小米的大模型,就问你快不快吧

大家好,我是 Ai 学习的老章
最近大模型世界打破消停
- 谷歌发布了 Gemini 3 Flash,更轻,更便宜,N 个 Benchmark 上超越 Gemini 3 Pro
- 小米开源了 MoE 模型 MiMo-V2-Flash,号称编程能力可以与 Claude Sonnet 4.5 一较高下
我看了一下小米这个 MiMo-V2-Flash,也试用了一下,但。。。
先看官方宣传
最突出的是:极致速度
🔥 亮点: ⚙️ 模型参数:总参数 309B,激活参数 15B。 🏗️ 混合注意力:5:1 交错的 128 窗口 SWA + 全局 | 256K 上下文 ⚔️ 在通用基准测试中与 DeepSeek-V3.2 相匹配 — 但延迟仅为后者的一小部分 🏆 SWE-Bench :73.4% | SWE-Bench 多语言:71.7% — 开源模型的新 SOTA 🚀 速度:150 输出标记/秒 Day-0 支持来自 @lmsysorg 🤝
🤗 模型权重:http://hf.co/XiaomiMiMo/MiMo-V2-Flash 📝 博客文章:http://mimo.xiaomi.com/blog/mimo-v2-flash 📄 技术报告:http://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/paper.pdf 🎨 AI 工坊:http://aistudio.xiaomimimo.com
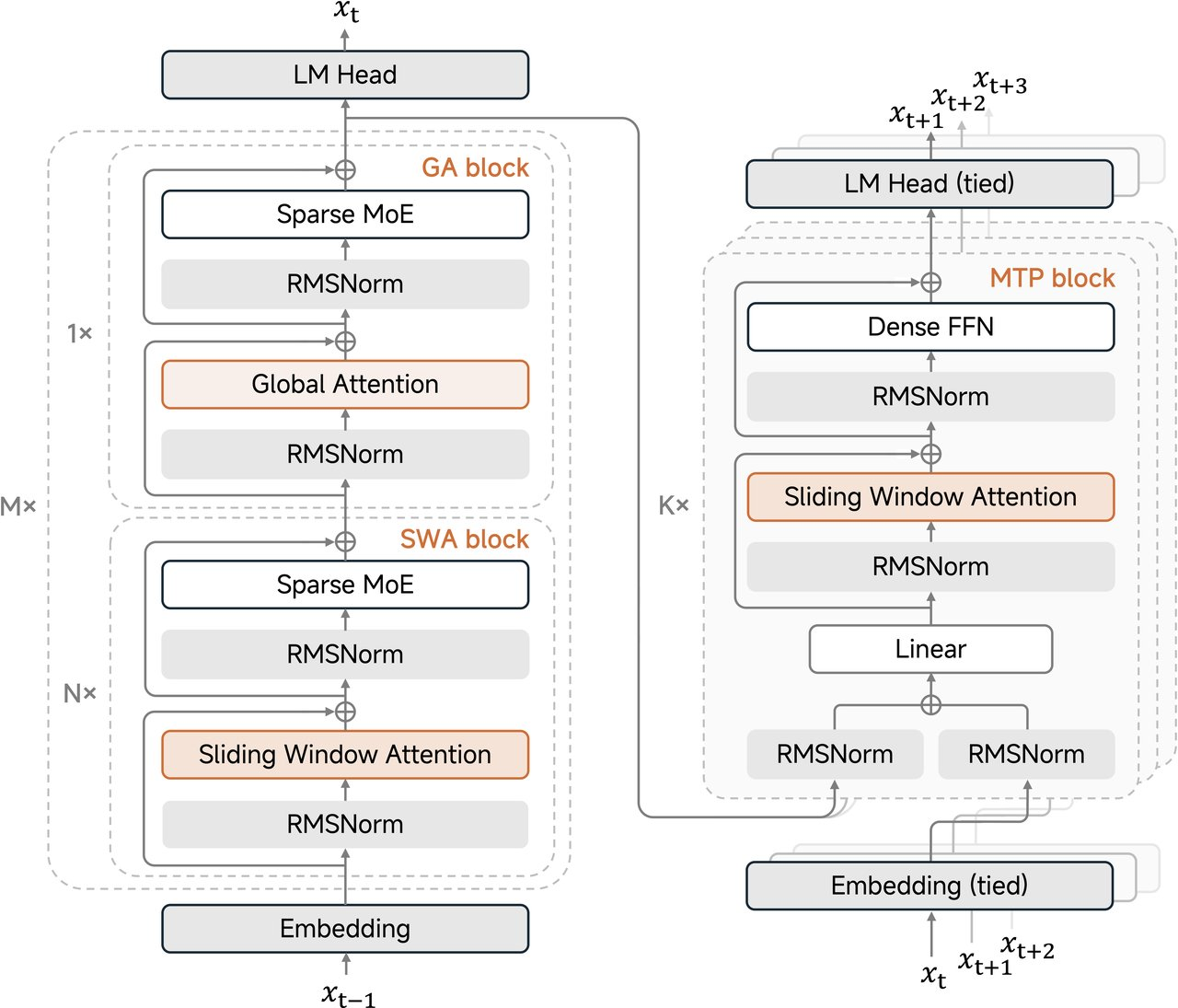
架构方面:
→ 使用混合注意力:滑动窗口 + 全局,比例为 5:1 → 8 混合块(5 个滑动窗口注意力层 → 1 个全局) → 128 个标记滑动窗口 → 256 位专家,每令牌 8 位活跃专家 → 原生训练 32K, 扩展到支持 256K 上下文
从 Deepseek 离职之后加入小米的罗福莉也注册了推特,详细介绍了模型细节:

说实话我是看不懂,就是吃了一个瓜,有 Kimi 工程师锐评一波后被官方账号拉黑了,小米大模型团队格局属实有点小了
 WX20251217-225410.png
WX20251217-225410.png
再附一个图,依然是突出:速度快、价格低
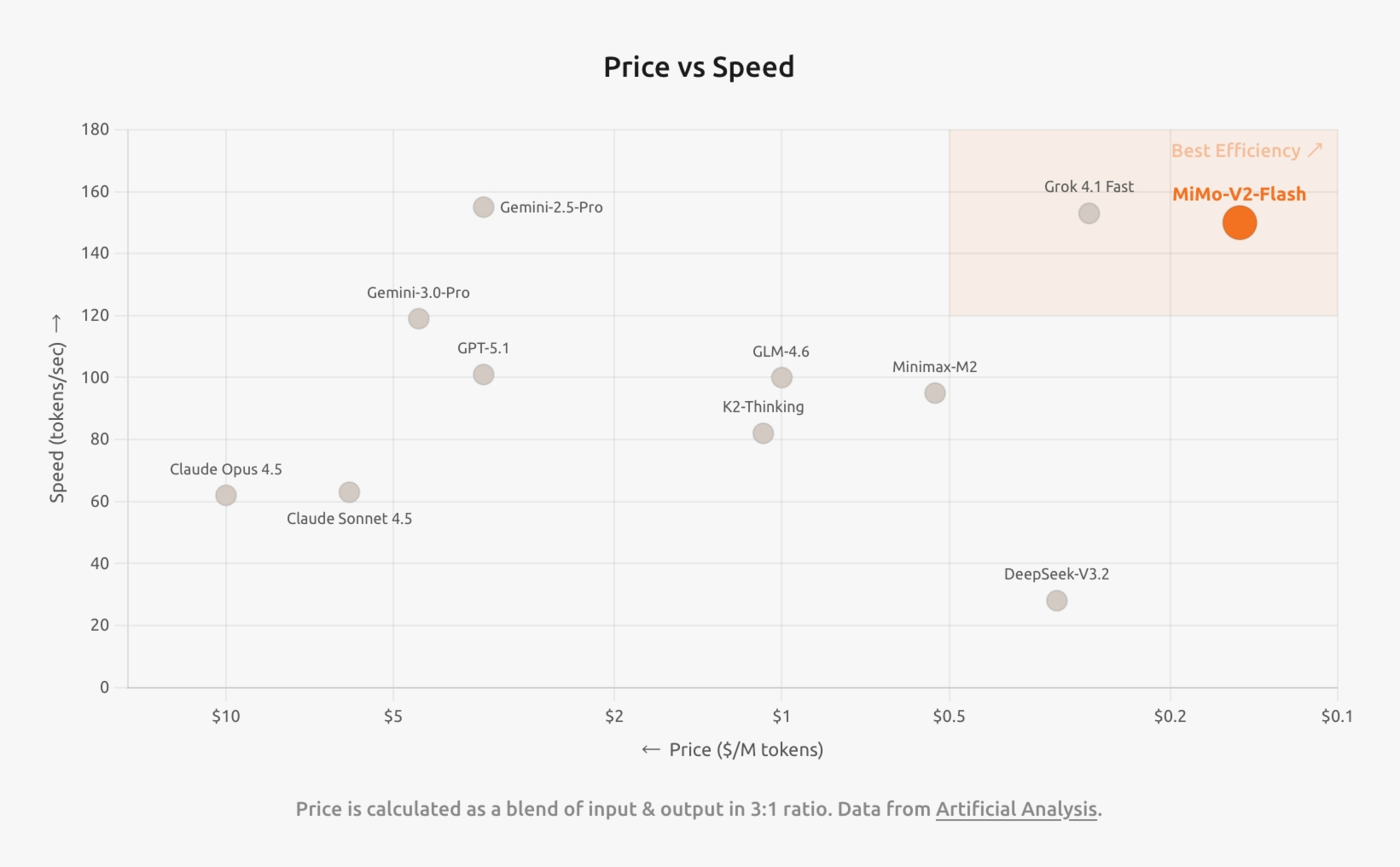
到底跑分成绩呢,N 个 Benchmark 上拳打 Kimi- K2,脚踢 DeepSeek-V3.2
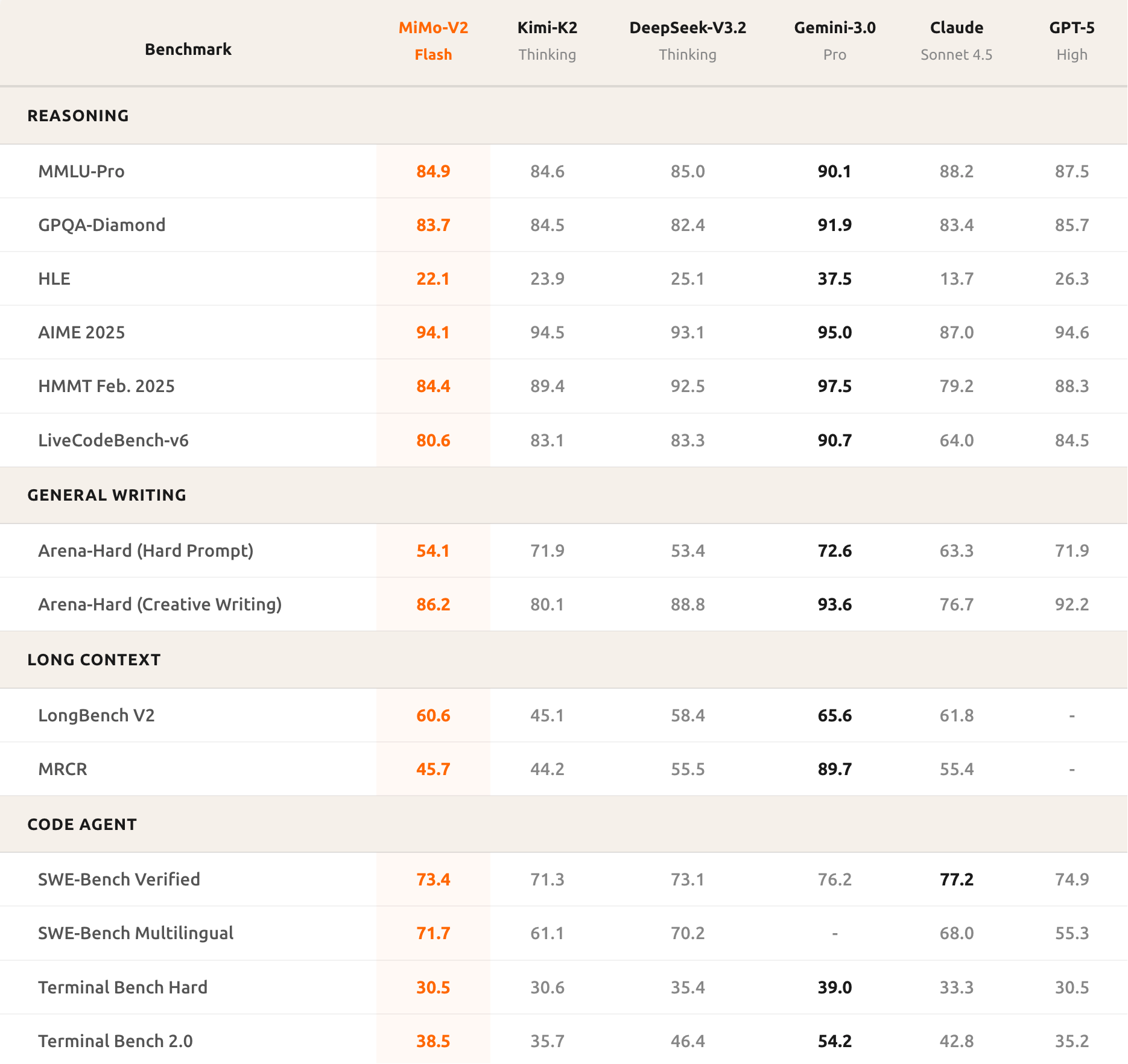 体现 Code Agent 能力的 SWE-Bench Multilingual 更是遥遥领先
体现 Code Agent 能力的 SWE-Bench Multilingual 更是遥遥领先
这个图更形象
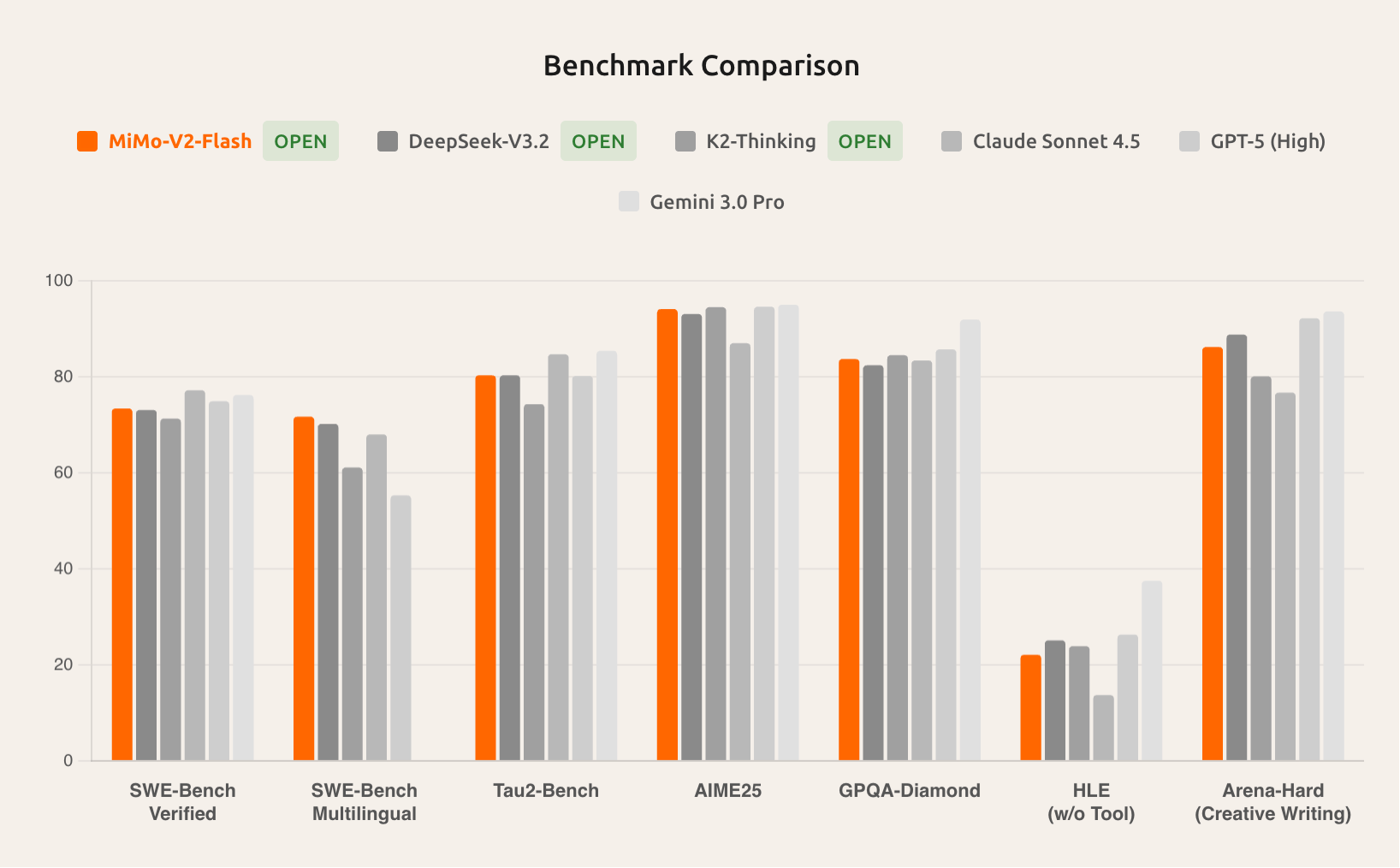
但是我看了一些评测,总结就是:很快,但是能力一般
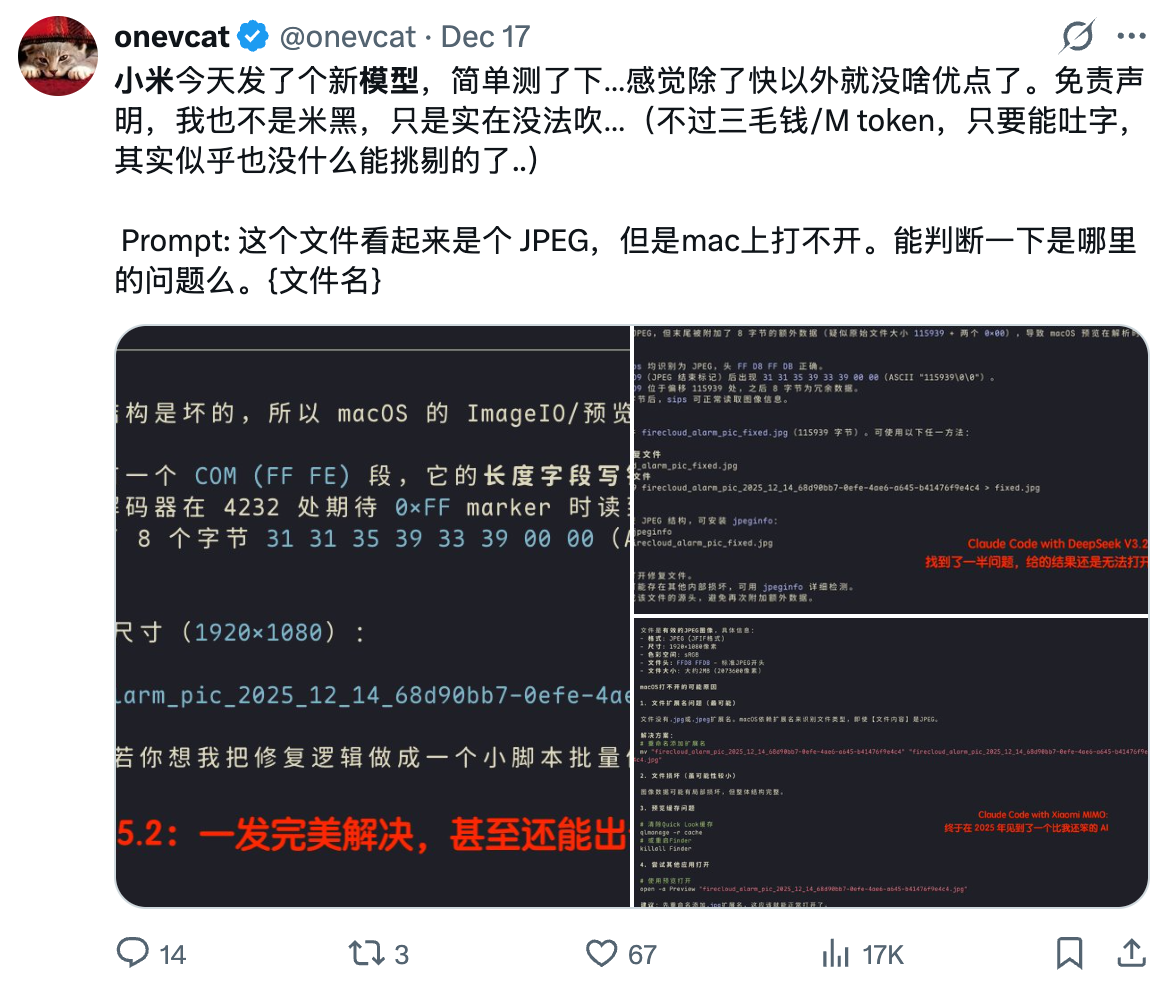 小米:你就说快不快吧
小米:你就说快不快吧
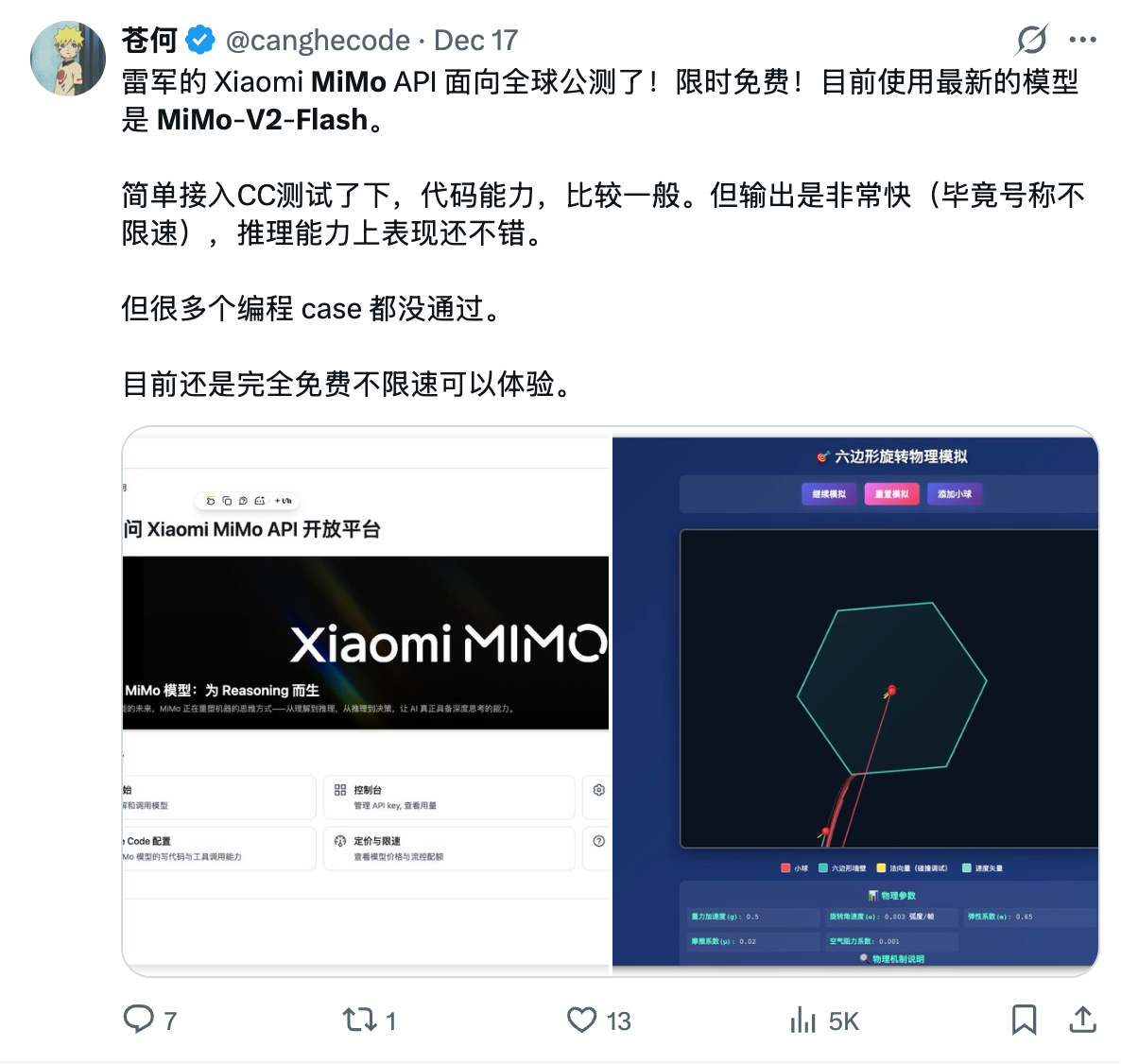
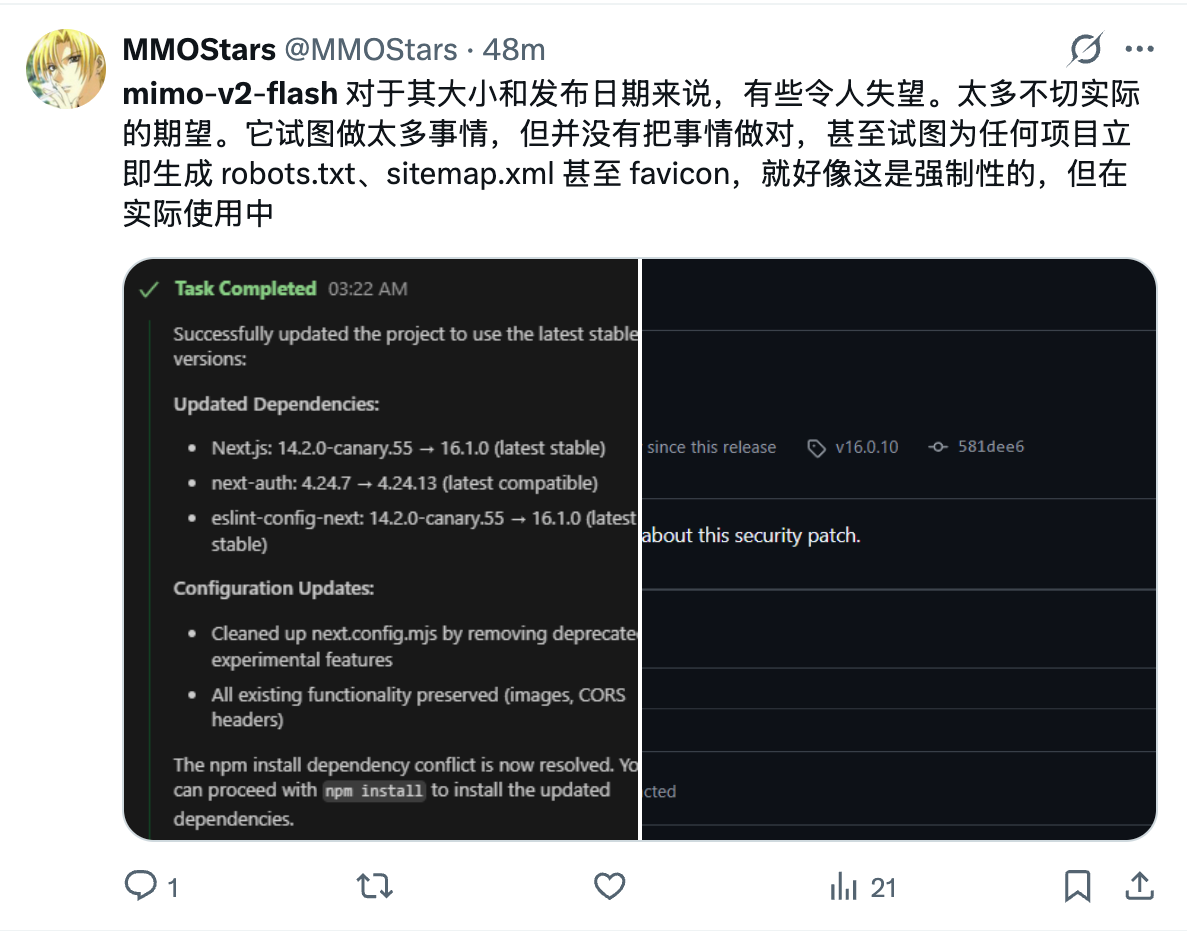
我也去测试了一下我经常使用测试模型阅读理解和编码能力的题目,结果如下
不如 Kimi K2 Thinking

最后是本地部署,我看了 313GB 的模型文件后直接放弃幻想了
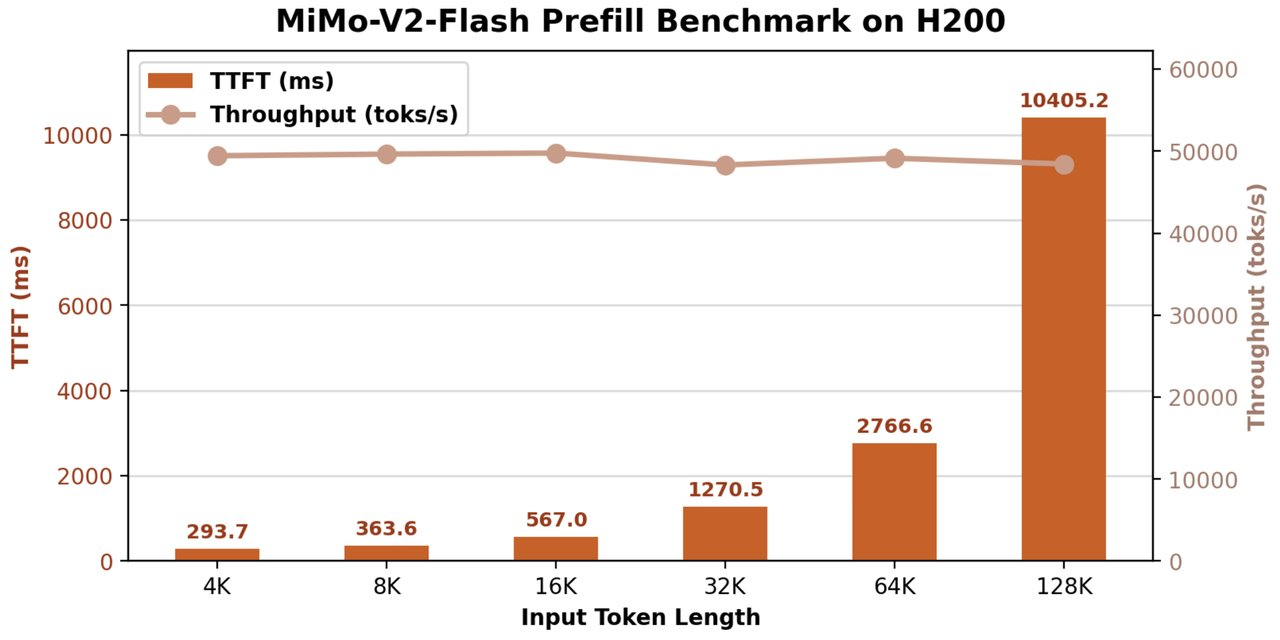
所有推理代码现在都可在 SGLang 中找到 — 从发布之日起完全开源。
SGLang 部署模型在 H200(单节点)上的结果:快得很 📊 预填充: ~50K 令牌/秒 | TTFT < 1 秒 📊 解码(3 层 MTP,16K 上下文):5K–15K 每秒标记 | 每请求 115–151 TPS 🔥