
你奶奶也能看懂:DeepSeek-OCR的秘密


作者:天落红蓝
转载自【AI大模型应用实践】
这两天,DeepSeek“搞事情”了:DeepSeek-OCR。

乍一看,你可能觉得平平无奇,毕竟优秀的专用OCR工具比比皆是。
更何况已有的VLM(视觉语言模型),很多已具备文档OCR能力。
事实并非如此。本文将用最精简的方式告诉你发生了什么。

一、别被名字骗了:它不是在“识字”,而是在“压缩”

为什么不少AI大佬,包括OpenAI前联合创始人Karpathy,都为它点赞?
光看名字,你可能以为这只是一个识别图片中文字的OCR工具。
但它真正的秘密,恰恰不在“认图识字”(这是它的表面功能),而在识字背后的方法 — 一种将大量文本信息压缩成极少量的视觉Token表达的方法(称作“上下文光学压缩”)。
准确地说,DeepSeek-OCR蕴含了一种让AI一次看更多内容、更省资源的新方法 ——
把几千个文字的内容渲染成图像,再“挤”进几十个视觉Token里,而模型读出来的准确率,却依然能保持在97%左右。
听起来有点神,对吧?有点像这样:
把厚厚一本文档拍成一张清晰的照片,然后让AI看着照片,就能背出整本书。
这才是DeepSeek-OCR的神奇所在。

二、反常规的思路:AI不读字,而是“看图记忆”

过去,我们让AI阅读文字,是把每个字、每个词都转成一个个Token输入。AI就像在“数砖头”一样,一块一块地读完。如果文章很长,这些Token就成千上万,计算又慢又费钱。
DeepSeek-OCR让我们可以不走寻常路。
我们先把整段文字“拍个照”——就像把一篇文章排版成PDF页面。
接着,DeepSeek-OCR把这张图压缩成几十个视觉模态的Token。
这些视觉Token不是传统意义的“字”,而是模型内部能理解的“图像记忆”。
模型拿到这些Token后,不需要再逐字阅读,直接“看图回忆”,就能够“回忆”(也就是识别)起所有的文字。

有点像我们自己:
看着一张会议纪要的截图,就能回忆出整个会议内容。
AI在这里具备的,正是这种“视觉记忆”的能力。
当然,测试效果也令人震惊:
原来1000个文本token的内容,再渲染成图像后,现在用不到100个视觉Token就能表示,识别率高达97%,还保留了排版、表格、公式这些结构信息。
让我们用一句话总结:
DeepSeek-OCR的意义不是“识别文字”,而是用图像的方式“压缩文字”。
这确实有点反常规:相比图像,文字不应该是更省资源吗?

三、技术内幕:“扫描仪”与“翻译官”

它是怎么做到的?我们简单了解DeepSeek-OCR背后的架构:它由两部分组成—— 编码器(Encoder)和解码器(Decoder):
编码器像扫描仪,把文字页面转成极少量的“视觉记忆”(Tokens)
解码器则像翻译官,根据这些视觉记忆,完整地“还原”出文字
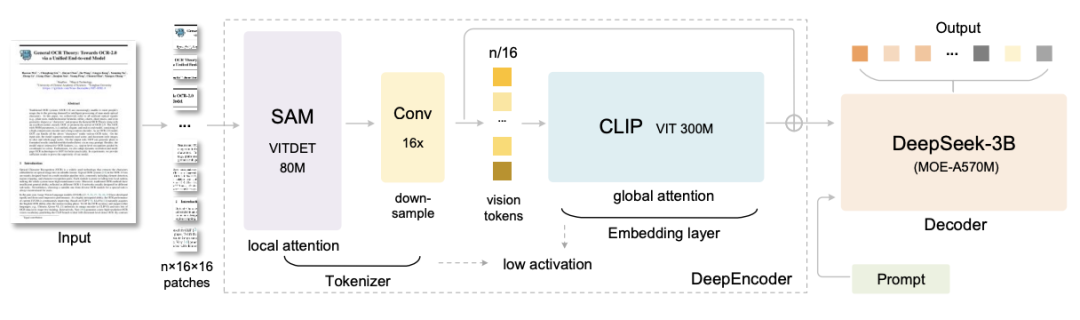
编码器的工作过程分成三个阶段:
第一步,是局部扫描。
模型会把整页图像切成很多小块,在图像的各个角落采集细节,确保每个字母、符号都没漏掉。
第二步,是压缩提炼。
把这些海量细节进行16倍下采样,浓缩成几百个视觉Token的“摘要”。这一步就像把一大堆会议笔记提炼成出几行重点。
第三步,是全局理解。
模型重新浏览这些Token间的联系,通读一遍,并梳理整体脉络,把控全局。
于是,一页复杂的文字页,就变成了一段可以高效存储的“视觉压缩包”。
接着,轮到解码器登场。
它是一个大约30亿参数的MoE模型,会根据这些压缩后的视觉Token,一口气“读图还原”出完整的内容 —— 除了文字,还包括排版、表格、公式,甚至Markdown格式的结构。
如果说传统OCR会“念字”,那DeepSeek-OCR则是“读图理解文档页面”。

四、效果惊人:一图胜千“词”,十倍信息浓缩

DeepSeek-OCR的压缩效果惊人:一页原本需要几千个文本Token表达的文档,现在只需几十到一百个视觉模态Token就能表达,并保持识别率高达97%,还保留了排版、表格、公式这些结构信息。
在多语言、多格式OCR的基准测试上,它的表现也全面超越传统OCR模型:在OmniDocBench上,它只用100个Token就超越了前代的256个Token模型。
在实际使用中,这种压缩让AI的“阅读效率”提高了一个数量级。
官方数据显示:
一台显卡每天能处理20万页文档,一个20台的集群能在一天内处理3300万页。
想想看,过去要分段输入、分段摘要的长报告,现在一张图就能搞定。
这对企业来说,就是——
同样的算力,能理解十倍的信息量;
同样的费用,能读完十倍的资料。

五、深远意义:重新定义AI的“记忆力”

你应该已经意识到,DeepSeek-OCR的意义,远不止在OCR本身。
它其实在重新定义AI“记忆”和“思考”的方式。
它可以轻易突破LLM的上下文极限
传统模型的上下文窗口有限——输入太多文字就“爆仓”。即使没“爆仓”,过度膨胀的上下文也会让LLM的理解力急剧下降(为什么会有“上下文工程”)。
而现在,通过视觉压缩,AI可以在相同的窗口中装下十倍的信息。未来,百万级、千万级token上下文不再是梦想。
智能体环境下,更少的Token上下文,也会大幅降低不确定性。
也就是说,AI可以一次“看”完整个公司文档库,再精准回答你的问题。
它让输入信息变得更丰富
文字之外,图片还能保留排版、格式、标注、甚至小表情。这些信息在文本Token中难以表达。现在,AI能真正“看到”人类写作的视觉层次。
更重要的是,这种机制启发了AI的“人类式记忆”
正如DeepSeek在论文中的阐述,我们人类的记忆会逐渐模糊旧事,但保留重要线索。而DeepSeek-OCR可以实现类似的概念 —— 光学记忆衰减。
想象一下,你的记忆衰减是否正如一张图片 ——
越遥远的记忆,”分辨率“越低,或者,“压缩率”越高。
未来,借助于DeepSeek-OCR这样的模型,会把久远的内容逐渐降为低分辨率高压缩率的图像表达,像模糊的回忆照片一样存在。虽然细节看不清了,但当需要时,仍能从中找出要点。
就像我们回想小时候的事 —— 不记得每个细节,却记得那天的阳光和感觉。
这让AI的“记忆”第一次有了层次感:
近的清晰,远的模糊,但全都在。它不再死记硬背,而是有选择地遗忘。

六、展望未来:AI的眼睛正在睁开

DeepSeek-OCR展示的,不只是OCR的未来,更提出了一种AI新的认知方式。
Karpathy曾说,传统的文本Tokenizer必须被淘汰。未来的AI,或许所有输入都可能是图像 —— 即便是文字,也要先转成图片再输入。
这听起来疯狂,但DeepSeek-OCR似乎正让它变得可信。它让我们重新思考文字与图像的关系:
图像不再是装饰,反而成了最紧凑的文字信息载体。
这你能信?
也许未来的AI训练,不再是灌入一行行文字,而是输入一张张“知识截图”。模型通过视觉压缩后,再去理解、储存、或者遗忘(高压缩的低“分辨率”),像人类一样形成层次化的记忆。
关于DeepSeek-OCR,你只需要记住:
过去的AI“读书”,是一个字一个字地念;DeepSeek-OCR则可以看着整本书的照片就把它背出来。这就是它带来的惊喜。
AI的眼睛,正在慢慢睁开。而这双眼睛,可能会彻底改变AI的思考方式。
END
