
科普向:如何在2025年看懂 AI 模型跑分


目录
哈喽,大家元旦快乐,我是小A。
现在的AI圈子,节奏快得来不及眨眼。这周 Gemini 3 pro 刚发,下周 Claude Opus 4.5 就来了,转头OpenAI又甩出了 GPT-5.2,各个公司不甘示弱。每一家发新模型的时候,发布会的PPT上都写着 我们在XX榜单上吊打全场。
但我要说句实话:大多数人看着那些满天飞的分数,完全是一头雾水。
如果你只是看个热闹,那没关系;但如果你是做这行的,或者是想知道哪款模型真能干活,看不懂这些 Benchmark(基准测试),你就只能被厂商的营销牵着鼻子走。
今天这篇文章,我就把手头关于 2025年最新的大模型基准测试 扒开了、揉碎了,给你整理出一份指南。读完这篇,你不仅能看懂那些复杂的排行榜,还能知道如何为你自己的业务挑选模型。
一、 绕不开的Benchmark
如果你觉得跑分只是数字游戏,那就大错特错了。到了2025年底,Benchmark至少有三个价值:
- 统一度量衡:当 GPT-5.2 和 Claude Opus 4.5 在这个月撞车发布时,公关稿都说自己是第一。没有Benchmark,我们就只能看厂商怎么营销。
- 丈量进化的标尺:拿 MMLU(大规模多任务语言理解) 来说,2022年那时候大家还在70%分段,到了现在,前沿模型已经普遍冲破了 90% 的大关。
- 照妖镜:有的模型聊起天来头头是道,看上去很强,实际多做几步数学推理就 智商下线。Benchmark能把这些短板暴露出来。
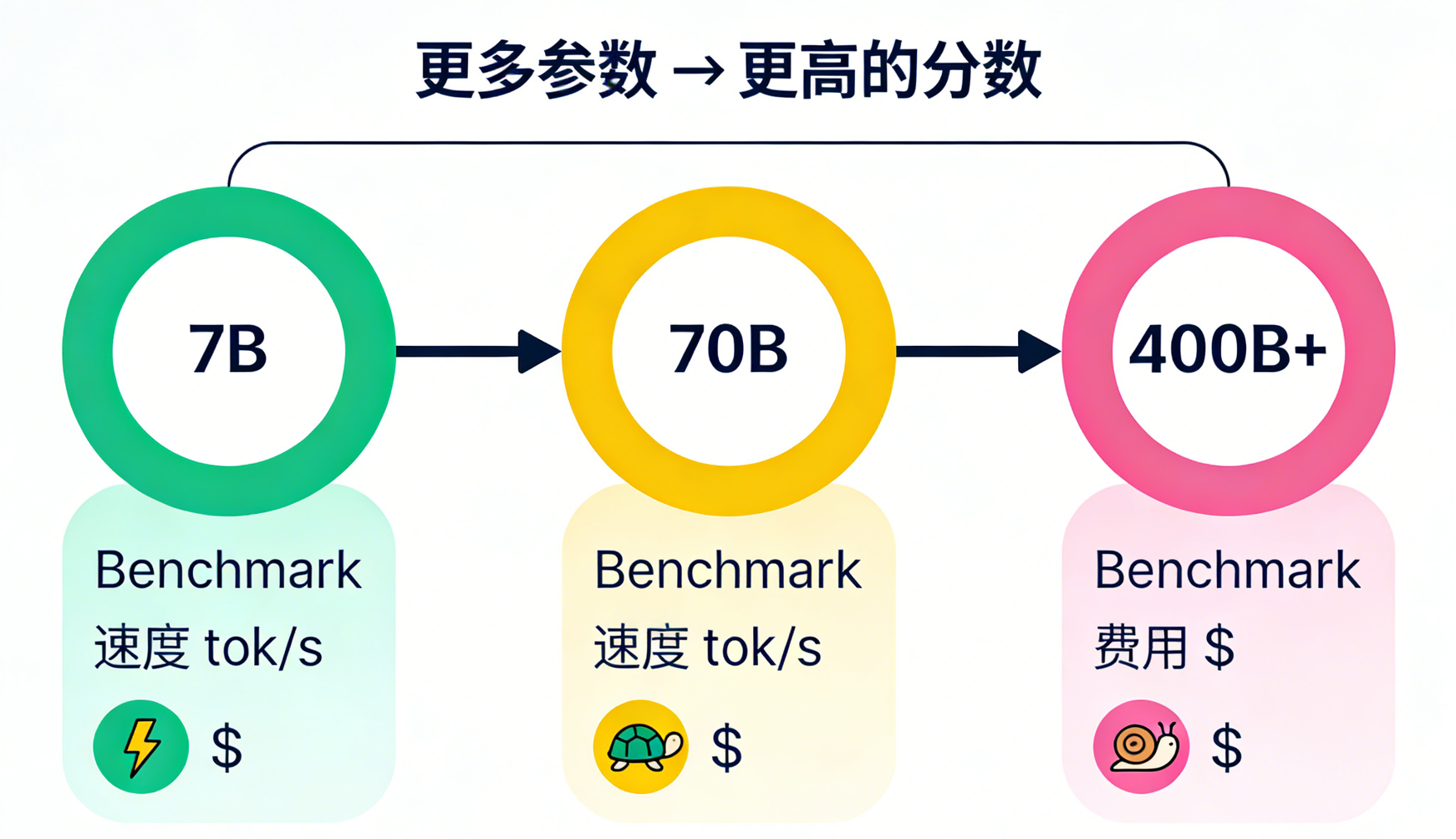
但这里有个 潜规则 你得知道:高分不代表高智商,还可能代表慢。
模型参数量越大,通常能处理更复杂的逻辑,跑分自然高。但代价是推理速度下降。这就好比你请了个诺贝尔奖得主来回答 1+1等于几,他绝对正确,但可能会思考你其中的深意。
二、 2025年,我们该看哪些榜单?
现在的基准测试多如牛毛,为了不浪费大家时间,我把它们分成了金字塔一样的层级机构:从基础到高阶。
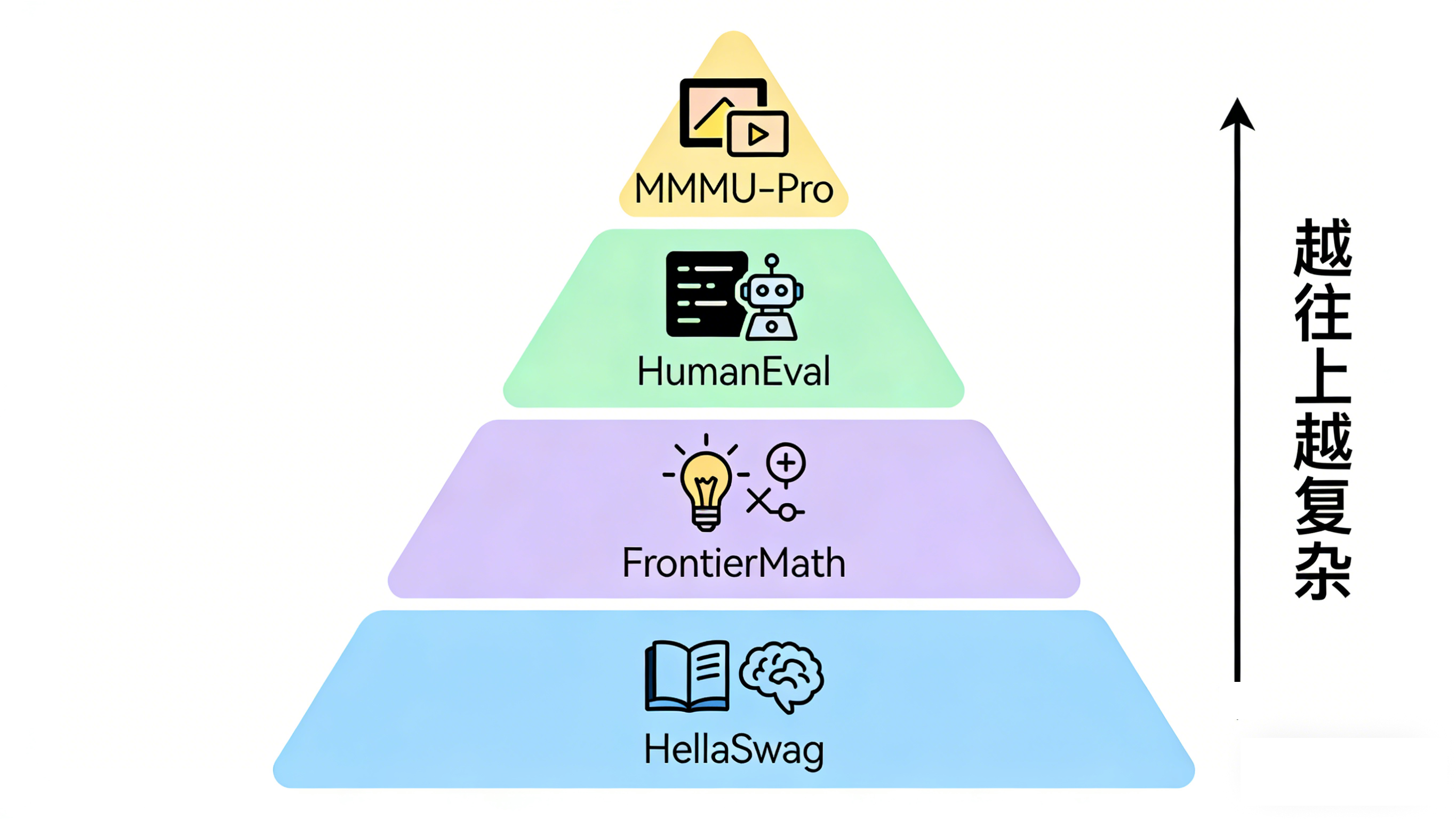
1. 基础:知识与逻辑
MMLU(过气):
它曾经是测试大模型百科知识的王者,涵盖57个学科。但说实话,现在的旗舰模型在MMLU上都能跑出 88%以上 的成绩,区分度太低,已经很难拉开差距了。
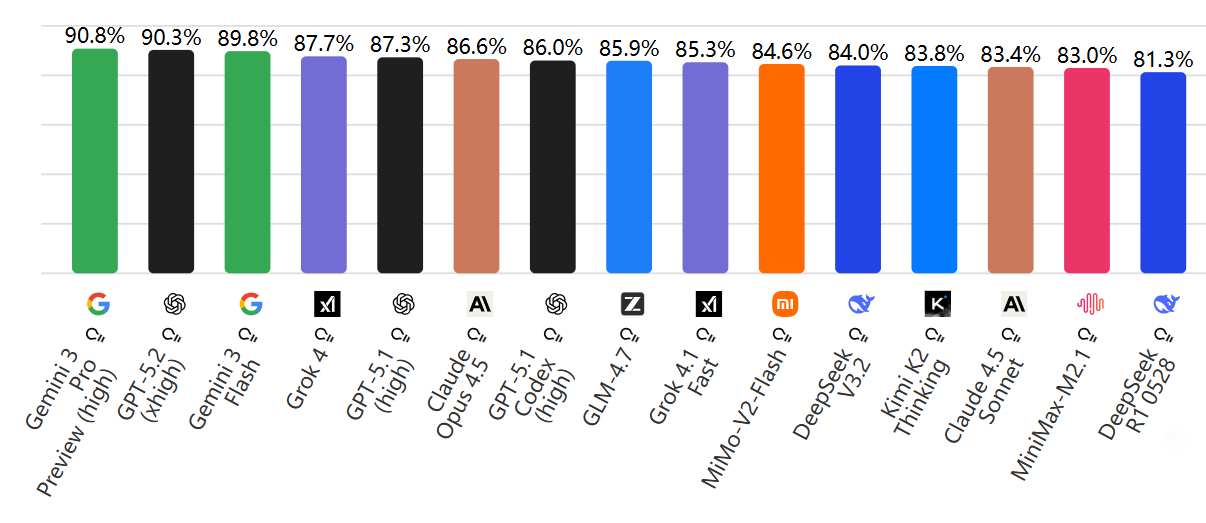
GPQA:
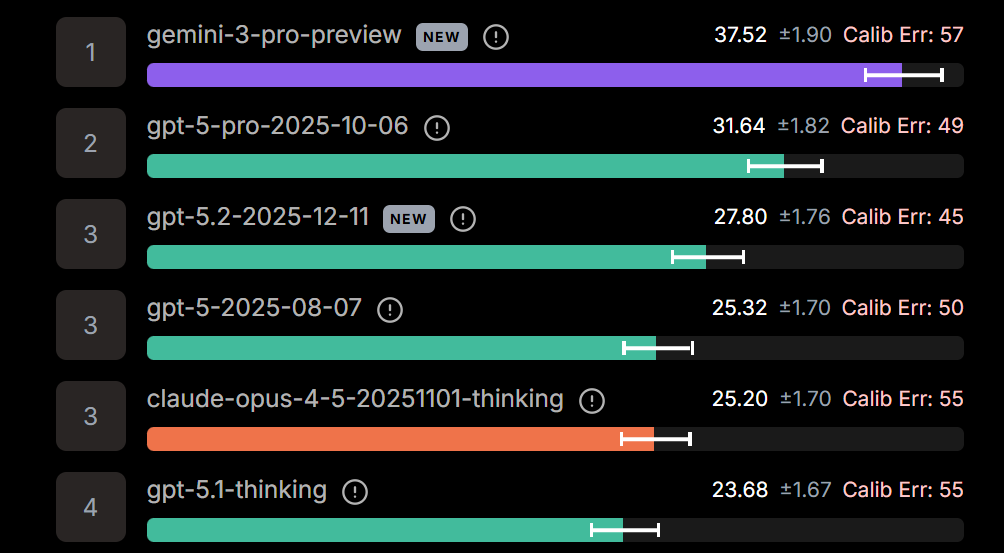
为了难住现在的AI,研究人员搞出了GPQA。这是谷歌级别的研究生难度问答,涉及生物、物理、化学,即使允许你上网搜,普通人也只能拿34%的分(仅仅比瞎蒙高9%)。
在这个魔鬼测试中,截止2025年12月,Gemini 3 Pro 以 90.8% 的恐怖高分霸榜。
HellaSwag(常识):
这个测试很有意思,它考的是“人味”。比如:一个人在做饭,伸手拿平底锅,接下来会发生什么?
AI很容易被那些词语通顺但逻辑荒谬的选项忽悠(比如平底锅飞走了)。人类能拿95.6%,而现在的模型还在努力学习不要预测概率,而是预测现实。
HLE:人类最后的考试)
这是2025年的重头戏。由于老榜单都被刷爆了,Dan Hendrycks带着 Scale AI 搞了这个。
- 含金量:2500道由全球专家众筹的题目,横跨数学、文学、历史等。
- 防作弊:所有题目必须是网上搜不到原题的,设计初衷就是为了防谷歌、防数据库查找。
- 现状:即便是现在的最强模型,面对HLE也经常 一本正经地胡说八道。
- 争议:Future House曾指出HLE里部分生物化学题答案有误,这其实反映了我们在评估AI时面临的困境——题目难到连出题的人类专家都可能犯错。
2. 中阶:编码与Agent
别只看聊天,对于老板们来说,能写代码、能干活才是硬道理。
SWE-bench(程序员):
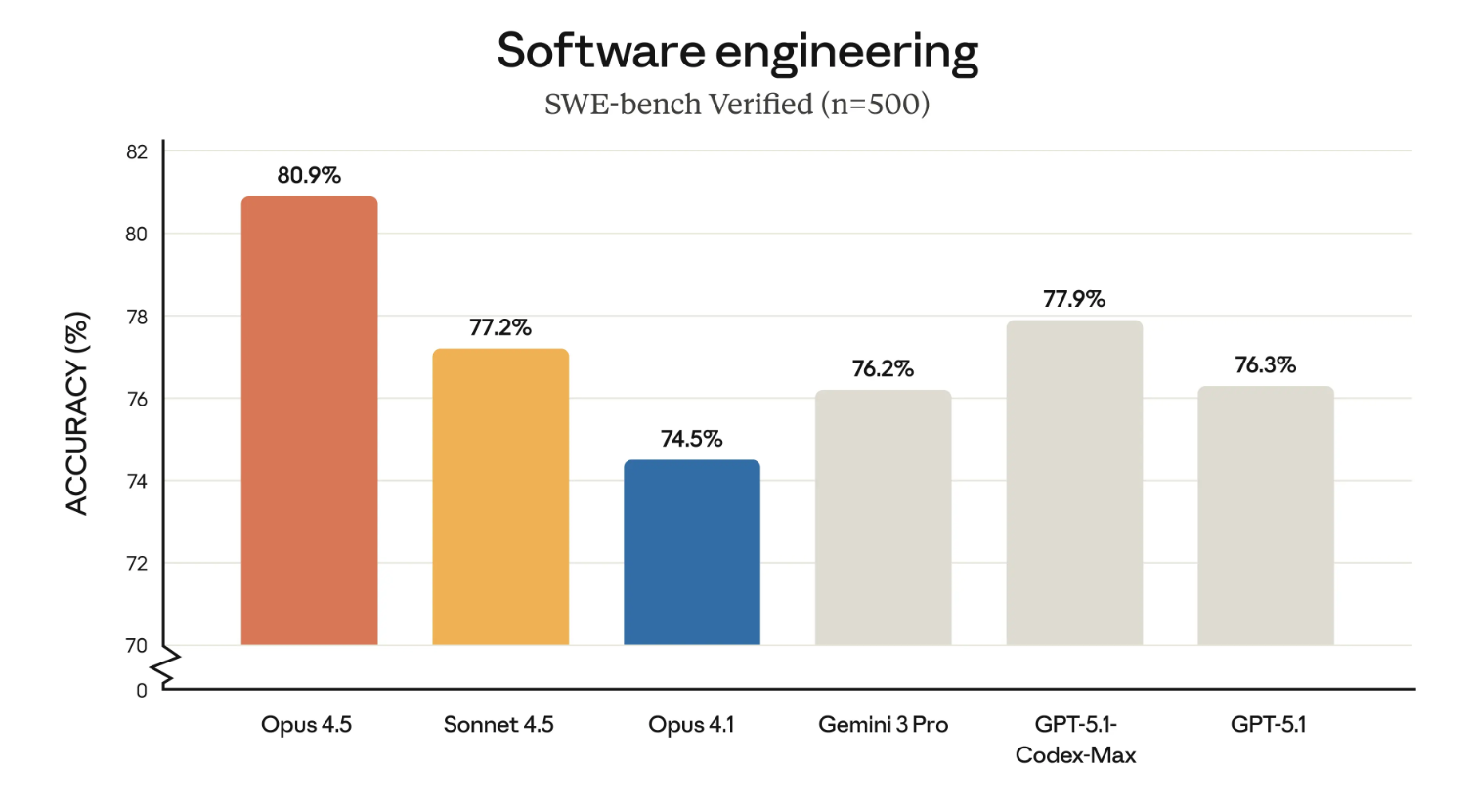
HumanEval那种写个简单Python函数的测试早就不够看了。SWE-bench直接把AI扔进真实的GitHub仓库里,让它修Bug。
这里要重点表扬 Claude Opus 4.5。在SWE-bench Verified(经过人工严格筛选的高质量任务集)中,它是第一个突破 80% 大关的模型(80.9%)。它已经能像一个靠谱的中级工程师一样解决实际问题了。
GDPVal(打工人):
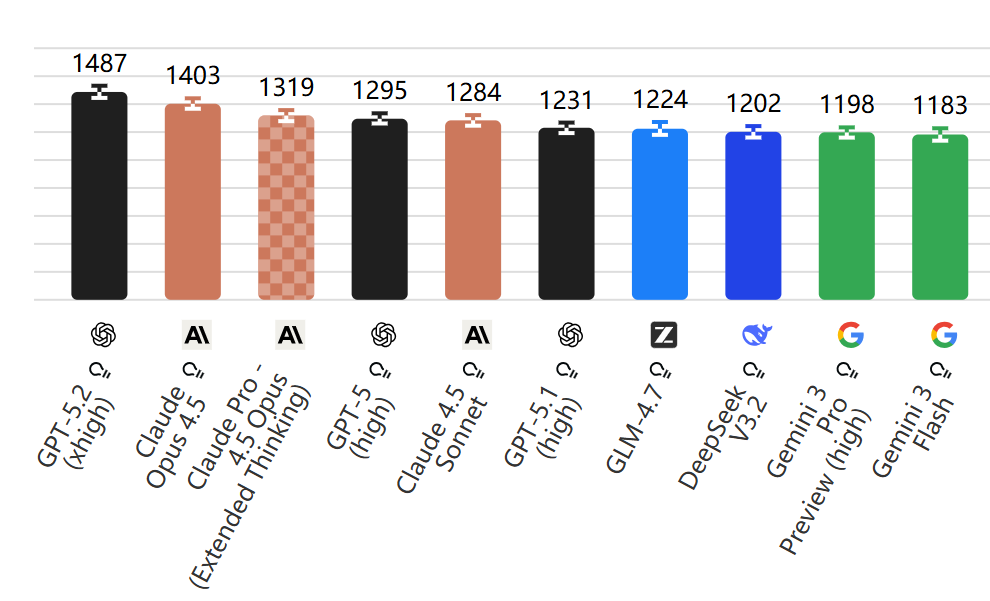
这个榜单很有意思,它直接衡量AI的经济产出能力。涵盖44种职业,要求AI产出法律简报、PPT、工程规格书等。目前 GPT-5.2 在这方面表现最强,妥妥的 职场卷王。
GAIA(AI助理):
这大概是目前让AI最头疼的测试。题目对人类来说很简单(比如查一下某部1970年代电影导演的出生地),但对AI来说,需要联网搜索、阅读文档、计算、综合信息,哪怕中间错一步就全盘皆输。GPT-4刚出来时在这上面只有15%的准确率,可见路还很长。
3. 高阶:多模态基准测试
现在的模型必须得有识别能力。
MMMU-Pro:
专门测试视觉推理。Gemini 3 Pro 在这里依然是领头羊(81%),它能看着复杂的图表做微积分,或者理解视频里的因果关系。
ARC-AGI-2:
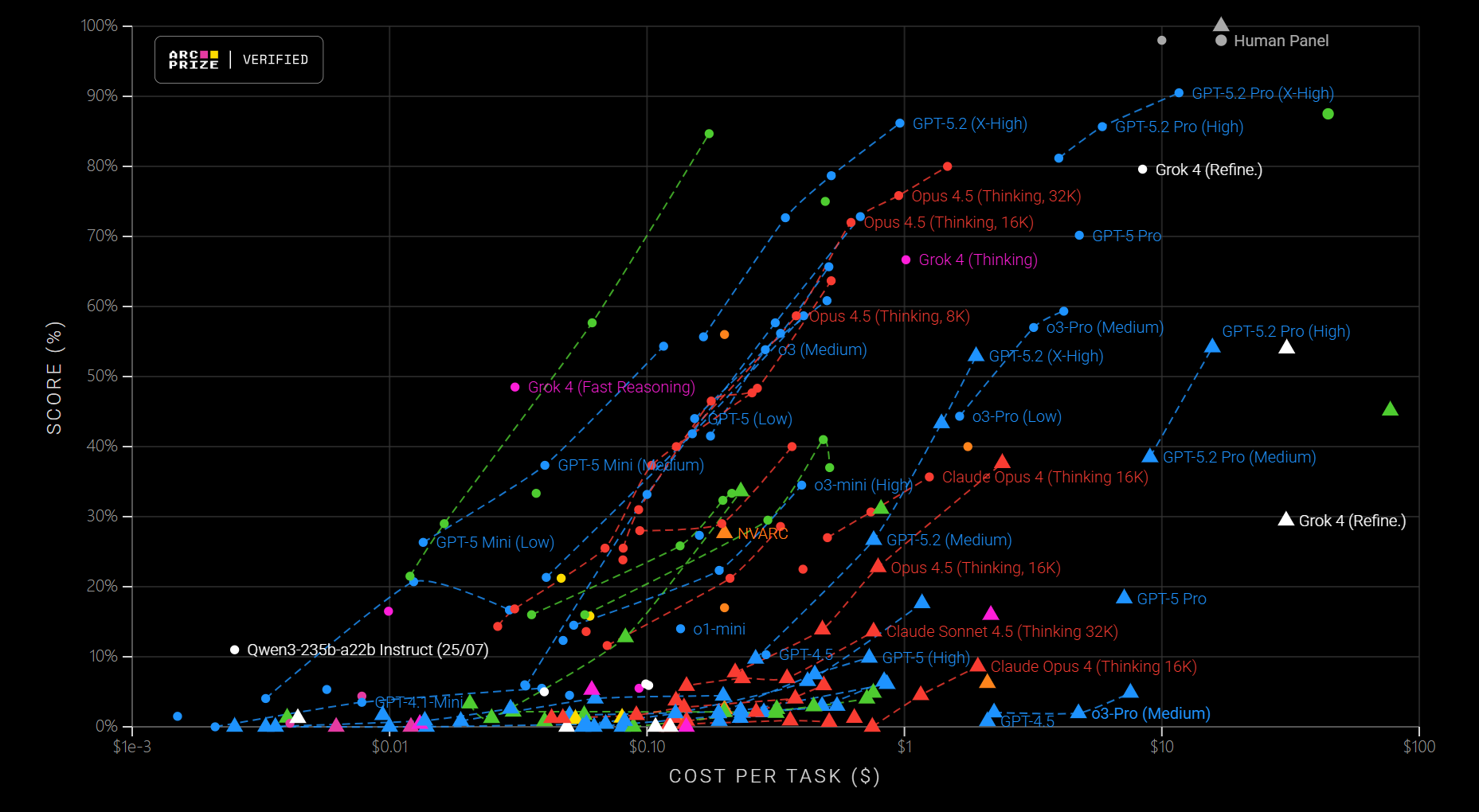
这是一个纯粹测试 流体智力(对不熟悉的事物,能以迅速准确的反应来判断其彼此间的关系)的谜题集。人类看两眼就能找到规律,纯语言模型得分是0%。即使是最强的混合系统,花上每题30美元的算力成本,也赶不上人类。这是目前AI离人类直觉差距最大的地方。
三、 谁2025年看哪个?
看了这么多分项,到底谁最强?我们结合几个权威排行版来看:
-
LMArena:
这是最接地气的榜单,靠的是全球用户盲测投票,比较主观。- 总冠军:Gemini 3 Pro (1501分)。
- 亚军:Grok 4.1 (1483分)。
- 其他强者:Claude Opus 4.5 和 GPT-5.2 紧随其后。
- 注:这里反映的是好不好用,有时候话痨且自信的模型更讨喜。
-
Hugging Face Open LLM Leaderboard:
这是开源模型的圣地。这里必须要说说我们 国内的模型。
Qwen3(通义千问)、DeepSeek V3.1(深度求索) 以及 Llama 3.3 70B,在这些榜单上已经和闭源模型杀得难解难分。
特别是国内的 DeepSeek 和 Qwen 系列,在数学和代码能力上,已经成为了全球开源界的扛把子。这证明了只要路子对,开源一样能打。
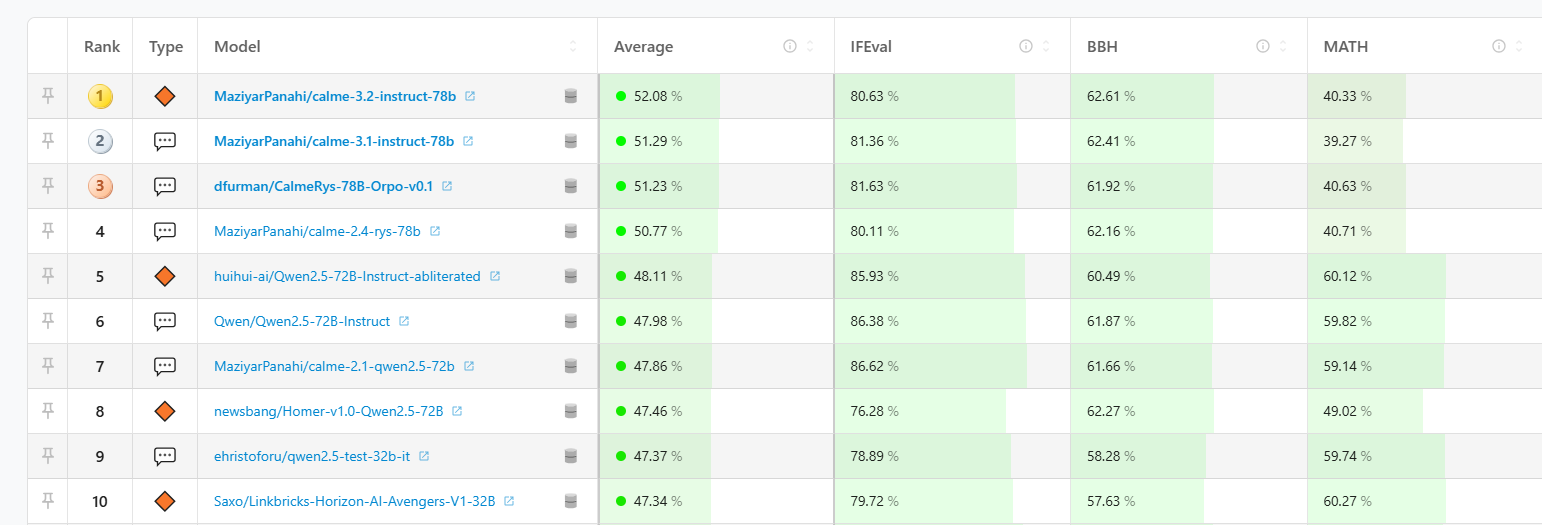
- Stanford HELM:
如果你关注安全性、偏见和合规,看这个。Claude 3.5 Sonnet 在综合安全评分上排名最高,Anthropic在这方面确实做得滴水不漏。
四、 如何自己进行模型测试?
看别人的榜单总归不放心,尤其是当你用了微调模型时。怎么自己跑分?
这事儿其实没那么神秘,行业标准工具是 EleutherAI LM Evaluation Harness。
怎么玩?(简易版教程)
-
安装神器:
pip install lm-eval -
小试牛刀:
别上来就跑全量,先用国内优秀的轻量级模型(比如Qwen2.5-1.5B)试个手:lm_eval --model hf \ --model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \ --tasks hellaswag \ --device mps \ --limit 10(注:MPS是Mac芯片加速,N卡用户请用cuda:0)
-
避坑点:
- 数据污染:一定要确保你的测试题模型没在训练数据里见过。否则你测出来的不是推理能力,是记忆力。
- 温度归零:测试时把Temperature设为0,我们要的是准确,不是创意。
- LLM-as-a-judge:对于那些没有标准答案的开放性问题(比如写文案),可以用更强的模型(如GPT-4o或Gemini 3 Pro)来当裁判,给小模型的输出打分。虽然不完美,但已经能达到人类 85% 的判断水平。
五、 结语
写到最后,我想告诉大家的是:2025年,已经不存在唯一最好的模型了。
- 如果你搞科研、做多模态分析,Gemini 3 Pro 是目前的顶峰。
- 如果你是写代码、做工程落地,Claude Opus 4.5 是首选。
- 如果你想搞定日常杂活、追求综合性价比,GPT-5.2 依然稳健。
- 而如果你想私有化部署,或者是预算有限,请把目光投向国内的 Qwen3,它是当之无愧的开源之光。
Benchmark只是我们理解这些AI的一把尺子,当你能看懂这些数字背后的逻辑时,你就不会再被“奥特曼”的营销迷惑了。
新的一年,愿你的AI选型不踩坑,每一分钱算力都花在刀刃上。
本文基于2025年12月的行业数据整理,转载请注明出处。
