
ReconVLA引爆AAAI 2026!机器人“开眼看世界”获顶级会议首肯
当你命令机器人“把蓝色积木放到粉色积木上”,它那双“眼睛”看到的可能只是一片模糊的色彩与形状,根本分不清哪个是关键目标——这正是当前机器人视觉的普遍困境,它们空有摄像头,却没有人类“聚焦关键信息”的视觉注意力。而近期,由香港科技大学(广州)、西湖大学与浙江大学联合发表的ReconVLA模型,一举夺得AAAI 2026杰出论文奖,这不仅是具身智能领域在顶级AI会议上“零的突破”,更标志着让机器“看懂、思考并行动”的能力,已成为人工智能研究的核心前沿。

获奖论文的基本信息。图片来源:AAAI 2026 获奖论文《ReconVLA:重构视觉-语言-动作模型作为有效的机器人感知器》
01 机器人的“散光”问题
机器人视觉模型一直有个根深蒂固的问题:视觉注意力难以聚焦。当面对“把蓝色积木放到粉色积木上”这样的指令时,模型本应专注寻找这两个特定物体,但它们的注意力却常常像“散光”一样平均分布在整张图像上。

VLA模型关键瓶颈演示。在执行“将积木滑入抽屉”的指令时,基线模型(上排)的注意力分散,而ReconVLA(下排)能精准聚焦于任务相关的积木和。图片来源:AAAI 2026 获奖论文《ReconVLA:重构视觉-语言-动作模型作为有效的机器人感知器》
这个问题导致机器人容易被无关物体或背景干扰,抓取失败率居高不下。在工业场景中,传统机器人视觉系统面对位置变化的工件时,抓取效率会大幅降低。
学术界尝试过两种主流解决方案:一是先检测目标再裁剪区域;二是让模型输出目标坐标框。但这些方法都像给机器人戴上一副笨重的眼镜——解决了部分问题,却增加了系统复杂性和误差传递。
独到见解:机器人视觉的根本矛盾在于,我们给机器“人类级别”的指令,却只赋予它“机器级别”的感知能力。这就像让一个近视的人在不戴眼镜的情况下完成精密手术。
02 让机器人学会“凝视”
ReconVLA提出的解决方案既巧妙又直观:如果机器人能“重建”目标区域,那它就必须真正“看懂”这个目标。
ReconVLA的核心创新是增加了一个“视觉重建分支”。模型在执行任务的同时,需要完成一项特殊作业——重建它此刻应该“凝视”的目标区域。这类似于人类的视觉机制:当你专注于一个物体时,你脑中会形成关于这个物体的清晰图像。研究团队使用轻量级扩散变换器来完成重建,并在潜在空间中实现高保真复原。通过最小化重建误差,模型被迫在其内部视觉表示中编码关于目标物体的精细信息,从而实现隐式而稳定的注意力对齐。
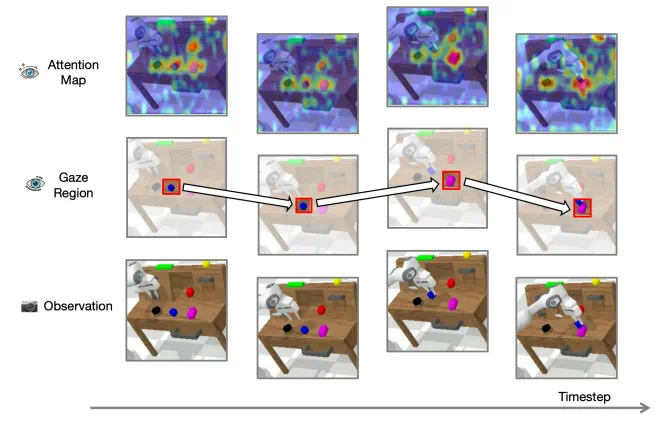
ReconVLA的注意力机制。模型在每个时间步(Timestep)都能生成精准的注意力图(Attention Map),并锁定需要“凝视”的关键区域(Gaze Region)。图片来源:AAAI 2026 获奖论文《ReconVLA:重构视觉-语言-动作模型作为有效的机器人感知器》
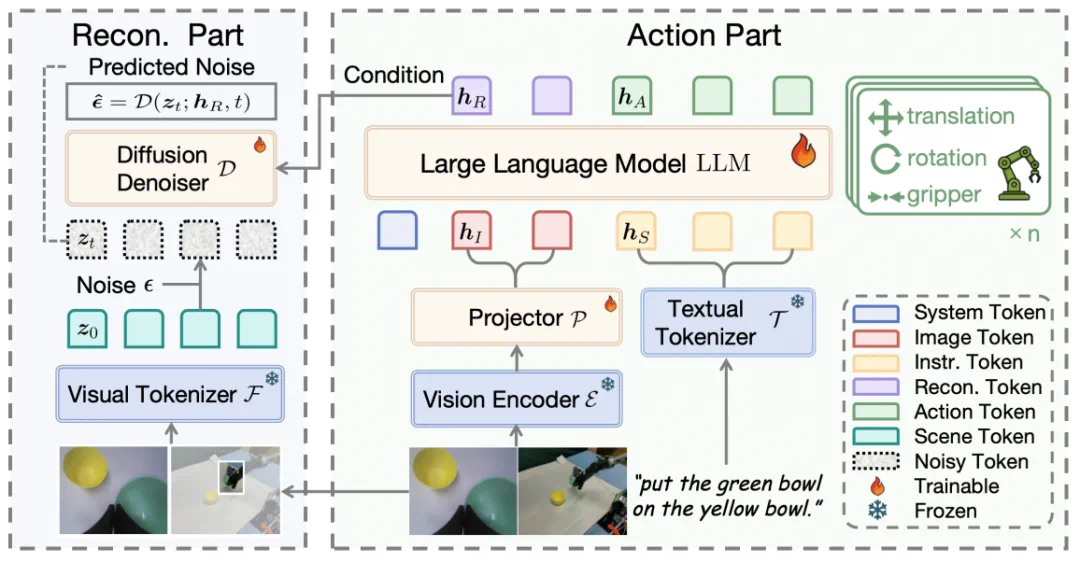
ReconVLA整体框架图。模型包含动作预测和视觉重建两个协同分支,通过扩散去噪过程重建目标区域,实现视觉表征与动作决策的紧密耦合。图片来源:AAAI 2026 获奖论文《ReconVLA:重构视觉-语言-动作模型作为有效的机器人感知器》
03 性能全面领先,泛化能力突出
在权威的CALVIN仿真基准测试中,ReconVLA展现出了压倒性的性能优势。尤其是在要求连续完成多项任务的挑战中,其表现远超其他主流模型。
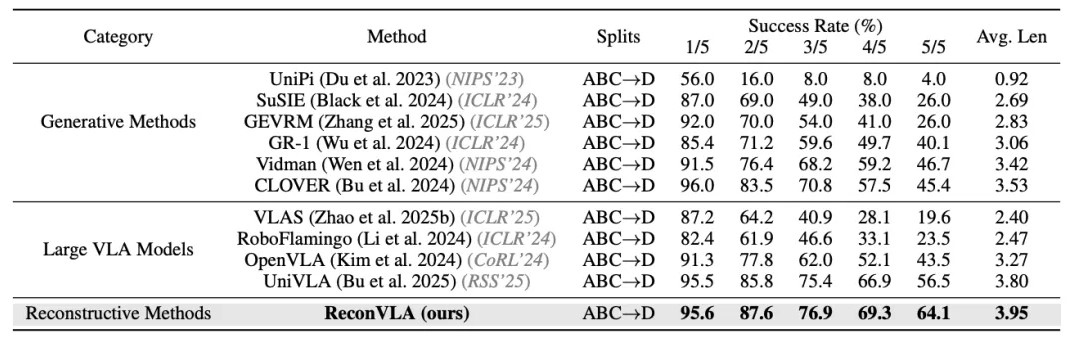
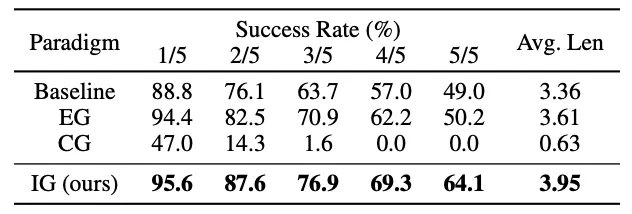
在CALVIN ABC→D任务上的性能对比。图片来源:AAAI 2026 获奖论文《ReconVLA:重构视觉-语言-动作模型作为有效的机器人感知器》

真实世界机器人任务实验设置。图片来源:AAAI 2026 获奖论文《ReconVLA:重构视觉-语言-动作模型作为有效的机器人感知器》
更令人信服的是在真实机器人上的测试。研究团队使用六自由度机械臂,执行了叠碗、放水果、翻杯、清理餐桌等多项任务。ReconVLA不仅在所有任务上全面领先,在面对从未见过的新物体时,仍能保持超过40%的成功率,展现了强大的视觉泛化能力。
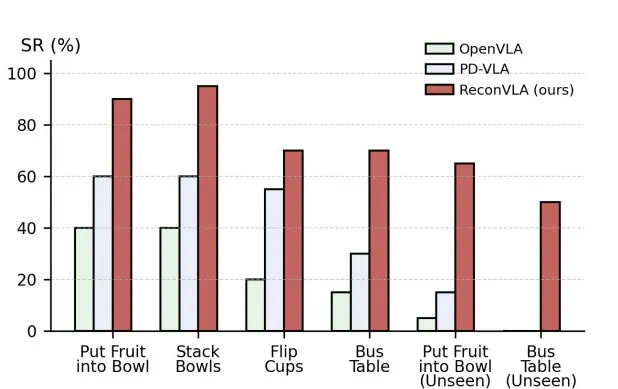
真实机器人任务成功率对比。ReconVLA(橙色)在叠碗、放水果等多项任务上均显著优于OpenVLA和PD-VLA,在“未见物体”条件下表现依旧稳健。图片来源:AAAI 2026 获奖论文《ReconVLA:重构视觉-语言-动作模型作为有效的机器人感知器》
04 隐式对齐的范式革新
ReconVLA与现有方案的根本区别在于它放弃了“显式定位”的固有思维,转而寻求一种更接近人类本能的“隐式对齐”。传统方法需要模型明确输出“看哪里”,而ReconVLA则通过“能否重建目标区域”来约束模型必须学会关注关键物体。
不同视觉定位范式的效果对比。图片来源:AAAI 2026 获奖论文《ReconVLA:重构视觉-语言-动作模型作为有效的机器人感知器》
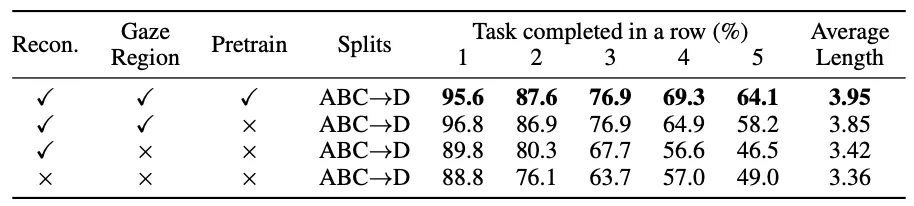
消融实验表。证明了“重建目标区域(Gaze Region)”和“大规模预训练(Pretrain)”是模型成功的关键组件。图片来源:AAAI 2026 获奖论文《ReconVLA:重构视觉-语言-动作模型作为有效的机器人感知器》
如“不同视觉定位范式的效果对比表”所示,显式定位(EG)和思维链定位(CG)的提升有限甚至有害,而ReconVLA采用的隐式定位(IG)实现了性能的飞跃。这种方法的优势显而易见:简化了模型架构,同时提高了精度和泛化能力。研究团队的消融实验进一步验证了这一设计的有效性。结果显示,重建目标区域比重建整张图像效果更好,因为这让模型能专注于目标物体,避免被无关背景干扰。
05 开源共建生态,瞄准通用基础模型
面对如何将实验室突破转化为实际应用的问题,研究团队选择了开源策略。论文和代码已在GitHub上公开,降低了技术使用门槛。团队还构建了包含超过10万条交互轨迹、约200万张图像的大规模预训练数据集,为进一步的研究和应用奠定了基础。
06 具身智能的“iPhone时刻”
ReconVLA获得AAAI杰出论文奖的标志性意义不亚于2012年AlexNet在ImageNet竞赛中的突破 —— 它预示着具身智能可能正迎来自己的“iPhone时刻”。
随着3D空间理解、实时SLAM(同步定位与地图构建)和物体姿态追踪等技术的成熟,机器人正从“执行预定程序”向“理解并适应环境”转变。未来,我们可能会看到具身智能在三个方向加速发展:家庭服务机器人能够理解并执行更复杂的自然语言指令;工业自动化系统具备更强的适应性和灵活性;专业领域应用如医疗手术辅助、危险环境作业等取得突破。
机械臂在实验室中准确地将小碗叠起,桌上的水果被一一放入对应颜色的碗中,即使面对从未见过的物体,它也能保持40%以上的操作成功率。
机器人需要的不只是更快的处理器或更大的数据集,而是一双真正能“看懂”世界的眼睛。当具身智能学会“凝视”,当机器开始理解“注意”的含义,我们与真正智能机器共处的时代,或许已经拉开了序幕。
