
脑部核磁共振模型:BrainFound 推荐与部署实操


目录
1. BrainFound 强在哪?
BrainFound 是一个专门针对脑部 MRI 影像的 3D 自监督基础模型。简单来说,它把计算机视觉里很火的 DINOv2 框架从 2D 图片扩展到了 3D 体积数据,专门用来处理脑部扫描图。
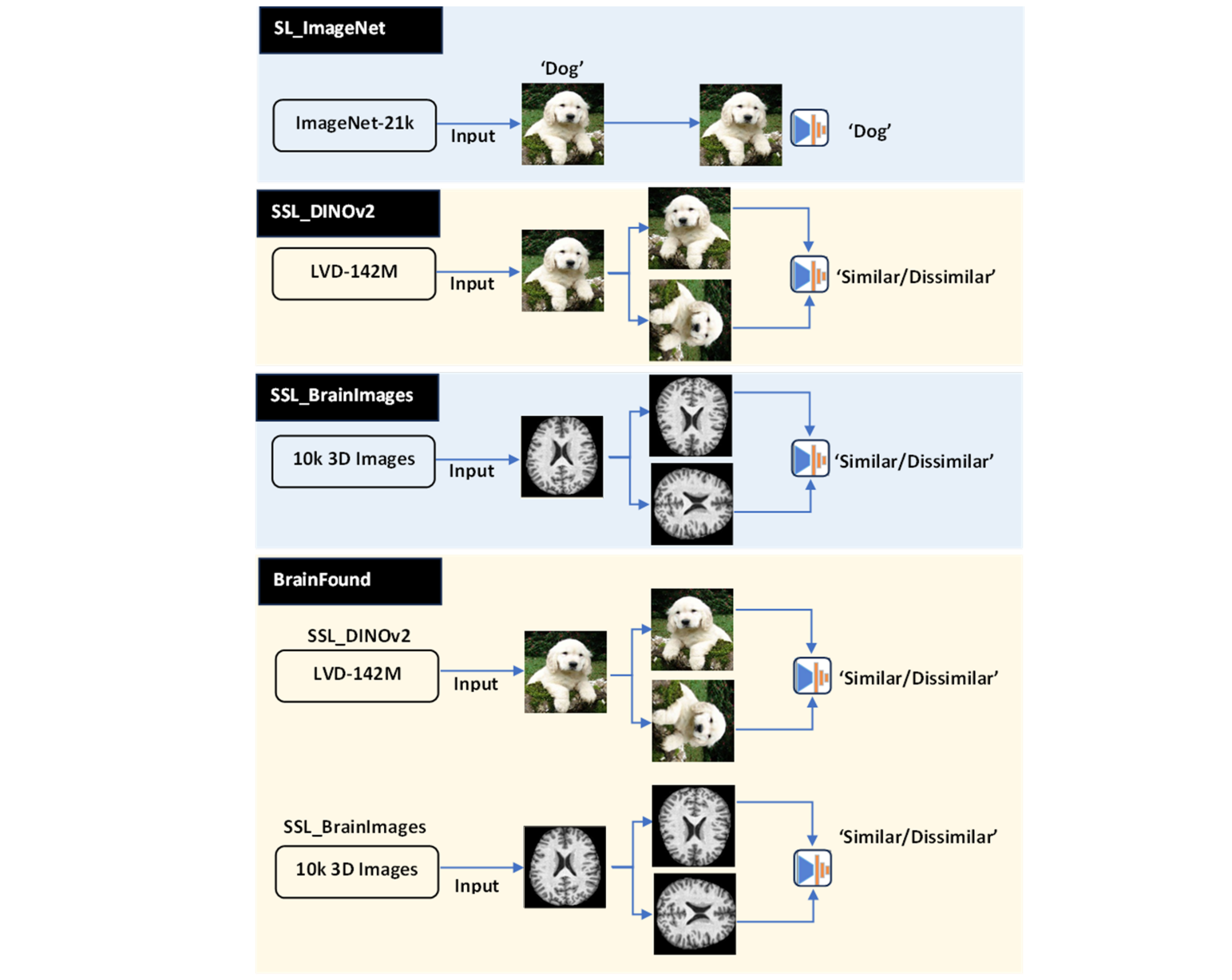
图1:BrainFound采用师生自蒸馏机制,教师网络生成稳定特征,学生网络从无标签数据中学习通用表示
相比传统模型,它的核心优势:
- 省标注数据: 传统 AI 需要医生一张张标数据,太贵太慢。BrainFound 是自监督的,能从未标注的数据里自己学特征。哪怕你只有极少量的标注数据,它也能跑出很好的分类或分割结果。
- 真·3D 视野: 很多模型是把 MRI 切成一张张 2D 切片看,容易丢失空间关系。BrainFound 直接处理 3D 体积数据,就像看整个雕塑而不是看切片,诊断更准。
- 多模态通吃: 支持 T1、T2、FLAIR 等多种扫描模式,可以把它们的信息融合在一起分析,互补不足。
- 不挑食: 无论是各向同性还是各向异性的扫描分辨率,它都能适应。
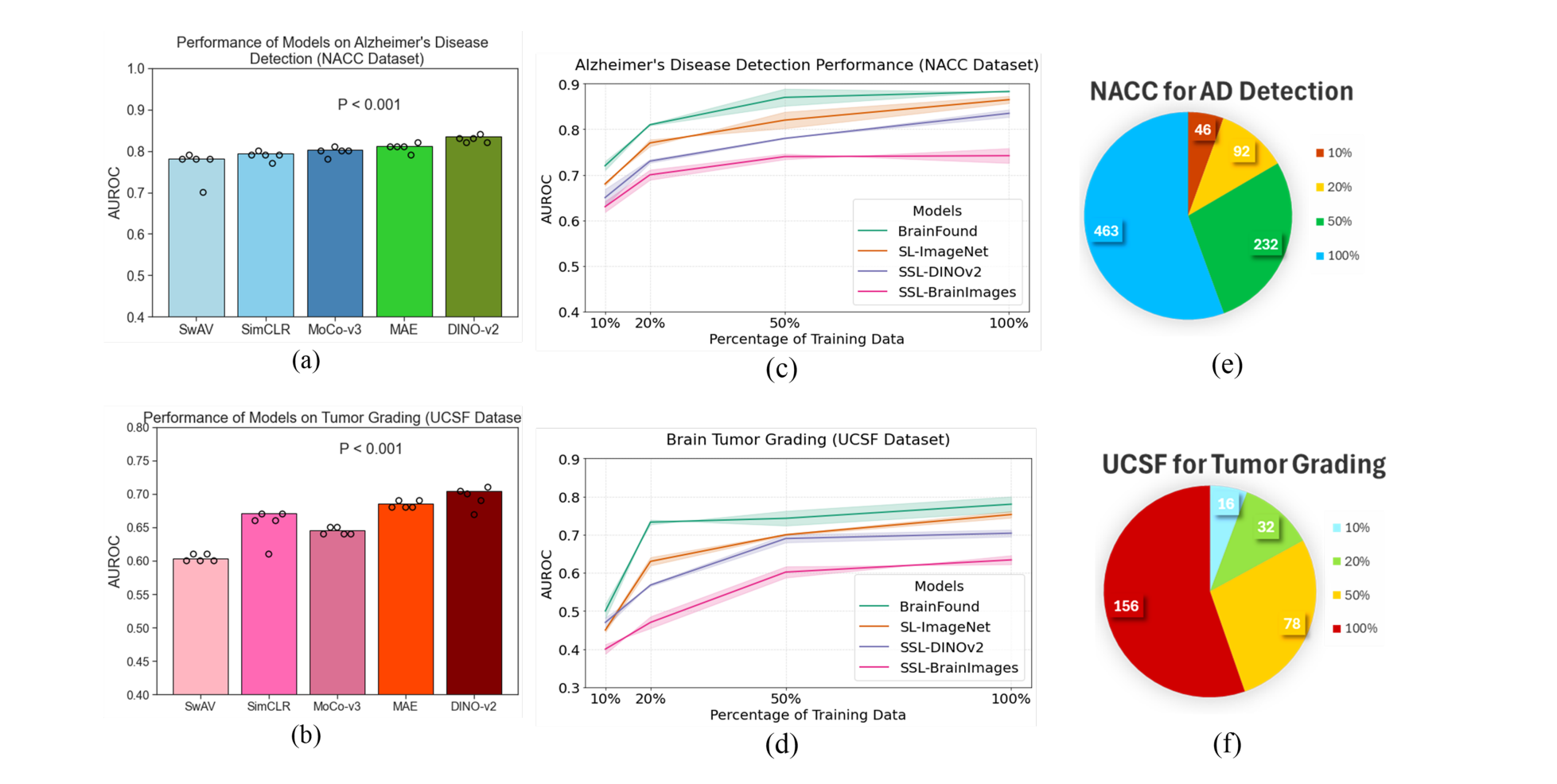
图2:少样本场景下(仅10%标注数据),BrainFound仍保持高性能
2. 环境准备
想要跑起来,你需要一台带 NVIDIA 显卡 的电脑(显存建议 8GB 以上),并安装好 Python 环境。
第一步:获取代码
打开终端(Terminal 或 CMD),下载项目代码。
注意:如果 GitHub 访问慢,可以使用国内的 GitHub 镜像站或者加速器,或者直接下载 ZIP 包解压。
git clone https://github.com/Moona-Mazher/BrainFound.git
cd BrainFound
第二步:创建虚拟环境
强烈推荐使用 Conda,防止环境冲突,Conda下载地址。
图3:Conda下载
接着使用Conda:
# 创建一个名为 brainfound 的环境,指定 Python 3.11
conda create -n brainfound python=3.11
# 激活环境
conda activate brainfound
第三步:安装依赖
官方的 requirements.txt 包含 pytorch 等大包,直接 pip 安装在国内非常慢且容易断连。请务必使用清华源或阿里源加速。
# 使用清华源安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
验证安装:
在终端输入以下命令,如果输出 环境正常,说明安装成功。
python -c "import torch, albumentations, SimpleITK, pandas, numpy; print('环境正常,核心包加载成功!')"
3. 数据准备:从 DICOM 到 NIfTI
格式转换
项目自带了转换脚本:
cd Preprocessing
# --input_dir 填你的 DICOM 文件夹路径
# --output_dir 填你想保存 NIfTI 的路径
python dicom_to_nifti.py --input_dir ./my_dicom_data --output_dir ./my_nifti_data
预处理
为了让模型读得懂,需要对图像做去颅骨、归一化等操作。
cd ../scripts
# --modalities 指定你有哪些类型的数据,比如 T1 T2 FLAIR
python preprocess_with_mripreprocessor.py \
--input_dir ./my_nifti_data \
--output_dir ./preprocessed_data \
--modalities T1 T2 FLAIR
4. 如何在代码中使用(实战)
这一步教你怎么在 Python 代码里调用这个模型,输入你自己的数据进行推理。
目录结构确认
确保你的项目目录结构如下,否则 import 会报错:
BrainFound/
├── models/
│ ├── dinov2_base.py
│ └── brainfound.py
└── ...
编写推理脚本
新建一个文件 run_demo.py,复制以下代码。这段代码演示了如何加载模型并输入一个模拟的 3D 数据。
import torch
from models.brainfound import BrainFound
def main():
print("正在加载 BrainFound 模型...")
# 1. 初始化模型
# num_modalities: 你有几种模态 (比如 T1, T2, FLAIR 就是3种)
# num_classes: 分类任务的类别数 (比如 正常vs患病 就是2类)
model = BrainFound(
num_modalities=3,
num_classes=2,
pretrained=True # 尝试加载预训练权重
)
# 2. 准备数据
# 模型接受的输入格式为: [Batch大小, 模态数, 深度(切片数), 高度, 宽度]
# 这里模拟生成一个随机数据:
# Batch=1 (1个病人), Modalities=3, Depth=64 (64层切片), H=256, W=256
input_tensor = torch.randn(1, 3, 64, 256, 256)
# 如果有显卡,把模型和数据丢进 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
input_tensor = input_tensor.to(device)
# 3. 推理
model.eval() # 切换到评估模式
with torch.no_grad():
output = model(input_tensor)
print("推理完成!")
print(f"输出结果形状: {output.shape}")
print(f"输出值: {output}")
if __name__ == "__main__":
main()
运行脚本
python run_demo.py
5. 常见问题 (FAQ)
Q1: 运行报错 CUDA out of memory 怎么办?
A: 3D 模型非常吃显存。
- 减小 Batch Size(设为 1)。
- 降低输入图像的分辨率(例如从 256x256 降到 128x128)。
- 减少切片数量。
Q2: 我只有 T1 图像,没有 T2 和 FLAIR,能用吗?
A: 可以。在初始化模型时,将 num_modalities 设置为 1 即可。BrainFound 设计就是灵活支持单模态或多模态的。
Q3: 这个模型可以直接用于临床诊断吗?
A: 不可以。 这是一个基础模型,它提供了强大的特征提取能力。你需要用它配合你的特定任务进行微调(Fine-tuning)验证后,才能用于研究参考。
