
很多肿瘤不是没被发现,而是一开始就被“算错了”:DeepSomatic给出新解法

在肿瘤基因检测中,真正昂贵的不是测序本身,而是“算错”。一次错误的突变判断,可能意味着选错靶向药、错过治疗窗口,甚至让患者走上完全不同的治疗路径。问题并不在于数据不够,而在于我们长期使用的判断逻辑并不适合这种高度噪声、强异质性的任务。Google Research推出的DeepSomatic,并不是让检测更快,而是试图解决一个更根本的问题:如何更准地判断哪些突变才真正重要。
肿瘤检测真正贵的,是“误判”
很多人以为,精准医疗的门槛在于“数据量”。但在肿瘤基因检测的真实世界里,情况恰恰相反:数据早就够了,真正的问题是判断不够准。
在一个典型的临床路径中,肿瘤样本会被送去做全基因组(WGS)或全外显子组(WES)测序。检测本身并不便宜,但更贵的是后续的决策——用什么药、怎么联合、是否参与临床试验。这些选择,几乎全部建立在“突变是否真实、是否关键”的判断上。
如果这个判断错了,后面的一切都会错。但现实是,很多肿瘤突变不是没被“发现”,而是被“算错”了。
为什么肿瘤突变这么容易被“误判”?
从生物学角度看,癌症是一种由体细胞突变驱动的疾病。它的关键不在于继承自父母的稳定种系变异,而在于个体一生中不断积累的突变组合。
理论上,只要我们能准确识别这些突变,就能更有针对性地设计治疗方案。但现实却极其复杂:
1. 真正的突变,往往非常“弱”
很多体细胞突变的出现频率很低,它们淹没在大量背景噪声中,信号强度甚至接近测序误差本身。
2. 样本条件非常“脏”
临床中大量样本来自FFPE(福尔马林固定石蜡包埋)组织,这种保存方式会引入系统性 DNA 损伤模式;而在血液肿瘤(如白血病)中,往往根本没有“正常对照”样本。
3. 癌症的异质性极高
即便是同一种癌症,不同个体的突变分布也可能完全不同。这让基于固定规则的算法极难适配。
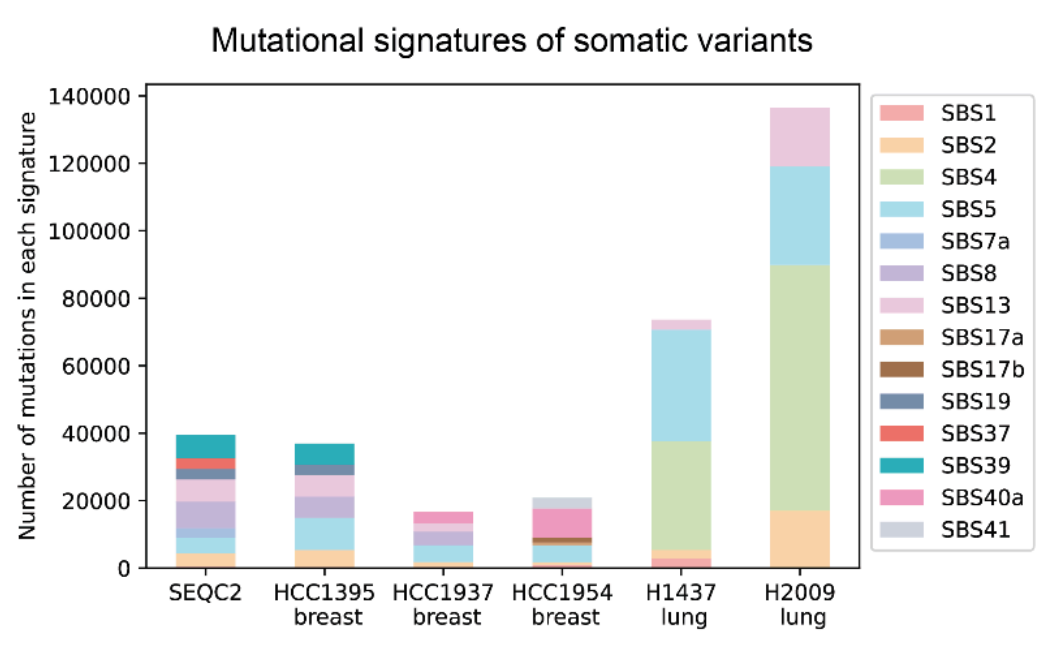
用于训练DeepSomatic的基准数据集。每个柱状图显示了在四个乳腺癌样本和两个肺癌样本中发现的突变数量,颜色代表不同类型的突变。肺癌显示出一种由环境毒素引起的显著突变类型,包括以绿色显示的SBS4突变。但即使是同一种癌症,其突变特征也存在很大差异。图片来源:Google
这些因素叠加在一起,导致一个现实问题:肿瘤突变识别,本质上不是“算力问题”,而是“判断问题”。
DeepSomatic到底换了什么解法?
DeepSomatic是Google Research与加州大学圣克鲁兹等机构联合开发的一款体细胞变异识别模型。它的核心创新,并不是“算得更快”,而是换了一种判断方式。
传统方法的逻辑是:规则判断。大多数变异检测工具基于统计模型和人工规则:如果满足某些阈值,判为突变;如果不满足,视为噪声。但问题在于,肿瘤样本的真实分布,并不总是服从这些假设。
DeepSomatic的逻辑是:模式识别。DeepSomatic的思路更接近于视觉识别,而不是数值比对:
1.它先把测序比对结果转化为张量化的“图像表示”,编码:
- 碱基对齐模式
- 质量分布
- 上下文结构
- 样本间差异
2.然后使用卷积神经网络(CNN)直接学习这些模式之间的差异。
3.输出的是:
- 参考序列
- 种系变异
- 体细胞变异
- 测序噪声
的分类结果。
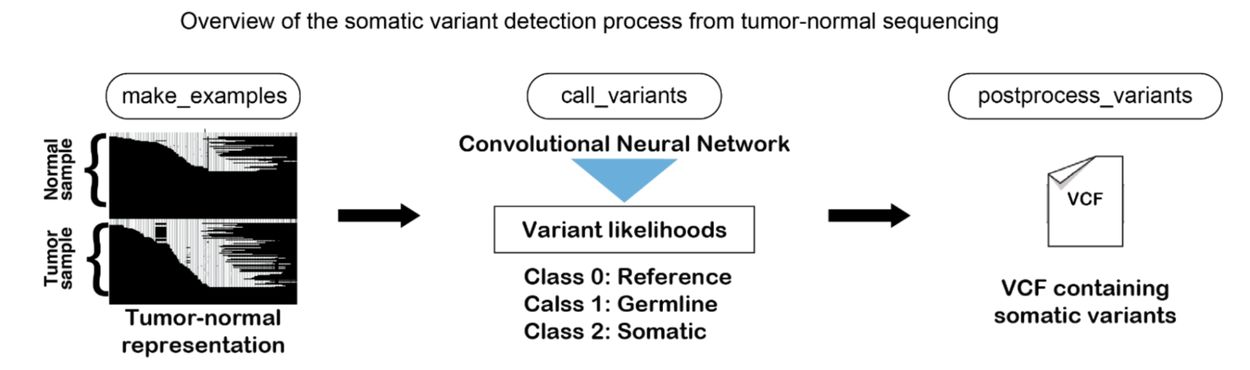
DeepSomatic能够检测基因组数据中的癌症变异。首先,它将肿瘤细胞和非癌细胞的测序数据转换成图像。然后,DeepSomatic将这些图像输入其卷积神经网络,以区分参考基因组、该个体中的非癌症种系变异以及肿瘤中由癌症引起的体细胞变异,同时剔除由微小测序错误导致的变异。最终得到一份癌症致病变异(或突变)列表。图片来源:Google
这是一个关键变化:从“它是否符合某条规则”,变成了“它看起来像不像一个真实的突变”。
它到底比传统工具强在哪里?
DeepSomatic的优势,并不体现在理想条件下,而是在最难的真实场景中。
1. 跨平台适配能力
它同时支持:
- Illumina(短读长)
- PacBio HiFi(长读长)
- Oxford Nanopore(长读长)
这意味着在真实实验室环境中,不同硬件的输出可以用同一套判断逻辑处理。
2. 对Indel的显著提升
插入/缺失变异(Indel)是影响蛋白结构的关键类型,但也是传统工具最不稳定的部分。官方测试显示:
- Illumina:DeepSomatic ≈ 90%,次优 ≈ 80%
- PacBio:DeepSomatic > 80%,对比工具 < 50%
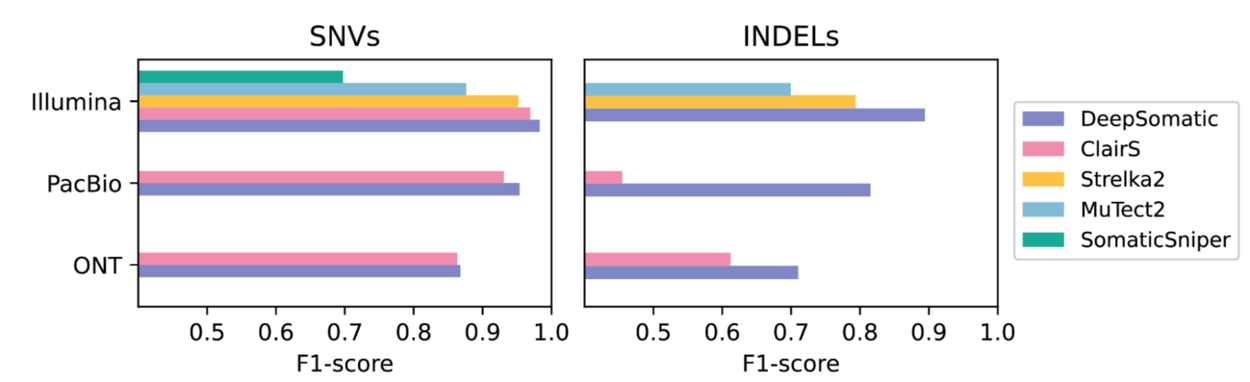
图中紫色部分展示了DeepSomatic对广泛用于研究的乳腺癌样本的检测结果,并与其他工具进行了比较。多种软件工具可以识别Illumina测序数据中的癌症变异,而对于PacBio和Oxford Nanopore Technologies生成的长读长测序数据,目前只有一种替代工具(粉色部分)可用。F1分数用于衡量检测到的变异数量及其准确度。DeepSomatic在检测单核苷酸变异(即基因密码中的单字母变异)方面表现略好,而在检测插入/缺失(Indel)变异方面则有显著提升。图片来源:Google
3. 对复杂样本更稳健
在FFPE样本或仅做WES的样本中,DeepSomatic仍保持较高准确性。
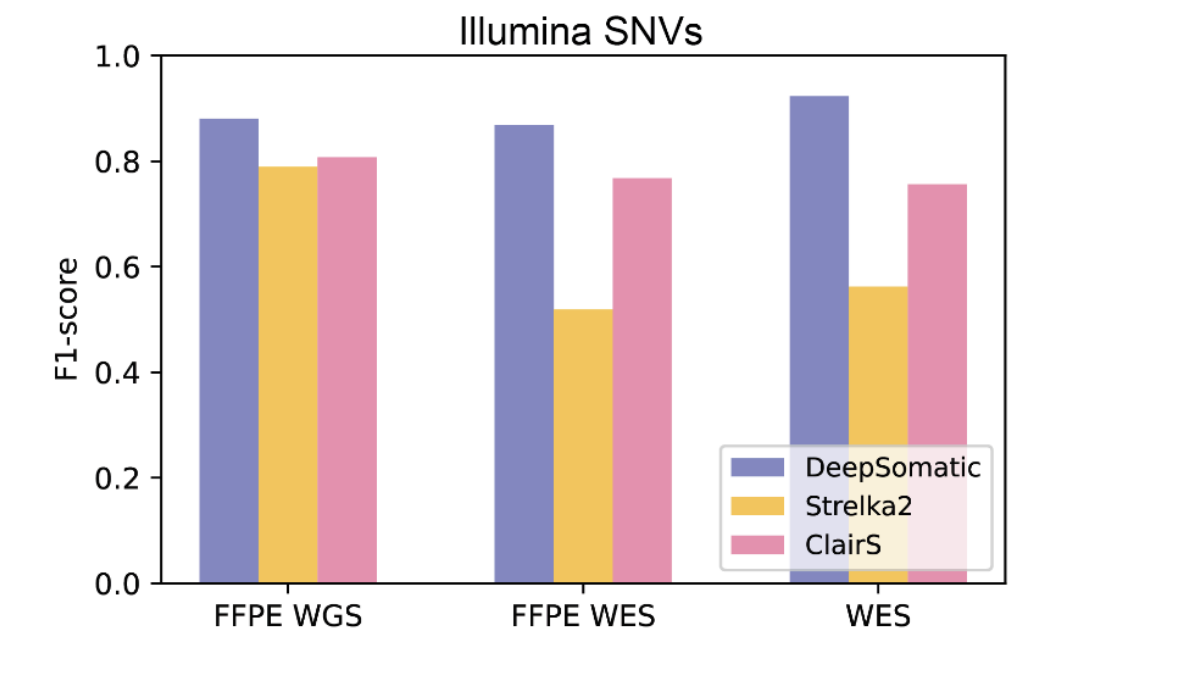
DeepSomatic对采用更复杂的预处理步骤制备的样本具有显著更高的准确率,这些步骤包括:固定福尔马林石蜡包埋(FFPE),一种用于保存组织样本的方法;以及全外显子组测序(WES),一种仅对基因组中编码蛋白质的部分进行测序的方法。中间部分展示了一个采用FFPE保存并进行全外显子组测序的样本。图片来源:Google
4. 支持tumor-only场景
在没有正常对照样本的情况下,它仍能尝试区分体细胞突变与背景信号。这对血液肿瘤等场景极为重要。
它不只是工具,而是判断层的基础设施
如果把精准医疗的链条简化为:测序 → 变异识别 → 临床解读 → 治疗决策,那么DeepSomatic所在的第二步,恰恰是整个系统中最脆弱也最关键的一步。
影像 AI 解决的是“你看到了什么”,DeepSomatic解决的是“你到底该信谁”。这让它不只是一个算法,而是一种判断引擎。
它值钱的地方不在“卖给病人”
DeepSomatic并不是一个面向患者直接收费的产品,它的价值更接近于“底层基础设施”。它真正影响的是:
- 医院的误判率
- 药企的靶点可信度
- 科研项目的可复现性
- 检测公司的技术壁垒
Google选择将其开源,并不等于“无商业价值”,而更像是在推动它成为事实标准。一旦大量项目基于它构建流程,围绕它的集成、认证、服务、合规模块,才是产业化的核心。
从科研走向产业标准:它会怎么落地?
这类“判断引擎型”技术,通常会经历四个阶段:
1.科研验证期(当前)
2.临床集成期
3.药企 / CRO绑定期
4.行业标准期
当足够多的人用它来“对齐结果”,它就不再是一个工具,而是一种默认判断方式。
把技术指标翻译成真实价值
技术层面上,DeepSomatic提高了F1分数、Indel识别率和复杂样本稳定性。产业层面上,这意味着:
- 对医生:误判风险下降
- 对患者:治疗路径更稳定
- 对药企:靶点更可信
- 对研究者:可复现性更强
这不是性能的提升,而是决策可靠性的提升。
不是“有没有”,而是“准不准”
精准医疗真正的门槛,从来不是“有没有数据”,而是“你敢不敢信你的判断”。DeepSomatic的意义不在于它用了AI,而在于它重新定义了:什么才叫“可信的判断”。很多肿瘤看起来难解,不一定是因为它们无法理解,而是因为我们过去一直在用错误的方式去判断它们。
DeepSomatic 不是终点,但它正在改变起点。
