
从短片段到长叙事:EgoLCD如何利用SNP技术,让AI理解时间与剧情?

在当今的文娱与科技交叉领域,AI视频生成无疑是最炙手可热的赛道。
从Sora的惊艳亮相到各路模型的百花齐放,我们见证了AI从生成几秒钟的模糊片段,进化到能够通过文本描述构建精美画面的能力。
然而,当我们试图利用AI去构建一个真正的沉浸式虚拟世界,例如《头号玩家》中的“绿洲”,或是一个永不完结的第一人称游戏时,现有的技术却撞上了一堵无形的墙——记忆。
目前的AI视频模型随着生成时间的推移,画面中的物体会莫名变形,场景的语义会逐渐崩坏,这种被称为“内容偏移”的现象,成为了阻碍长视频生成迈向实用化的最大绊脚石。
近期,由北京大学、中山大学、浙江大学、中国科学院及清华大学等多家顶尖科研机构联合推出的一项重磅研究——EgoLCD(Ego Long-Context Diffusion),基于长上下文扩散模型,为解决这一难题提供了全新的范式。这不仅仅是一个视频生成模型,更是迈向可扩展具身智能“世界模型”的重要一步。
EgoLCD通过模拟人类的“长短时记忆”机制,成功实现了长时间、高连贯性的第一视角视频生成,为未来的沉浸式娱乐、VR体验及元宇宙构建描绘了全新的技术蓝图。

论文地址:https://arxiv.org/pdf/2512.04515
一、 痛点直击:为什么AI总是“记不住”?
在深入EgoLCD的技术内核之前,我们需要理解长视频生成为何如此艰难。论文指出,生成冗长且连贯的第一视角视频极具挑战性,因为它从根本上考验着模型的计算资源和长期记忆能力。
目前的视频生成范式主要依赖于自回归(AR)模型或标准Transformer架构。然而,标准Transformer中的自注意力机制具有二次复杂度,这意味着随着视频时长的增加,计算量呈爆炸式增长,使得处理长序列在计算上几乎不可行。虽然现有的自回归模型通过键值(KV)缓存来维持生成记忆,试图让未来帧以过去帧为条件,但这种记忆往往极其脆弱。
在第一视角视频中,这种脆弱性被无限放大。剧烈的相机晃动、复杂的手部与物体交互、以及严格的程序化任务,都要求模型必须拥有极其精准的连续性。一旦模型“走神”,物体身份就会丢失,场景逻辑就会断裂。这种“内容偏移”导致生成的视频虽长,却是一段段逻辑不通的碎片,无法用于严肃的文娱内容创作或具身智能体训练。

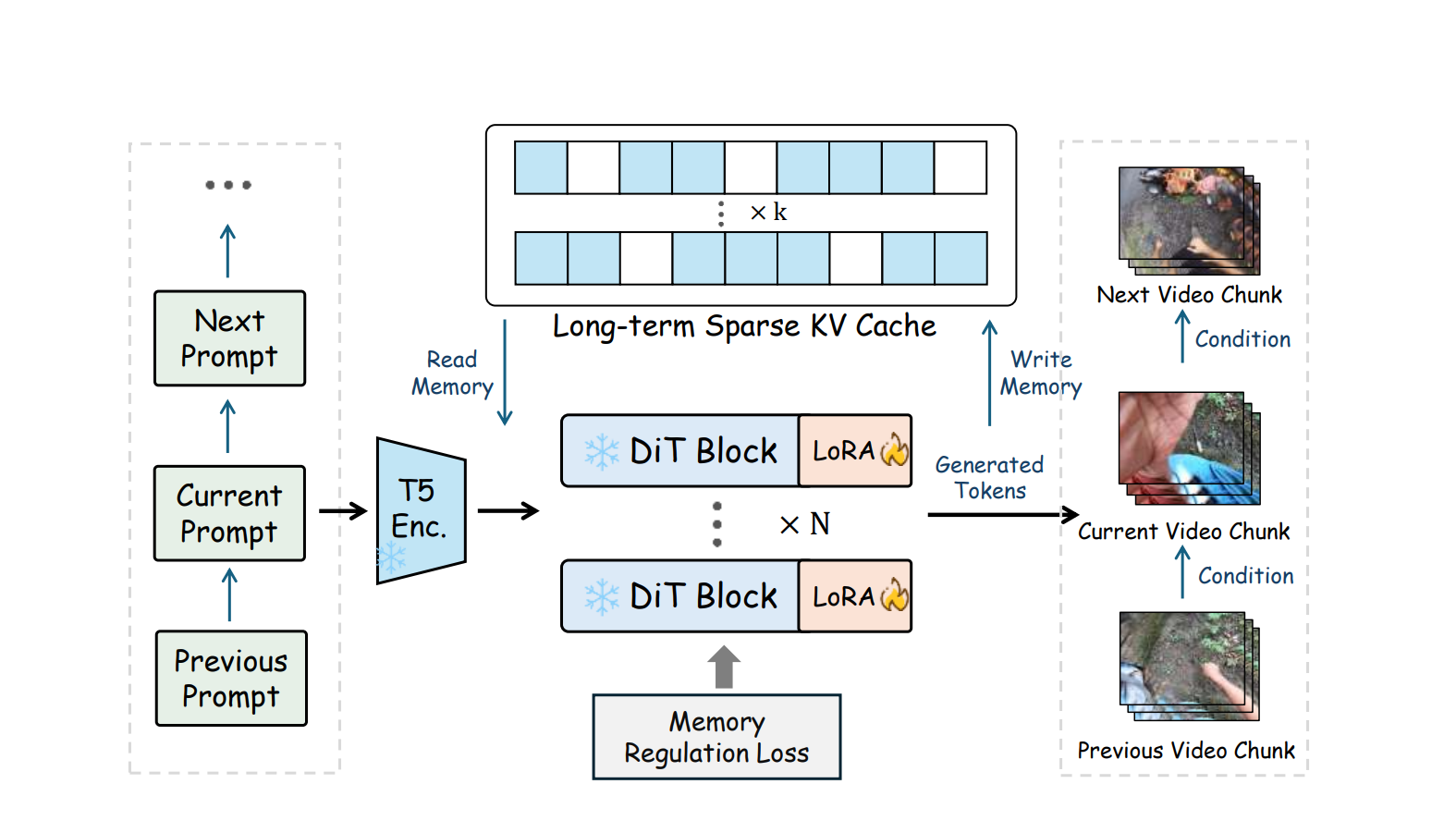
二、 EgoLCD的核心黑科技:赋予AI“长短时记忆”
为了打破僵局,研究团队提出了 EgoLCD 框架。其核心理念在于仿生学的 “双记忆设计”。
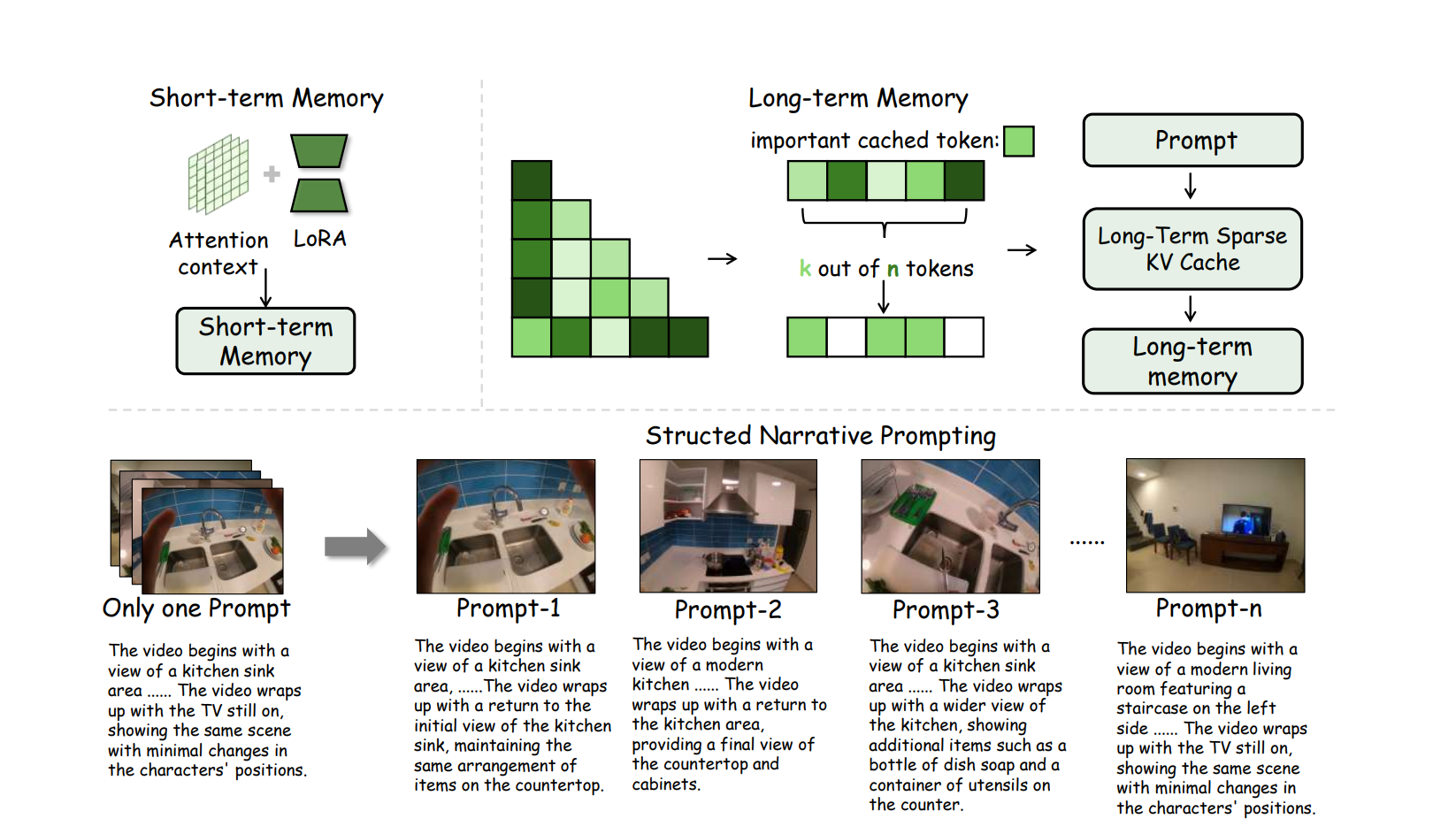
1. 长期记忆:稀疏KV缓存
EgoLCD 模仿人类记住剧情关键节点的机制:
- 智能检索: 系统计算当前片段与历史信息的语义相似度,仅检索最重要的 Top-m 个历史片段。
- 低复杂度: 这种稀疏化策略实现了亚线性的记忆复杂度,确保全局上下文,例如场景布局、物体特征不被遗忘。
2. 短期记忆:LoRA增强的注意力机制
- 快速适配: 引入 LoRA(低秩适配) 参数作为“隐式记忆单元”,捕捉瞬息万变的视觉动态。
- 稳定切换: 像人类的工作记忆一样,它能灵活应对第一视角下高方差的相机运动,而不干扰长期记忆。
3. 记忆调节损失
引入“监制”机制,模型在生成每一帧时都必须受到历史记忆的约束。通过 语义锚点 强制保持一致性,防止“红苹果变成绿梨子”。
三、 结构化叙事提示:像导演一样指挥AI
视频是叙事的载体。为了让 EgoLCD 具备逻辑和剧情,论文提出了 结构化叙事提示。
- 分镜脚本化: 将长视频分割成 5 秒为单位的剪辑,确保每个单元动作连贯。
- 大模型辅助: 利用 GPT-4o 生成包含视觉效果、人物、动作、环境的详细描述。
- 时间链条: 在推理时,系统会参考先前片段的提示。
> 效果: EgoLCD 不再是盲目生成画面,而是像一个严格执行剧本的演员,精确完成复杂的动作序列。
四、 实力验证:用数据说话的“世界模拟器”
🏆 权威基准测试
在 EgoVid-5M 基准测试中,EgoLCD 经历了两个阶段的磨炼:
- 通用学习: 在通用视频库学习物理规律与运动先验。
- 专业训练: 在 Ego4D 大规模第一视角数据集上深耕。
🔍 全新评估协议:NRDP
传统的 FVD 指标会掩盖长视频后半段崩坏的问题。为此,研究团队开发了 归一化参考偏移惩罚。
- 关注衰减: 越靠后的质量偏移,惩罚越重。
- 结果: 在主体一致性、背景一致性及美学质量上,EgoLCD 展现出了卓越的时间稳定性。

五、 结语:迈向无限连贯的数字未来
EgoLCD 的出现,标志着 AI 视频生成从“短视频娱乐”向 “世界模拟” 迈出了关键一步。
- 沉浸式游戏与VR: 未来生成无限延展、逻辑自洽的 VR 场景将不再遥远。
- 影视制作: 长镜头的生成将变得更加容易且成本低廉。
- 具身智能训练: 作为“世界模拟器”,它为机器人提供了训练复杂交互操作的丰富数据源。
EgoLCD 不仅仅是一个模型,它是一个能够理解时间、记忆过去并推演未来的“数字大脑”。在通往构建可扩展具身智能世界的道路上,这无疑是一座崭新的里程碑。
