
AI 破解抗生素耐药性难题


目录
- 01. 背景:超级细菌与被寄予厚望的抗菌肽
- 02. 关键方法创新:从“词频统计”到“语义理解”
- 03. 核心发现:模体长度决定设计策略
- 04. 生物物理机制:富精氨酸模体为何更高效?
- 05. 结构预测验证:模体三维特征关联活性
- 06. 产业启示:AIDD 的落地路径
- 07. 总结
哈喽大家好,我是小A。
今天要聊的话题,关乎全人类的命运,也关乎下一个万亿级的医药市场。
大家知道,现在超级细菌有多猛吗?世界卫生组织警告:全球每年因抗生素耐药性死亡人数超百万。咱们常用的抗生素,在这些不断进化的细菌面前,越来越像“滋水枪”。
在这个背景下,抗菌肽 被寄予厚望。抗菌肽是自然界中广泛存在的短肽分子,因能直接破坏细菌膜结构,被视为下一代抗生素的候选者。
但是,怎么设计出高效的抗菌肽?传统药物研发效率低得感人,难以系统挖掘这些模体的深层规律。
最近,美国国家标准与技术研究院 (NIST) 的团队搞了个大新闻,简单说,他们用 自然语言处理 (NLP) 的技术,破解生物分子的密码。
图 1:日益严重的抗生素耐药性危机促使科学家寻找新型抗菌肽(示意图)
方法创新:词频统计到语义理解
研究将 AMP 序列视为“文档”,k-mer 视为“单词”,通过 LDA (Latent Dirichlet Allocation) 模型 将共现 k-mer 聚类为“主题”。
- 传统方法的局限: 频率基方法仅统计高频 k-mer,导致冗余(如重复亮氨酸序列)。
- LDA 的突破: 每个主题代表一组功能相似的模体。例如,富含精氨酸(R)的模体多集中于同一主题。
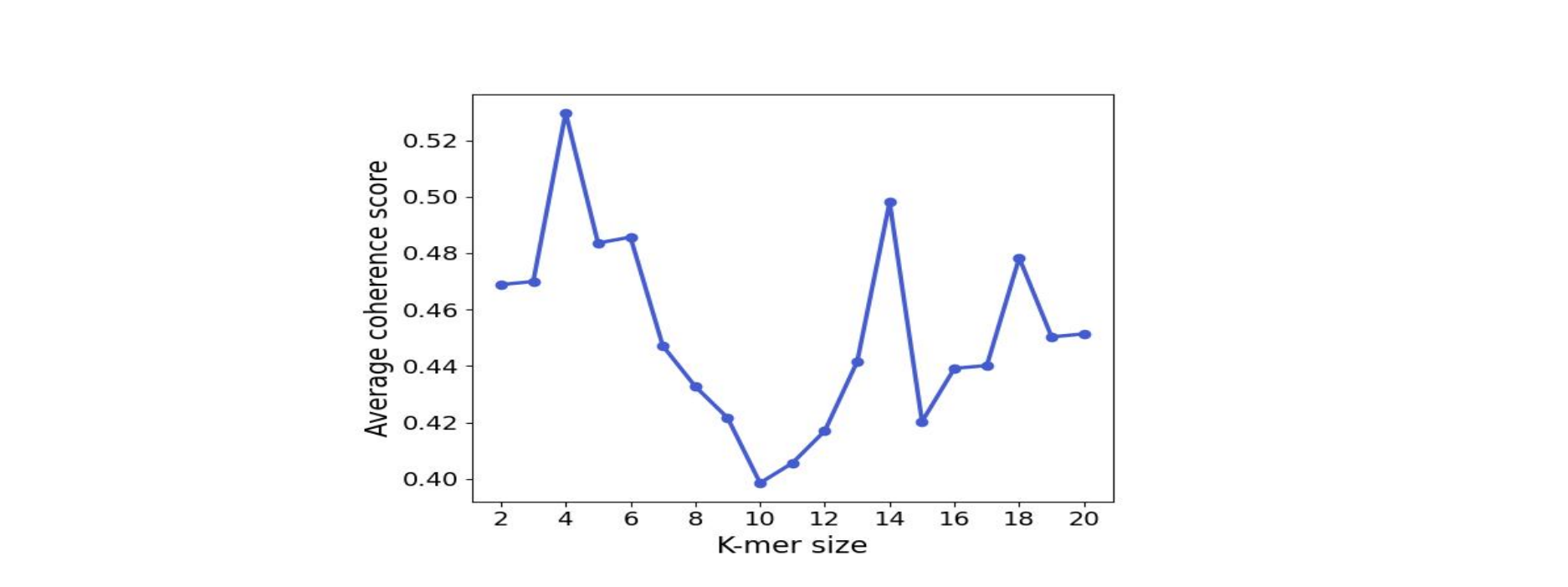
通过优化 k-mer 长度(4、14、18)和主题数量(基于相干分数),LDA 模型在 k=14 时相干分数峰值最高,对应螺旋结构模体;而 k=18 时主题数增至 4,覆盖 β 折叠等复杂模式。
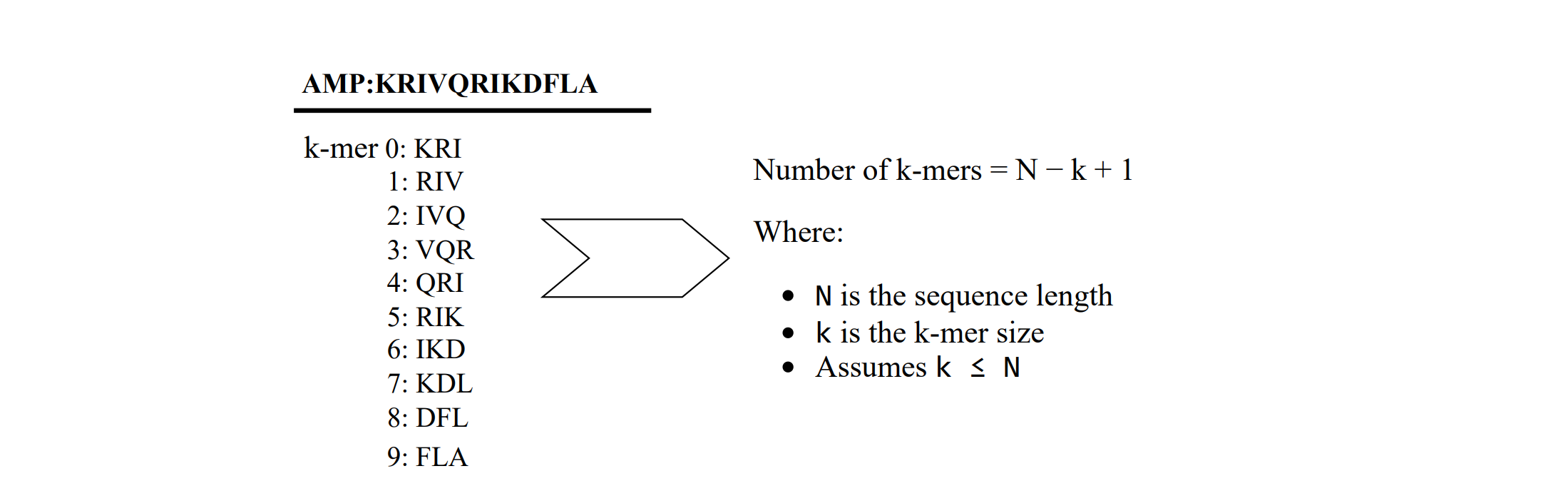
图 2:利用 NLP 算法对肽序列进行“语义”聚类分析
核心发现:模体长度决定设计策略
——短模体促多样性、长模体保相似性
研究显示,模体长度是平衡“创新性”与“有效性”的关键杠杆:
- 短模体 (如 4-mer): 适合生成多样性 AMP。
- 案例: LDA 提取的 4-mer 模体 “RPRP”(富含脯氨酸和精氨酸)虽频率低,但能通过柔性结构增强膜穿透性。
- 长模体 (如 18-mer): 更易保留已知靶点相似性。
- 案例: 18-mer 模体在主题 3 中 MIC 值低至 2.98 μmol/L,且 ESMFold 结构预测显示其以随机卷曲为主,与常见螺旋模体形成互补。
设计指导: 若目标是突破现有 AMP 框架,可优先采用短模体;若需快速针对特定病原,则长模体更可靠。
生物物理机制:富精氨酸模体为何更高效?
氨基酸组成分析揭示,LDA 模体中 精氨酸 ® 和 组氨酸 (H) 富集度显著高于频率基模体。
- 精氨酸 ®: 强正电荷增强与细菌膜负电荷的静电作用。
- 组氨酸 (H): 具有 pH 响应特性,助力靶向感染酸性环境。
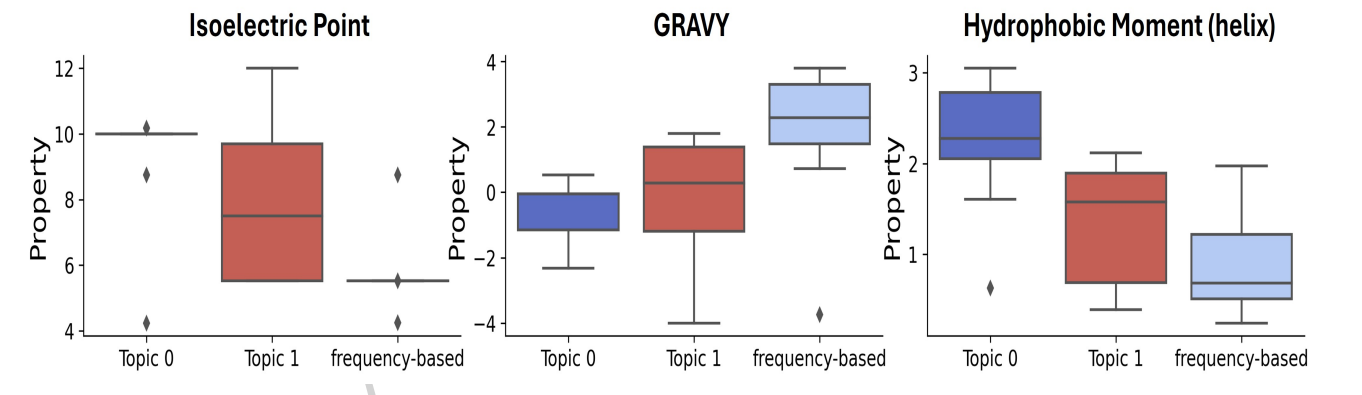
对比图显示,LDA 模体的 等电点 (IP) 多 >7(偏碱性),疏水矩 (HM) 更高,说明其兼具两亲性——这是膜破坏活性的关键。
反观频率基模体,虽富集亮氨酸(L)和苯丙氨酸(F)带来高疏水性,但缺乏上下文关联,导致 MIC 值普遍偏高。
图 5:精氨酸富集模体与细菌膜表面的静电相互作用示意
结构预测验证:模体三维特征关联活性
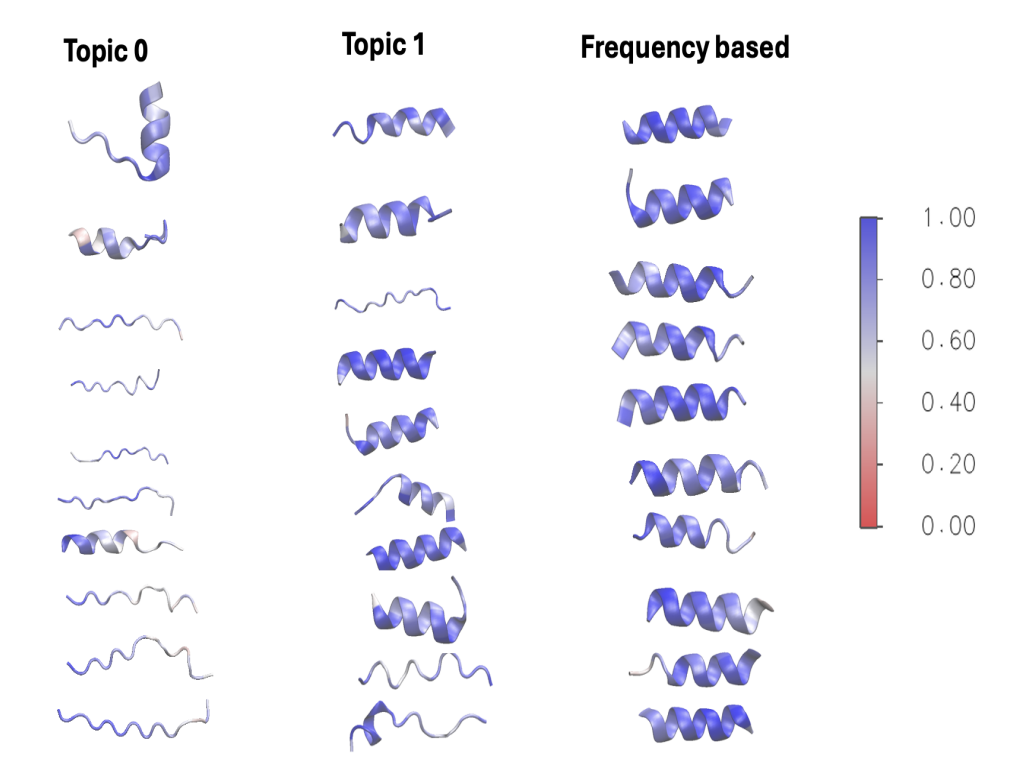
通过 ESMFold 对 14-mer 和 18-mer 模体进行结构预测,发现 LDA 模体结构多样性显著:
- 主题 1: 以 螺旋 (Helix) 为主。螺旋模体(如主题 1 的“TGLELMACKITNQC”)与低 MIC 值强相关,印证了螺旋结构在膜扰动中的优势。
- 主题 3: 多为 随机卷曲 (Random Coil)。
此外,熵值分析表明 LDA 模体多样性更高(熵值 >2.5),规避了频率基模体的重复性陷阱。
三、 产业启示:AIDD 的落地路径
这项工作的价值不在于发现某一条具体的序列,而在于证明了一种 可扩展的药物设计:在缺乏大规模带标签数据的前提下,仍然可以通过无监督模型,系统性地缩小搜索空间。
对于国内的生物医药研发团队,以下三点具有直接的可操作性:
-
算法策略升级
在处理肽类或蛋白质序列数据时,应降低对简单同源比对的依赖,引入 NLP 领域的 主题模型 (Topic Modeling) 或 注意力机制 (Attention Mechanism),以捕捉残基之间的隐式关联。 -
序列设计参数
- 短模体 (4-mer): 适合作为“积木”,用于构建多样性更高的新型组合库。
- 中长模体 (14-mer): 携带了完整的结构信息(如两亲性分布),适合作为核心骨架 (Scaffold) 进行保留或微调。
-
关注“功能性残基”组合
在设计新型抗菌肽时,应从单纯追求“高疏水+高正电”的暴力美学,转向关注 “脯氨酸-精氨酸” 等能够提供结构柔性和静电协同的特定组合。
总结
NIST 的这项研究表明,AI 在生物学中的应用已经跨过了“预测结构”的阶段,开始深入到 “理解功能逻辑” 的层面。
对于从业者而言,这意味着我们需要重新审视手中的数据处理管线:
那些被统计算法作为“低频噪声”过滤掉的信息里,或许正以此隐藏着解决耐药性危机的答案。
