
2025,大模型文档解析(OCR)年终盘点

文章转载自[PaperAgent ]
大家好,我是PaperAgent,不是Agent!
今年6月以来文档解析(Document Parsing)方法的快速增长,总结下来有10余种:
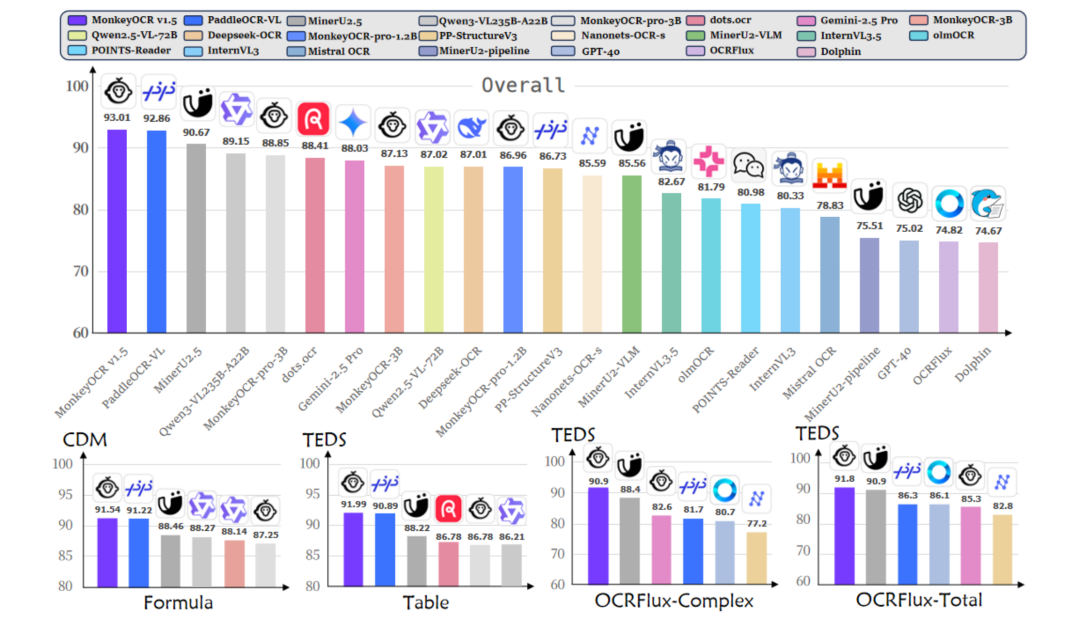
有使用需求的小伙伴,可以参考OmniDocBench评分选择使用: 在OCR面前,大模型虽好,但恕我直言:开源小模型更香
把这些 方案按“技术路线 + 工程形态”两个维度收拢,可以归结为 4 大类:传统级联流水线、模块化专用VLM、通用VLM、端到端专用VLM
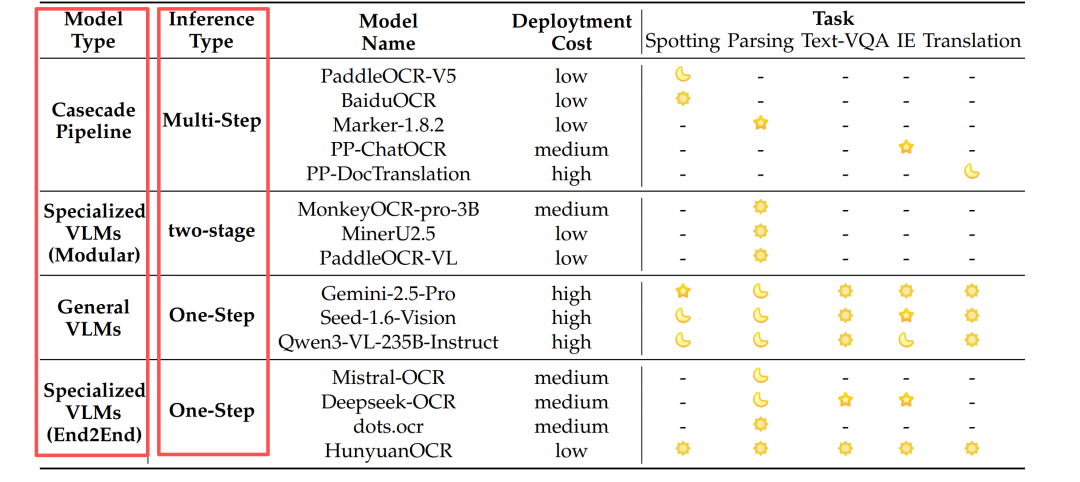
1. 传统级联流水线
检测 → 识别 → 版面 → 后处理,每一步独立模型;优点灵活、成本低,缺点误差累积、链路长。
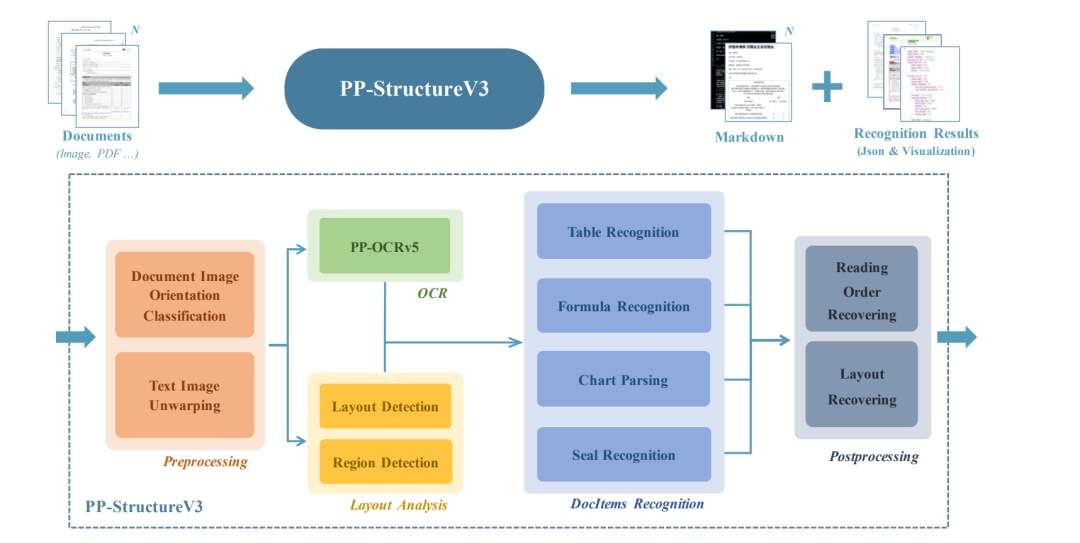
PP-StructureV3
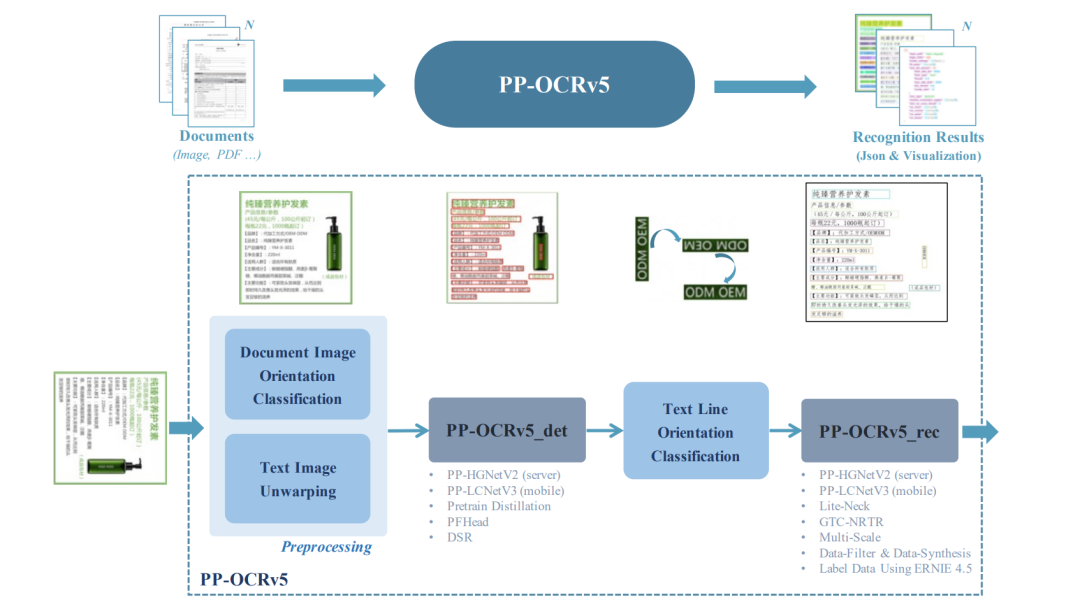
流程包括预处理、OCRv5、版面分析、文档元素识别与后处理,可有效解析图像内容并以结构化数据形式输出。
PaddleOCR-V5
流程包括图像预处理、文本区域检测、文本行方向分类和文本识别,最终从图像中提取文字并以结构化文本形式输出。
Mineru2-pipeline
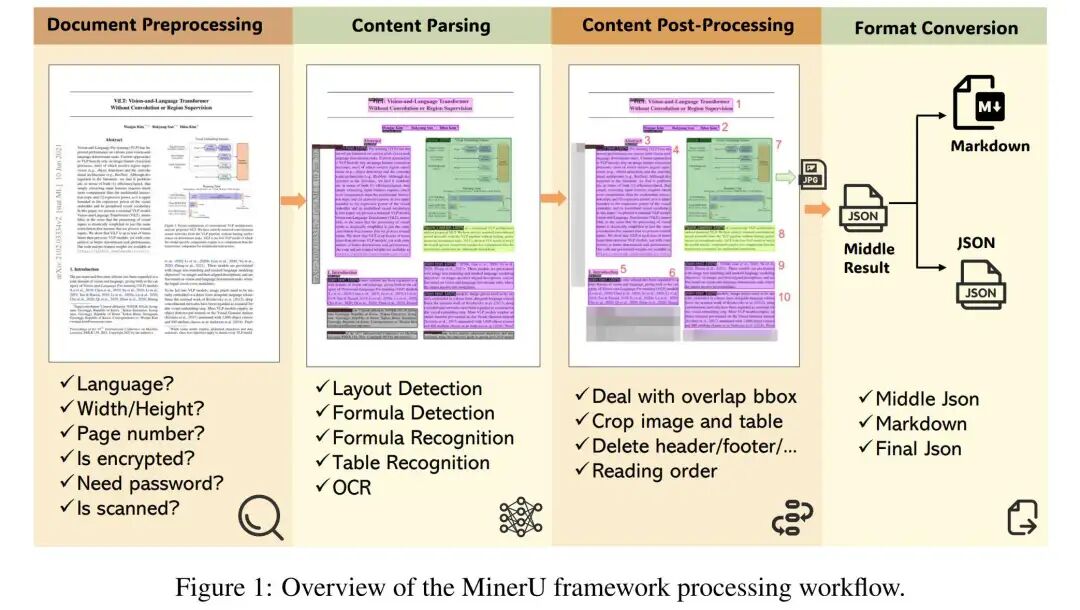
MinerU框架处理工作流:文档预处理/内容解析/内容后处理/格式转换
2. 轻量多模态两段式
先用小模型做版面/阅读顺序,再用“专供 OCR 的小型 VLM”做内容识别;算力比通用大模型省,精度又比流水线高。
PaddleOCR-VL
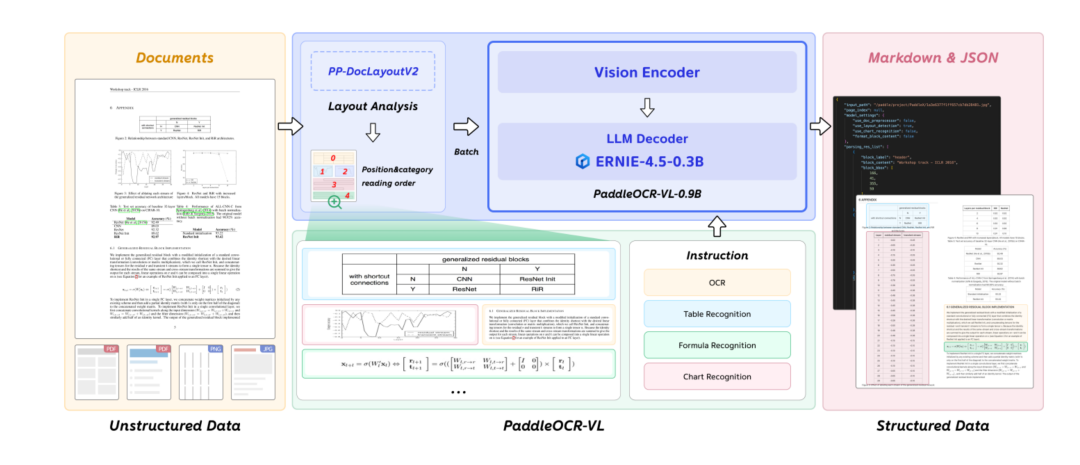
用专用小模型PP-DocLayoutV2做“版面分析”,把文档切成“文本块/表格/公式/图表”,并给出阅读顺序;
用0.9B视觉语言模型PaddleOCR-VL-0.9B逐一识别每个区域;
轻量后处理把结果拼成Markdown/JSON。
https://arxiv.org/pdf/2510.14528
MonkeyOCR-1.5
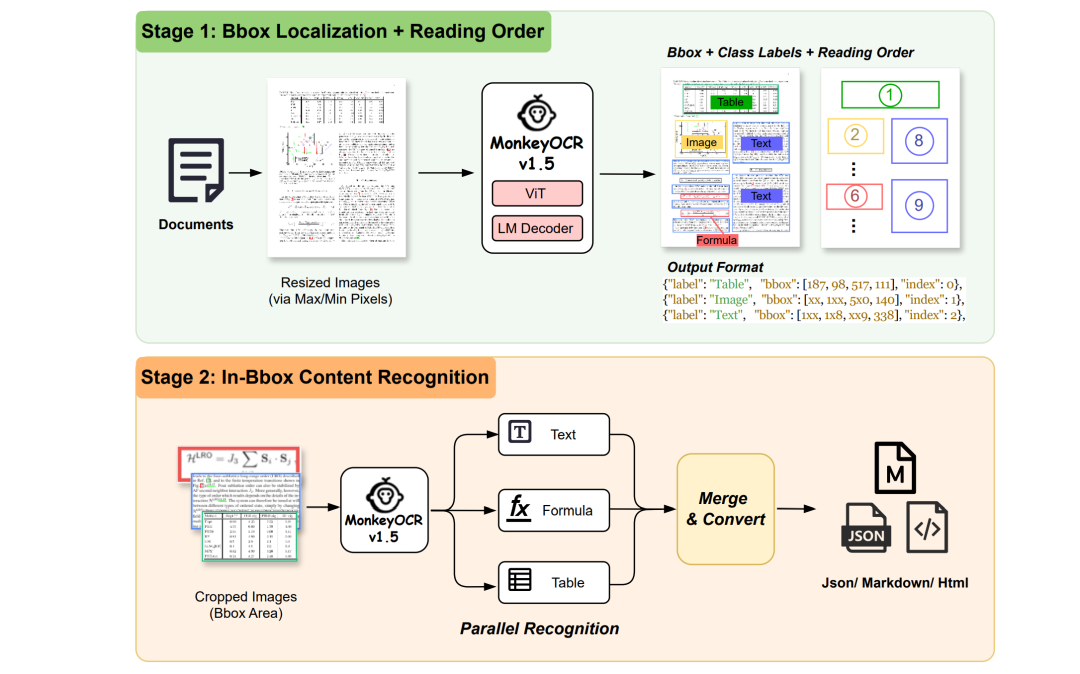
MonkeyOCR v1.5 整体流程——先检测所有版面元素并生成顺序索引,再借助 VLM 并行识别各元素内容。
https://arxiv.org/pdf/2511.10390v2
MinerU2.5
MinerU2.5 的核心思想是“先全局后局部、先结构后语义”的解耦范式。 Stage-I Layout Analysis:低分辨率缩略图→快速全局版面检测+阅读顺序+旋转角; Stage-II Content Recognition:依布局裁剪原图关键区→并行送入原生分辨率 ViT→轻量 0.5 B LM 解码,输出 OCR/公式 LaTeX/表格 OTSL。
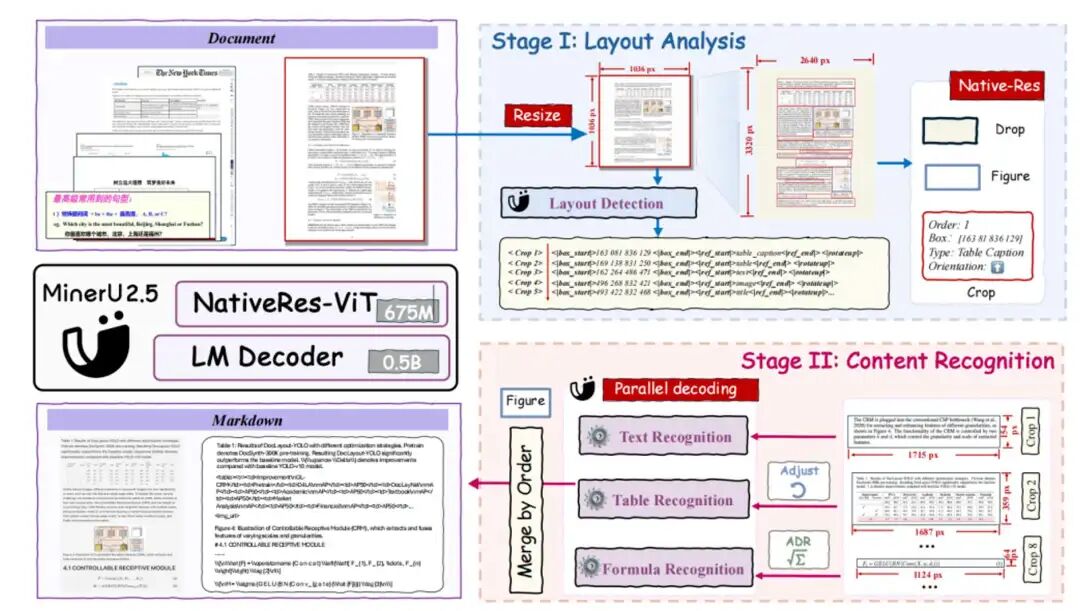
https://arxiv.org/pdf/2509.22186
3. 通用多模态大模型一段式
整张图直接扔给百亿级通用视觉-语言模型,一步出文本;效果上限最高,但 GPU 贵、吞吐低。 典型代表:Gemini-2.5-Pro、Qwen3-VL-235B、Seed-1.6-Vision、Qwen2.5-VL-72B、InternVL3.5-241B、GPT-4o
4. 轻量多模态一段式
dots.ocr
dots.ocr 是一款功能强大、支持多语言的文档解析模型,它在单一的视觉语言模型中统一了布局检测和内容识别,同时能保持良好的阅读顺序。参数规模小17亿参数
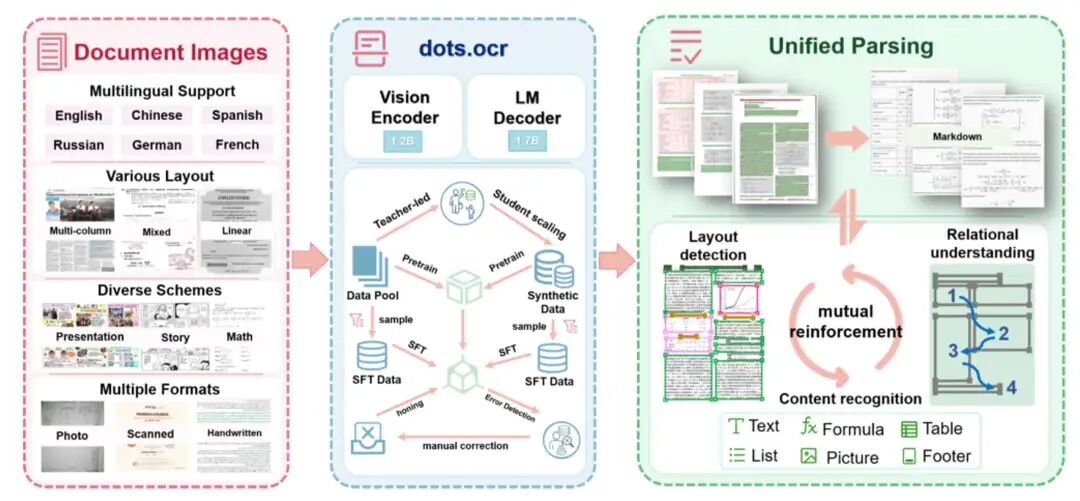
https://github.com/rednote-hilab/dots.ocr
Deepseek-OCR
DeepSeek-OCR把长文本渲染成图片,用多分辨率视觉编码器(16×卷积+窗口/全局注意力)将大图压成极少token(最低100),经MoE解码器还原,实现10-20×无损压缩,突破文本token瓶颈。

https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
HunyuanOCR
HunyuanOCR 架构——一个端到端框架,集成原生分辨率视觉编码器、自适应 MLP 连接器和轻量级语言模型,可统一完成多种 OCR 任务:文本检测识别、版面解析、信息抽取、视觉问答以及图像文本翻译。

https://arxiv.org/pdf/2511.19575
一句话
“传统流水线、专用两段 VLM、通用一段大模型、以及端到端专用VLM”——4 条路线覆盖当下所有 OCR 落地场景。
每天一篇大模型Paper来锻炼我们的思维~已经读到这了,不妨点个👍、❤️、↗️三连,加个星标⭐,不迷路哦~
