(如深度关系、运动规律)。
- 训练范式的割裂:以往的研究通常将视频生成、可控生成和模态估计作为独立任务处理,或者仅进行单向交互,缺乏统一训练带来的协同效应。
提出的方案
- 全能型 DiT 架构:UnityVideo 将视频生成(Video Generation)和视觉模态估计(Video Estimation)整合进同一个流匹配(Flow Matching)框架中。
- 动态噪声调度:设计了一种动态噪声注入策略,使得模型可以在单次训练循环中同时处理条件生成、模态估计和联合生成这三种不同的训练目标。
- 模态自适应学习:引入了上下文学习器(In-Context Learner)和模态切换器(Modality Switcher),使模型能够区分并处理多种异构模态信号。
应用的技术
- 动态任务路由 :根据学习难度为不同任务(条件生成、估计、联合生成)分配不同的采样概率 ,并对应不同的噪声调度策略。
- 上下文学习器 :利用文本提示(如 "depth map", "human skeleton")来引导模型识别模态类型,而非仅描述视频内容,从而激活模型的上下文推理能力。
- 模态自适应切换器:在 DiT 块中引入可学习的模态嵌入列表 ,通过 AdaLN-Zero 机制生成模态特定的调制参数(scale , shift , gate )。
- 课程学习:将模态分为像素对齐(如深度、光流)和非像素对齐(如分割、骨骼)两组,分阶段进行混合训练以确保稳定收敛。
达到的效果
- 性能优越:在 Text-to-Video 生成、可控生成和视频深度/光流估计任务上,均达到或超越了现有 SOTA 方法(如 Kling1.6, HunyuanVideo, Aether 等)。
- 收敛速度提升:相比于单模态微调,联合多模态训练显著降低了训练损失,加速了收敛。
- 物理一致性增强:定性实验显示,UnityVideo 在生成涉及物理规律(如玻璃折射、水流)的视频时,比现有商业模型更符合物理逻辑。
方法
UnityVideo 在单个 Diffusion Transformer 中统一了视频生成和多模态理解。如图 3 所示,该模型通过共享的 DiT 主干网络 处理 RGB 视频 、文本条件 和辅助模态 。在训练过程中,本文动态采样任务类型并应用相应的噪声调度。为了在这个统一架构中处理多种模态,本文引入了上下文学习器 和 模态自适应切换器。通过渐进式课程训练,模型在所有任务和模态上实现了同步收敛。
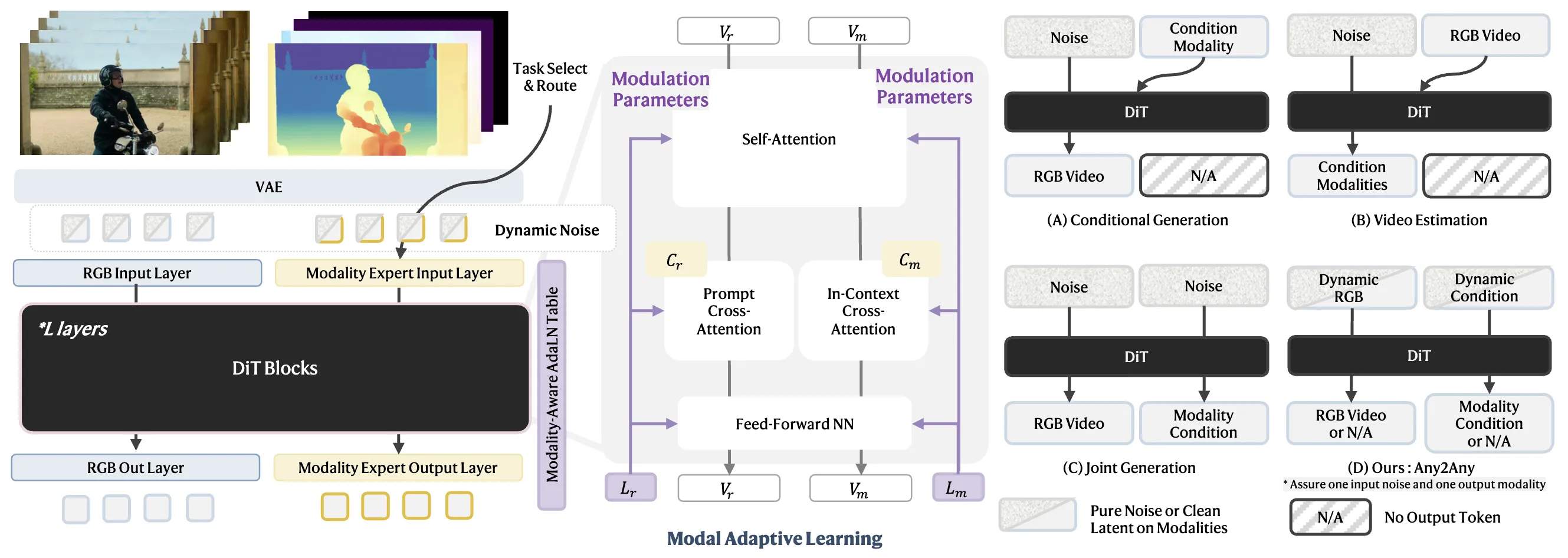 图 3.UnityVideo 概述。 UnityVideo 通过应用于输入标记的动态噪声注入策略(左)实现任务统一,并通过提出的模态感知 AdaLN 表(中)实现模态统一。 具体来说,和 分别表示 RGB 模态和辅助视频相关模态(例如深度、光流、DensePose、骨架)的可学习参数表。 和 表示 RGB 视频内容和上下文模态学习提示的提示条件,而 和 分别对应于 RGB 和辅助模态的标记序列。
图 3.UnityVideo 概述。 UnityVideo 通过应用于输入标记的动态噪声注入策略(左)实现任务统一,并通过提出的模态感知 AdaLN 表(中)实现模态统一。 具体来说,和 分别表示 RGB 模态和辅助视频相关模态(例如深度、光流、DensePose、骨架)的可学习参数表。 和 表示 RGB 视频内容和上下文模态学习提示的提示条件,而 和 分别对应于 RGB 和辅助模态的标记序列。
统一多任务

统一多模态
不同模态的联合训练可以显著提升单个任务的性能,如图 2 所示。然而,使用共享参数处理不同模态需要显式的机制来区分它们。本文引入了两种互补的设计:用于语义级模态感知的上下文学习器,和用于架构级调制的模态自适应切换器。
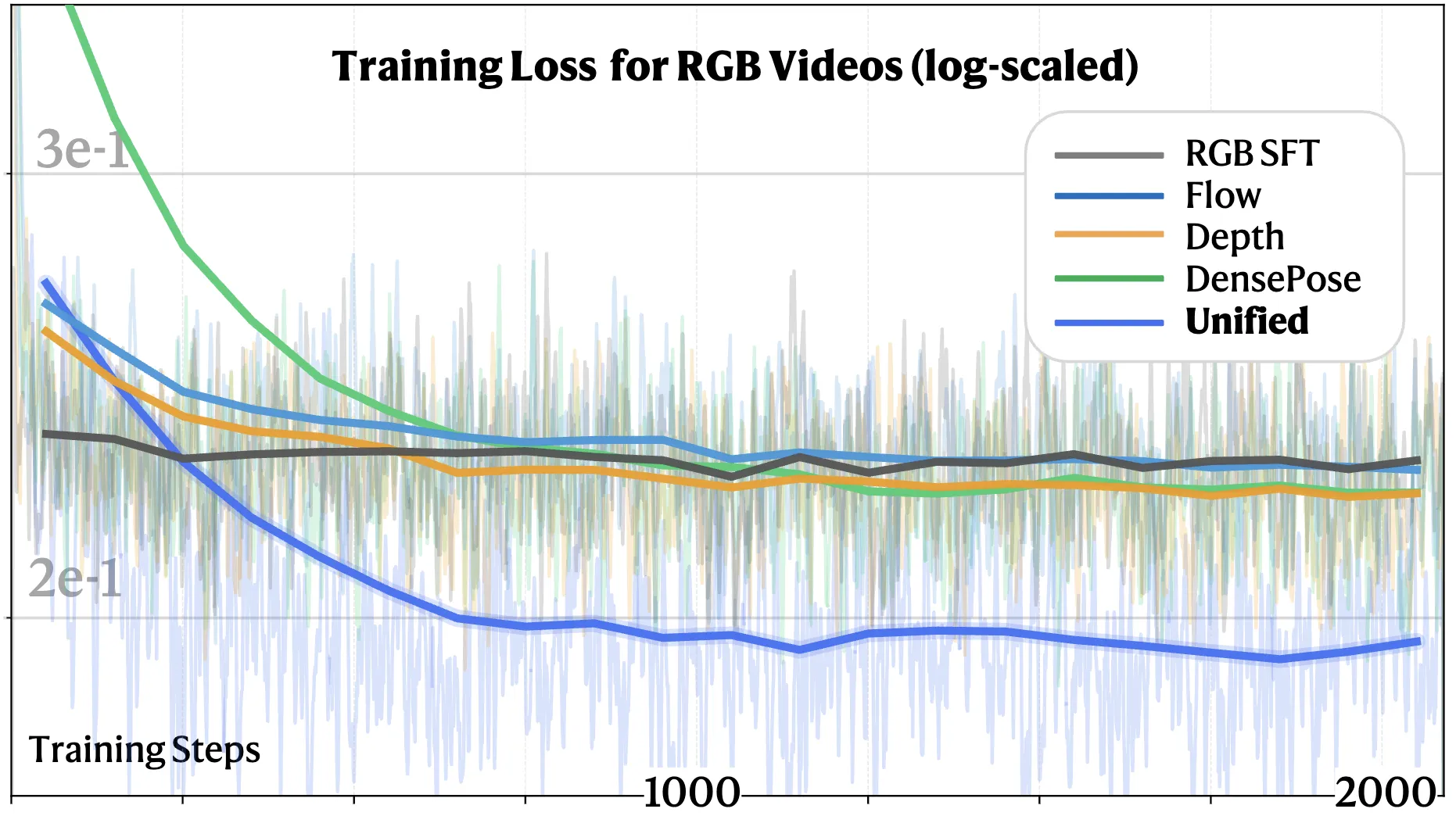 图 2.统一模式的培训有利于视频生成。 统一的多模态和多任务联合训练在 RGB 视频生成上实现了最低的最终损失,优于单模态联合训练和 RGB 微调基线。
图 2.统一模式的培训有利于视频生成。 统一的多模态和多任务联合训练在 RGB 视频生成上实现了最低的最终损失,优于单模态联合训练和 RGB 微调基线。

训练策略
多模态课程学习 简单地从头开始联合训练所有模态会导致收敛缓慢和性能次优。我们将模态根据其空间对齐属性分为两组。像素对齐模态(光流、深度、DensePose)允许与 RGB 帧建立直接的像素到像素对应关系,而像素非对齐模态(分割掩码、骨骼)则包含更抽象的几何表示且需要额外的视觉渲染步骤。
采用两阶段课程策略:第一阶段(Stage 1) 仅在经过筛选的单人数据上训练 RGB 视频和像素对齐模态,为空间对应关系的学习建立坚实基础。第二阶段(Stage 2) 引入所有模态以及多样化的场景数据集,涵盖以人为中心和通用的场景。这种渐进式策略使得模型能够理解所有五种模态,同时支持对未见模态组合的鲁棒零样本(zero-shot)推理。
OpenUni 数据集 我们的训练数据包含 130 万个视频片段,涵盖五种模态:光流、深度、DensePose、骨骼和分割。如图 4 所示,我们从多个来源收集真实世界的视频,并使用预训练模型提取模态标注。数据集包括 370,358 个单人片段、97,468 个双人片段、489,445 个来自 Koala36M的片段,以及 343,558 个来自 OpenS2V 的片段,共计 130 万个样本用于训练。为了防止对特定数据集或模态的过拟合,我们将每个批次(batch)划分为四个平衡的组,确保在所有模态和来源中进行均匀采样。
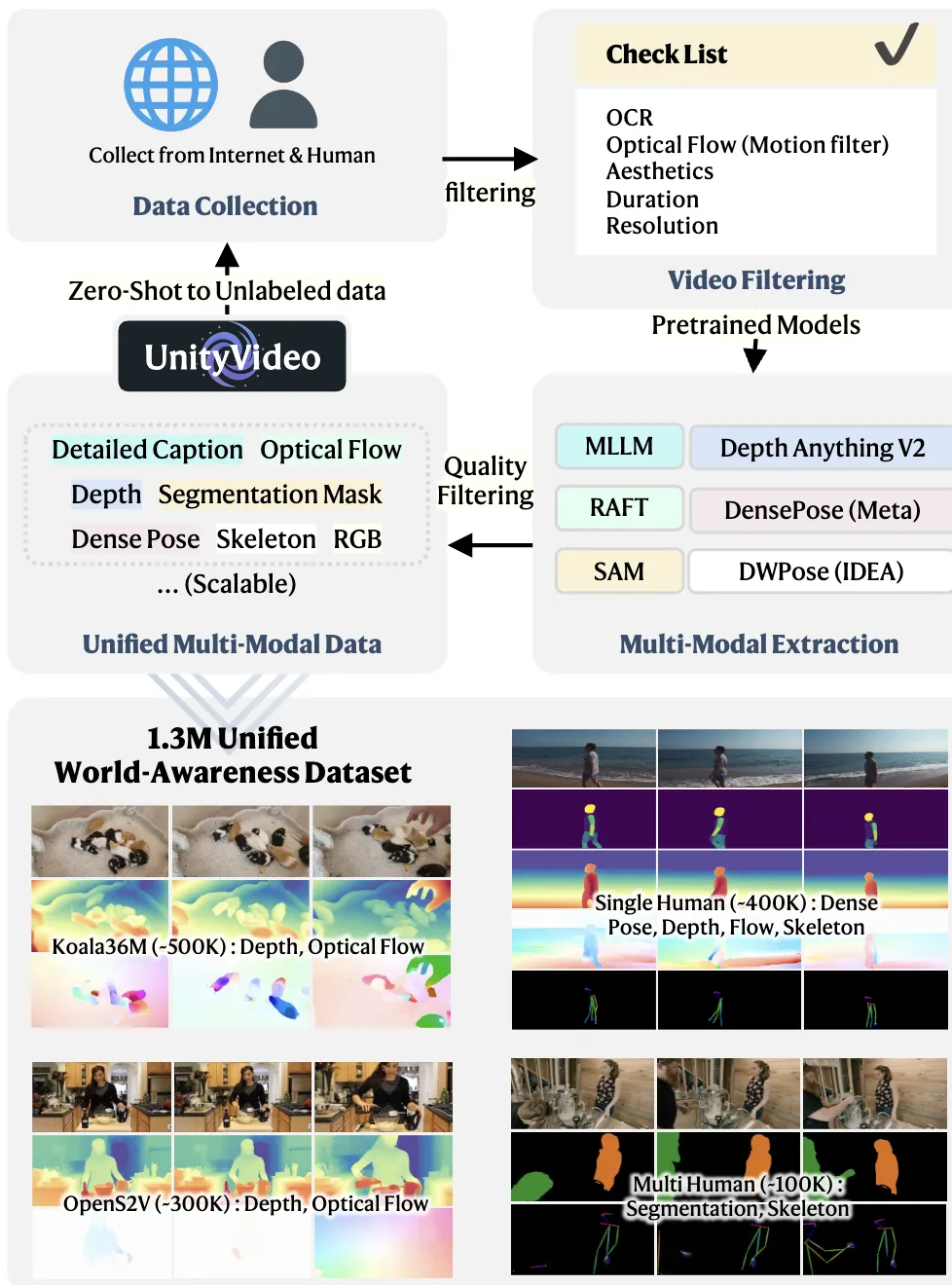 图4。OpenUni数据集。OpenUni包含130万对统一的多模态数据,旨在丰富视频模态,赋予更全面的世界感知
图4。OpenUni数据集。OpenUni包含130万对统一的多模态数据,旨在丰富视频模态,赋予更全面的世界感知
训练目标
遵循条件流匹配(Conditional Flow Matching),本文框架采用一种动态训练策略,通过选择性地对不同模态添加噪声,在三种模式之间自适应切换。特定模式的损失函数如下:

公式 (1) 实现了从辅助模态条件生成 RGB 视频,公式 (2) 执行从 RGB 视频进行模态估计,而公式 (3) 则从文本联合生成两种模态。
在训练过程中,批次中的每个样本被随机分配到这三种模式之一,使得所有任务都能在单个优化步骤中贡献梯度。这种统一的公式允许在单个架构内进行无缝的多任务学习。
实验
为了验证 UnityVideo 的有效性,本文在多个基准上进行了广泛的实验。
实验设置
- 数据集:使用了本文提出的 OpenUni 数据集,包含 130 万对多模态视频数据。
- 评测指标:
- 视频生成:使用 VBench 评估,包括主观一致性、背景一致性、美学质量、时间闪烁等指标。
- 深度估计:在 UniBench 数据集上评估,报告绝对相对误差 (AbsRel) 和阈值准确率 ()。
- 视频分割:报告平均精度 (mAP) 和平均交并比 (mIoU)。
主要结果
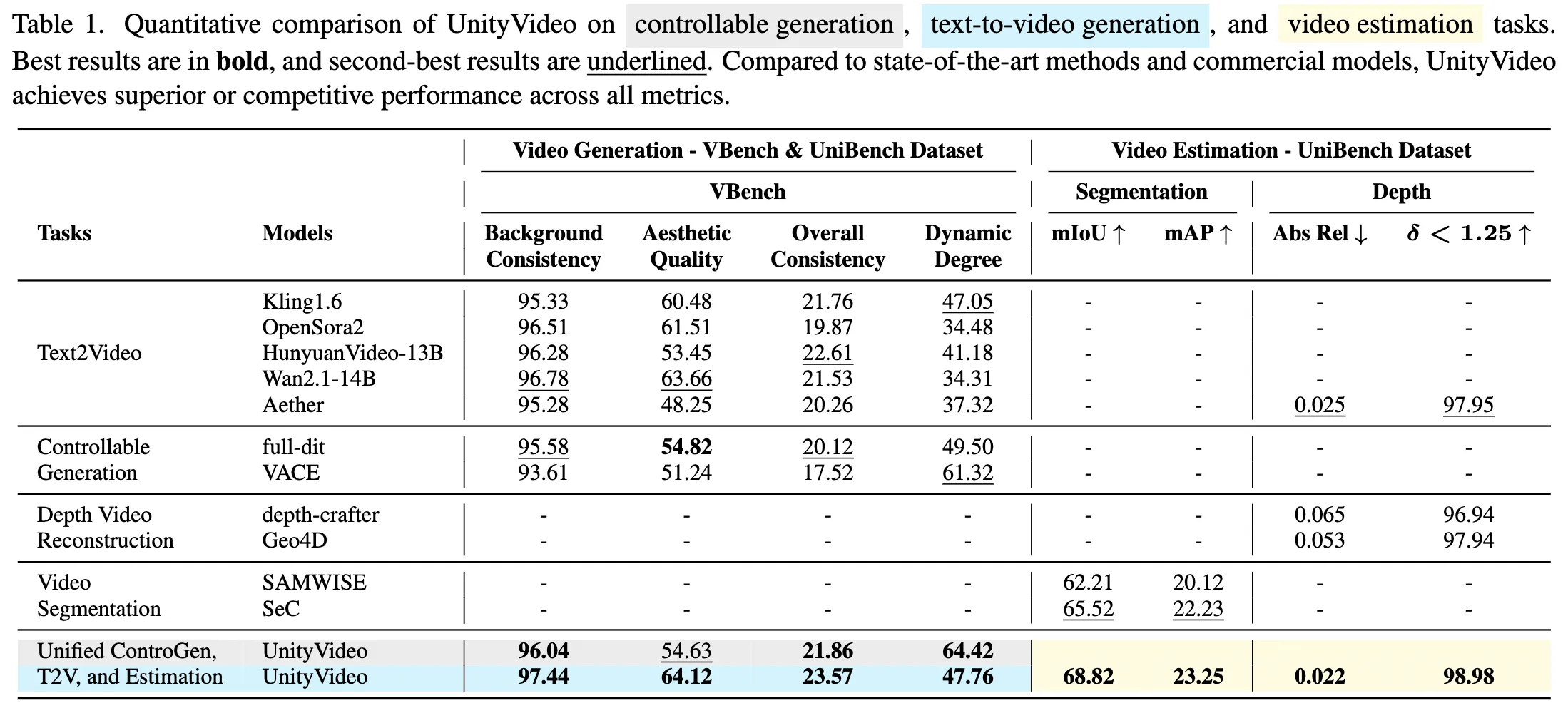
- 定量比较:如表 1 所示,UnityVideo 在文本生成视频、可控生成和视频估计任务上均取得了优异成绩。
- 在 T2V 任务中,UnityVideo 在所有指标上均优于 Kling1.6、OpenSora2、HunyuanVideo-13B 等模型。
- 在可控生成方面,相比 ControlNet 类方法(如 VACE),在一致性和动态程度上表现更好。
- 在视频估计方面,其深度估计和分割精度超越了专用模型(如 DepthCrafter, SAMWISE)。
- 定性比较:
- 物理感知:相比其他模型,UnityVideo 能更准确地反映物理现象(如水的折射)。
- 细节与一致性:在深度引导生成中,UnityVideo 既忠实于深度信息,又保持了高视频质量,避免了背景闪烁。具体见下图5.
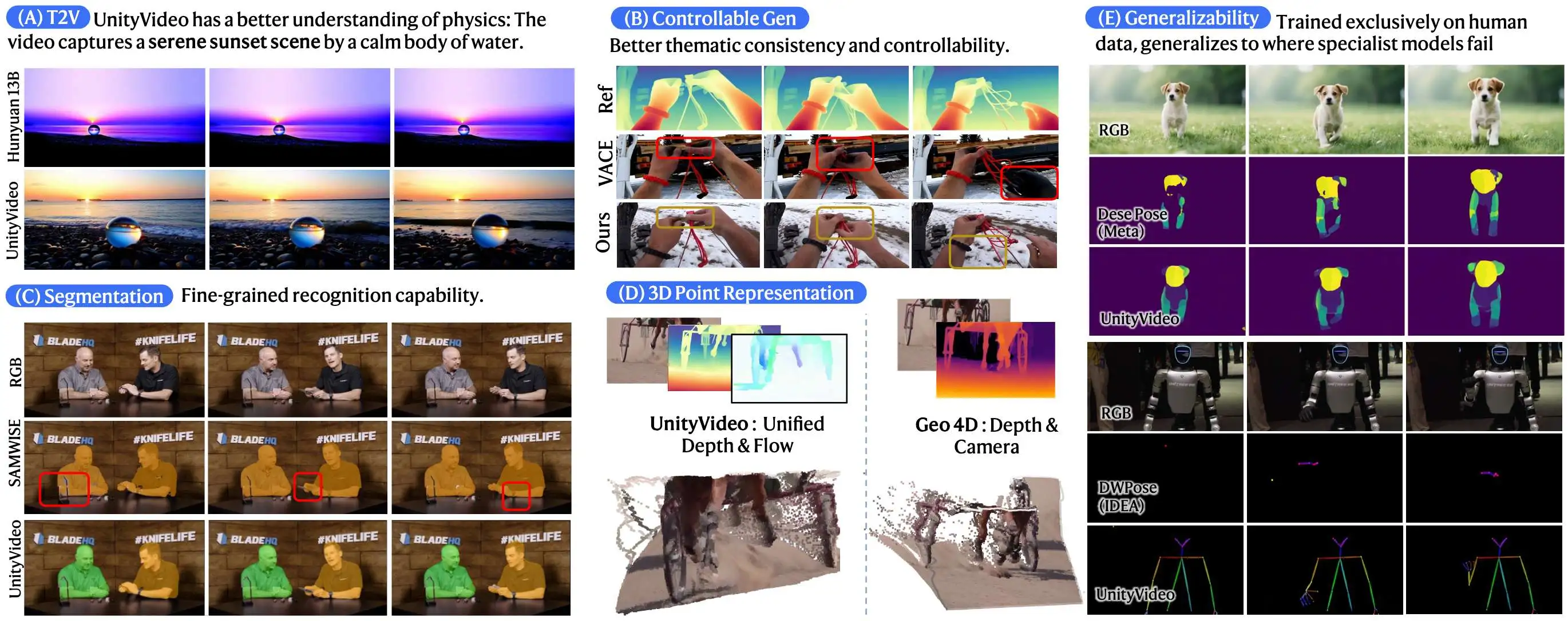 图5。与不同任务中SOTA方法的比较。UnityVideo展现出更优越的物理推理能力,更好地遵守控制条件,并对辅助模态有更深入的理解。
图5。与不同任务中SOTA方法的比较。UnityVideo展现出更优越的物理推理能力,更好地遵守控制条件,并对辅助模态有更深入的理解。
消融实验
- 多模态的影响:表 2 显示,联合训练多种模态(如深度+光流)比单独训练单一模态带来了一致的性能提升,特别是在图像质量和整体一致性上。
- 多任务训练的影响:表 3 表明,如果仅训练“可控生成”任务,性能会下降;而引入“联合生成”的多任务训练可以恢复甚至超越基线性能。
- 架构设计的影响:表 4 和图 6 证明,上下文学习器和模态切换器各自都能提升性能,而两者结合使用效果最佳。
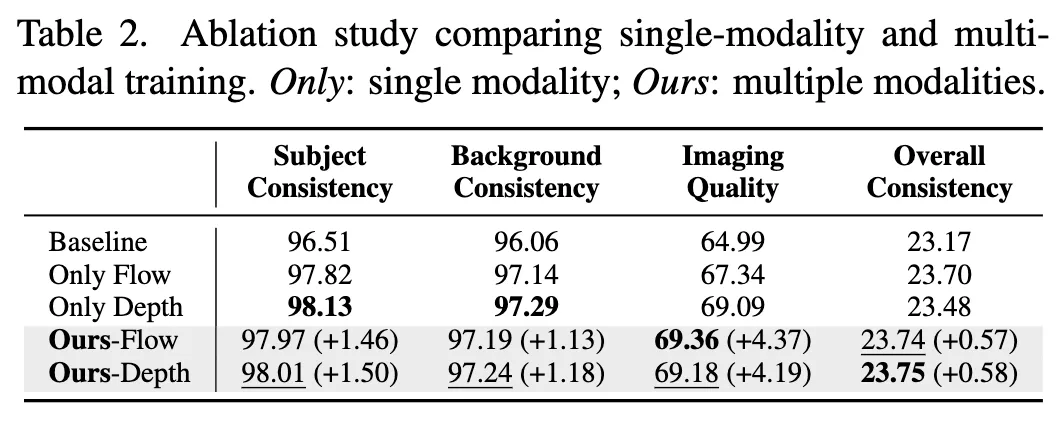
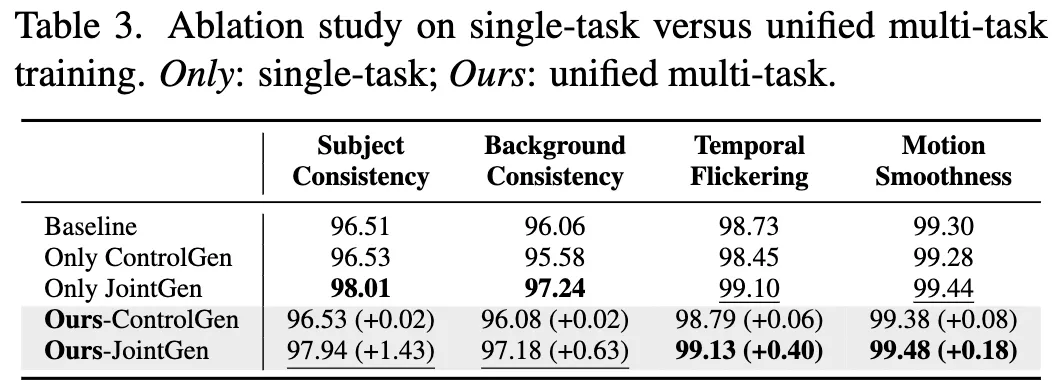
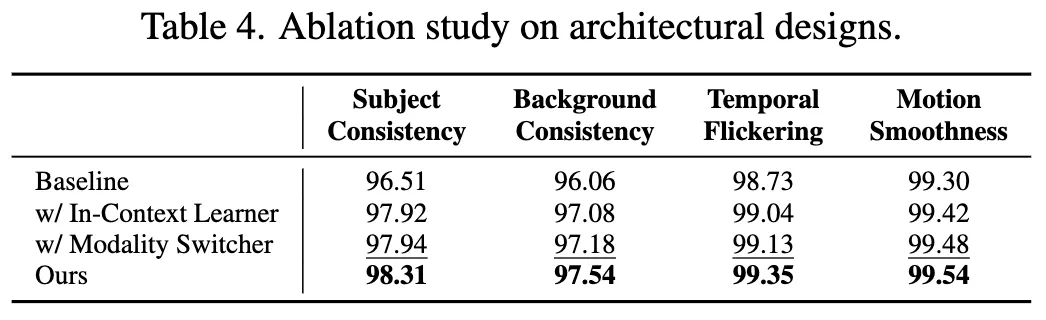

模型分析与用户研究
- 泛化能力:图 7 展示了上下文学习器使得模型能够将针对“人”的训练泛化到未见过的“物体”分割上。
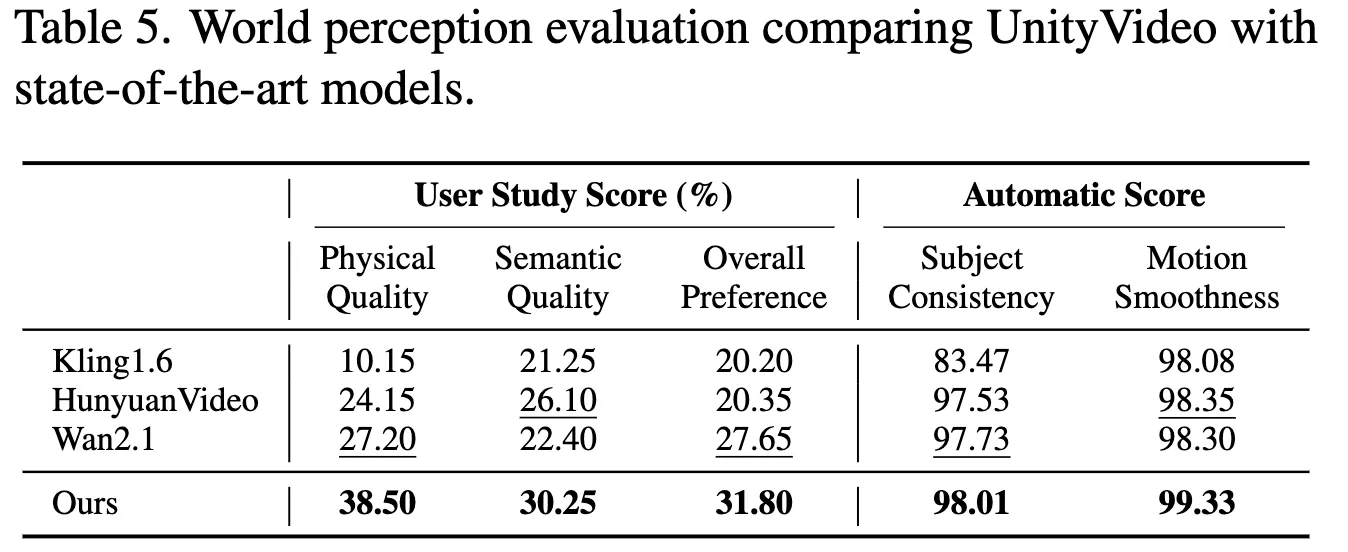
- 用户研究:在包含 70 个样本的人工评估中,UnityVideo 在物理质量、语义质量和整体偏好上均获得了最高评分(表 5)。

总结
UnityVideo,这是一个在单一 Diffusion Transformer 中对多种视觉模态和任务进行建模的统一框架。通过利用模态自适应学习,UnityVideo 实现了 RGB 视频与辅助模态(深度、光流、分割、骨骼和 DensePose)之间的双向学习,从而在两类任务上都实现了相互增强。本文的实验展示了其在不同基准上的最先进性能,以及对未见模态组合的强大零样本泛化能力。为了支持这项研究,本文贡献了 OpenUni,这是一个包含 130 万同步样本的大型多模态数据集,以及 UniBench,这是一个带有真值标注的高质量评估基准。UnityVideo 为统一多模态建模铺平了道路,是迈向下一代世界模型的重要一步。
参考文献
[1] UnityVideo: Unified Multi-Modal Multi-Task Learning for Enhancing World-Aware Video Generation
