
原来全球巨头都在为AI交智商税!DeepSeek-V3靠省钱大招,让英伟达慌了
在当下,全球科技巨头仿佛陷入了一场疯狂的赌局:他们笃信“大力出奇迹”,将数百亿美元砸向英伟达,疯狂抢购那些单价堪比豪车、且一片难求的顶级AI芯片。仿佛谁拥有的显卡多,谁就掌握了通往未来的门票。
然而,就在这场金钱游戏中,来自中国的DeepSeek团队扔出了一枚重磅炸弹。
他们的新模型 DeepSeek-V3 横空出世,不仅在能力上比肩顶尖的 GPT-4,更揭示了一个令资本市场颤抖的真相:我们过去对AI的认知可能全错了。 这一成果证明,AI算力之所以昂贵,或许并不是因为芯片不够强,而是因为我们一直在用极其低效的方法“烧钱”。
给法拉利装限速器还能赢?DeepSeek-V3极限逆袭
在这场AI军备竞赛中,有一个让所有入局者头疼的公开秘密:算力成本,既是护城河,也是碎钞机。
对于一家想做大模型的企业来说,入场券是昂贵的。训练一个聪明的大模型,动辄需要建立一个拥有数千张顶级显卡的超级计算中心。这不仅意味着烧掉数亿资金,更面临着物理瓶颈:随着模型越来越“胖”(参数变大),显卡的内存(显存)不够装了,显卡之间的数据传输也开始堵车了。
更严峻的现实是,由于供应链的客观限制,国内企业往往难以大规模获得海外最顶尖的“满血版”芯片,只能使用数据传输速度相对受限的版本。这就像是给一辆法拉利装上了限速器,再去参加F1比赛。
哪怕你的引擎(计算能力)再强,只要路不够宽(带宽受限),车队就跑不起来。几千张显卡就像几千个协同工作的工人,满血版芯片允许他们用5G视频通话高效协作,而受限版芯片只允许他们发短信。这意味着,显卡大部分时间不是在“干活”,而是在“等待数据”。对于投资者而言,显卡空转的那一秒,就是在白白烧钱。这种“效率折损”迫使企业面临一个残酷选择:要么接受迭代速度落后,要么花双倍的钱去堆数量。
在过去,市场普遍认为这是一个死局,硬件的上限已经锁死了企业的商业想象力与竞争天花板。但DeepSeek CEO梁文锋亲自挂帅的团队,通过最新的技术披露给出了绝地反击:既然硬件被锁死,那就在架构上把每一滴性能榨干。 这不仅是一次技术的突围,更是一份“如何在受限硬件下,把钱花在刀刃上”的商业教科书。
DeepSeek-V3凭什么花小钱办大事?
DeepSeek-V3 是在一个由2048张NVIDIA H800 GPU组成的集群上训练出来的。相比于拥有数万张H100的Meta或Google,这个算力规模并不夸张。他们是如何做到的?DeepSeek揭示了三大“降本增效”的撒手锏。
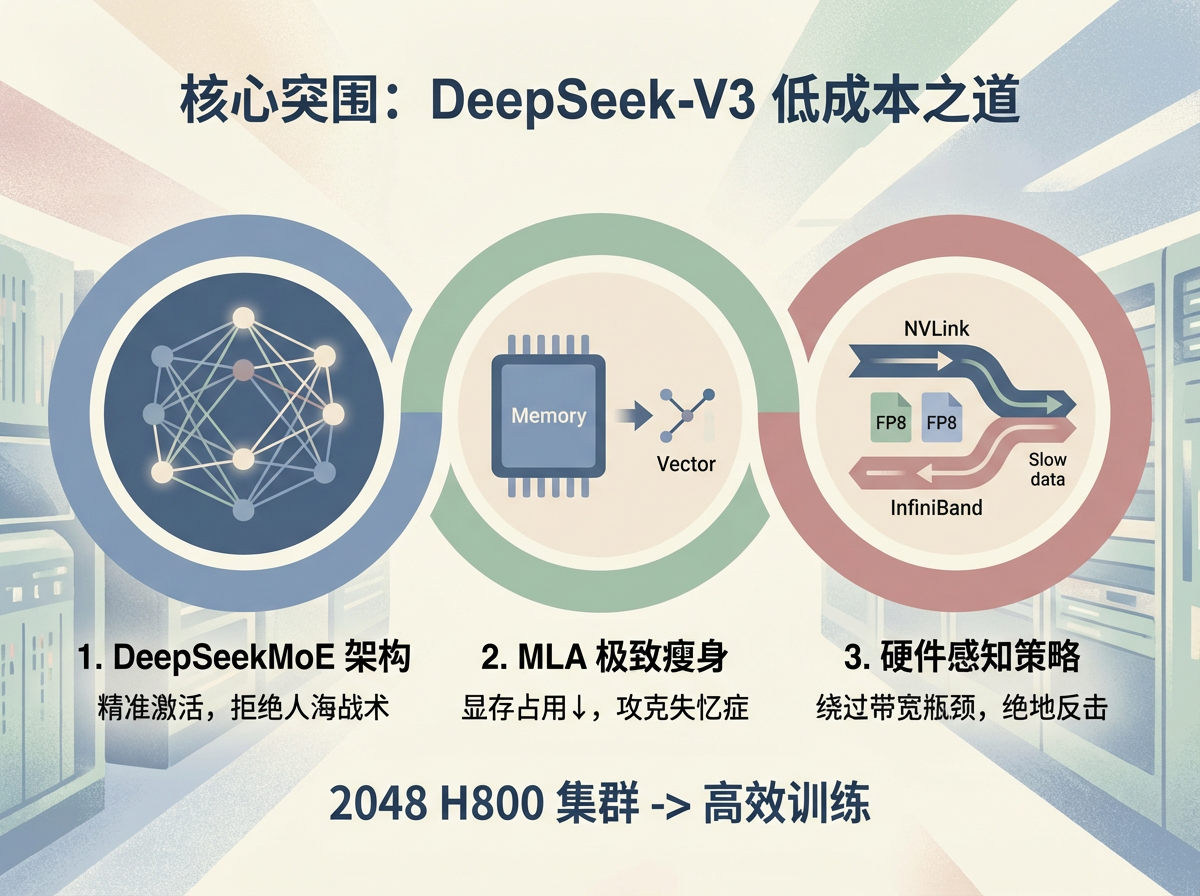
1. 拒绝“人海战术”:DeepSeekMoE 架构的效率魔法
【痛点直击】 传统的稠密模型(Dense Model)像是一个臃肿的大型国企,处理任何一个小任务都要全体员工(所有参数)参与,极其浪费算力资源。
【DeepSeek 破局】 混合专家架构(MoE)。
DeepSeek-V3拥有惊人的6710亿参数,这通常意味着天文数字般的计算量。但实际上,它在处理每个Token(字/词)时,仅激活370亿参数。
相比同级别的Llama-3.1-405B模型,DeepSeek-V3的计算成本降低了整整一个数量级(约250 GFLOPS vs 2448 GFLOPS)。这意味着,达到同样的效果,企业只需付出十分之一的电费和算力费,直接大幅降低了大模型训练与部署的商业门槛,让中小厂商也能具备顶级模型的竞争能力。这就像公司遇到了问题,不再召开全员大会浪费人力成本,而是精准指派3个最懂行的专家解决,其他人继续创造价值,极大提升了资源利用效率与商业回报。
2. 攻克“失忆症”:MLA 技术带来的极致瘦身
【痛点直击】 大模型虽然聪明,但“记性”太占地方。推理过程中产生的KV缓存(Key-Value Cache)会迅速吃光昂贵的显存,导致模型变慢甚至崩溃。这也是为什么现在的大模型很难塞进手机里的原因。
【DeepSeek 破局】 多头潜在注意力(MLA)。
你可以将其理解为一种极高效率的“速记法”。DeepSeek通过数学上的投影矩阵,将繁重的信息压缩成极小的向量。
DeepSeek-V3处理每个Token仅占用70 KB的显存。作为对比,Meta的LLaMA-3.1 405B需要516 KB,阿里的Qwen-2.5 72B需要327 KB。
目前,显存占用的断崖式下跌,直接意味着单张显卡能服务的用户数量翻倍,显著提升了模型商业化部署的盈利空间。而DeepSeek的这一改变,更打通了高性能AI从云端走向终端的关键商业路径——对于AI PC、智能终端厂商而言,这意味着更低的硬件适配成本与更丰富的功能创新可能,为终端AI商业化开辟了新赛道。
3. 带着镣铐跳舞:针对“阉割版”带宽的绝地反击
【痛点直击】 H800 GPU最大的痛点是NVLink带宽被限制在400GB/s(H100是900GB/s)。数据在显卡之间传输就像在早高峰的二环路上爬行,算力再强也得等数据传输到位。
【DeepSeek 破局】 硬件感知的“过桥”策略。
- FP8 混合精度训练: DeepSeek是全球首个在大规模MoE模型上成功应用FP8(8位浮点数)训练的团队。简单说,就是降低数据传输的精度(相当于看视频从4K降级到1080P),但不影响最终画质(模型智能),从而让数据传输量减少50%,直接绕过了带宽瓶颈。
- 节点感知路由: 既然跨服务器传输慢,那就尽量在服务器内部解决问题。DeepSeek设计了一套智能物流系统,优先走“内部高速公路”(NVLink),少走“外部拥堵路段”(InfiniBand),完美规避了H800的硬件短板。
彻底颠覆AI圈:从拼钱烧芯片,到拼脑子省成本
DeepSeek此次的技术披露,其价值远超DeepSeek-V3产品本身,它像是一份**“AI行业的独立宣言”**,向整个资本市场和科技圈释放了三个足以重塑行业规则的信号:
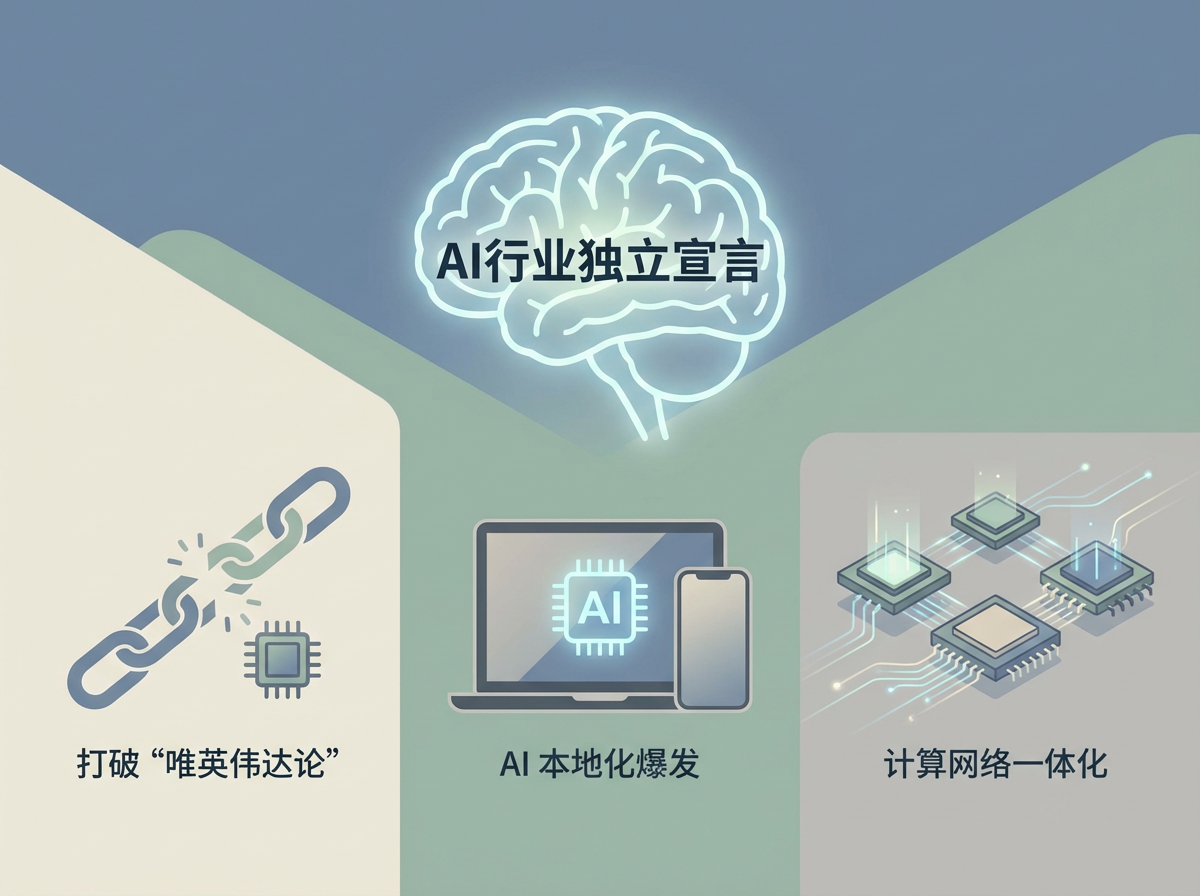
1. 打破“唯英伟达论”:硬件不是唯一的救世主
过去两年,整个AI行业陷入了一种病态的“硬件崇拜”,形成了畸形的商业评估逻辑:投资者判断一家AI公司的价值,先问手握多少张H100芯片。这种逻辑推高了英伟达的市值,却让行业陷入“烧钱竞赛”——创业公司被迫背负沉重的“算力税”,盈利周期被无限拉长,行业资源大量浪费在低效的硬件堆叠上。
DeepSeek的成功是一个转折点。它证明了,通过优秀的硬件感知协同设计(Co-design),可以用二流的硬件跑出一流的成绩。这意味着,“算力霸权”并非不可撼动,“智力(算法架构)”可以弥补“体力(芯片性能)”的不足。 对于那些买不到顶级芯片的中国企业,或者预算有限的全球创业者来说,这无疑是一针强心剂:与其在硬件军备竞赛中被巨头拖死,不如在软件架构上寻找弯道超车的机会。
2. AI 本地化爆发:把“超级大脑”装进你的笔记本
长期以来,大模型因为“太胖”(参数大、显存占用高),只能住在云端昂贵的数据中心里。用户每问一个问题,数据都要在你的电脑和远在千里之外的服务器之间跑个来回。这不仅反应慢,而且如果你断网了,AI就“傻”了。
DeepSeek-V3在推理端的极致高效(V2版本仅需210亿激活参数即可运行),意味着高性能AI不再必须依赖云端。每秒20个Token的生成速度,已经可以在配备AI芯片的高端个人电脑甚至未来的旗舰手机上流畅运行。
这是一个巨大的商业信号:AI将从“云端服务”走向“终端应用”。
未来,你的笔记本电脑里将住着一个不需要联网、反应极快、且永远不会泄露隐私的超级秘书。它不仅能帮你瞬间整理完几百份本地文档,还能在你开会时实时记录重点——而且这一切都在你自己的设备上完成,不需要给大公司交“会员费”。这会直接引爆AI PC和AI手机的换机潮,重塑整个消费电子市场。
3. 半导体的新风向:从“算得快”到“传得快”
DeepSeek在论文中花了大量篇幅探讨网络架构(多平面胖树 MPFT)和通信延迟,甚至不得不为了绕过带宽瓶颈设计复杂的软件策略。这实际上是给全球半导体行业提了一个醒:现在的芯片,“偏科”太严重了。
目前的GPU计算能力过剩,但通信能力(带宽)严重滞后。未来的AI芯片竞争,将不再仅仅是比拼谁的计算核心多,而是比拼谁能更好地解决“内存墙”(数据存不下)和“通信墙”(数据传不动)的问题。“计算网络一体化”将成为下一个万亿级风口。
能够让芯片之间像“连体婴儿”一样无缝共享数据的技术(如CXL、光互连),将取代单纯的算力堆叠,成为资本追逐的新宠。
从全球科技巨头疯狂烧钱抢芯片,到DeepSeek-V3用架构创新打破算力困局,这场AI行业的变革已悄然来临。DeepSeek-V3不仅是一款实力出众的模型,更像是一份写给所有从业者和投资者的低成本AI生存指南。
它清晰地告诉我们,在摩尔定律逐渐放缓、硬件成本居高不下的今天,盲目跟风堆算力早已不是最优解,唯有深耕架构设计、挖掘软件潜力的创新,才是打破行业僵局的唯一出路。对于那些紧盯AI赛道的投资者而言,与其执着于哪家公司融资多、手握多少张顶级显卡,不如多关注像DeepSeek这样的团队——他们真正懂得如何把昂贵的AI技术,做成像水电煤一样普惠、廉价的基础资源。
毕竟在商业世界的终极竞争中,从来都不是谁烧的钱越多谁就越强大,而是谁能把成本降到极致、把效率提至顶峰,谁就真正拥有了定义未来AI时代的权力。而DeepSeek-V3的横空出世,正是这场变革的有力注脚。
