
当硅谷还在刷分,中国已在定标准:MedGPT 拿下全球医疗 AI 冠军
如果你是三甲医院院长,会选只会考试的硅谷学霸AI,还是获Nature子刊认可、由国内顶级专家划定“安全红线”的国产模型?
长期以来,医疗AI陷入一个商业悖论:实验室准确率惊人,临床医生却不敢用。核心痛点在于通用模型学习的是概率,而临床面临的是后果——一个药量的失误对AI只是扣分,对患者却是生命。近日,中国AI医疗公司“未来医生”协同北京协和、北大口腔等顶尖机构的32位专家,在Nature体系期刊发布了全球首个双轨评价标准CSEDB。
它终结了医疗AI只拼智商的时代,强制要求AI必须像医生一样,在确保不触发“误诊、禁忌用药”等致命红线的前提下,再谈有效性。在这一标尺下,中国自研模型MedGPT击败了OpenAI o3、Gemini-2.5等硅谷巨头摘得全球冠冕。这标志着中国团队不仅拿下了技术高地,更在顶尖学术界率先定义了医疗AI从技术工具转向临床责任的生存准则。

为什么实验室的医疗AI一进诊室就露怯?
在商业分析视角下,医疗AI存在巨大的交付落差。通用大模型虽能高分通过执业考试,但在商业落地中渗透率极低。根源在于底层逻辑错位:通用模型本质是基于概率的语言机器,学习的是话术合理性,而非医学严谨性。
北京协和医院梁乃新教授指出,真实临床复杂性远超标准化考试。考试核心是知识提取,而诊疗是多变量博弈。例如面对多病共存的老年患者,通用模型常因识别主症给出标准建议,却极易忽视并发症禁忌。在AI逻辑中这可能只是千分之一的统计失误,但在医疗逻辑中却往往意味着不可逆的重大风险。
这种“概率幻觉”导致了商业闭环的断裂。对医疗机构而言,无法预判那1%失误何时发生的系统,其商业价值甚至是负数。在现有法律框架下,AI无法承担主体责任,决策偏差的风险最终全由医院和医生承担。这种“责任真空”导致三甲医院对通用AI天然排斥,哪怕其榜单成绩再好。
此外,现有评测体系忽略了医疗核心——后果控制。传统指标关注准确率,但医生不仅要知病“是什么”,更要预判方案“会发生什么”。缺乏量化临床风险的标尺,让医疗AI长期被挡在严肃诊疗门外,只能在导诊等边缘场景徘徊。
CSEDB标准的野心:从拼智商到定规矩
商业竞争的最高境界是制定标准。正如5G领域的标准之争决定了通信巨头的十年兴衰,医疗AI的下半场,谁掌握了评判权,谁就掌握了通往万亿市场的准入证。此次登上Nature子刊的CSEDB(Clinical Safety-Effectiveness Dual-Track Benchmark),其核心价值在于它终结了医疗AI自说自话的时代,为真实临床能力建立了一个基于专家共识的、可量化的标准化基准。
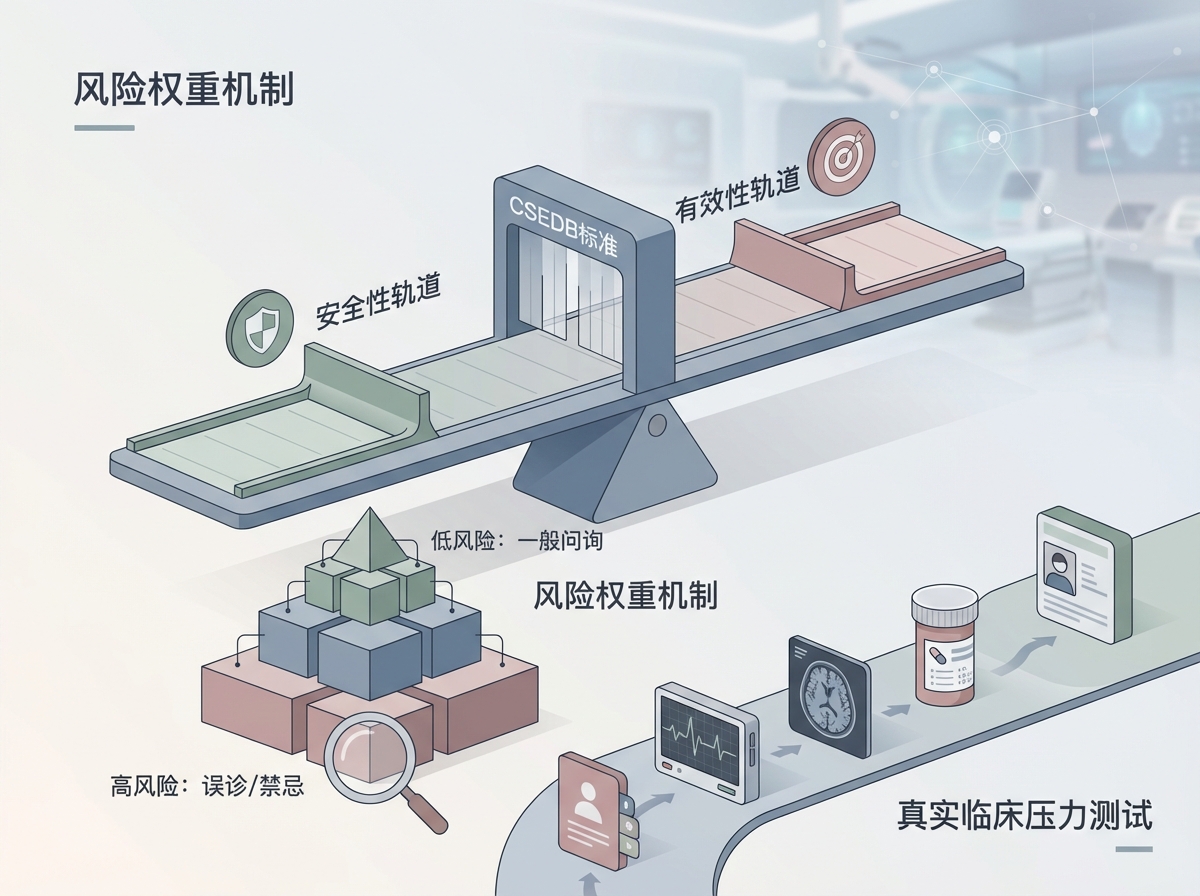
1. 首次引入“安全性与有效性双轨评价体系”
- CSEDB最重大的创新在于它打破了以往一刀切的总分评测逻辑。在传统标准中,一个AI即便犯了一个致死性错误,只要它在其他99个病例上表现优秀,依然能拿到高分。而CSEDB设立了两道平行的门槛:安全性轨道与有效性轨道。只有当模型同时通过这两项测试,才被认为具备临床部署的基本资格。这种设计逻辑将“不伤人”放在了“能治病”的前面,从根源上契合了医学伦理的底线,也为监管机构提供了清晰的决策依据。
2. 引入风险权重机制:像精算师一样看病
- CSEDB在指标设计上引入了极其细腻的分级机制。它根据潜在的临床风险,将每一项评估指标赋予了1到5级的权重。涉及误诊、严重用药禁忌、忽视严重过敏史等高风险情境的指标,会对最终评分产生决定性的影响。这种评分结构实际上是在模拟医疗决策中的风险控制体系,倒逼开发者在训练模型时就必须将“风险厌恶”植入算法底层,而非盲目追求回答的博弈性与丰富度。
3. 覆盖真实临床场景的“压力测试”数据集
- 为了支撑这套标准,专家团队构建了一个包含2069个开放式问答条目的数据集。这些问答场景并非来自教科书,而是高度贴近一线临床的真实病例推演。它涵盖了从危急重症识别到致死性诊断失误,再到剂量与器官功能失配等极具挑战性的闭环。这种以医疗后果为中心的设计,让它能够跨越不同国家、不同医疗体系的鸿沟,成为一套具备跨体系参考价值的临床能力度量衡。
既然标准的生死线已经划定,那么谁能率先跳过这道坎?在CSEDB的严苛评测中,全球主流模型悉数受试,而最终摘得榜首、甚至在安全性评分上让OpenAI都略逊一筹的,是来自中国公司“未来医生”的自研产品——MedGPT。
MedGPT的技术大拆箱:为什么它能击败硅谷巨头?
在商业战场上,能够长期领先的产品往往具有难以被简单复刻的工程壁垒。MedGPT之所以能在CSEDB的严苛测试中摘得全球桂冠,并成为唯一一个安全性评分超过有效性的模型,是因为它在底层架构上彻底告别了黑盒化的概率预测,转而构建了一套尊重医学复杂性的快慢双系统。
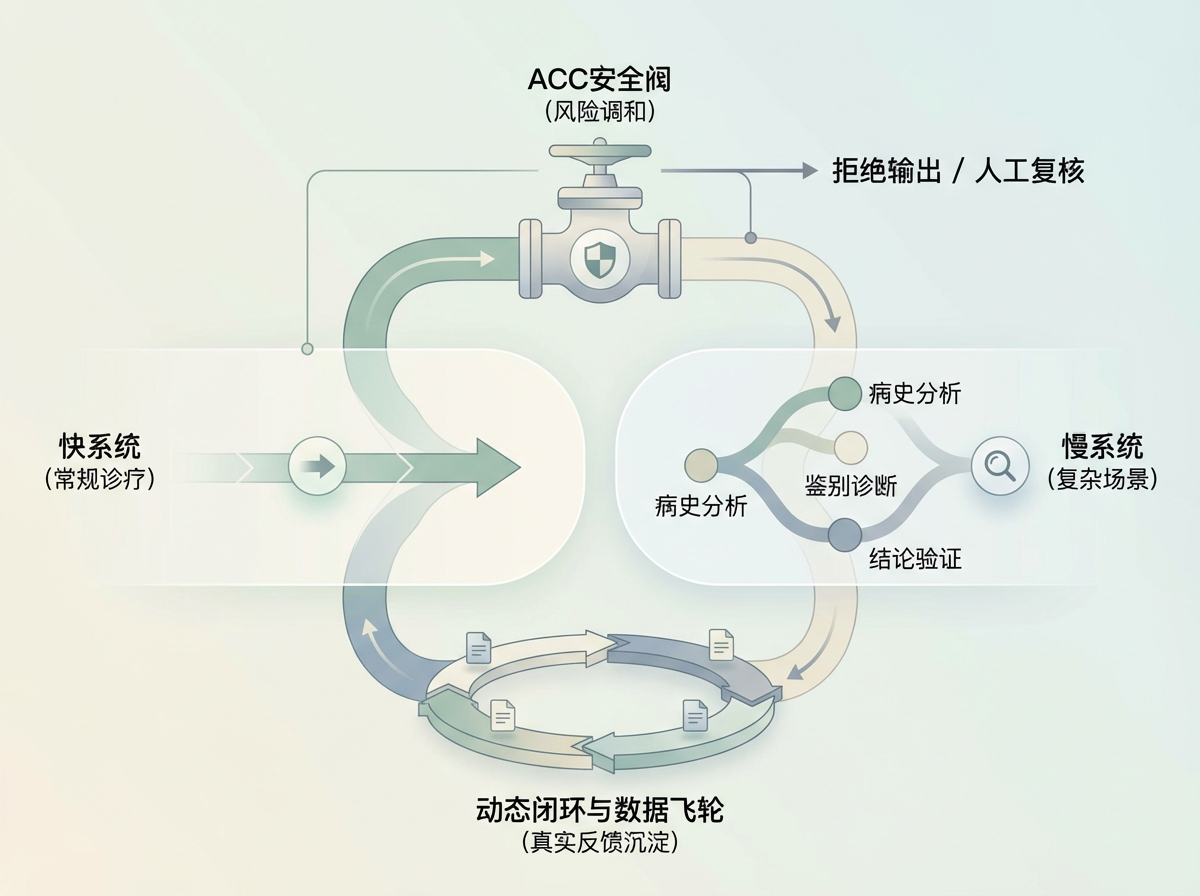
1. 模仿人类专家思维的“快慢双系统”模式
- MedGPT的核心架构借鉴了诺贝尔奖得主丹尼尔·卡尼曼的认知理论。其“快系统”专为路径清晰、风险可控的常规诊疗设计,采用轻量化推理,响应速度达到百毫秒级,主打效率;而“慢系统”则针对复杂、高风险的临床场景,它会主动拉长推理链,将诊断拆解为“病史分析-鉴别诊断-结论验证”等多个步骤,并调用权威医学知识库进行多轮交叉校验。这种架构有效解决了大模型常见的鲁莽幻觉。
2. ACC层:医疗决策的安全阀
- 为了处理快慢系统可能出现的冲突,MedGPT引入了专门的风险调和与控制机制——ACC层。当系统在深度推理中发现风险信号,或者信息不确定性超过安全阈值时,ACC层会强制干预。这种机制让MedGPT具备了拒绝输出的能力,在无法确保安全的情况下,模型会直接引导患者向人工医生寻求帮助。这种自知之明,是将其转化为严肃医疗工具的关键一步。
3. 医学逻辑的显式建模与动态闭环
- 不同于通用大模型的一次性生成,MedGPT将临床决策过程拆成了结构化路径,每一步推理都有据可查、可追溯。更重要的是,它建立了一个庞大的数据飞轮:持续沉淀来自大量一线医生的真实诊疗反馈数据。这种临床反馈在环的训练模式,让模型的进化方向始终被真实场景牵引,使其准确率能够以每月1.2%-1.5%的速度稳定提升。这种从实践中来到实践中去的工程能力,构成了MedGPT的核心壁垒。
质疑与反思:既当裁判又当选手?
看到这里,敏锐的读者或许会问:标准由“未来医生”协同制定,冠军又由MedGPT摘得,这是否有“既当裁判员又当运动员”之嫌?
事实上,这恰恰反映了医疗AI赛道的高门槛——在这个人命关天的领域,只有最懂雷区在哪里的选手,才有资格参与标准的测绘。
首先,CSEDB并非闭门造车,它通过了《npj Digital Medicine》严苛的匿名同行评审,其评价维度的客观性获得了国际学术界的背书。其次,来自协和、阜外等顶尖医院的32位一线临床专家全程参与。对于这些专家而言,学术声誉远重于商业站台。他们加入的本质,是为AI诊疗划定一条医学伦理红线。
从商业竞争角度看,这更像是一场开卷考试。中国团队主动公开了一套极高难度的考卷,并诚邀全球巨头同台竞技。如果说硅谷大模型追求的是全知全能的上限,那么中国团队通过CSEDB和MedGPT锁定的,则是绝对安全的底线。
商业拼图的最后一环:让AI变身人人用得起的数字名医
在医疗AI这场长跑中,单纯的技术领先并不能自动转化为商业成功。未来医生团队的高明之处在于,他们并没有仅仅停留在刷榜阶段,而是以MedGPT为动力引擎,构建了一个精准匹配不同医疗角色与场景的产品矩阵,从而实现了从技术实验室到商业生态位的纵深布局。
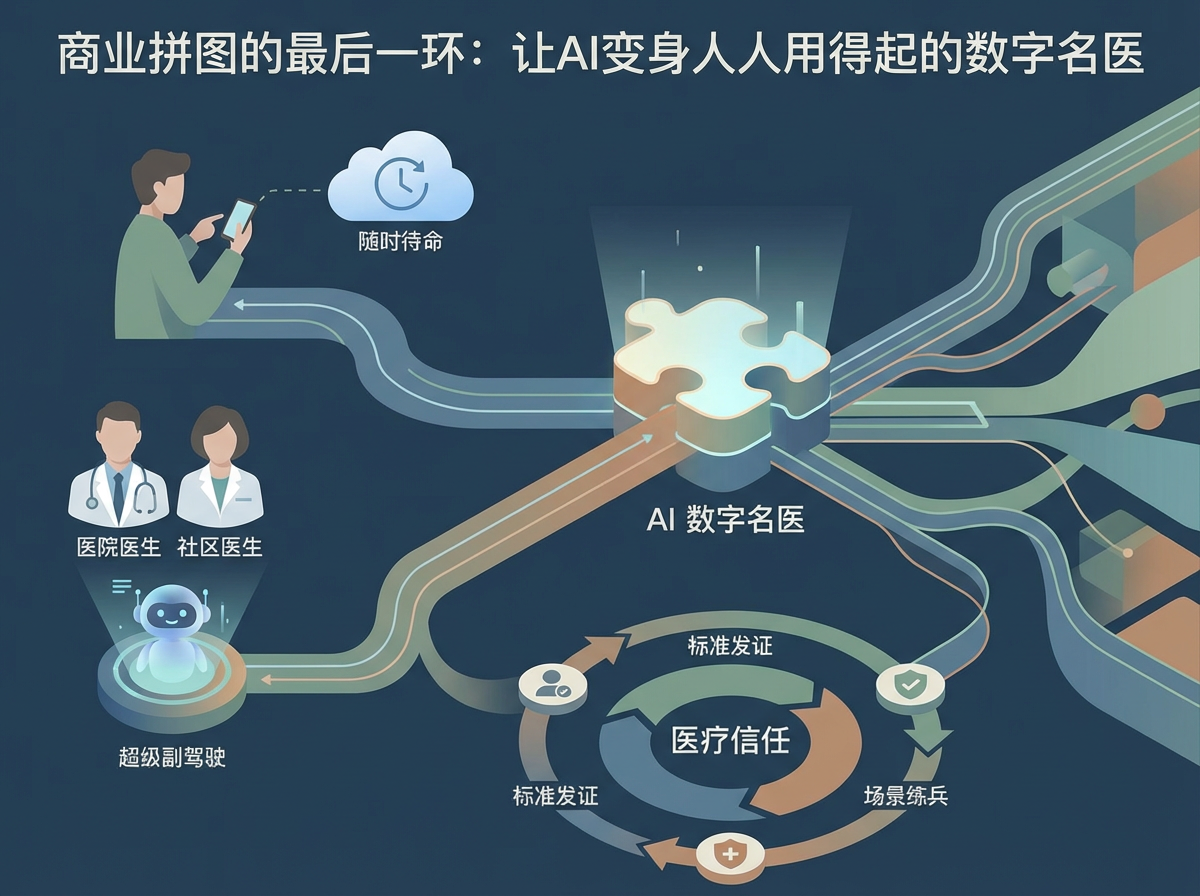
•对患者:随时待命的专家分身。 中国人看病最难的是名医难求。MedGPT通过AI实现了优质医疗资源的无限复制,把顶级医生的诊疗能力变成了一段代码,7×24小时在线。这意味着,以前需要排队数月才能挂上的专家号,现在通过手机就能获得同等严谨的建议,让高品质医疗服务像水电一样触手可及。
• 对医生和基层:配备一名超级副驾驶。 在大型医院,它帮医生写病历、查文献,把专家从繁琐杂事中解放出来去攻克科研难题。在资源匮乏的偏远基层,它成了社区医生的全能导师,在诊断关键时刻提供预警,有效拦截误诊风险。它并非要取代医生,而是让医疗资源的供给效率实现了指数级翻倍。
• 竞争壁垒:标准发证,场景练兵。 这种牵引式进化构成了其核心护城河:CSEDB标准是AI进入临床的“准生证”,确保其靠谱;而产品矩阵则是AI的大练兵场,通过千万名医生的真实反馈让AI越用越聪明。这种从标准到产品的完整闭环,让未来医生赢得了行业内最稀缺的资产——医疗信任。
市场趋势展望:医疗AI正从算力竞赛转向信任竞赛
放眼全球医疗大模型市场,一个清晰的转折点已经出现:医疗AI的竞争,正在从单纯的能力展示阶段,正式进入责任定义阶段。以往那种依靠堆叠算力、增加参数规模来刷榜的玩法,在严肃医疗场景下已经显得力不从心。未来的行业巨头,必然是那些能够将AI的智能转化为医疗信任的企业。
从宏观角度看,中国团队在Nature子刊发布标准,标志着中国在医疗AI领域已经从规则跟随者变成了规则制定者。在过去,我们往往在硅谷定义的框架内进行追赶,但在医疗这种对行业洞察要求极高的细分赛道,中国团队凭借着庞大的临床样本和对医疗逻辑的深度尊重,抢占了全球话语权。这种标准输出的商业意义巨大,它意味着未来的全球医疗AI评测,可能会在很大程度上参考中国团队制定的这套框架。
同时,医疗AI的估值逻辑也将发生重构。传统的医疗服务受限于人力成本和物理空间,是典型的线性增长模式;而AI驱动的医疗服务,其核心资产是“数字化医疗逻辑”和“可规模化的信任”。当MedGPT这样的模型能够被证明在安全性上达到甚至超过人类医生,且能以零边际成本进行服务分发时,标志着中国在医疗AI领域开始从规则跟随者,向规则共建与制定者转变。
总结而言,在这场名为医疗AI的马拉松中,短期技术领先并不罕见,长期兑现的临床价值却极其稀缺。MedGPT在CSEDB标准下的夺冠,不仅是一次技术的胜利,更是一次对医疗复杂性敬畏之心的胜利。它预示着一个新时代的到来:AI不再是只会背书的学霸,而是能够真正承担责任、赢得医患信任的数字化医生。在这个从智能转向信任的过程中,谁能跑通“安全与有效”的双轨,谁就将拥有未来医疗市场的入场券。
