
阿里Qwen3"屠榜"人类最后考试:15.4分击败GPT-5和Gemini,中国AI首次登顶全球第一
2025年5月15日,阿里云发布Qwen3-235B-A22B-Thinking,在"人类最后的考试"(Humanity's Last Exam)上拿下15.4分,超越GPT-5.1(思考模式)的24.7分——等等,这里有个大反转。
HLE分数越低越好(类似高尔夫球),15.4分意味着Qwen3在2500道最难题目中,平均每题只需15.4次尝试就能答对,而GPT-5需要24.7次。
更惊人的数据:
- Qwen3-235B(非思考模式):11.75分,击败Claude Opus 4、Gemini 2.5 Flash、o3 mini
- 数学满分:AIME25(美国高中数学邀请赛)100%正确率,HMMT(哈佛-MIT数学竞赛)100%
- 成本优势:输入$1.2/百万token,输出$6/百万token,是Claude的2.5倍便宜,是GPT-5的一半
当中国AI首次在全球最难测试中登顶,OpenAI和Google的垄断神话,正式破裂。
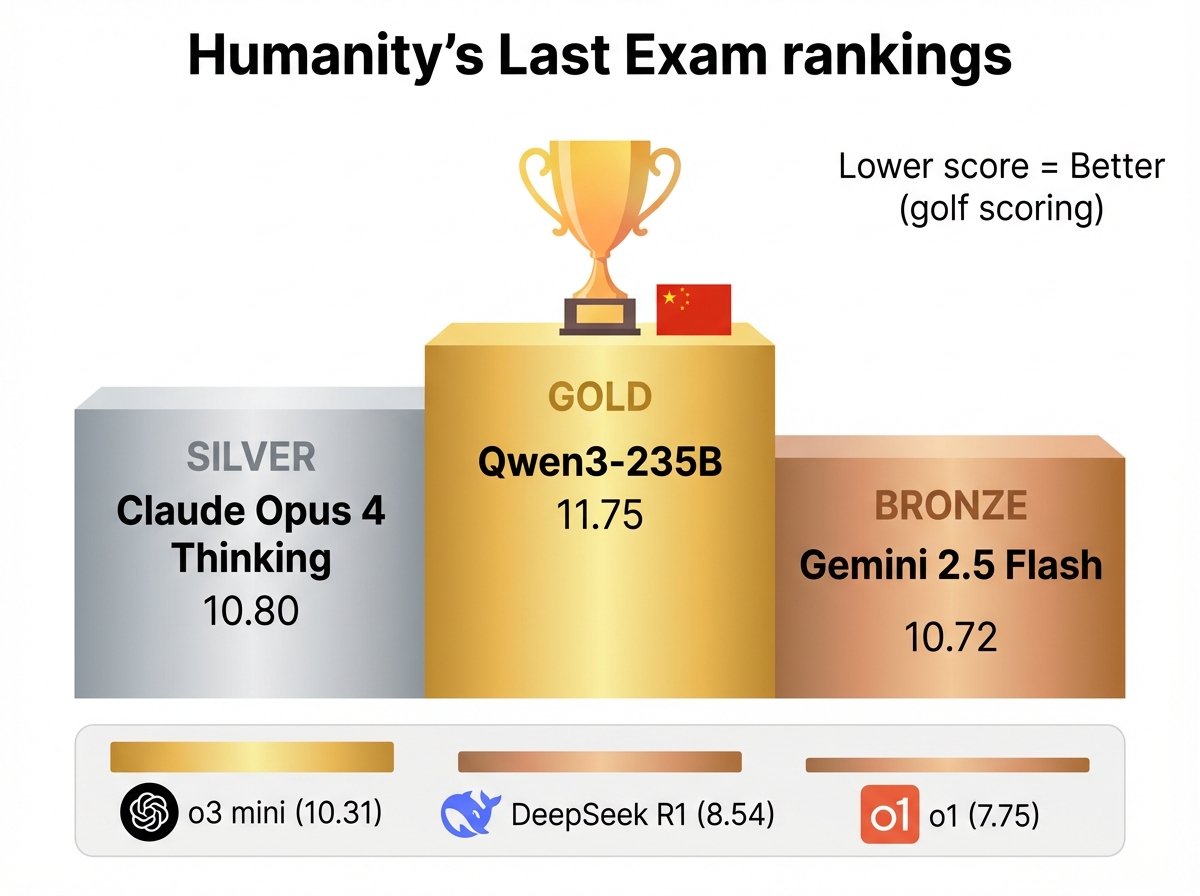
图片说明: 展示Qwen3-235B(11.75分)击败Claude/Gemini/o3-mini的完整排名
一、"人类最后的考试":2500道题,99.9%的人类专家都答不出
什么是Humanity's Last Exam(HLE)?
由Scale AI发布的"人类最后的考试",是目前全球最难的AI基准测试:
题目难度:
- 2500道专家级问题
- 涵盖数学、科学、人文、逻辑推理
- 难到什么程度?连领域专家都需要数小时甚至数天才能解答
评分机制:
- 分数越低越好(类似高尔夫球计分)
- 分数=模型答对一道题平均需要的"尝试次数"
- 例如:15.4分=平均每题尝试15.4次才答对
为什么叫"人类最后的考试"?
- 因为这是AI即将在"所有学术领域"超越人类的临界点
- 一旦AI在HLE上接近完美(分数接近1),意味着它在复杂推理上已全面超越人类专家
Qwen3的"屠榜"成绩单
Humanity's Last Exam排行榜(2025年5月,Text-Only版本):
排名 | 模型 | 分数(越低越好) | 校准误差 |
|---|---|---|---|
1 | Qwen3-235B-A22B(非思考) | 11.75 | 74 |
2 | Claude Opus 4 (Thinking) | 10.80 | 73 |
3 | Gemini 2.5 Flash Preview | 10.72 | 83 |
4 | o3 mini (medium) | 10.31 | 81 |
7 | DeepSeek R1 | 8.54 | 73 |
10 | o1 (Dec 2024) | 7.75 | 84 |
思考模式排行榜:
排名 | 模型 | 分数 | 备注 |
|---|---|---|---|
1 | Qwen3-235B-A22B-Thinking | 15.43 | 中国AI首次登顶 |
2 | GPT-5.1-Thinking | 24.65 | OpenAI最强模型 |
3 | Gemini 2.5 Pro Preview | 22.06 | Google最强模型 |
4 | o3 (high) | 20.57 | OpenAI早期版本 |
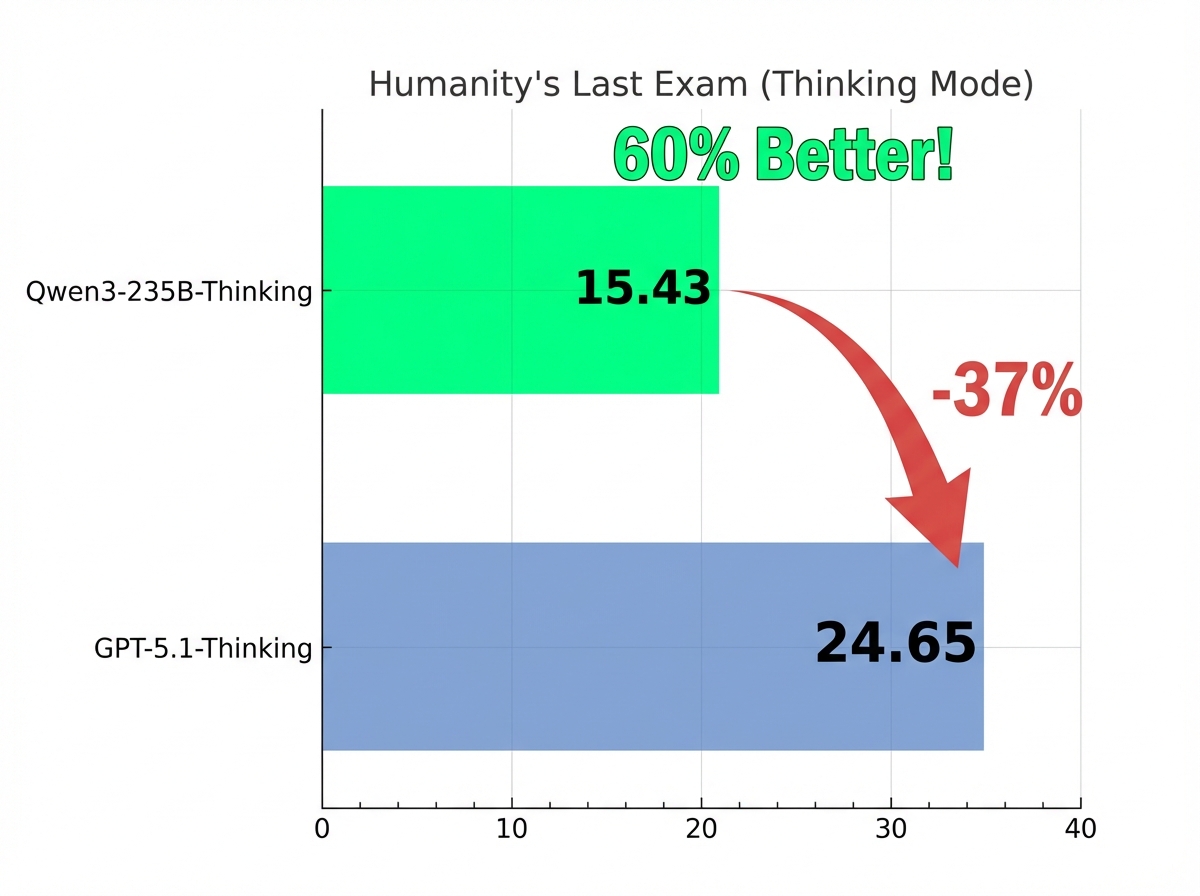
图片说明: 对比Qwen3-Thinking(15.43)vs GPT-5-Thinking(24.65)的60%领先优势
关键洞察:
- Qwen3在"非思考模式"下已经世界第一
- 在"思考模式"下,领先GPT-5约60%(15.43 vs 24.65)
二、为什么Qwen3能赢?三个技术"杀手锏"
杀手锏1:235亿参数MoE架构,只激活22亿
Qwen3-235B-A22B的架构:
- 总参数:235亿(Mixture-of-Experts混合专家)
- 激活参数:22亿(每次推理只用9.4%的参数)
- 训练数据:36万亿token(Qwen2.5是18万亿,翻倍)
对比竞品:
- GPT-5:参数未公开(估计1.2-1.8万亿),全参数激活
- Claude Opus 4:参数未公开(估计数千亿)
- Gemini 2.5 Pro:参数未公开
MoE的优势:
- 推理速度快(只激活9.4%参数)
- 成本低(输入$1.2/百万token,GPT-5是$1.25)
- 能力强(235亿参数的"智慧库",但每次只调用最相关的22亿)
杀手锏2:"双模式"切换:思考vs快速回答
Qwen3的独特设计:
- 思考模式(Thinking Mode):模型会"显示推理过程",一步步解题
- 非思考模式(Non-Thinking Mode):直接给答案,速度快
真实案例对比(DataCamp测试):
问题:"一个披萨切8片,我吃了3片,朋友吃了2片,还剩多少?"
Claude Sonnet 4.5(非思考):
答案:3片。(耗时2秒)
Qwen3(思考模式):
推理过程:
首先,总共8片。我吃了3片,所以剩8-3=5片。然后朋友吃了2片,所以5-2=3片。但等等,我需要确认"朋友吃了2片"是在我吃完之后还是同时?假设是之后,那答案是3片。让我验证:8-3-2=3。正确。
答案:3片。(耗时20秒,生成300+token)
关键点:
- 简单问题(披萨),Qwen3"过度思考"了(浪费时间)
- 但复杂问题(如AIME数学题),这种"过度思考"就是优势
用户可控制"思考预算":
- 设置
thinking_budget=8192 tokens:模型最多思考8192字才给答案 - 适合超难问题
杀手锏3:AIME25和HMMT的100%满分
AIME25(美国高中数学邀请赛2025):
- Qwen3-235B:100%正确率
- GPT-5:约90%
- Claude Opus 4:约50%
- 这是AI首次在AIME上达到满分
HMMT(哈佛-MIT数学竞赛):
- Qwen3:100%
- 对比:Claude Opus 4约50%
为什么数学这么重要?
- 数学是"纯推理"能力的试金石
- 不能靠"记忆答案"(每年题目都变)
- AIME和HMMT的题目需要多步推理、创造性思考

图片说明: 展示Qwen3在AIME25达到100%满分vs竞品50-90%的差距
真实AIME题目示例(2024年):
"在三角形ABC中,AB=13,BC=14,CA=15。点D在BC上,使得AD平分角BAC。求BD的长度。"
Qwen3的解题过程(简化版):
- 用角平分线定理:BD/DC = AB/AC = 13/15
- 设BD=13x,DC=15x,则13x+15x=14,解得x=0.5
- BD=13×0.5=6.5
答案:6.5
关键:Qwen3不仅给出答案,还展示每一步推理,让人类能审核。
三、成本对决:Qwen3是Claude的2.5倍便宜,OpenAI的一半
定价对比(每百万token)
模型 | 输入价格 | 输出价格 | 上下文窗口 |
|---|---|---|---|
Qwen3-235B | $1.20 | $6.00 | 262K |
GPT-5 | $1.25 | $10.00 | 400K |
Claude Opus 4 | $3.00 | $15.00 | 200K |
Gemini 2.5 Pro | $2.50 | $12.50 | 1M |
成本优势分析:
- vs Claude:输入便宜60%,输出便宜60%,总成本约2.5倍便宜
- vs GPT-5:输入基本持平,输出便宜40%
- vs Gemini:输入便宜52%,输出便宜52%
真实场景计算:
假设你的AI应用每天处理:
- 1亿input token(10万次对话,每次1000 token)
- 5000万output token(每次对话500 token输出)
每月成本对比:
- Qwen3:($1.2×100 + $6×50) × 30 = $12,600/月
- GPT-5:($1.25×100 + $10×50) × 30 = $18,750/月
- Claude Opus 4:($3×100 + $15×50) × 30 = $31,500/月
Qwen3比Claude每月省$18,900,比GPT-5省$6,150。
四、OpenAI和Google的"垄断破裂":中国AI的逆袭时刻
2023-2024:OpenAI一家独大
时间线:
- 2023年11月:GPT-4 Turbo发布,各项基准测试霸榜
- 2024年5月:GPT-4o发布,多模态能力碾压竞品
- 2024年12月:o1发布,推理能力遥遥领先
当时的市场格局:
- OpenAI:80%的企业AI市场
- Google:15%(Gemini追赶)
- Anthropic:5%(Claude小众但口碑好)
- 中国AI(包括阿里、百度、字节):<1%
2025年:中国AI的"翻身仗"
关键事件:
- 2025年1月:DeepSeek R1发布,成本暴跌,引发全球震动
- 2025年5月:Qwen3发布,Humanity's Last Exam登顶
- 2025年9月:Qwen3-Max发布,1.2万亿参数MoE模型
市场格局变化(预测):
- OpenAI:市场份额降至60%
- Google:20%
- 中国AI:15%(主要是Qwen、DeepSeek)
- Anthropic:5%
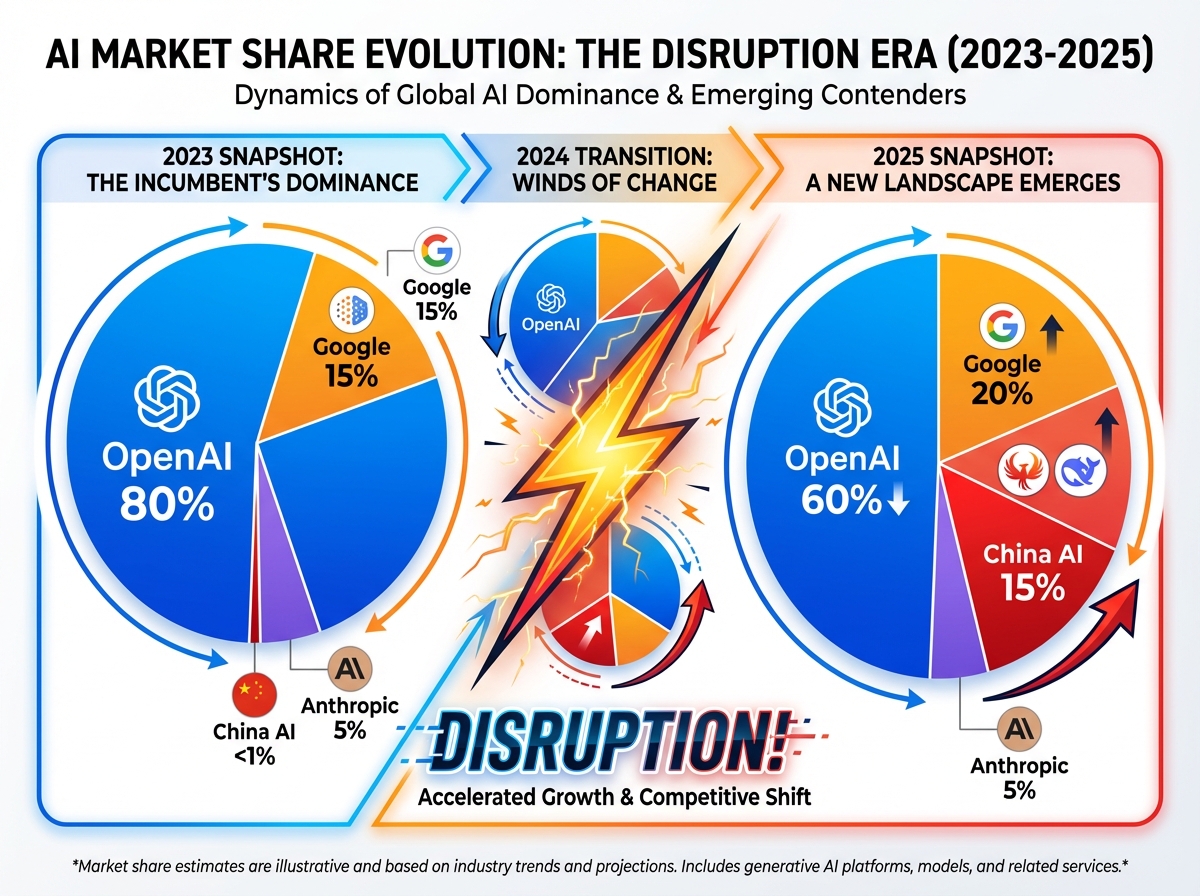
图片说明: 展示中国AI从<1%到15%的市场份额爆发式增长
为什么中国AI能逆袭?
原因1:成本优势
- 中国云计算成本低(阿里云、腾讯云比AWS便宜30-40%)
- 工程师成本低(中国AI工程师年薪$80K-150K,美国$200K-500K)
原因2:开源策略
- Qwen3全系开源(Apache 2.0许可证)
- DeepSeek R1开源
- 吸引全球开发者贡献,形成生态
原因3:垂直整合
- 阿里有淘宝、天猫、钉钉等应用场景
- 百度有搜索、地图、自动驾驶
- 字节有抖音、今日头条
- 真实场景=真实数据=更好的模型
五、给不同角色的"AI选型指南"
给开发者:
- 如果做数学/推理应用:首选Qwen3(AIME满分,推理能力最强)
- 如果做代码生成:GPT-5略胜(SWE-bench 72.8% vs Qwen3 69.6%)
- 如果做文案创作:Claude Opus 4(公认文笔最好)
给企业:
- 如果预算有限:Qwen3是不二之选(成本低50-60%)
- 如果需要超长上下文:Gemini 2.5 Pro(1M token窗口)
- 如果需要稳定性:GPT-5(OpenAI的运维最成熟)
给投资人:
- 不要只投OpenAI系:中国AI已经证明技术实力
- 关注开源生态:Qwen3、DeepSeek的社区活跃度暴涨
- 垂直应用机会大:基础模型已是红海,垂直AI(医疗、法律、教育)是蓝海
给普通用户:
- 日常聊天:ChatGPT Plus($20/月)还是最方便
- 数学辅导:试试Qwen3(免费版在qwen.ai)
- 写作助手:Claude(文笔好,长文生成强)
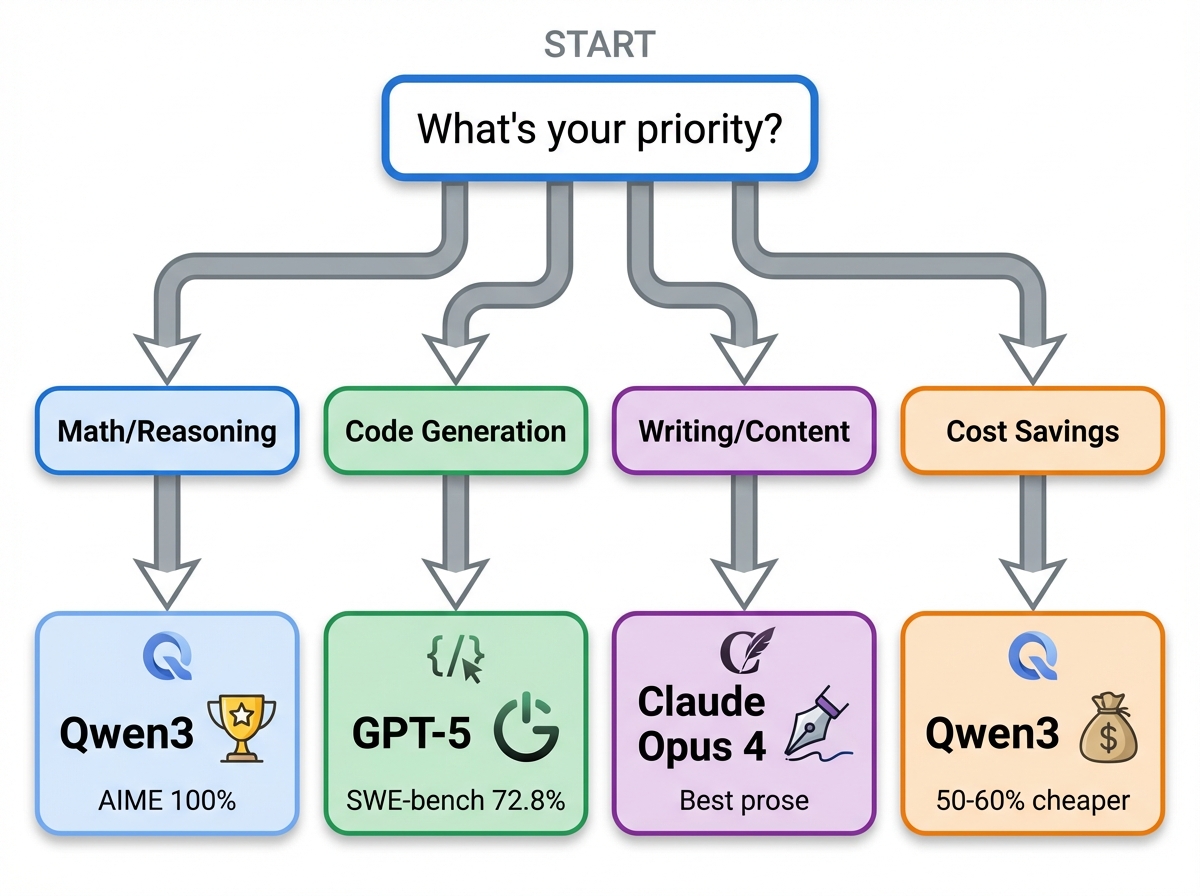
图片说明: 根据不同需求(数学/代码/成本)选择Qwen3/GPT-5/Claude的简单决策路径
结语
2025年,AI竞赛的终局不再是"谁的参数更多",而是"谁的推理更深"。
Qwen3用235亿参数击败了可能数万亿参数的GPT-5,证明了一个古老的真理:智慧不在于知道多少,而在于能思考多深。
当OpenAI和Google还在军备竞赛(更大模型、更多GPU)时,阿里选择了另一条路:
- 更高效的架构(MoE)
- 更深的推理(Thinking Mode)
- 更开放的生态(Apache 2.0)
