
AI 论文的真相:是效率神器还是学术造假


哈喽大家好,我是小A。
现在学术圈对 AI 的接受度越来越高,看到一篇论文,脑子里就会浮现:这里有多少是豆包帮写得?
别笑,这事儿很严肃。
我们都知道,把繁重的文献综述丢给 AI,那种 30 秒出稿省时省力。但是,今天我看到一篇发表在《JMIR Mental Health》上的最新研究,可能要给正在用 AI 写论文的朋友们浇一盆冷水了。
简单说:AI 可能不仅在瞎编,而且编得连它自己都信了。
这份来自澳大利亚迪肯大学的研究揭开了 AI 在科研领域的遮羞布:在使用 GPT-4o 生成的参考文献中,有近三分之二(约 66%)是完全伪造的,或者存在严重错误。
1. GPT-4o 哪些时候会撒谎
GPT 就像一个超级实习生,他名校毕业、谈吐优雅、打字飞快,但这人有个毛病,为了让报告好看,他敢凭空捏造数据,弄虚作假。
研究人员找了三个心理健康领域话题,让 GPT-4o 写综述:重度抑郁症、暴食症、躯体变形障碍。
要求 AI 写 6 篇综述,要求每篇引用至少 20 个同行评审的学术来源。之后,研究人员对 AI 给出的 176 个引用进行了核查。
结果令人震惊:
- 完全虚构: 约 20% 的引用是 AI 凭空捏造的。这些论文标题听起来极其专业,作者也真实存在,但世界上根本不存在这篇文章。
- 半真半假: 在剩下真实存在的文献中,又有近一半包含致命错误(年份不对、DOI 码错误、作者张冠李戴)。
- 总计: 近三分之二的引用是不可用的垃圾。
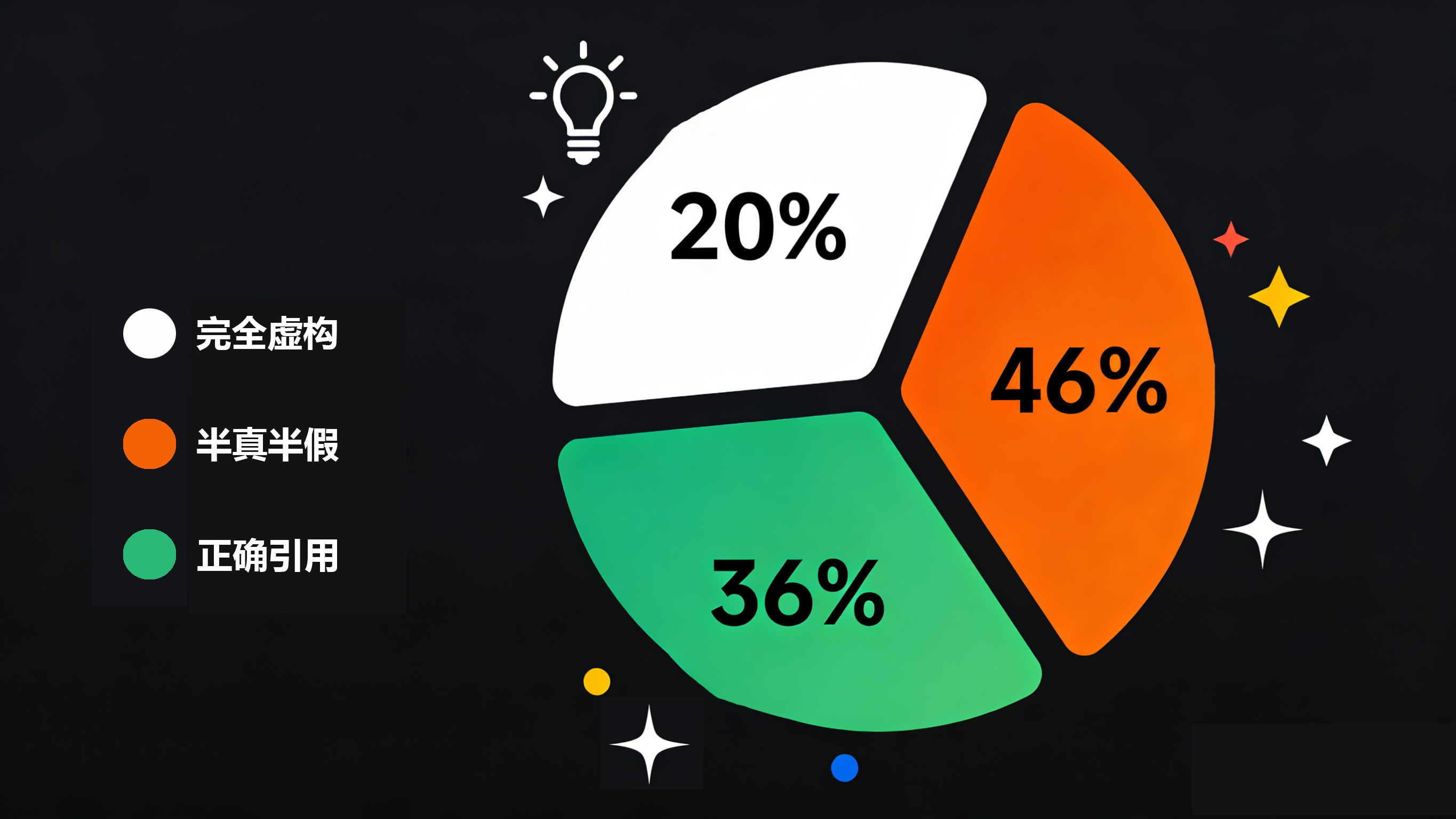
图 1:完全虚构 20%、半真半假 46%、正确引用 36%
2. AI 撒谎的规律
这个研究最重要的发现,不仅仅是 AI 会撒谎,而是 AI 撒谎是有规律的。
AI 的诚实程度与话题热度成正比。
- 对于“重度抑郁症”这种讨论度高的话题,GPT-4o 只有 6% 的引用是伪造的。
- 但到了“躯体变形障碍”这种冷门话题,伪造率直接飙升到 29%,如果再加上引用细节错误,准确率竟然只有惨淡的 29%!
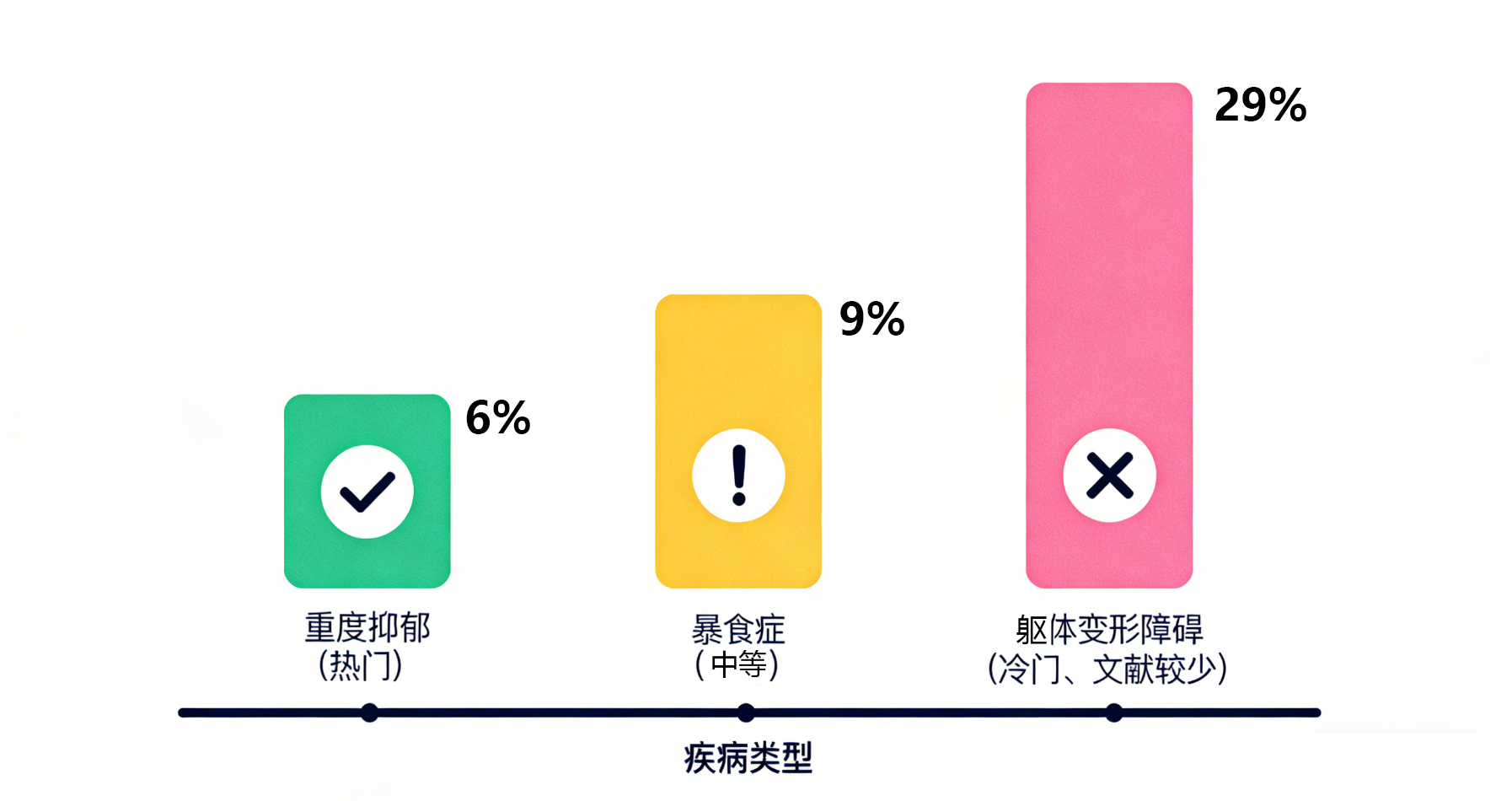
图 2:三个不同疾病领域的引用错误率对比,冷门领域的错误率显著高于热门领域
这揭示了大模型的底层逻辑缺陷: 它不是在查阅知识,它是在概率推断。
当资料库里关于冷门领域的语料不够多时,AI 就开始动用它的“幻觉能力”。它会分析这个领域的常用词汇、高频作者,然后像拼乐高一样,拼凑出一个看起来极其合理,但完全不存在的引用。
越是专业、越是细分、越是冷门的领域,AI 一本正经胡说八道的概率就越高。 尤其是当研究人员要求它写“暴食症的数字干预”这种极度具体的细分方向时,伪造率直接干到了 46%。
意味着如果你还在用 AI 辅助挖掘冷门知识,可能被 AI 坑得很惨。
3. 学术界的大模型危机
这让我联想到了更深层次的危机。
小 A 曾看过这样一个新闻,超过三分之二的研究人员无法复现同行的研究。

图 3:BBC 2017 年关于科研复现危机的新闻
现在,AI 的相关论文也这样。
1. 垃圾进,垃圾出 (GIGO)
AI 是吃互联网数据长大的,如果训练数据本身就包含了大量不可复现的、甚至是错误的、欺诈性的研究数据,模型自然也会受到污染。
2. 审稿人的崩溃
这才是真正的问题所在。现在的期刊投稿量爆炸,审稿人也是人,他们很难有精力去复现每一个实验,特别是大模型部署的高端设备,他们很难去核对每一个引用的 DOI 是否正确。
这就形成了一个连锁反应:
AI 相关论文 ➔ AI 伪造了引用 ➔ 审稿人默认信任 ➔ 部分错误论文发表 ➔ 下一代 AI 用这些论文训练。

图 4:疲惫不堪的审稿人
4. 微调模型,才是科研 AI 的现实出路
讨论到这里,其实很容易看清一个趋势:真正能进入科研场景的,并不是更会聊天的通用大模型,而是被严格约束过的专业模型。
以 GPT-4o 为代表的通用模型,本质目标是对话体验和通用能力最大化。但在科研、医疗、法律等低容错场景中,存在天然风险。
相比之下,国内不少模型从一开始就把重心放在了工程可控性上。
-
一方面,是对长文本和复杂文献的处理能力。
无论是 DeepSeek 还是 Kimi,都在设计阶段就针对论文、技术报告、法规条文这类文本结构进行了优化,而不是只服务于短对话。 -
另一方面,是对检索增强生成(RAG)路径的高度依赖。
在科研类问题中,这类模型往往会先检索最新的论文、数据库或权威来源,再基于明确引用进行整理和总结。这种模式并不是更聪明,而是更符合科研工作的基本逻辑:结论必须可追溯、可核验。
更重要的一点在于:微调正在成为决定模型能否“上桌”的关键门槛。
未经过领域微调的通用模型,面对专业问题时,只能依赖参数中的模糊记忆,这也是幻觉产生的根源。而通过引入领域数据、规则约束和任务导向微调,模型的角色会发生根本变化。
它不再试图“什么都回答”,而是明确知道哪些问题必须基于已有资料,哪些问题应该拒答或回溯来源。
在医疗、法律、科研辅助等高风险领域,模型是否足够大并不是核心问题,是否足够被驯化才是。
从这个角度看,开源模型 + 专业化微调 + RAG 体系,正在构成一条比单纯堆参数更现实、也更可持续的路径。
5. 如何不被 AI 坑?
既然 AI 这么不靠谱,我们是不是就该把它们扔进垃圾桶?
当然不是。因噎废食是愚蠢的。我给各位科研党、学生党几条保命建议:
- AI 只是灵感引擎: 用它来头脑风暴、润色语言、生成代码框架,这些它做得很好。
- 对 AI 零信任: AI 生成的每一个引用,每一个 DOI 链接,必须人工点击核实,不要相信它给出的任何一个名字。
- 善用 RAG 工具: 尽量使用带有联网引用功能的 AI 工具,而不是纯聊天的 LLM。
- 警惕冷门陷阱: 如果你在研究一个很偏门的课题,请务必降低对 AI 的依赖,它在那里的表现远不如你。
结语
AI 正在重塑科学,但它目前更像是一把没有安全锁的电锯。它能帮你砍倒大树,也能一不小心锯断你的腿。
本文基于发表于《JMIR Mental Health》的最新实验研究整理
