
8个专业技巧,让你的n8n工作流稳如老狗


作为程序员,我们总是在追求效率和优雅的代码。我们用各种框架和工具,把复杂的业务逻辑安排得明明白白。但总有一些时候,我们会被一些“破事”拖慢脚步。
比如,每天都要从数据库里导出一份报表,手动发给运营;又或者,每次代码合并请求,都得手动去通知审核团队;再比如,为了测试一个接口,需要在好几个系统之间切来换去,手动构造各种数据…
这些事情,说难不难,但就是繁琐。我们明明是来创造世界的,怎么能把时间浪费在这些重复性的劳动上呢?
很多时候,我们可能会觉得,为了一个小需求就去写个脚本,有点“杀鸡用牛刀”。但如果有一个可视化的工具,让你通过拖拉拽的方式,就能轻松地将这些繁琐的流程自动化,是不是听起来就很酷?
这正是我今天要跟你聊的 n8n。还没用过的看这篇:0元线上部署n8n,2核+16G+无限流量 。
在接下来的这篇文章里,我将结合我最近踩过的一些“坑”,跟你分享 8 个能让你在搭建自动化工作流时,效率翻倍的小技巧。
小技巧
做好命名工作
创建工作流后,在右上角输入 workflow 名称和 tag,方便检索。
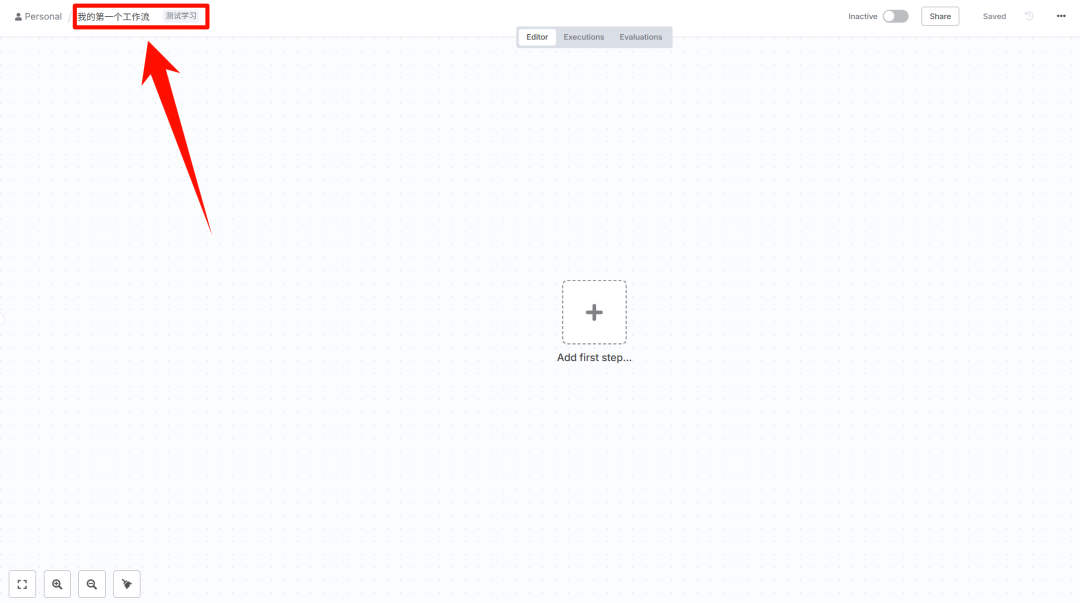
回到首页后,方便检索信息
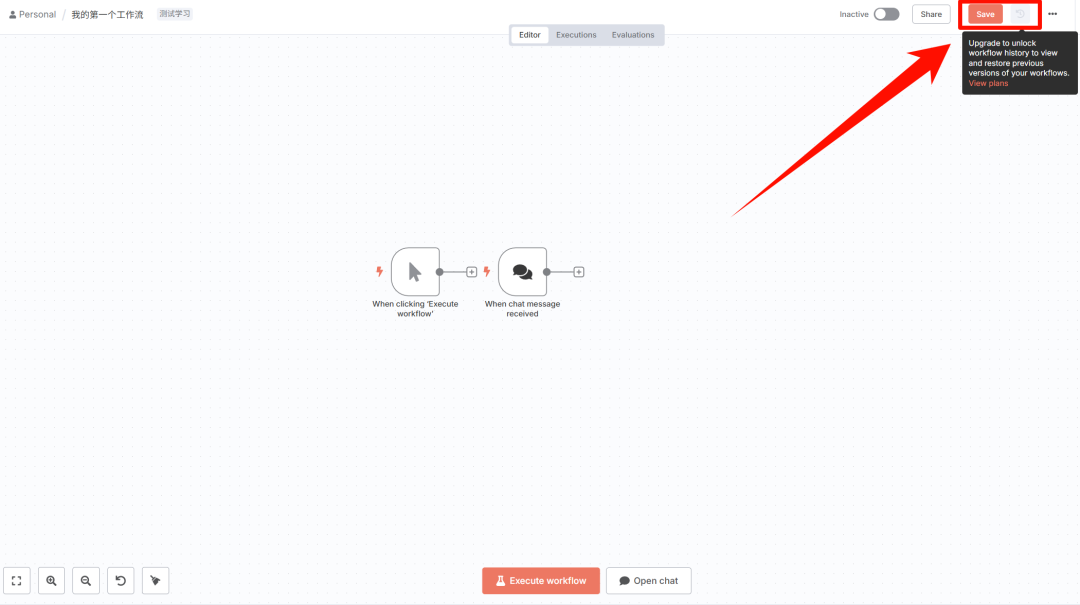
及时保存进度
开发过程中,如需保存点击右上角「Save」,在其右侧有一个需要付费打开的版本管理。
如果不想付费打开的话,那就及时复制工作流到本地保存吧。
Setting 设置
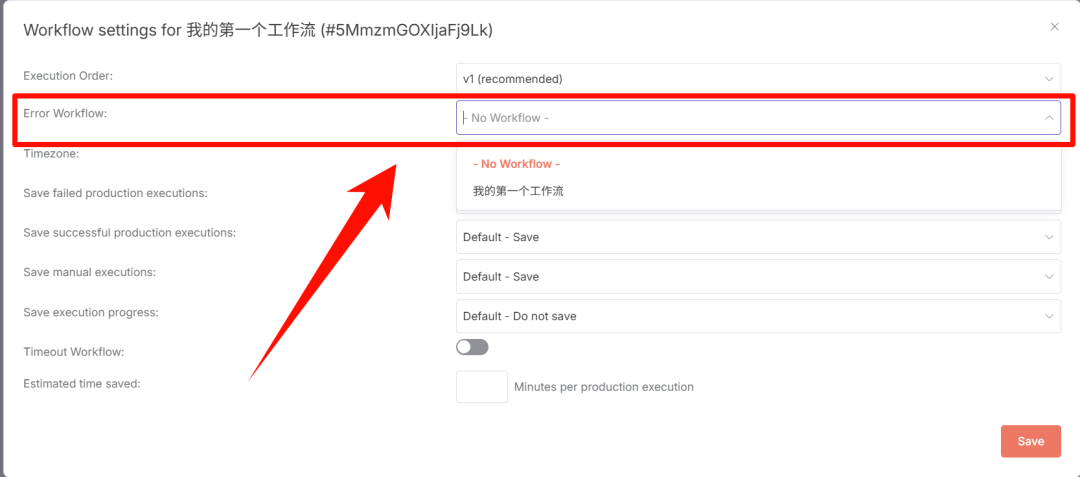
右上角有「...」的设置功能。
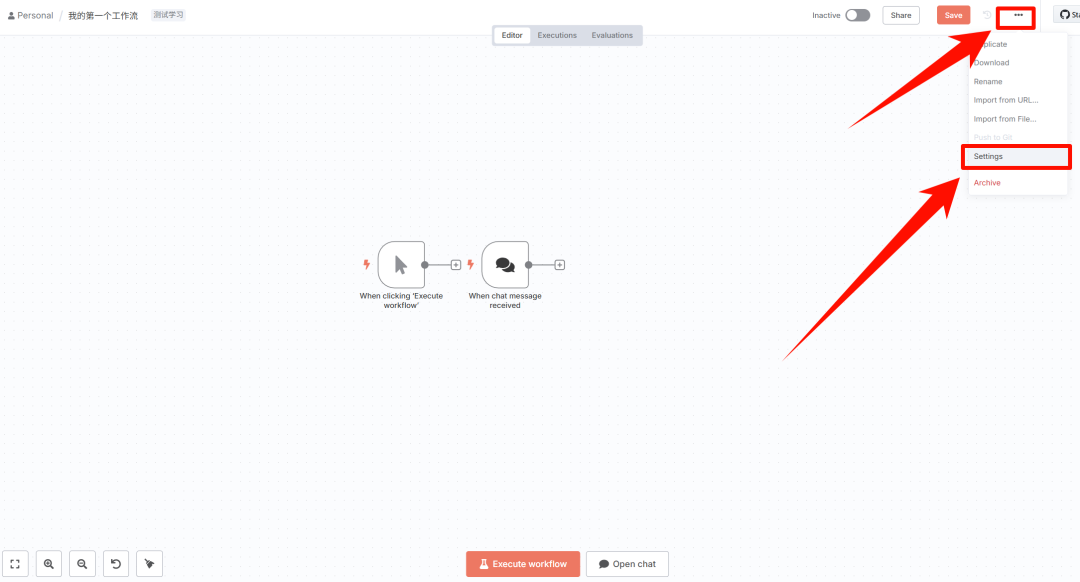
可以设置工作流出错后调用的工作流,比如可以设置出错后发送通知。
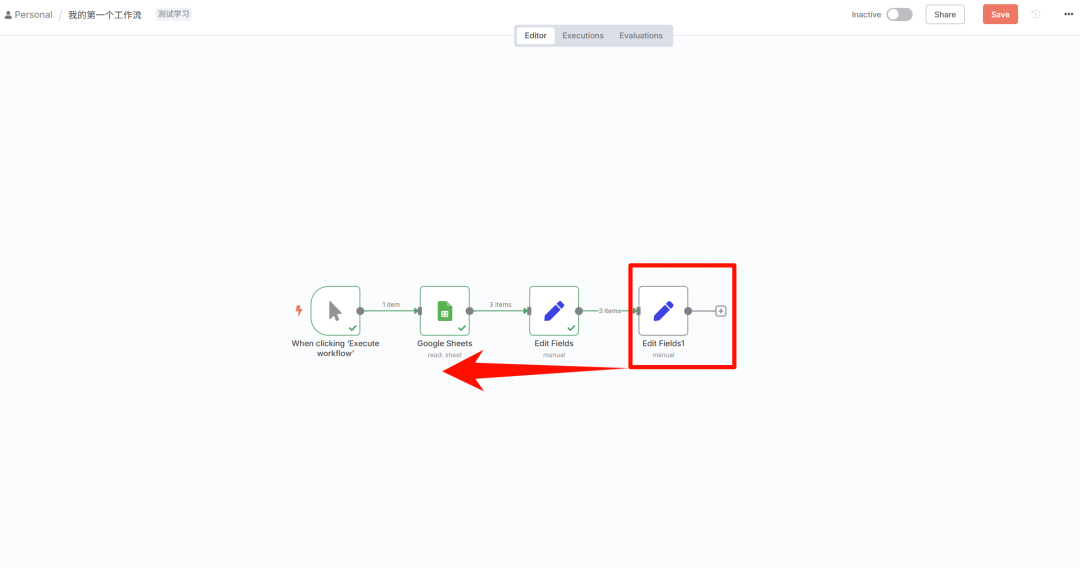
节点信息获取
如果需要在原本流程中加一个处理节点
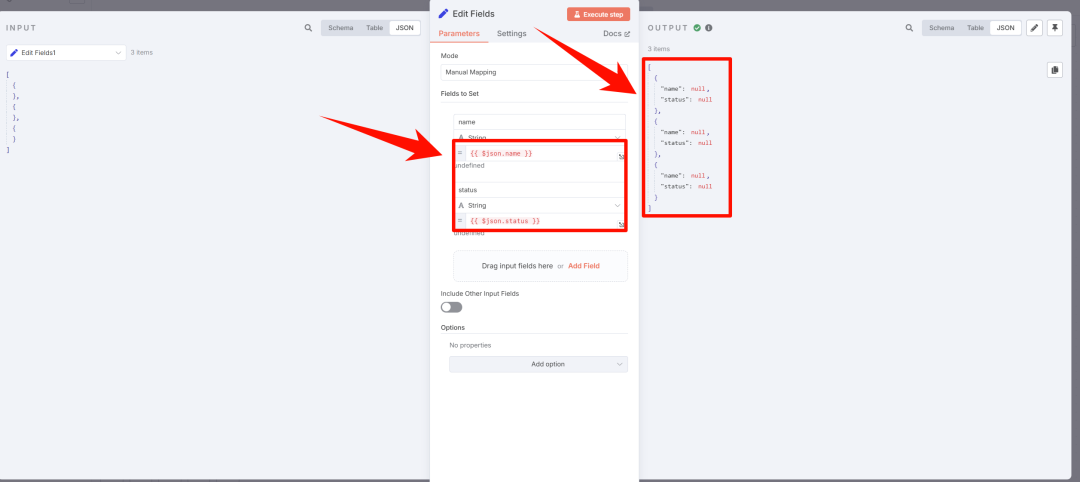
就会发现,用 {{ $json.xxx}}获取信息的方式都失效了,因为这种获取方式默认指向了前一个节点,而现在中间接入了一个新节点。
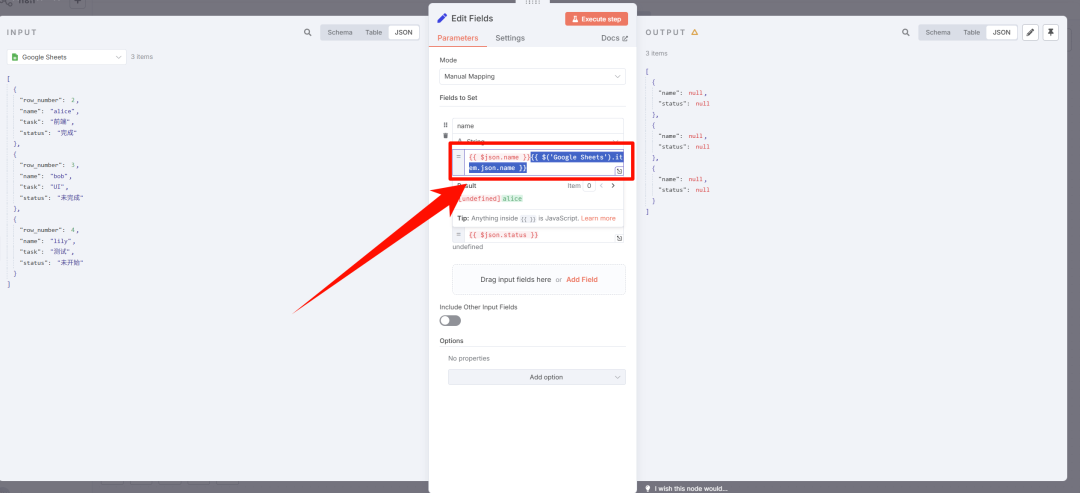
这时候,就需要利用节点名称来进行全局获取{{ $('xxx').item.json}}。
暂存数据信息
每次运行工作流都会获取所有信息,但如果测试的时候,其实没必要频繁获取。
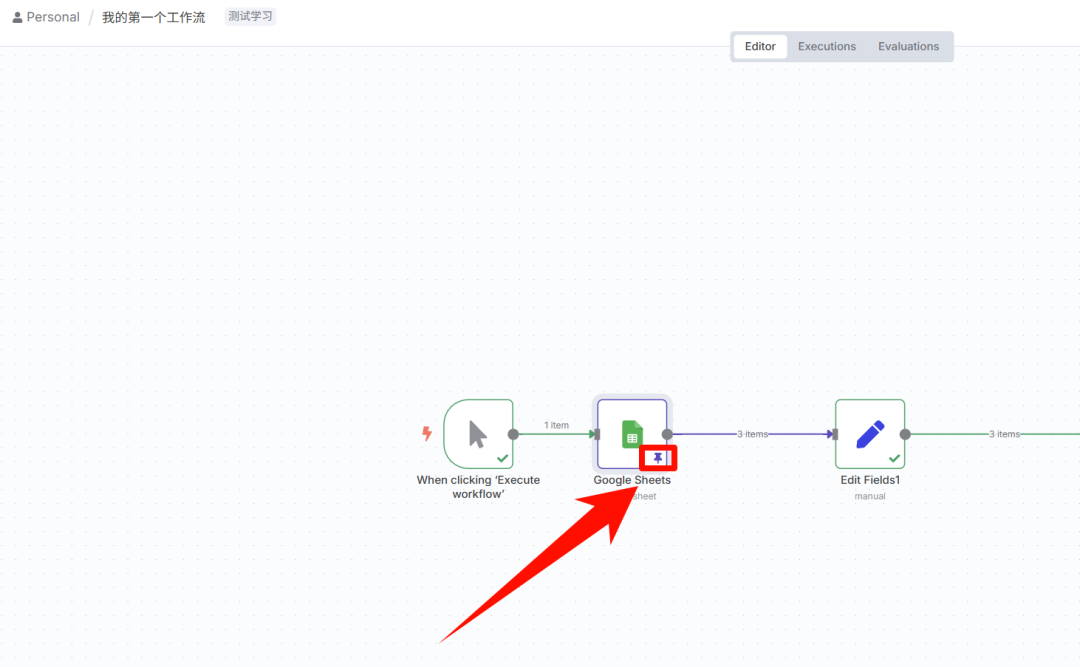
这时候我们就可以Pin住信息,这样工作流就会暂存信息,无需每次去拉取。
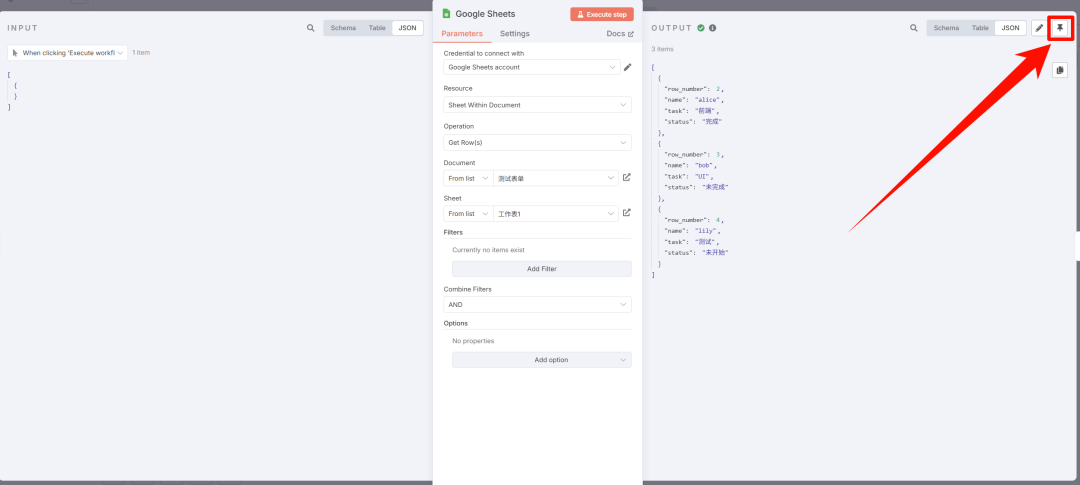
但是正式运行的时候记住要取消,否则每次都是固定的数据,新手可能会认为是个 bug,浪费很多时间在找问题上。
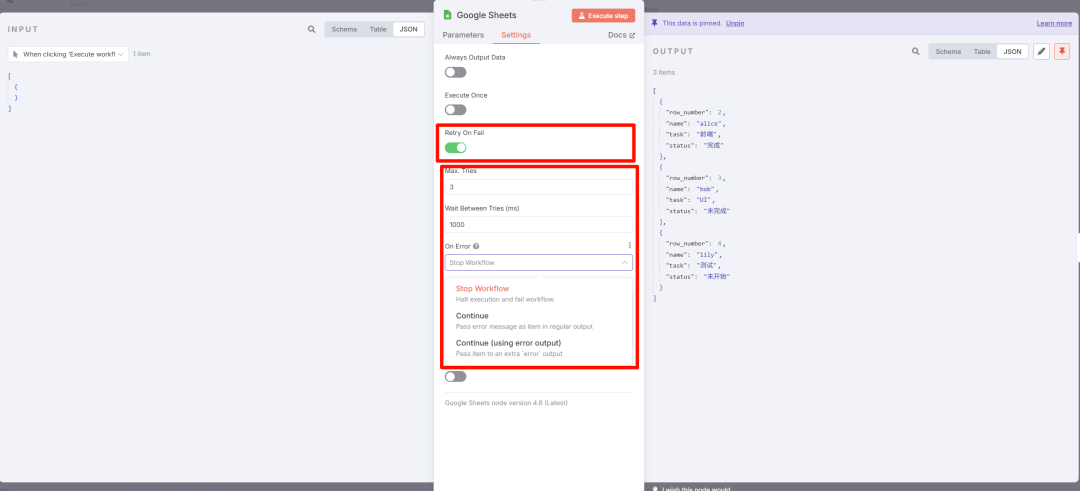
节点失败重试
实际情况中,并不可能每次节点或者 API 都那么稳定,一次成功,所以很多情况下需要设置一个「失败重试(Retry On Fail)」。
主要参数有:最大尝试次数(Max. Tries)、尝试间隔(Wait Between Tries (ms))、失败后的默认操作(On Error)。
失败后可以选择「停止」、「继续」、「输出错误信息」等操作。
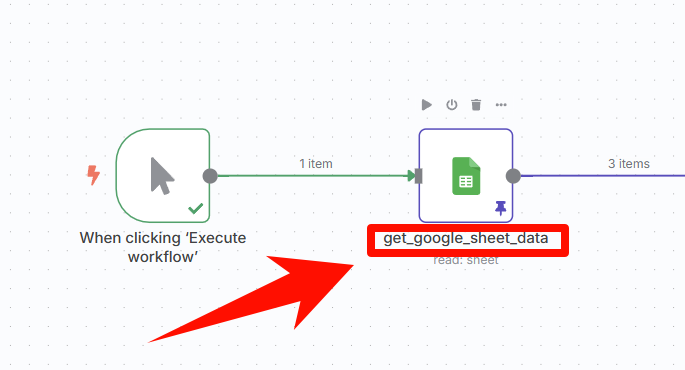
节点命名方式
通常工作流也是数据流,可以参考数据的流向来进行命名。
比如数据有增删改查,可以考虑用 add、delete、modify、get 等来标注。并且常用的命名方式有下划线「_」间隔或者驼峰形式「getGoogleSheetData」,每个首字母大写,其余小写。
写过代码的肯定一下就懂了。
工作流的注释
把鼠标放到右侧「+」附近时,会出来一个「note」便签标贴,利用快捷键「shift + S」可直接添加。
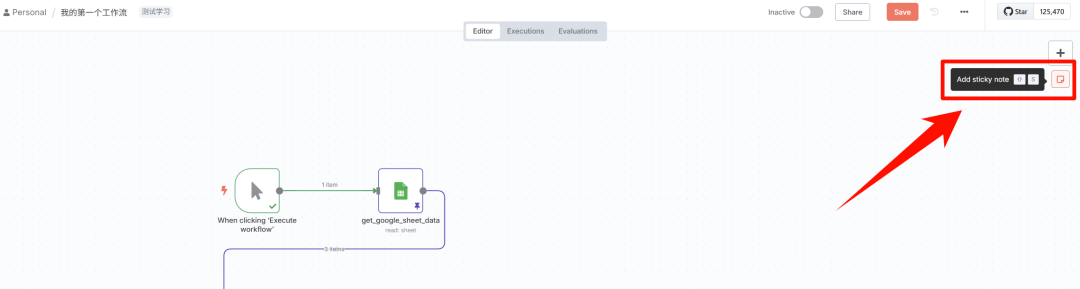
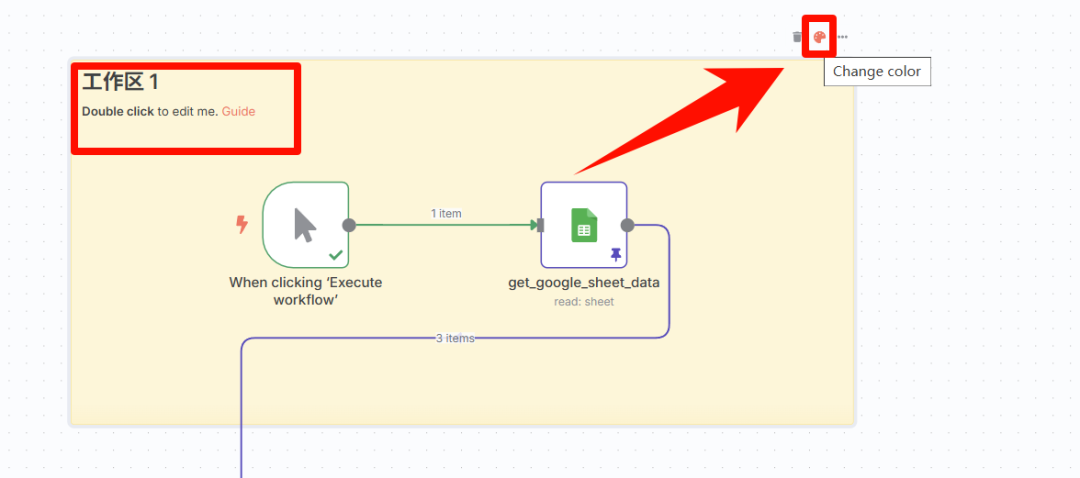
移动和缩放后,可放置在节点后方,高亮一块区域,放置鼠标在区域上,右上角图标可以改变颜色。
红框内文字,双节可修改(markdown 语法),可用来功能注释,避免开发后忘记相关信息。
结语
我们掌握的每一个技巧,每一次对细节的打磨,其最终目的,都是为了构建一个更可靠、更智能的自动化体系。
而这个体系的价值,并不仅仅在于节省了多少时间,更在于它将我们从重复的、机械的束缚中解放出来,让我们能将宝贵的精力,投入到更富创造力、更具挑战的价值创造中去。
愿我们都能成为驾驭工具的大师,而非被流程束缚的执行者。把重复交给机器,把创造还给自己。
原文链接:https://mp.weixin.qq.com/s/byNTR5gJs6lfPg4hjcALzA
转载自[纯AI老王]
